
Google's Gemma 4 will Change How AI Models are Built
Breaking down the architectural decisions Google made — and why edge and server models are built on opposite logic.

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
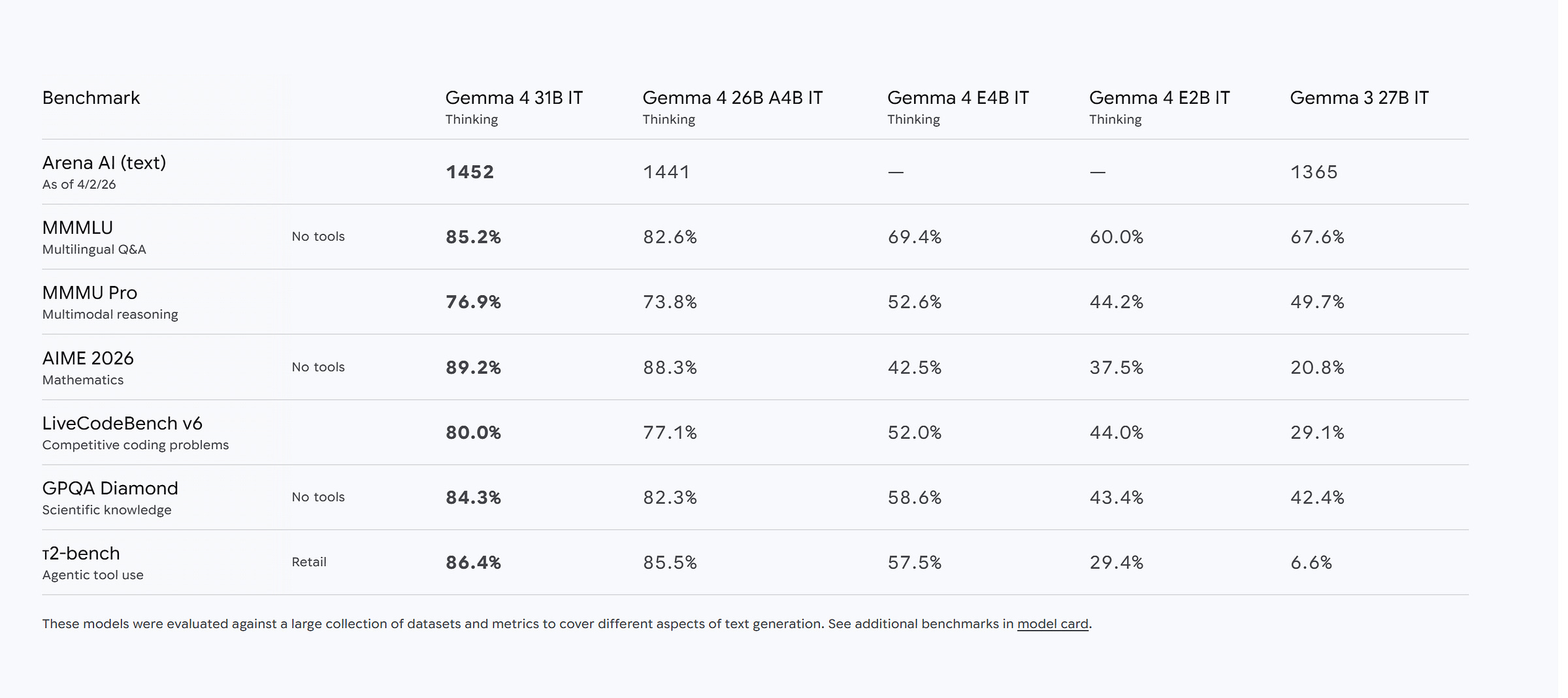
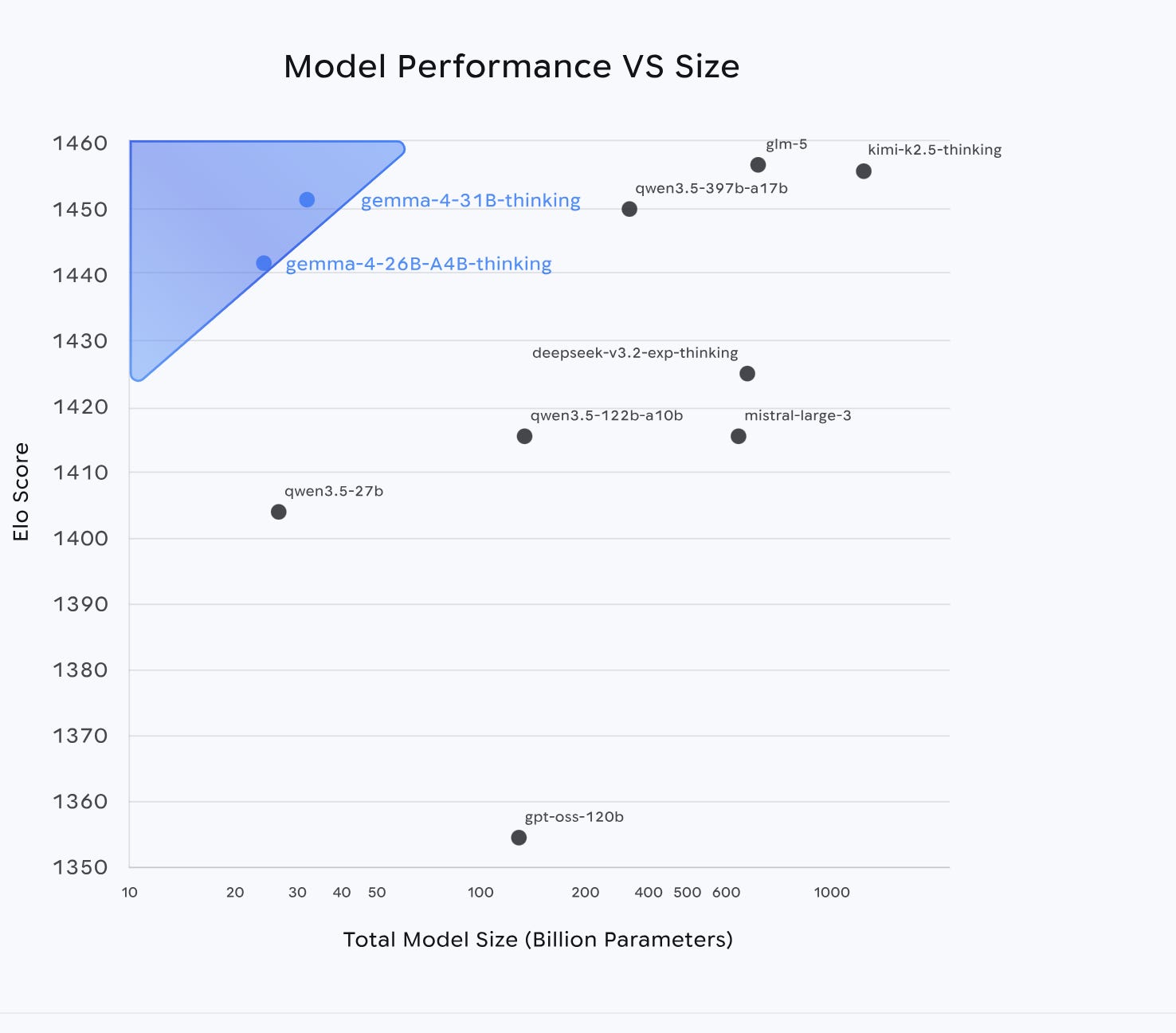
Everyone is staring at the Gemma 4 benchmarks right now, but that misses the actual design shift. Google shipped four models, but if you look under the hood, you’re looking at two entirely divergent architectures: E2B and E4B for phones, and 26B and 31B for servers. Unlike traditional multi-model rollouts (where it’s the same core architecture at different scales) , the edge pair and server pair have very different DNAs.
Why? Because the physical constraints of a phone and an H100 are exact opposites.
Think about the hardware. A phone has abundant flash but starves for DRAM — you’ve typically got 128GB of storage against maybe 8GB of shared memory, all bound by a battery that dies if you hit it wrong. A server gives you DRAM in abundance and FLOPS you pay for by the hour. Every architectural choice is a trade between memory, storage, and compute. When that scarcity flips, you have to pull opposite levers: you compress memory at the cost of compute on an edge device, and you spend memory to save compute on a server. That’s why one architectural DNA can’t survive both deployments.
Gemma solves this through different architectural DNAs, and I think that’s the real signal about where the industry’s headed — one family name, very different architectures underneath depending on where the model has to run. This has several implications for the future of AI, all of which go way beyond simply discussing the model choices/benchmark numbers.
In this article, we will cover:
The two constraints: the KV cache scaling and narrow hidden dimensions forcing this entire split.
Per-layer embeddings: why the E2B blows half its weight budget on flash lookups, and why the server models don’t bother.
Interleaved local-global attention: where Gemma 4 actually pays the O(n²) compute tax, and where it doesn’t.
Divergent GQA: how edge compresses KV everywhere, while server compresses it selectively.
Cross-layer KV sharing: the edge-only trick that slashes cache by 83%, and the MLP tax it charges you to do it.
Partial RoPE: rotating only 25% of dimensions so the content actually has room to breathe.
Hybrid MoE: the always-on dense FFN that makes running 4x Mixtral’s sparsity safe in production.
The FA2 serving break: why a 512 head dimension costs pre-Blackwell GPUs roughly 14x in throughput.
The deployment framework: which model earns its place where, and exactly what breaks in practice.
Let’s have some fun.
Executive Highlights (TL;DR of the Article)
The Core Thesis: The benchmark hype misses the real story. Gemma 4 is actually two entirely divergent architectures marketed under one name. Edge models (E2B/E4B) and server models (26B/31B) share almost nothing because a phone’s constraints (abundant flash, zero DRAM) are the exact opposite of an H100’s constraints.
Per-Layer Embeddings (Edge): The E2B blows nearly half its parameter budget (46%) on flash-based lookup tables. This prevents token meanings from colliding in a narrow hidden state, boosting reasoning without touching the phone’s limited DRAM. Server models skip this entirely.
Interleaving & The KV Cache War: To survive massive contexts, Gemma 4 alternates between cheap local attention and expensive global attention. On the edge, it goes further by heavily compressing the KV cache and reusing it across layers — shrinking the cache from gigabytes to megabytes so 128K context can actually fit on a phone.
Partial RoPE: At 128K context, standard positional encoding acts as noise, scrambling semantic meaning. Gemma 4 fixes this by only rotating 25% of the vector’s dimensions to track position, leaving the other 75% clean to act as pure, undistorted content channels.
Hybrid MoE (Server): The 26B server model pushes a hyper-aggressive 128-expert routing setup. It only survives this extreme sparsity because an always-on dense feed-forward network runs alongside the experts, acting as a structural safety net against routing failures.
The Infrastructure Break: The global attention layers require a head dimension of 512. This breaks FlashAttention-2 compatibility. If you run Gemma 4 on pre-Blackwell hardware (like an H100 or 4090) today, you will take a massive 14x throughput hit until the open-source serving stack patches the issue.
The Big Picture: Uniform scaling is dead. We are witnessing the unbundling of the one-size-fits-all transformer. The labs that win the next cycle won’t just scale brute compute; they will engineer specialized architectures that exploit the exact physics of the hardware they run on.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
What Is Per-Layer Embedding and Why Does Only Edge Gemma 4 Use It?
Every token enters a transformer through a massive lookup table that maps the raw word into a vector. That vector becomes the main signal flowing through the entire model. Attention and FFN layers reshape it at every layer, but they are all just transforming that exact same base vector that started life as a table entry.
That starting vector has a brutal job: it has to carry the token’s raw identity (the word “bank”) and its contextual potential (money vs. river) simultaneously. In a massive model like Llama 3 70B (hidden_size 8,192), there is enough bandwidth for both signals to travel without stepping on each other. Different dimensions specialize; the signal has room to breathe.
But E2B runs at a hidden_size of 1,536. At a fifth of the width, the signals suffocate. “Bank the river” and “bank the money” compete for the same constrained coordinates, and every downstream attention layer inherits that collision.
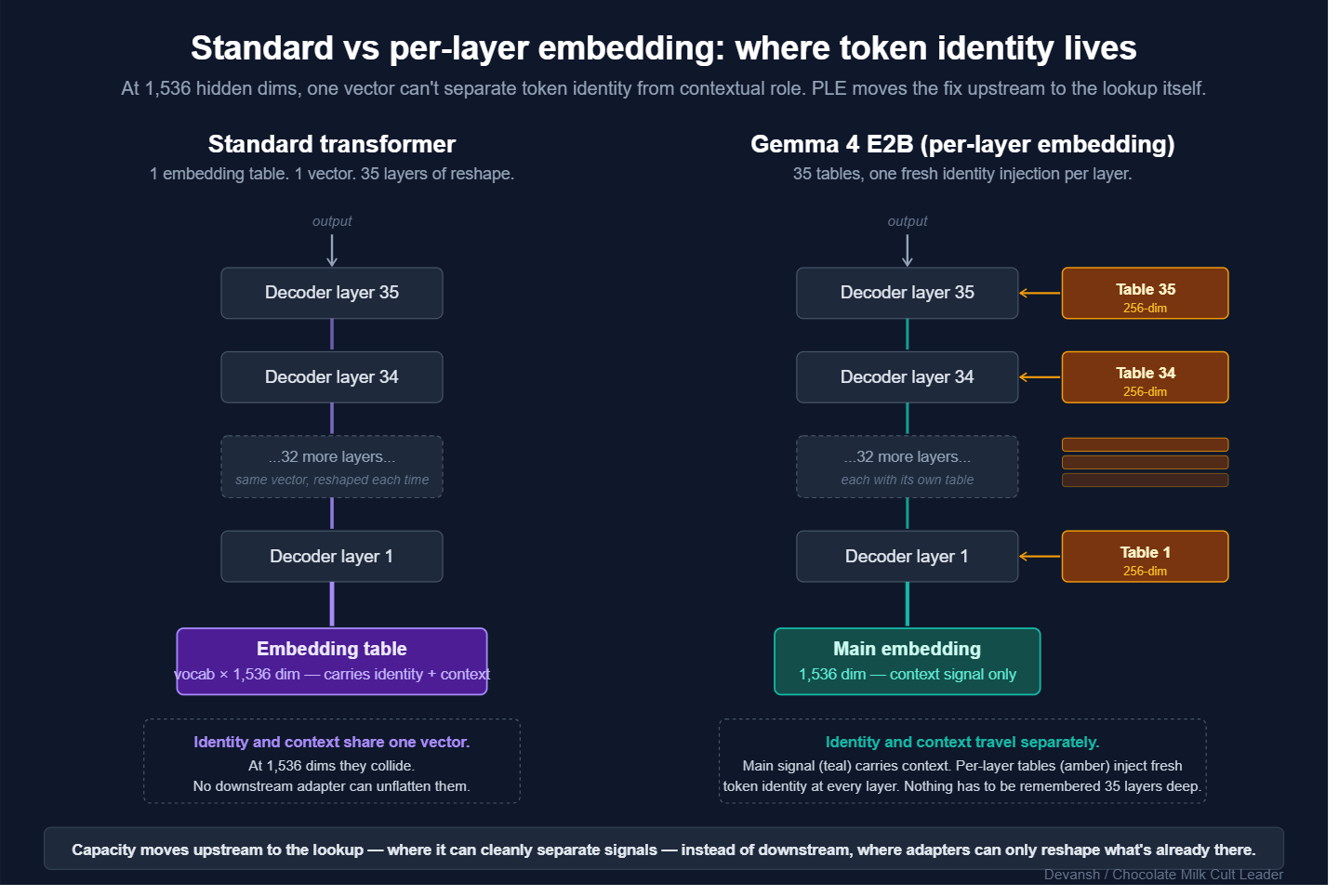
The naive fix is to bolt capacity downstream using adapters, LoRA, or extra trainable projections. But downstream math can only transform what survived the initial lookup. If the embedding flattened two meanings into the same direction, no amount of downstream projection unflattens them.

Google’s fix is to move the capacity upstream to the lookup itself. Instead of one giant table, E2B gives each of its 35 decoder layers its own dedicated 256-dim embedding table. When a token arrives, every layer does its own lookup. The main 1,536-dim signal flowing through the model no longer has to remember a token’s raw identity across 35 layers, because every layer has a fresh, context-aware identity signal waiting for it.
This is obviously not a free lunch. At 67.1M parameters per table across 35 layers, Per-Layer Embeddings (PLE) consume 2.35B parameters — 46% of E2B’s entire 5.1B budget. If this lived in DRAM, it would be fatal since the phone only has 8GB, and the KV cache and activations are already eating it.
But PLE tables don’t need DRAM. They are static lookups, read once per token per layer. Flash latency is irrelevant at that access pattern. So Google parks the tables in flash, where a phone has 128GB to burn. That 4.7GB footprint is effectively free.
This is also exactly why the 26B and 31B skip PLE entirely. On an H100, you have 80GB of HBM and no flash asymmetry to exploit. You would never blow 46% of your parameter budget on a trick that only pays off when DRAM is the binding constraint. Besides, at their wider hidden sizes (2,816 and 5,376), the representational collision stops being a fatal problem.

Does PLE actually do the work Google implies? They haven’t shipped an ablation, but E2B’s benchmarks are hard to explain without it. It hits 37.5% on AIME 2026 (beating Gemma 3 27B’s 20.8%) and 44.0% on LiveCodeBench v6. A model 12x smaller in effective parameters is beating its massive predecessor on reasoning, heavily implying the narrow main signal is finally free to actually reason instead of just remembering what token it saw. It would also be consistent with other patterns where small augmentations that specialization enable higher quality reasoning by allowing the other params to dedicate to reasoning.
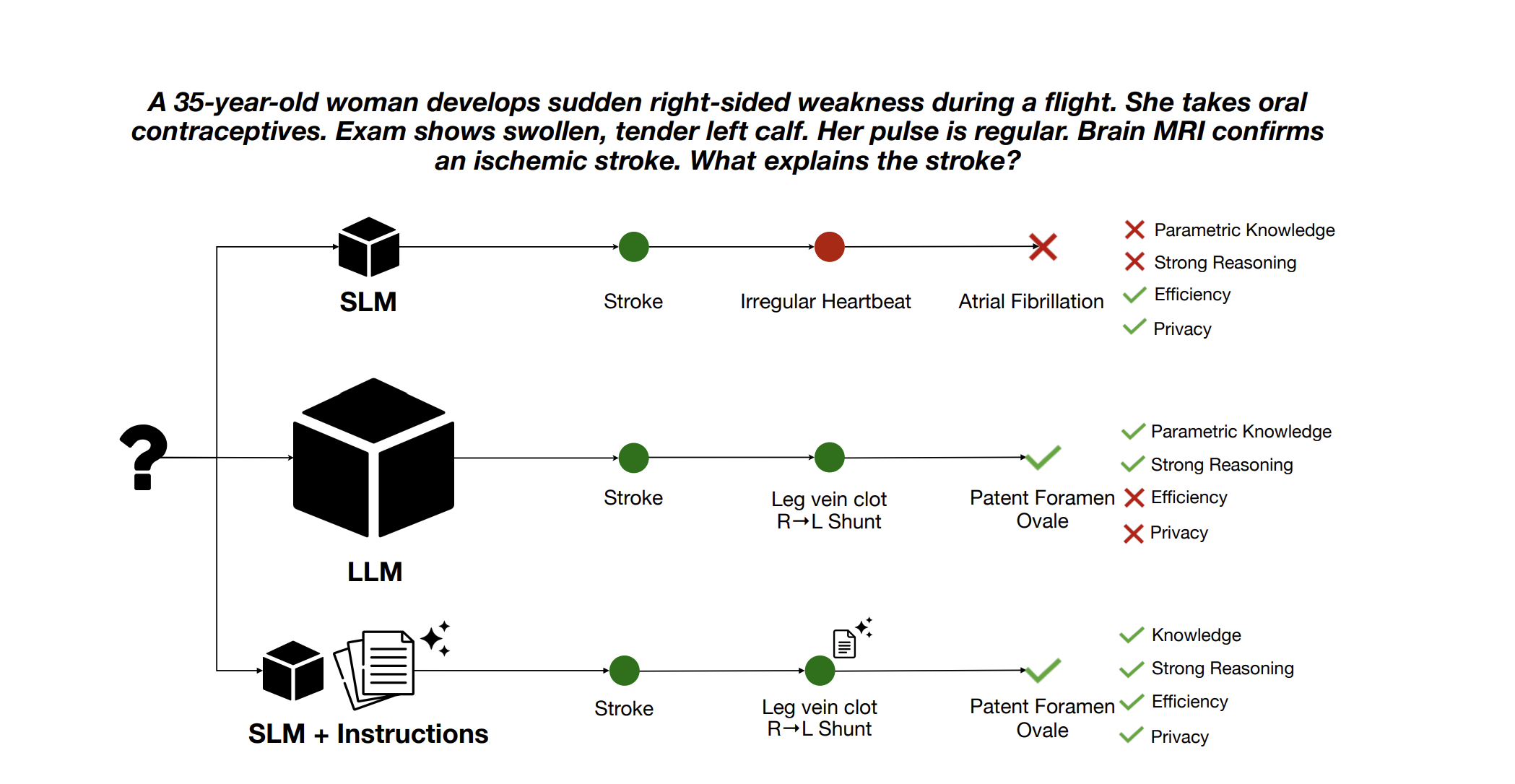
Given that everyone has decided how inefficient Self Attention is, it should come as no surprise that the next innovation Google made was around it.

Why Does Gemma 4 Interleave Local and Global Attention?
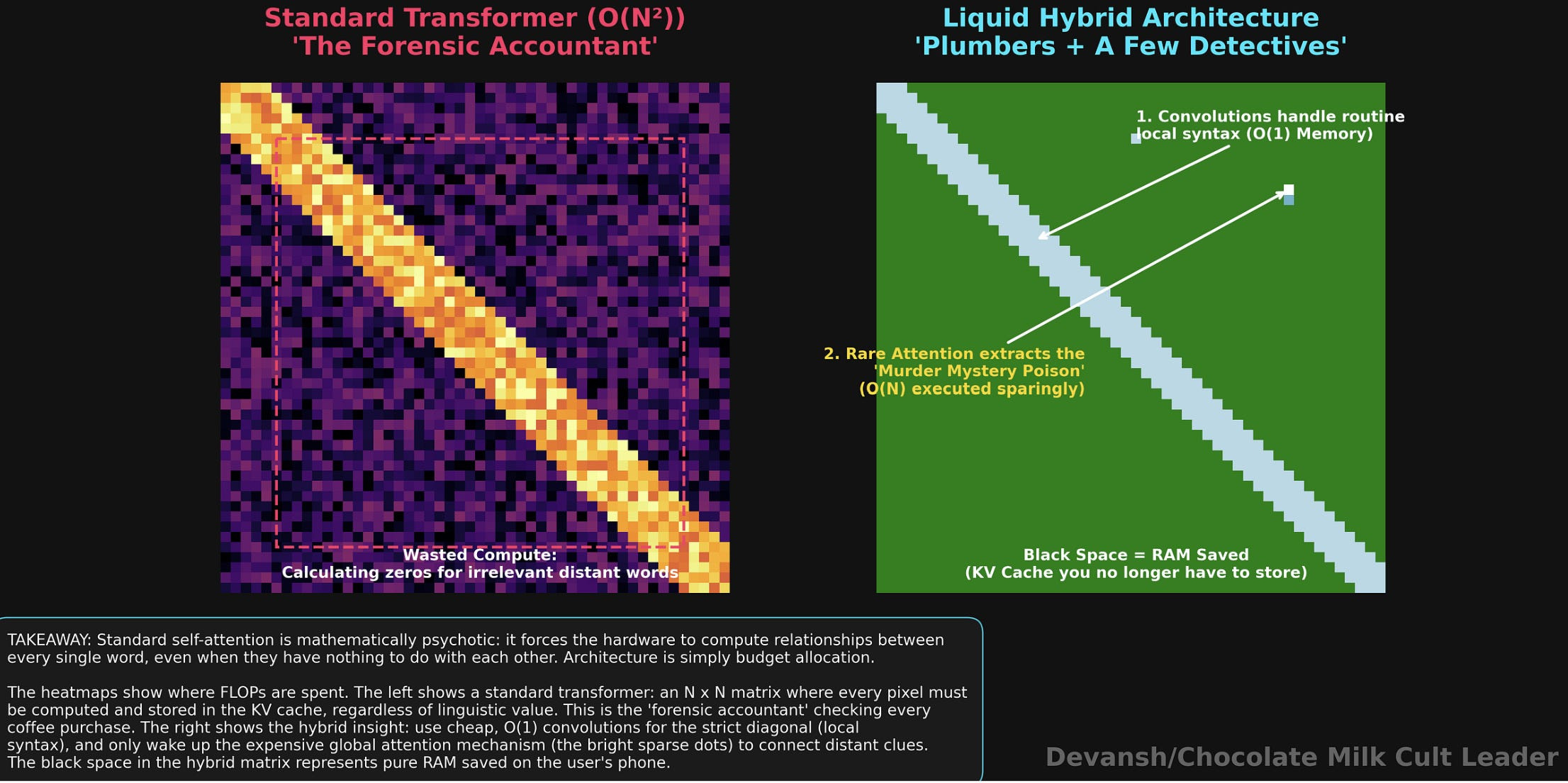
Attention is the most expensive thing a transformer does. Every token has to look at every other token, meaning the compute cost scales quadratically with sequence length. At 128K tokens, that is roughly 16 billion score computations per layer. Multiplied across 30 to 60 layers, it eats the FLOP budget alive.
The historical move is to stop looking at everything. Sliding window attention (Mistral, Phi) caps each token’s view at a fixed window — say, 512 tokens in each direction. The cost drops from O(n²) to O(n *window size), which at 128K context is a 250x reduction.
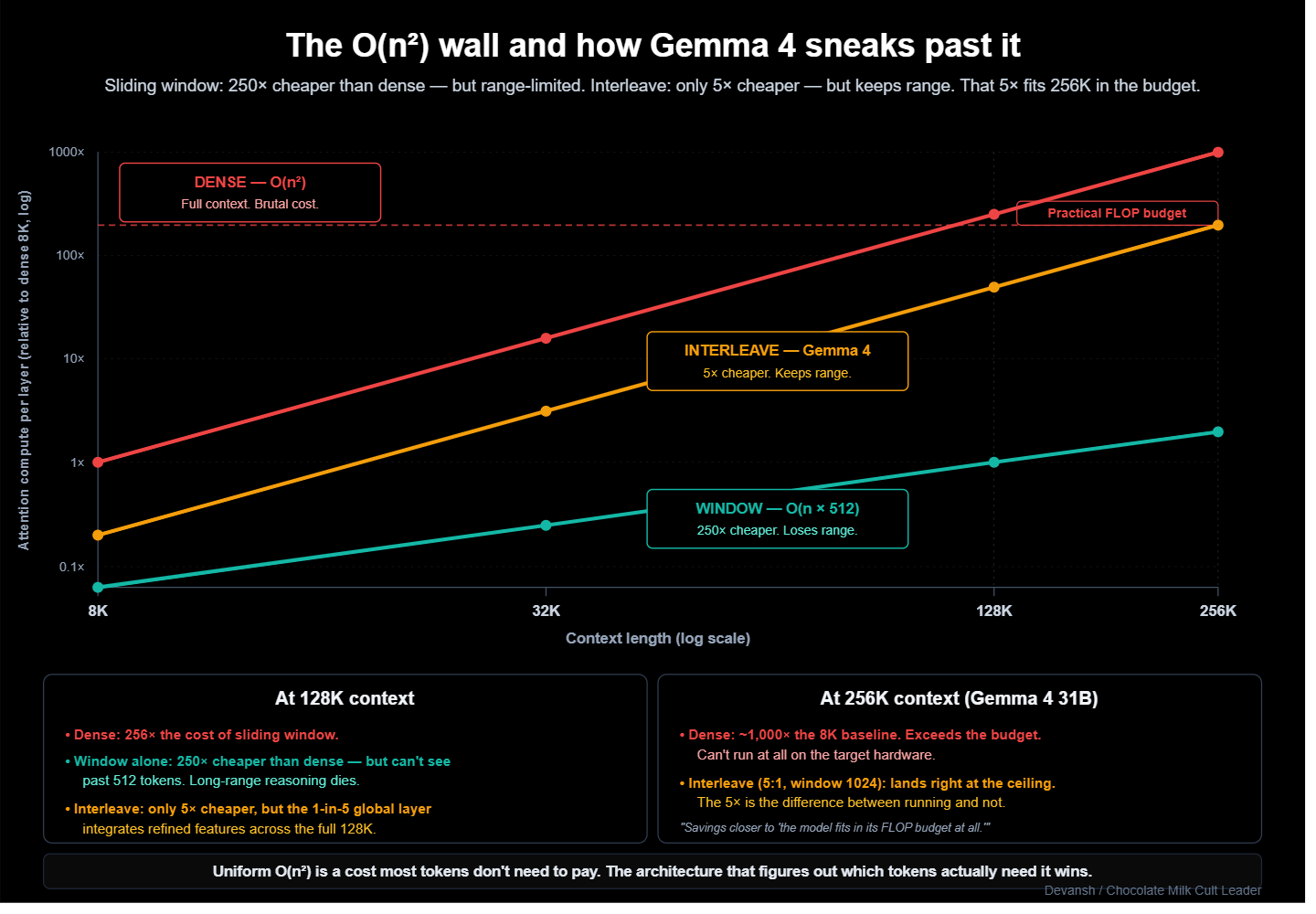
The wall you hit here is signal degradation. With a strict sliding window, a token at position 1,000 cannot directly see a token at position 50,000. Long-range dependencies have to hop through intermediate layers, and each hop degrades the signal. Most modern small models just accept this range limitation, operating on the assumption that if you’re using 2B phone model to process legal documents (or any solution not named Irys.ai for legal work for that matter), then you deserve to be arrested and have your contributions to the gene pool snipped.
Gemma 4 cannot make that assumption. E2B and E4B are multimodal, and processing video frames blows past 8K tokens in seconds. The edge models must handle long contexts. Google’s fix to this conundrum is interleaving. Most layers use local sliding-window attention, while a few execute full global attention. The model alternates between them on a fixed ratio:
E2B: 4 local + 1 global, repeated 7 times. Window: 512.
E4B: 5 local + 1 global, repeated 7 times. Window: 512.
26B: 5 local + 1 global, repeated 5 times. Window: 1024.
31B: 5 local + 1 global, repeated 10 times. Window: 1024.
Every model ends on a global layer. The output always sees the full context regardless of what the intermediate layers did.
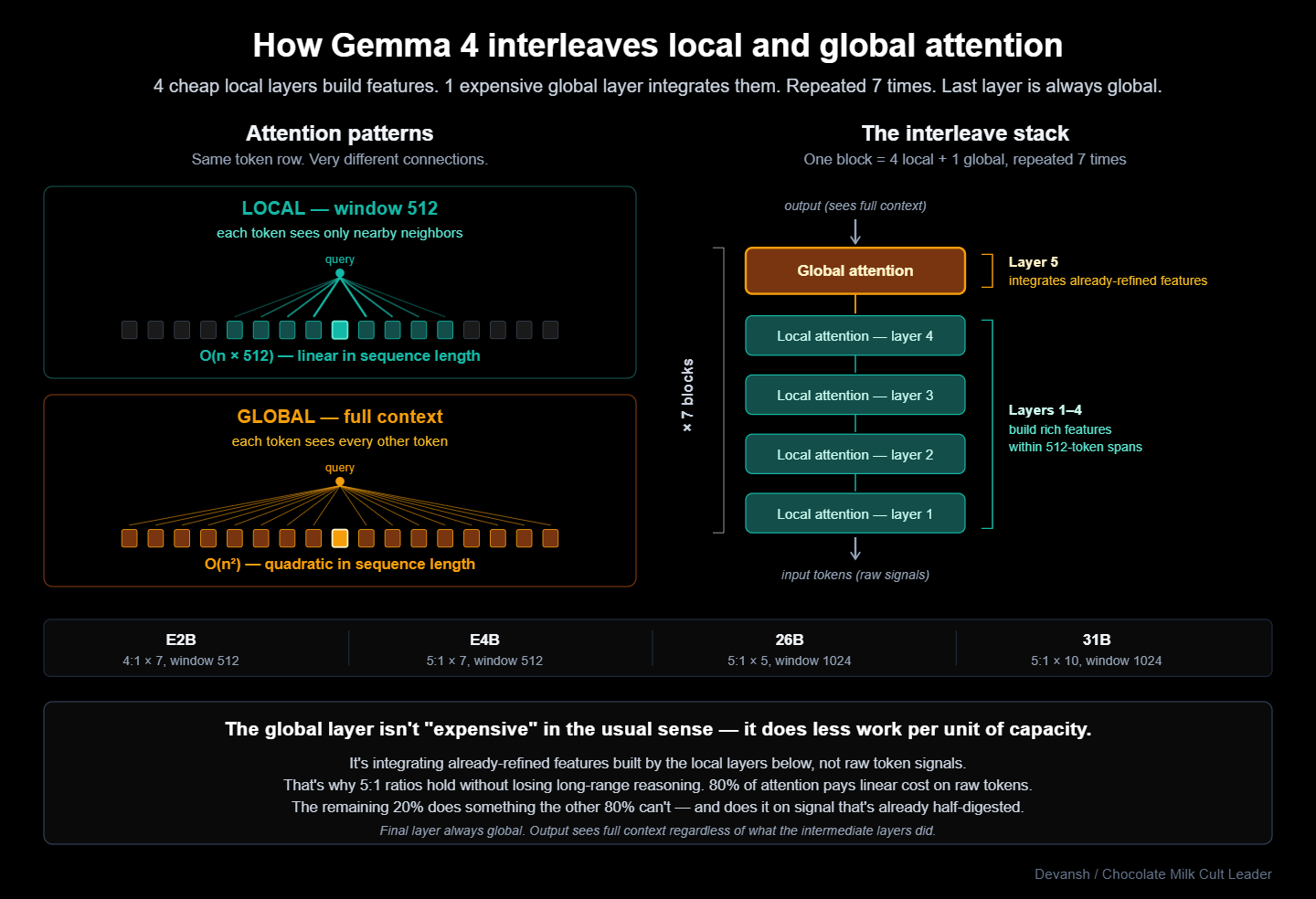
The insight here is that the global layer is not just doing the same work less frequently. Local layers build up rich feature representations within short spans — 512 tokens is plenty for syntax and local semantics. The occasional global layer then executes long-range integration on those already-refined features, rather than raw token signals. It does less work per unit of capacity, which is why the 5:1 ratio sustains long-range reasoning without degrading the output.
At E2B’s 4:1 ratio, 80% of the attention layers pay linear compute instead of quadratic. On an 8K query, that is a 5x speedup for attention compute on the phone. At the 31B’s 256K context, the savings are the only reason the model fits in its FLOP budget at all.
This means that your system is inflexible: if a user inputs a task requiring dense long-range integration across the entire context — like cross-referencing contradictions throughout a 200-page document — the model cannot dynamically allocate more global layers. It gets what it gets. Most tasks do not hit this ceiling, but when they do, the degradation is hard-coded.
Every modern long-context architecture is converging on this identical bet: uniform O(n squared) attention is a cost most tokens don’t need to pay. Mamba avoids it with selective state updates. Ring Attention avoids it by partitioning across devices. Gemma 4 avoids it by interleaving layer types. The architecture that figures out exactly which tokens actually need the expensive math wins.

Why Do Edge and Server Gemma 4 Use Opposite GQA Strategies?
The KV cache puts a silent chokehold on the memory budget of modern transformers. Every processed token must keep its Key and Value vectors in memory so future tokens can attend to them. Cache size scales as layers × KV_heads × head_dim × sequence_length × 2 (one tensor for K, one for V). At 128K context on a 7B model, that is 12.8GB just for the cache. That is the entire DRAM budget of a phone before the weights even load.
Grouped-Query Attention (GQA) is the standard response. By having multiple query heads share a single KV head, you can slash your costs down. For instance, an 8:1 ratio cuts your cache by 8x.
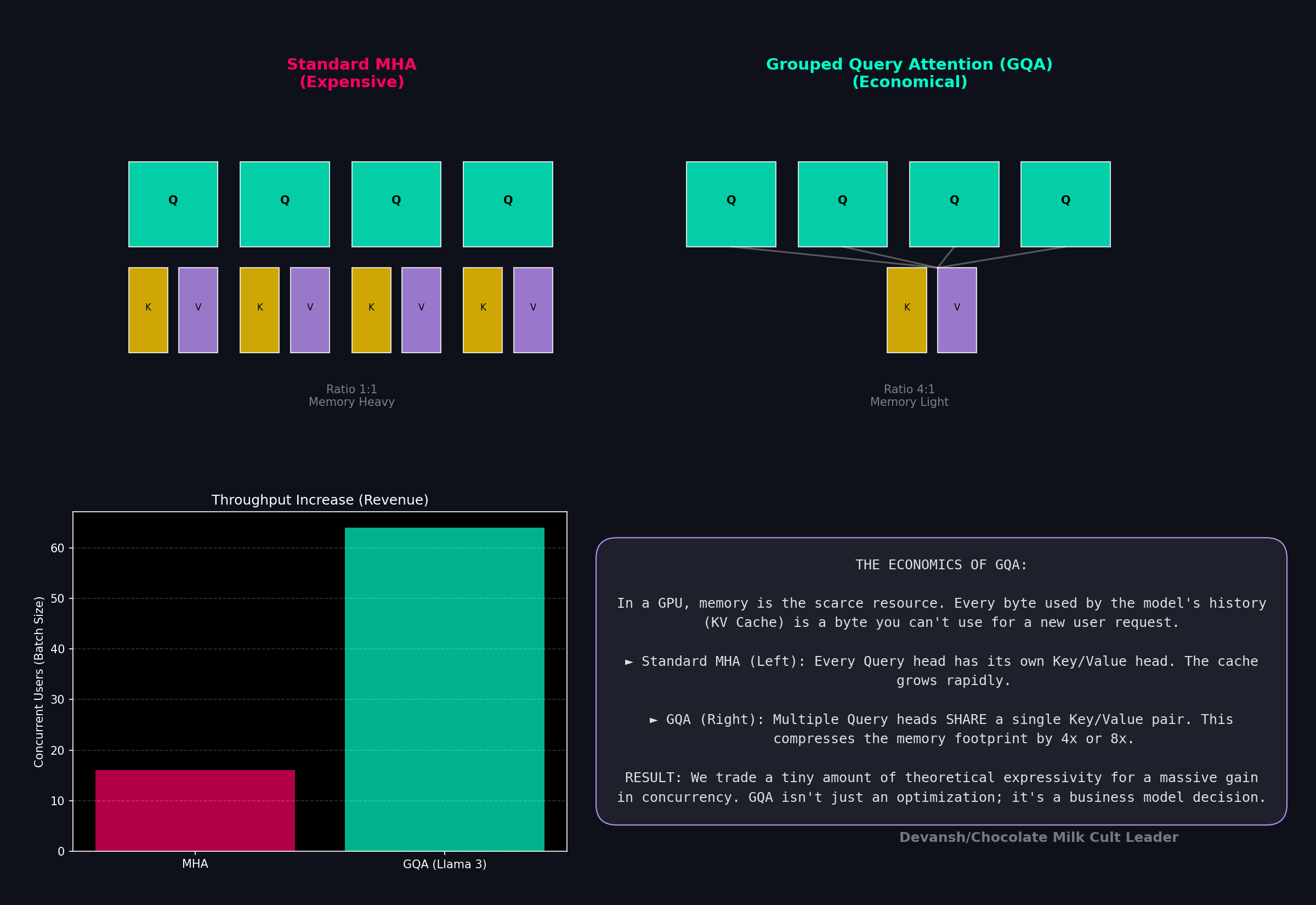
Gemma 4 breaks this uniformity in opposite directions depending on the hardware.
Edge models crush KV everywhere. E2B runs 8:1 uniform GQA across every layer. E4B runs 4:1. The logic is forced by the hardware — on a phone, doubling KV heads Yamchas your 8GB limit. There is no layer where the edge models can afford richer KV, so they don’t have one.
Server models compress selectively. The 26B and 31B both use 2:1 GQA on local attention layers and 8:1 on global layers. Local layers operate on short spans where fine-grained KV discrimination helps distinguish nearby tokens, so server architects spend the DRAM there. Global layers aggregate over 256K of context, doing broader integration that tolerates aggressive compression. You compress where the work is coarse, and spend where it is precise.
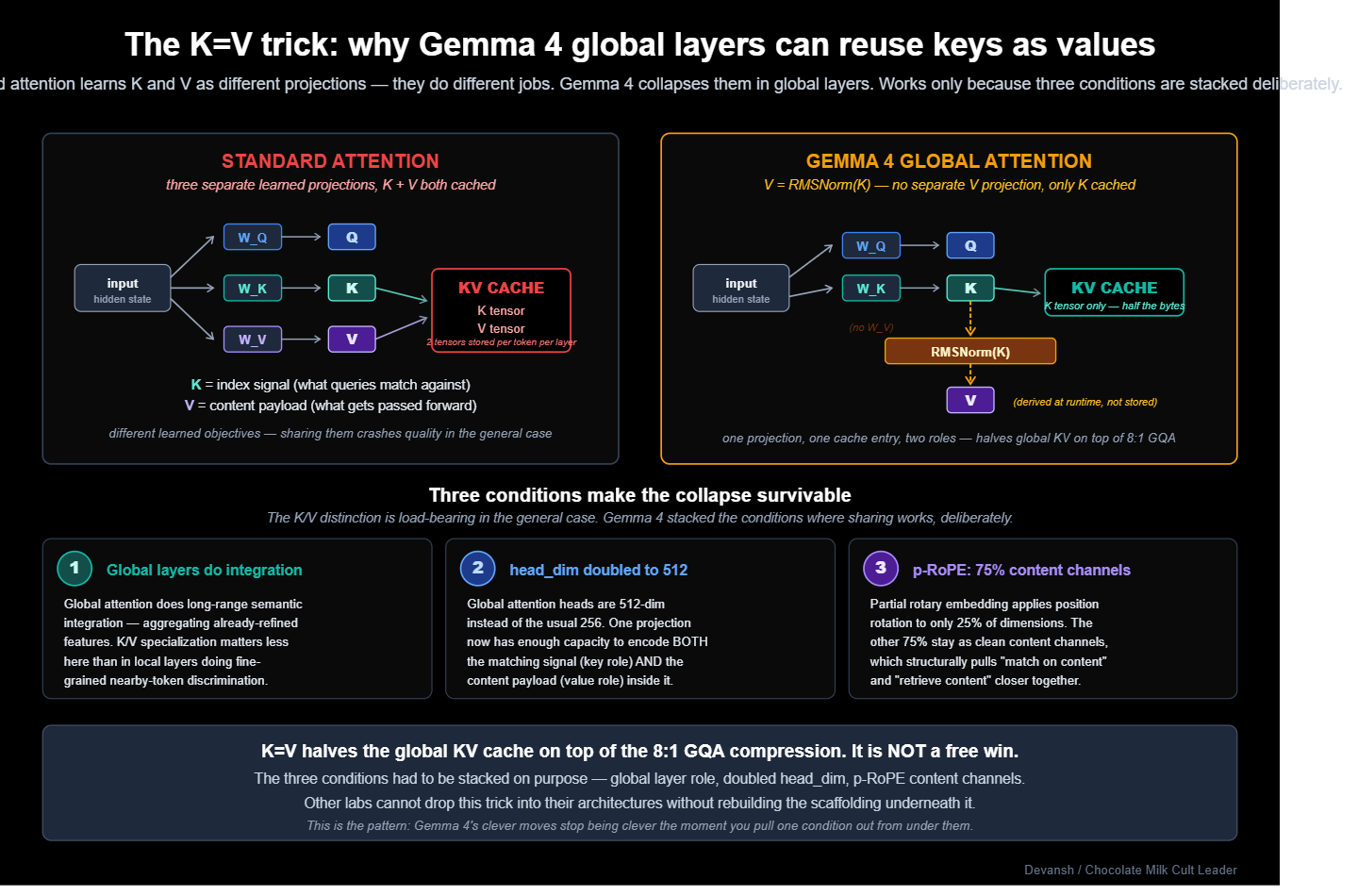
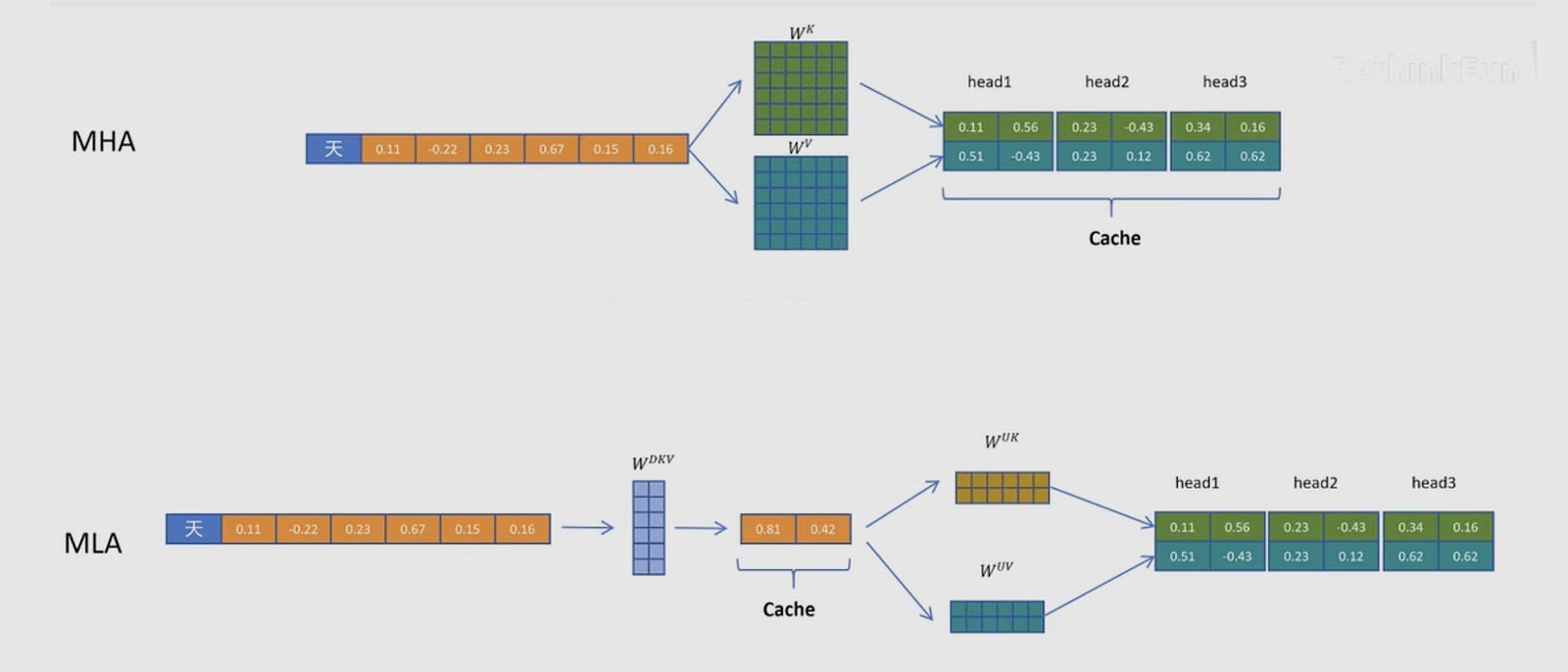
In global attention, the server models deploy one more trick: K=V weight sharing.
In normal attention, K and V do different jobs. Keys are the indexable signal queries compare against; they determine which tokens get attended to. Values are the payload passed forward once attention has selected a token. Think of a search engine: keys are how you index documents for retrieval, values are the document contents themselves. Typically, the mechanism learns these independently because “how to match” and “what to pass forward” are fundamentally different objectives.
Gemma 4 eliminates the V projection in global layers. The key projection is computed, then reused directly as the value, with only RMSNorm applied on the value side as a differentiator in the forward pass. As you might imagine, other architectures will typically avoid this since it nukes your quality. However, Gemma avoids that by building a good system around it:
Global attention does long-range semantic integration where K/V specialization matters less than in local layers doing fine-grained discrimination.
The global
head_dimis doubled to 512, giving each head enough room to encode both matching and content signal in one projection.Partial RoPE leaves 75% of dimensions as clean content channels, pulling “match on content” and “retrieve content” closer together by construction.
This halves the global KV cache on top of the 8:1 GQA compression.
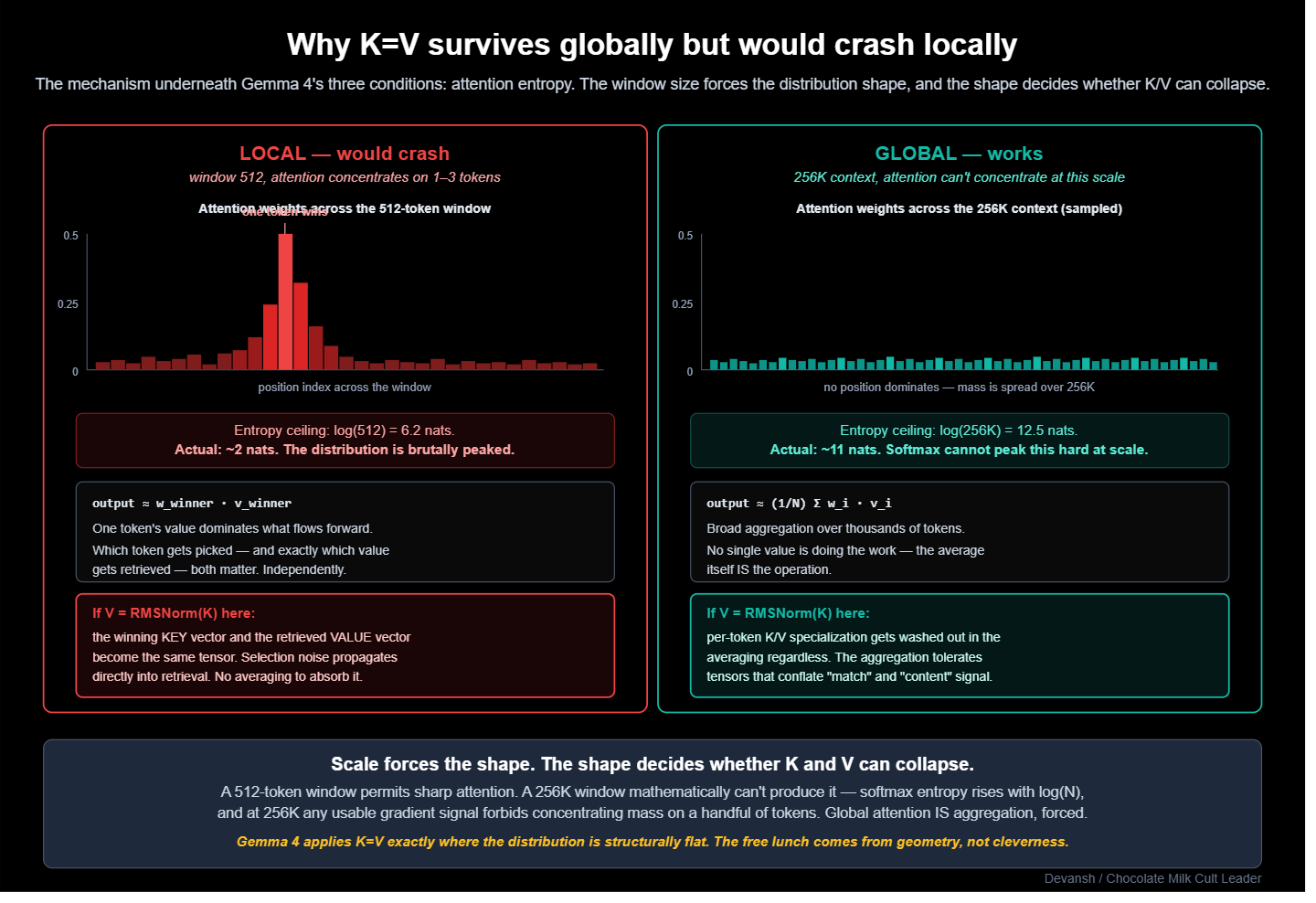
The split b/w server and edge versions of GQA follows the scarcity logic directly: edge has no DRAM, so it compresses everywhere; the server has DRAM for local discrimination, so it only compresses global aggregation.
This adds quite a bit of architectural complexity. Uniform GQA is one number you tune; divergent GQA is four (local edge, global edge, local server, global server) plus the K=V decision, and every combination must be validated against quality. Google paid that cost because the resource flip between edge and server made uniform GQA visibly suboptimal at both ends. Most labs will likely lack the resources to fight on both fronts simultaneously, so they’ll have to pick their specialization beforehand (by considering the constraints/use case) and be mediocre on the other one. Studying Gemma 4s decisions is a good way to understand that.
However, this is the only interesting optimization Gemma 4 uses. Up next, we will cover the one I found most interesting.
How Does Cross-Layer KV Sharing Cut Edge Cache by 83%?
GQA compresses KV within a layer. Cross-layer sharing attacks the vertical axis: why recompute K/V at every single layer in the first place?
Research shows that in the later layers of a trained network, representations converge. By layer 25 of 35, the residual stream has settled into a representation that the model is refining rather than transforming. In another lens, computing fresh K/V projections for layers doing similar work is redundant. On a phone, this redundancy is fatal.
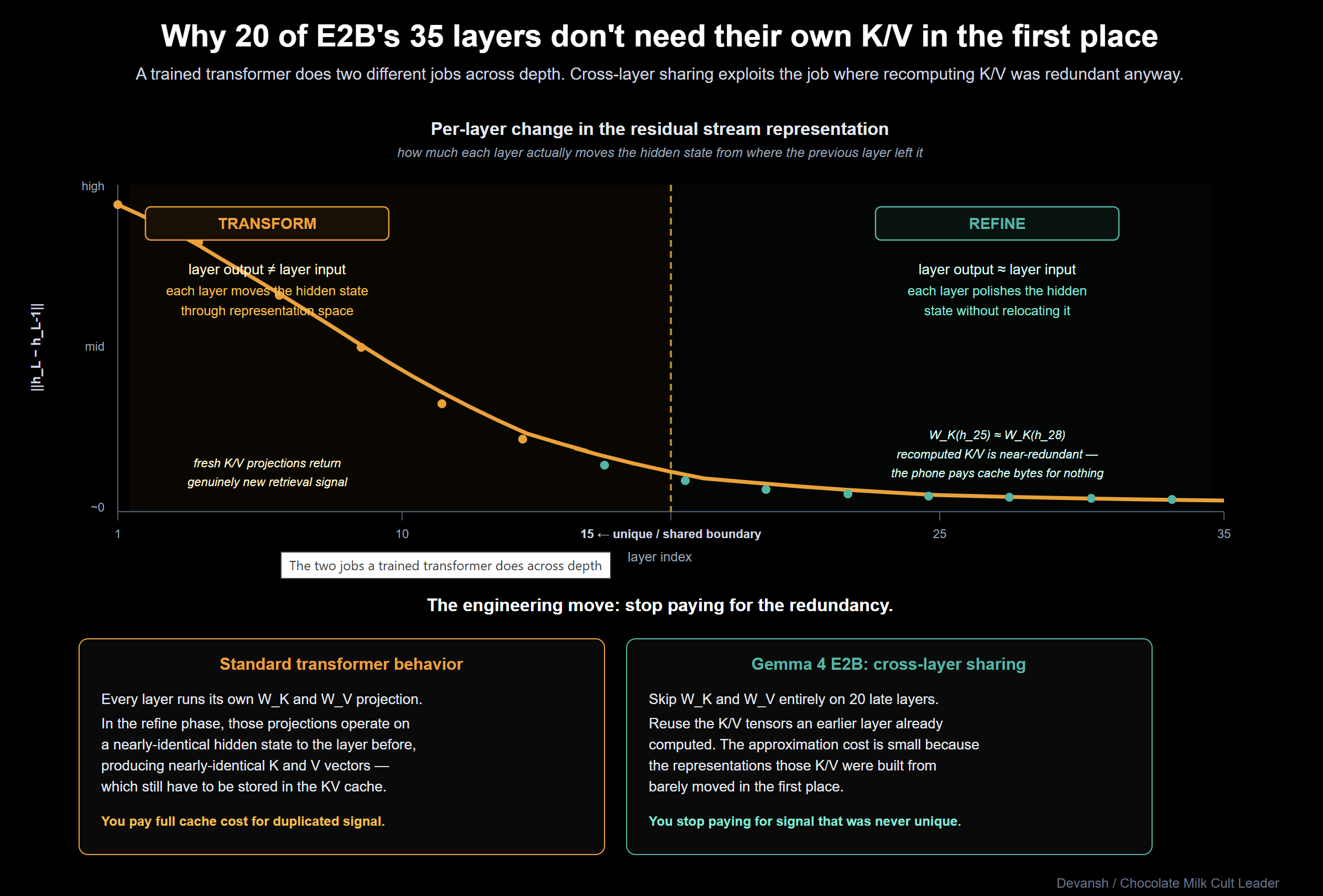
E2B’s fix is to have 20 of its 35 layers skip the K/V projection entirely and reuse K/V from an earlier layer. Only 15 layers compute unique KV. (E4B shares 18 of 42; server models share zero).
The sharing is back-loaded and strictly matches attention types — sliding-window layers only reuse from sliding-window layers; global only reuses from global. You don’t want a local layer’s short-span K/V hijacked by a global layer trying to see 128K of context.
Crucially, shared layers still compute their own Query (Q) projection. Q is cheap: you compute one per token and use it immediately. K and V are the memory killers: they get cached forever so future tokens can attend to them. Sharing Q saves nothing. Sharing K/V eliminates the cache entirely for 20 layers.
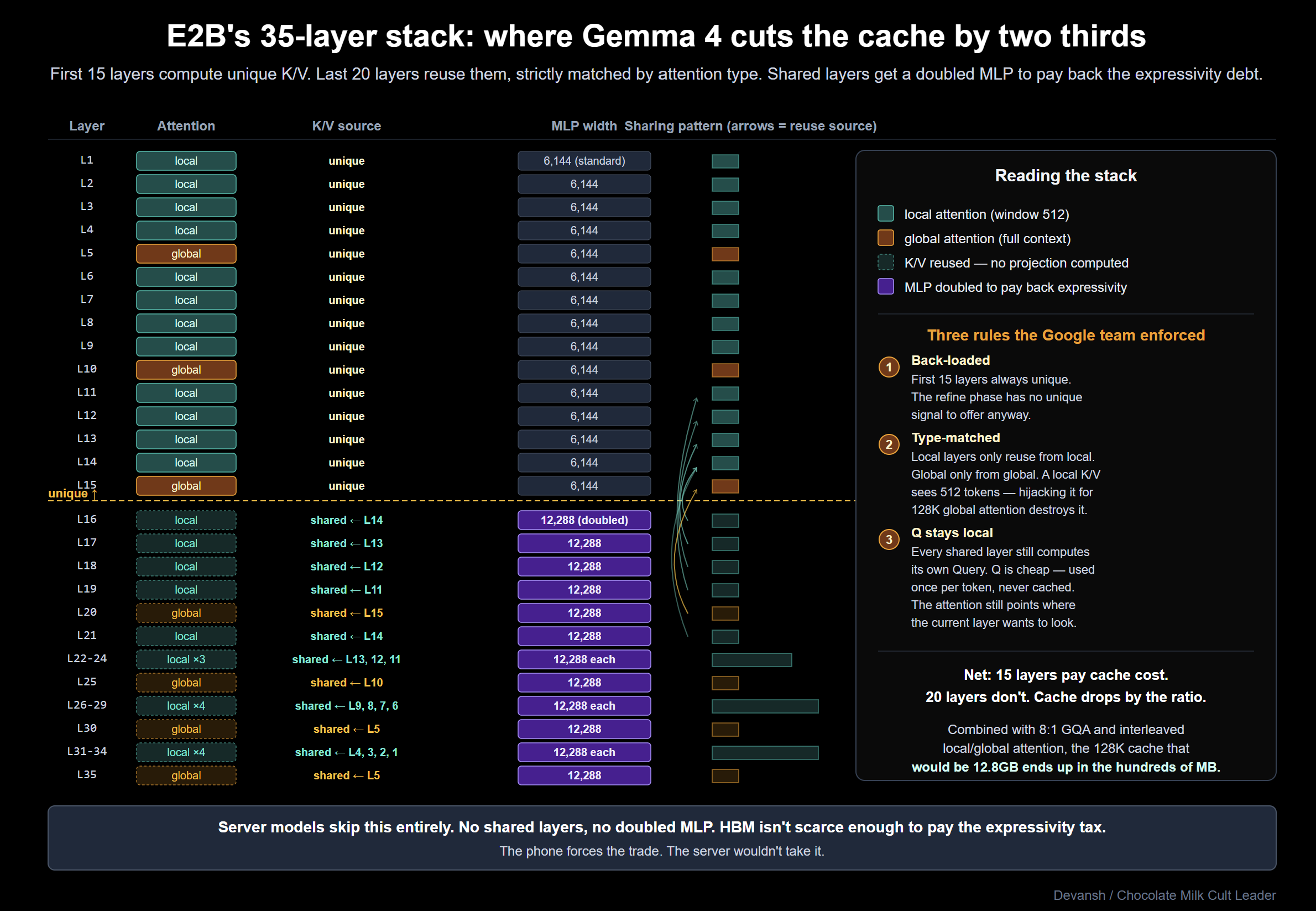
Let’s see how this plays out in hard numbers. A standard 7B transformer at 128K context demands a ~12.8GB KV cache. Combine cross-layer sharing with 8:1 GQA and interleaved attention, and E2B shrinks that cache from tens of gigabytes to hundreds of megabytes. Google’s reported 83% reduction at 8K context becomes an order-of-magnitude reduction at 128K. That is the only reason long-context models run on 8GB phones.
The Quality Tax and the MLP Compensation
This will naturally reduce your generation quality since a shared-KV layer can only attend to a representation shaped by an earlier layer’s objective. It cannot sharpen its own retrieval targets or reshape the payload. To prevent this from gutting model quality, you have to add capacity back. If attention is kneecapped, the Feed-Forward Network (FFN) is your only compensation lever.
On shared layers, Google doubles the MLP width from 6,144 to 12,288.
The math here is revealing. A standard GeGLU FFN at hidden_size 1,536 uses ~28M parameters. Doubling it adds ~28M more. But the K/V projections they removed only cost 1-2M parameters. This discrepancy is caused b/c replicating the cross-token mixing power of attention through a purely feed-forward path requires massive, brute-force capacity.
Why do this when you’re building a model for resource constraints? Doesn’t this beat the point of edge architecture?

Put simply, a wider FFN costs you FLOPs, not bytes. You don’t cache FFN outputs; you compute them, use them, and throw them away. In other words, you spend compute (which you have) to save memory (which you don’t).
Server models skip cross-layer sharing entirely because DRAM isn’t their binding constraint. The quality tax of sharing stops making sense, and the MLP doubling becomes pure parameter waste.
Notice the market convergence here. DeepSeek’s Multi-Head Latent Attention (MLA) attacks the exact same KV bottleneck by compressing K and V into a shared latent space within a layer. Cross-layer sharing skips recomputation across layers. Different axis, same target. The field has unanimously agreed that the KV cache is the primary enemy. It will be extremely interesting to see all the ways people attack the KV cache from various points in the AI stack.
There is one final aspect of the attention mechanism that DeepMind researchers reconfigured to give Gemma 4 it’s insane potency.
How Does Partial RoPE Separate Position From Content?
Transformers match tokens by taking the dot product of their vectors. To prevent the model from losing word order, you have to inject positional data into those vectors.
Rotary Position Embedding (RoPE) does this geometrically: it takes the vector’s coordinates and physically rotates them by an angle determined by the token’s position index. Tokens close together receive similar rotations, so their dot product stays high. Distant tokens rotate away from each other, causing the attention score to naturally decay. Position becomes geometry.
The standard implementation rotates every single dimension in the vector. That was fine at an 8K context window. At 128K, it breaks the model.
When you rotate every coordinate to encode extreme distances, the raw semantic meaning of the token gets distorted. If a query at token 120,000 is searching for a specific fact at token 500, it struggles to match the key because the extreme positional rotation acts as noise, scrambling the pure content signal. Every dimension is screaming its location, leaving no clean channels to communicate what the token actually means.
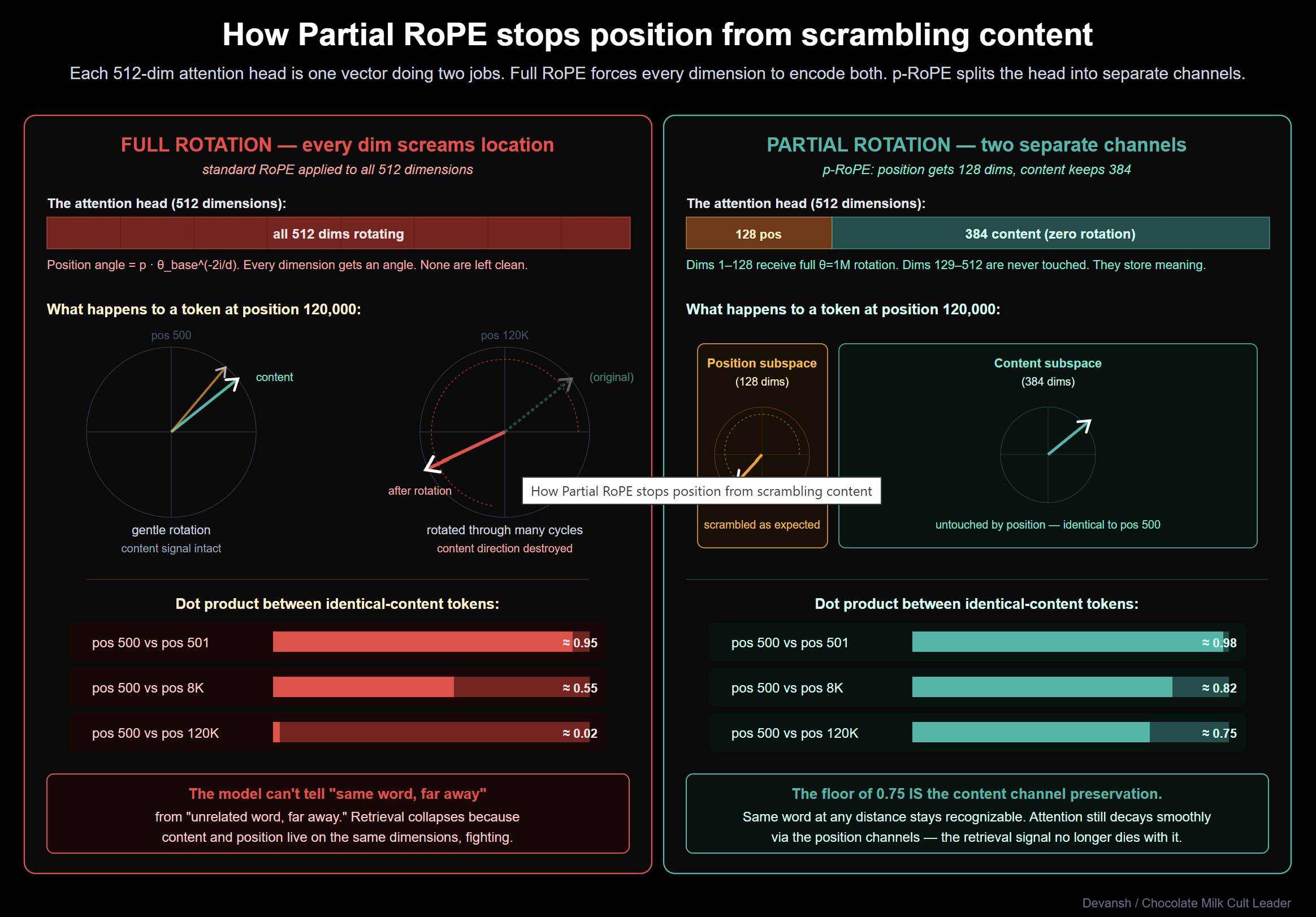
Labs have tried patching this with RoPE rescaling and NTK-aware scaling, but these are workarounds. They don’t fix the underlying flaw of position leaking into content.
Gemma 4’s global layers fix the flaw by adopting Partial RoPE (p-RoPE): they split the vector.
In each 512-dimension global attention head, 128 dimensions (25%) receive the full theta=1M rotation. These are the dedicated position channels, maintaining the geometry of the document so attention decays smoothly over 256K tokens.
The remaining 384 dimensions (75%) receive zero rotation. These are pure content channels. Because they never rotate, semantically identical tokens match perfectly across the entire context window, completely immune to distance. The model stops forcing every dimension to do two interfering jobs.
Google hasn’t published the ablation for the 25/75 split, but the engineering math is straightforward. 128 rotating dimensions provide exactly enough frequency bands to uniquely index 256K positions. Pushing it to 50% sacrifices pure content capacity for positional resolution you don’t need. Dropping it to 10% blurs distant positions together. The 25% mark is the empirical point where position and content both survive.

Local layers skip this entirely. Operating in a tight 512-token window, they stick to standard full-RoPE (theta=10K). Inside a short span, positional resolution is critical, and the rotation distortion never scales high enough to break semantic retrieval. This continues our theme of Gemma 4 winning by specializing it’s archietcture to the system.
The cost of partial rotation is effectively zero — skipping the math on 75% of the vector actually saves minor compute. The payoff is absolute dominance in long-range integration. The 31B hits 86.4% on tau2-bench Retail, obliterating Gemma 3’s 6.6%. While training data and the broader attention redesign contribute, p-RoPE is the specific architectural lever that allows the model to actually retrieve what it reads.
Everything covered so far has been primarily about the edge architecture. The 26B has one design decision worth unpacking, and the 31B ships with one serving-stack problem worth flagging. Both are worth a few paragraphs each.
Why Gemma 26B’s Uses a Hybrid MoE
In a standard Mixture-of-Experts architecture, tokens are routed to a fraction of the available capacity. Mixtral, for example, routes to 2 out of 8 experts, activating about 25% of the network per token.
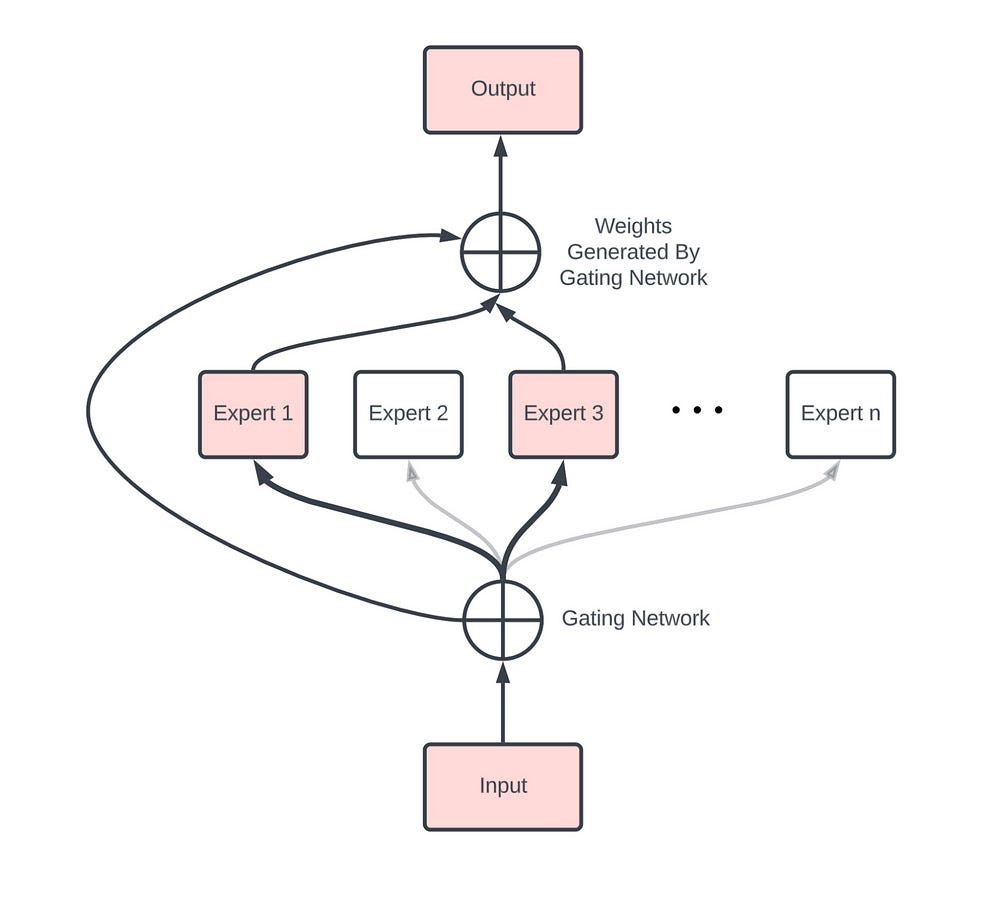
The 26B is much sparser. It uses 128 experts and routes to 8, activating just 6.25% of the network per token.
Normally, this level of sparsity is fragile. When you have 128 experts, routing errors are inevitable. If a token gets sent to the wrong experts, a standard MoE has no fallback, and the output degrades.
Gemma 4 solves this with a hybrid structure. Every token simultaneously runs through an always-on dense FFN (hidden dim 2,112) and its 8 routed experts (hidden dim 704 each). The outputs are then summed.
The dense path acts as a guaranteed quality floor. It processes every token reliably, regardless of what the router decides. If the router picks the perfect experts, they add specialized value on top. If the router misses, the dense path ensures the output remains coherent rather than crashing.
This structural fallback makes the 128-expert count practical. The economic result is that the 26B stores 25.2B parameters but only activates 3.8B per token. You get reasoning quality comparable to a 70B model, but you pay the inference cost of an 8B model.
The Flash Attention 2 Serving Break
FlashAttention-2 (FA2) is the standard kernel powering almost every modern GPU inference stack, including vLLM and HuggingFace. By keeping intermediate calculations in SRAM, it bypasses the massive memory bandwidth bottlenecks of standard attention.
But FA2 has a hard constraint: it only supports head dimensions up to 256.
Gemma 4’s global layers use a head dimension of 512. That width is not a mistake — it is mechanically required to make the K=V weight sharing and the partial-RoPE split work. But it means the global layers break FA2 compatibility.
On pre-Blackwell hardware (like an A100, H100, or RTX 4090), the serving stack falls back to unoptimized Triton kernels for these layers. In practice, throughput drops from an expected 50–100 tokens per second down to roughly 9. That is a 14x performance hit. On newer Blackwell GPUs, optimized kernels recover this throughput to around 124 tok/s.
The software fix is per-layer backend dispatch: routing local layers to FA2, and global layers to a different optimized kernel. As of April 2026, this is still an open issue in vLLM.
Gemma 4 is an architecture shipped slightly ahead of its infrastructure. If you are evaluating it for production on existing hardware today, you need to budget for the throughput hit, or wait for the software stack to catch up.
Conclusion: What Gemma 4 Actually Teaches Us
The current meta in AI is uniform scaling — pushing the exact same architecture across every deployment context (scaled up/down based on your constraints). That approach leaves massive capability on the table. True performance is not found in uniformity. It is found in exploiting the specific topological/ontological structure of the problem you are trying to solve. Phones and servers are not the same problem at different sizes, and treating them as if they are is just engineering convenience mistaken for principled design.
The industry has seen this dynamic before. Mixture of Experts sat on the shelf for decades because uniform dense models were simpler to build, until the economics of scale forced labs to specialize. That exact flip is now happening at the macro-architectural level.
Gemma 4 is one point in a trend that is shaping up in every layer of AI. Chip makers are realizing that they need to bifurcate inference and training, and some are looking further to split based on your workload/modality. Text-style tokenization is failing for vision, requiring rebuilds. Reasoning as a system is being bifurcated into its subcomponents. At every stage, we’re seeing the unbundling of intelligence.
Plan accordingly when thinking about how to navigate these very fun times.
Thank you for being here, and I hope you have a wonderful day,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. :
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819
Incredibly useful and helpful insight!
This is so much more useful than the gemma 4 release party I went to last Friday