
How to get started with MLOps and ML Engineering: AI Engineering at Scale part 1
How to build and deploy Machine Learning pipelines, extend the platform with tools, and implement varied ML services using a lifecycle model.

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
Recently, I partnered with Manning Publications to create a special learning path for the Chocolate Milk Cult. The result was the book, “Engineering AI at Scale: Platforms, RAG, Agents, and Reliability”, a practitioner’s handbook where we compiled insights from various Manning titles to give you one source of truth covering the foundations of ML platforms, prompt engineering, enterprise RAG, AI agents, LLM operations, and reliable deployment strategies.
Don’t worry, I won’t tell you to buy the book. I actually can’t— the book is completely free (get it here). So if you need an comprehensive guide to building production AI Systems at scale, with references to further reading, check it out. We’ll adapt it’s lessons into a series here.
In chaper 1 of this series, we will cover the following—
Understanding ML systems in production
The complete ML life cycle—from experimentation to deployment
Essential skills for production ML engineering
Building your first ML platform
Real-world ML project architectures
Executive Highlights (TL;DR of the Article)
The machine learning (ML) life cycle provides a framework for confidently taking ML projects from idea to production. While iterative in nature, understanding each phase helps you navigate the complexities of ML development.
Building reliable ML systems requires a combination of skills spanning software engineering, MLOps, and data science. Rather than trying to master everything at once, focus on understanding how these skills work together to create robust ML systems.
A well-designed ML platform forms the foundation for confidently developing and deploying ML services. We’ll use tools such as Kubeflow Pipelines for automation, MLFlow for model management, and Feast for feature management— learning how to integrate them effectively for production use.
We apply these concepts by building two different types of ML systems: an OCR system and a Movie recommender. The goal here is to provide you with hands-on experience with both image and tabular data, building confidence in handling diverse ML challenges.
The first step is to identify the problem the ML model is going to solve, followed by collecting and preparing the data to train and evaluate the model. Data versioning enables reproducibility, and model training is automated using a pipeline.
The ML life cycle serves as our guide, helping us understand not just how to build models, but also how to create reliable, production-ready ML systems that deliver real business value.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
1.1 The ML Life Cycle
While every ML project differs, the steps in which ML models are developed and deployed are largely similar. Compared to software projects where stability is often prioritized, ML projects tend to be more iterative in nature. We have yet to encounter an ML project where the first deployment was the end of it.
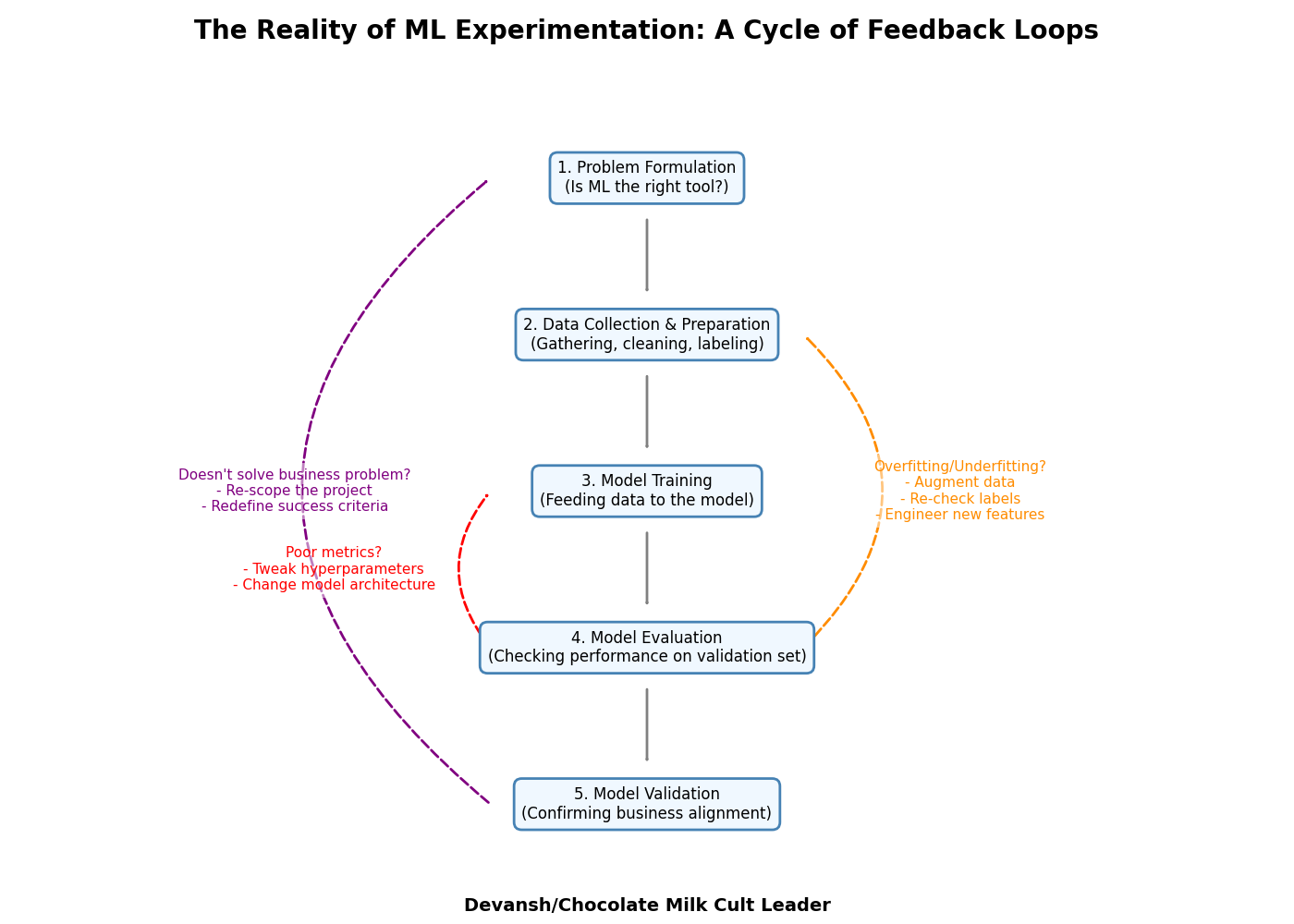
1.1.1 Experimentation Phase
Most ML projects are a series of continuous experiments involving a lot of trial and error as they often require repeated experimentation and finding the right approach depends on understanding complex data and adjusting models to effectively tackle real-world challenges. Figure 1.1 illustrates a typical workflow during this experimental part of the ML life cycle. While the arrows here are pointing in a single direction, there’s a lot of iteration going on in almost every step. For example, say you’re in between the model training and model evaluation step. If the model evaluation metrics are not up to par, you might consider another model architecture, or even go back further and check that you have sufficient high-quality data.

Note that each of these steps can be quite involved, and the flow between them is often non-linear with loops (for example, it is not uncommon to go back to data preparation after running the model training when there are problems detected with an underlying dataset) This is why each of these steps is assembled into an orchestrated pipeline. Having an orchestrated pipeline builds in automation from the get-go, which frees you from making potential mistakes that might be hard to track. Once we get to the Dev/Staging/Production Phase in section 1.1.2, we will fully automate the entire pipeline.
PROBLEM FORMULATION
The very first question you should ask in any potential ML project is whether you should be using machine learning at all (see this for a guide on how to pick the best approach). Sometimes simple heuristics work, and as tempting as it is, you need to suppress the urge to reach for that proverbial ML sledgehammer. In contrast, while simple heuristics can offer efficient solutions, ML becomes necessary when dealing with complex, high-dimensional data where patterns are intricate and nonlinear, demanding a more sophisticated approach for accurate analysis and prediction.

Therefore, if after thinking long and hard, the team (composed of business/product and technical folks) decides that a ML model is the way to go, then the very first step would be to identify what problem the ML model is going to solve. For example, an optical character recognition (OCR) model extracts identification numbers from identity cards. For fraud detection, it’s being able to pick up fraudulent transactions in a timely manner, while minimizing false positives.
DATA COLLECTION AND PREPARATION
Next, you have to figure out where the data is going to come from because you’ll need this info for training and evaluating the model. In the case of OCR, you’ll need images of valid identity cards (In our case, this is going to be a dataset of a few different ID cards from different countries, since our problem is focused on finding one in a given image). You might even consider generating synthetic data if real ones are difficult to come by. Once you have amassed enough training data (and this depends on several factors such as problem domain, what the model was fine-tuned on, etc.), you need to label them with annotations.

In our OCR example, this means getting annotators to draw a bounding box around the parts you care about (e.g., the identification number) and then inputting the identification numbers by hand. If this sounds laborious to you, it actually is (this is why I fund orphanages for access to a near constant supply of labor). For fraud detection, this could mean labeling transactions as fraudulent when customers complain, but also getting a domain expert to comb through the current dataset, or even possibly developing synthetic data with the help of that domain expert.
Once the labeled data is read, it’ll need to be organized into training, validation, and test datasets.
DATA VERSIONING
ML projects consist of both data and code. Changing code changes the software behavior. In ML, changing the data also does the same thing. Data versioning enables reproducibility. You want to be 100% sure that your model performs as expected given the same data and code.
Code is straightforward to version. Versioning data, however, is a different beast altogether. Data comes in different forms (images, CSV files, Pandas DataFrames, etc), and the ML community has not settled on a tool that has the same ubiquity as Git.
MODEL TRAINING
Model training is the process of feeding the ML model lots of data, and as the model is trained, the model parameters (or weights) get tuned to minimize the error between what was predicted by the model and the actual value.
Once an engineer has defined the dataset and strategy for training, model training can be automated. Having automation from the get-go means that data scientists can easily spin up multiple experiments at one go, and ensure that experiments are reproducible because parameters and artifacts (trained model, data, etc.) are tracked.
People new to ML would often think this takes up most of the time. In our experience, the reverse is true.
MODEL EVALUATION
As the model trains, as a sanity check, you’ll want to evaluate the performance of your model against a dataset that’s not part of the training set. This gives a reasonable measure of how your model might do against unseen data (with caveats!). There’s a wide variety of metrics that can be used, such as precision, recall, Area Under the Curve (AUC), and similar.
You want to pay special data leakage, which is an especially juicy way for ML Teams to get catfished into believing their system works (or maybe it’s the rose tinted glasses that causes them not to think about it?). Data Leakage happens when your model gets access to information during training that it wouldn’t have in the real world.
This can happen in various ways:
Target Leakage: Accidentally including features in your training data that are directly related to the target variable, essentially giving away the answer.
Train-Test Contamination: Not properly separating your training and testing data, leading to overfitting and an inaccurate picture of model performance. This problem
Temporal Leakage: Information from the future leaks back in time to training data, giving unrealistic ‘hints’. This happens when we randomly split temporal data, giving your training data hints about the future that it would not (this video is a good intro to the idea).
Inappropriate Data Pre-Processing: Steps like normalization, scaling, or imputation are done across the entire dataset before splitting. Similar to temporal leakage, this gives your training data insight into the all the values. For eg, imagine calculating the average income across all customers and then splitting it to predict loan defaults. The training set ‘knows’ the overall average, which isn’t realistic in practice.
External Validation with Leaked Features: When finally testing on a truly held-out set, the model still relies on features that wouldn’t realistically be available when making actual predictions.

We fix Data Leakage by putting a lot of effort into data handling (good AI Security is mostly fixed through good data validation + software security practices- and that is a hill I will die on). Here are some specific techniques-
Thorough Data Cleaning and Validation: Scrutinize your data for inconsistencies, missing values, and potential leakage points. Implement data quality checks and validation procedures to ensure your data is representative of the real world.
Feature Engineering with Care: Pay attention to the features you create and their potential for leakage. Avoid features that directly reveal the target variable or are overly dependent on the training data distribution.
Rigorous Code Reviews: Have multiple pairs of eyes review your code to identify potential data leakage pathways, especially in complex preprocessing or feature engineering steps. Having outsiders audit your practices can be a great addition here. Below is a description of Gemba Walks, a technique that Fidel Rodriguez, director of SaaS Analytics at LinkedIn(and former head of analytics at Google Ads) relies on extensively:
Gemba Walks- This was a new one for me, but when Fidel described it, I found it brilliant. Imagine your team has built a feature. Before shipping it out, have a complete outsider ask you questions about it. They can ask you whatever they want. This will help you see the feature as an outsider would, which can be crucial in identifying improvements/hidden flaws.
These processes reduce your Velocity. There is a tension b/w velocity and security present in ML Engineering. The tradeoff between velocity and security is an ongoing one, and it depends on a lot of moving pieces. I’ll drop a mental model for it soon, if you have any insights you want to share, you know how to reach me.
MODEL VALIDATION
If your model passes evaluation, the next step is to ensure the model performs as expected. Oftentimes, this means that validation is performed by business stakeholders that may be different from the team who built the model.
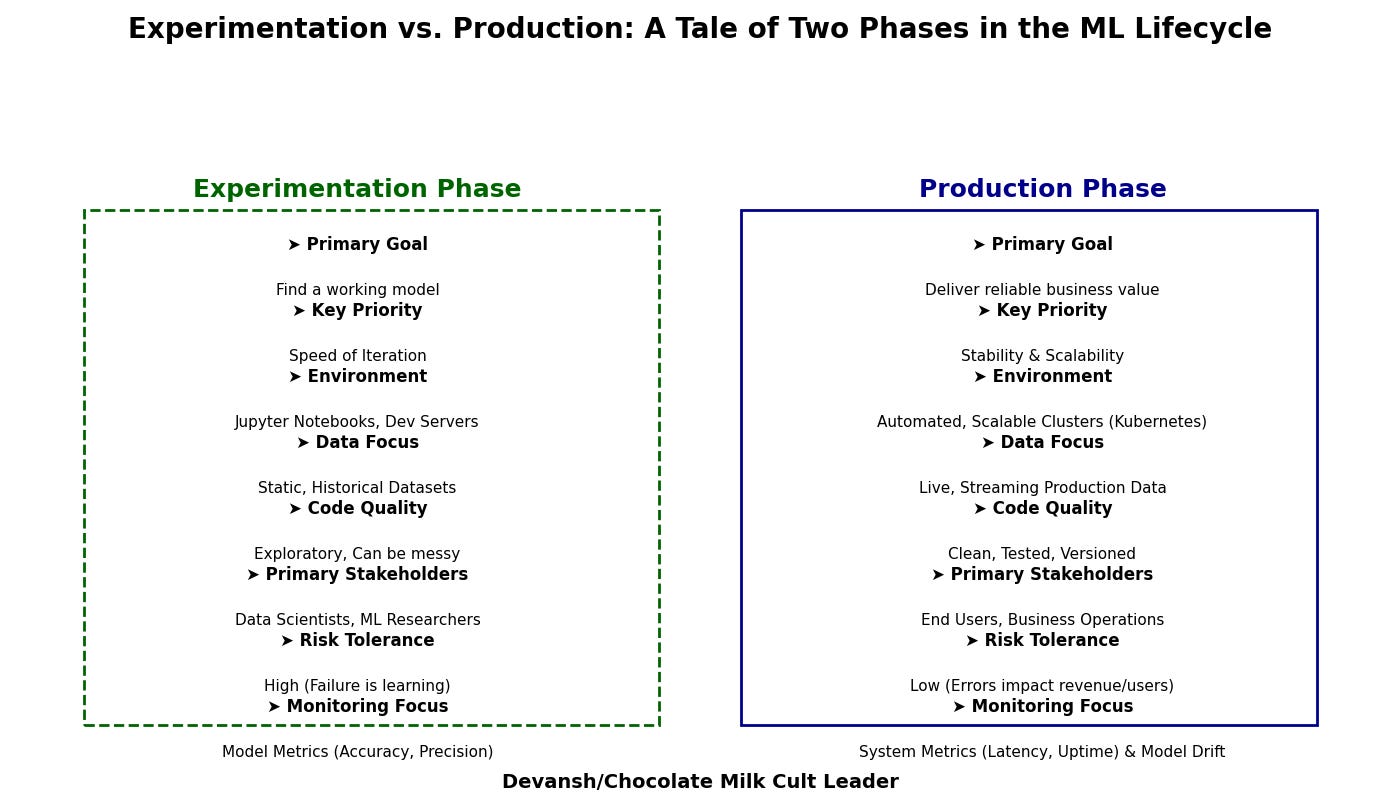
1.1.2 Dev/Staging/Production Phase
The distinction between the Experiment Phase and the Production Phase is critical as it marks the shift from exploring and refining models to deploying them in real-world settings. Understanding this transition is crucial because while experimentation might never be truly over, the focus shifts from pure exploration to maintaining and continuously improving the model’s performance in the production environment, where considerations such as ethical constraints, security, scalability, robustness, and real-time performance become paramount. Recognizing this shift helps in splitting responsibilities and resources needed for both phases, ensuring the smooth deployment and maintenance of ML models.
Once you’re at this stage, you’d have a working model. However, there is still a lot of work to do! For starters, we have not yet deployed the model. But before we get ahead of ourselves, figure 1.2 shows what this stage would look like.
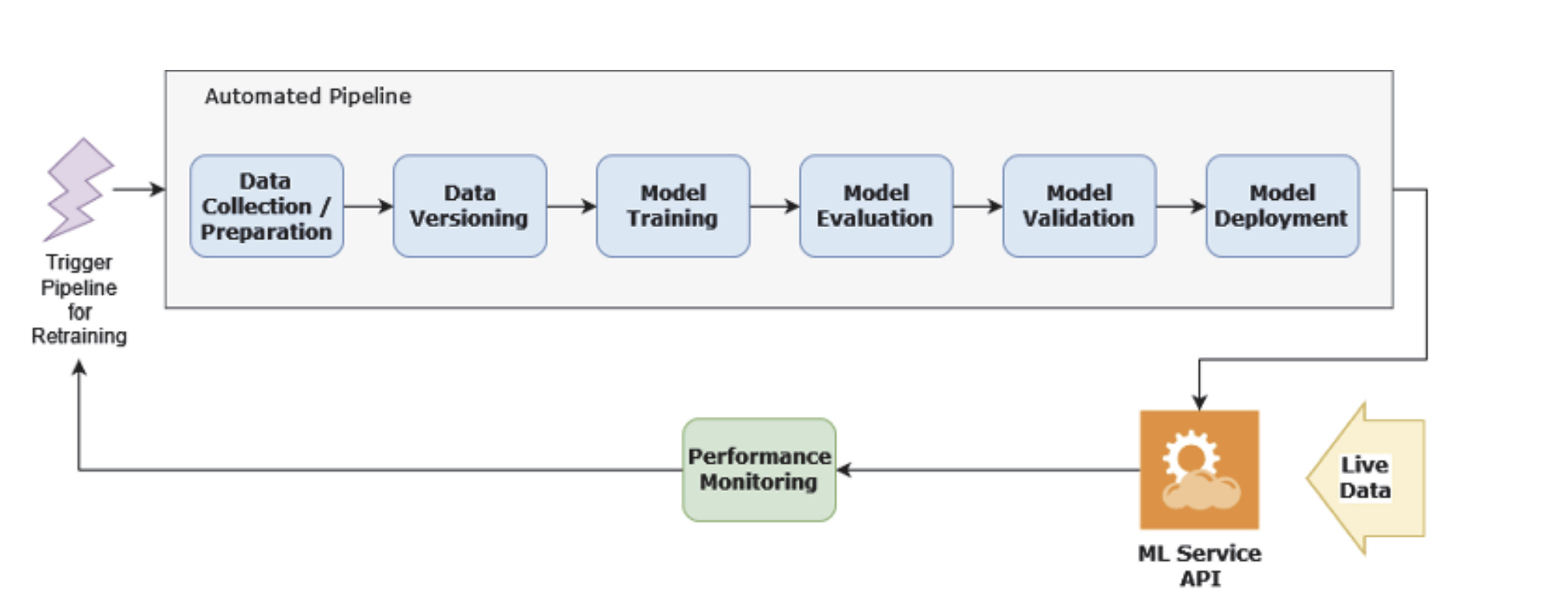
At first glance, this figure looks quite similar to figure 1.1. Pieces such as data versioning, model training, model evaluation, and model validation feature in both figures. During the experimentation phase, you would have an orchestrated pipeline that is more or less automated. In this phase, you’ll want to make it completely automated.
A trigger can come from continuous integration (CI) or some form of programmatic invocation. This then kickstarts the pipeline steps in succession. What’s new here is that at the end is model deployment. The result from this step is a deployed ML service, usually in the format of a REST API. Oftentimes, you also want to set up some sort of performance monitoring. In more sophisticated use cases, if performance metrics fall below a certain threshold, the trigger fires off again, and the entire process repeats.
MODEL DEPLOYMENT
Once you have a trained model that performs reasonably well, the next logical step is to deploy it so that customers can start using it. At some organizations, this is where hand-off to IT or DevOps/MLOps happen. However, we’ve seen a lot of benefits in getting the data scientists involved, too.
One of the simplest ways of model deployment is slapping on a REST API that performs model inference. The next step would then be containerization with something like Docker, then deploying it on a cloud platform like AWS or GCP. However, deployment doesn’t mean the job is done. You’ll need to perform load testing to ensure the service can handle the expected load. You might also need to think about auto-scaling should your service encounter spiky loads. Each model deployment needs to be versioned, too, and you’ll need strategies for rolling back in case things go wrong.
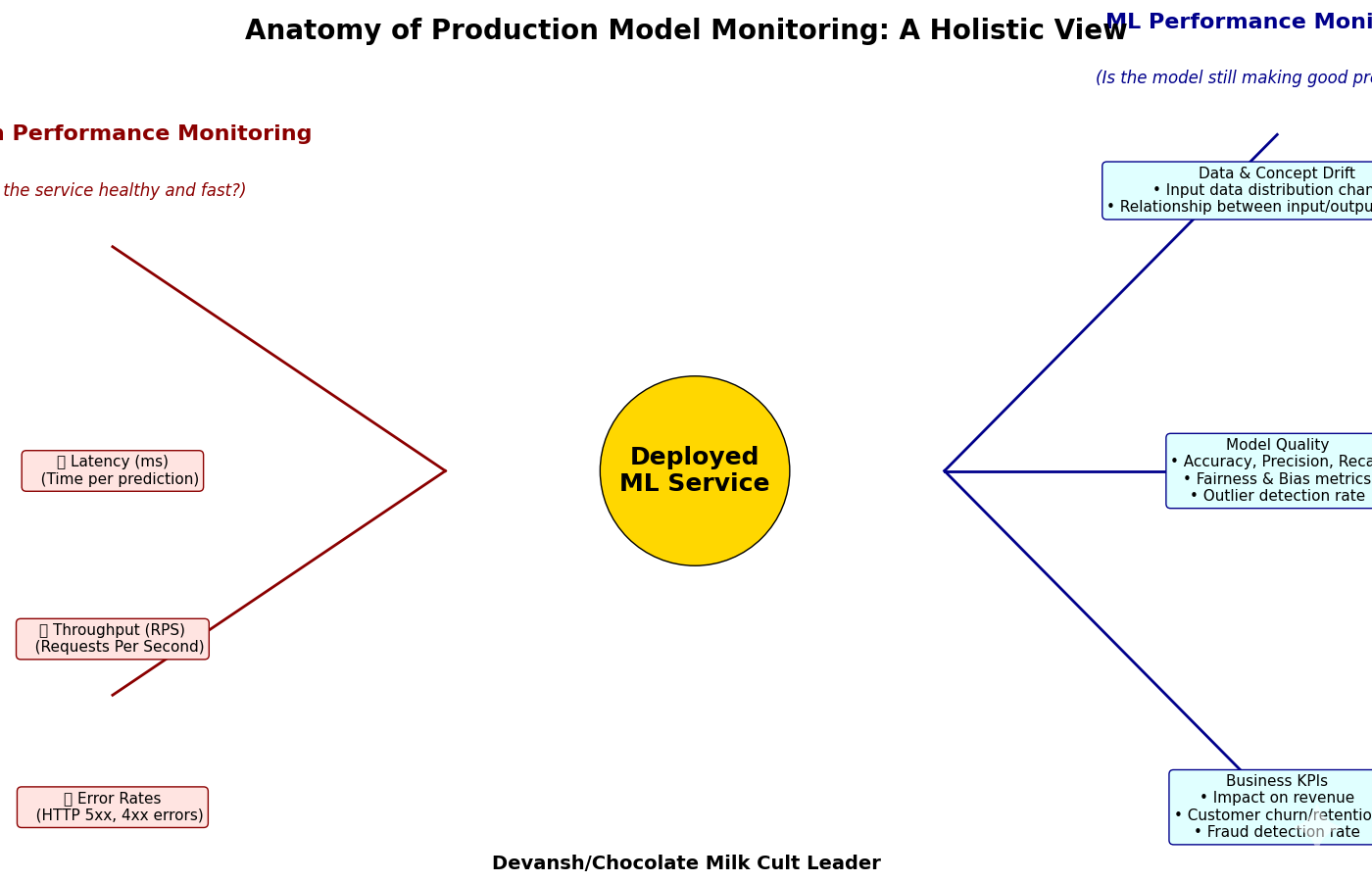
MODEL MONITORING
ML models often don’t survive first contact. Usually when your model hits production and encounters live data, it will not perform as well as during model evaluation. Therefore, you’ll need to have mechanisms to measure the performance of your model once it hits production. There are two major classes of things that should be monitored. There are performance metrics that measure things such as requests per second (RPS), counting HTTP status codes, and similar. For ML projects, it is also important to measure things such as data and model drift, because they can adversely affect model performance if left unchecked, as well as critical business metrics designed to measure the value the model brings, such as customer churn and retention rate.
MODEL RETRAINING
Even the most robust models might need model retraining from time to time. How do you know when a model should be retrained? As with so many complex questions, it depends.
However, when models need to be retrained, they should be as automated as possible. If you have automated pipelines during model training, you’re already off to a great start. However, that’s not all. You’ll also want to automate model deployment, too, so that once a new model gets trained, it can also be automatically deployed. Model retraining can be triggered either via a fixed schedule (like every month) or whenever some thresholds are met (like the number of approvals for a loan has suddenly decreased sharply).
1.2 Skills needed for MLOps
Building confidence as an ML engineer requires mastering a combination of skills across different domains. While this might seem daunting at first, remember that you don’t need to be an expert in everything from day one. What’s important is understanding how these skills fit together to create reliable ML systems (figure 1.3).
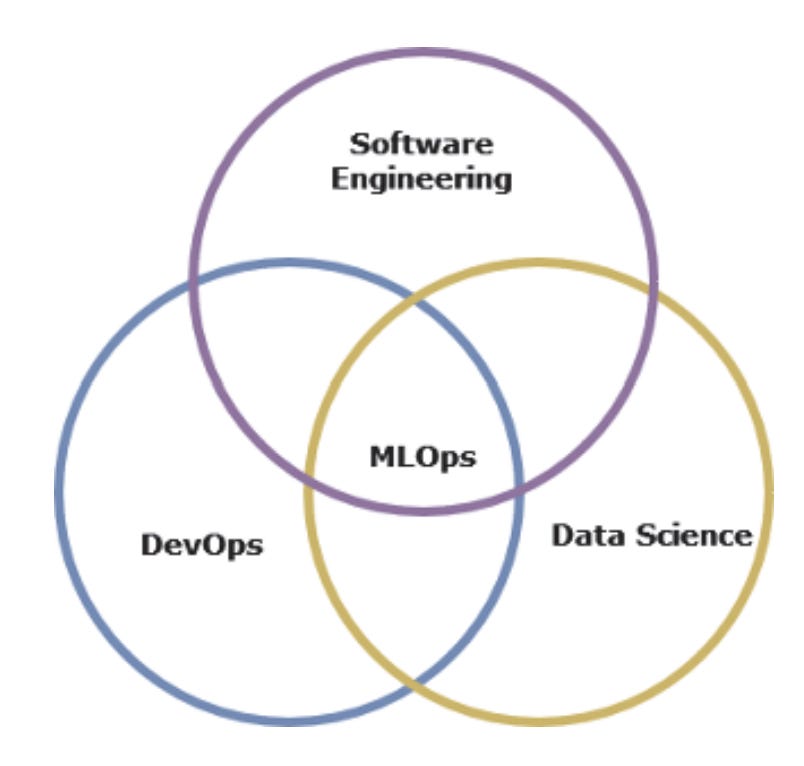
We will walk you through real examples that will demonstrate successful applications of each domain. But here’s what you’ll need to know coming in.
At the very core, you must be a decent software engineer who has successfully deployed a wide range of nontrivial software systems. This could range anything from mobile applications all the way to enterprise systems. You must be adept at debugging (as things will most definitely go wrong!) and know where to identify performance gaps and fix them.
The next prerequisite is the understanding of machine learning and data science. While this is organization specific, the ML engineer doesn’t need to be an expert in ML algorithms or know things like the nitty-gritty details of back-propagation. However, you must be comfortable working with common ML frameworks such as Tensorflow/PyTorch/Scikit-Learn and be unfazed in picking up new and unfamiliar ones.
If you’re looking for a good basis on what you need to know, check our deep-dive on how to learn AI (which contains insights on what you need to know as well) over here—
How to learn AI (or anything technical) in 2025

Every month, the Chocolate Milk Cult reaches over a million Builders, Startup Founders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission
Knowing how to build ML models is one thing; understanding the ML life cycle and appreciating its complexities and challenges is another. Most ML practitioners would agree that data-related challenges are often the trickiest, getting adequate training data of decent quality being the most notable. This requires a certain measure of data engineering skills.
A large part of MLOps is automation. Automation reduces mistakes and enables quicker iteration, and therefore faster feedback. Automation is also crucial in MLOps because experiment reproducibility becomes very important as you’d want your model to perform the same across Dev/Staging/Production environments, but it becomes critical when your ML model is subjected to regulatory compliance and auditing. Ultimately, reproducible results lead to trust.
There are a lot more skills that MLEs are expected to know or pick up, but this is a good start.
1.2.1 Prerequisites
Do not be discouraged if what you’ve read so far sounds daunting. Much like the famous quote about eating an elephant, the best way to handle complexity is to tackle a little piece at a time. The problems that you encounter can often be broken down into manageable pieces. In other words, this range of skills is not needed all at once, nor do you need to know everything.
To prepare you for the upcoming topics, we’ll take a whirlwind tour of MLOps tools, but more importantly, we’ll take you through the bare basics of Kubernetes. If you are already familiar with Kubernetes, feel free to skim or skip the section altogether. We think that this is valuable to tell data scientists, who want to get started quickly without being bogged down by unnecessary detail. These skills will equip you to set up your own ML platform, which will then enable you to build ML systems on top of it.
1.3 Building an ML platform
A well-designed ML platform is key to confidently developing and deploying ML services. Think of it as your foundation for building reliable ML systems—it provides the tools and infrastructure needed to handle all essential parts of the ML life cycle. While an ML platform consists of multiple components, don’t let that intimidate you. We’ll build it step by step, understanding each piece as we go.
Figure 1.4 is an example of an ML platform architecture. The area outside of the dotted line boundary is where most of your other data systems sit. They could be the data warehouse/lake, batch/streaming processors, different data sources, and so on. These are not ML platform specific; therefore, we won’t delve into too much detail, although we will cover a little about data processors such as Spark and Flink because they are at the periphery of the ML platform.
The area within the dotted lines is where the fun begins. To build a ML platform from scratch, first, we need to set up Kubeflow, an open source ML platform on Kubernetes. One of the core components of Kubeflow is Kubeflow Pipelines, which provides the pipeline orchestration piece.
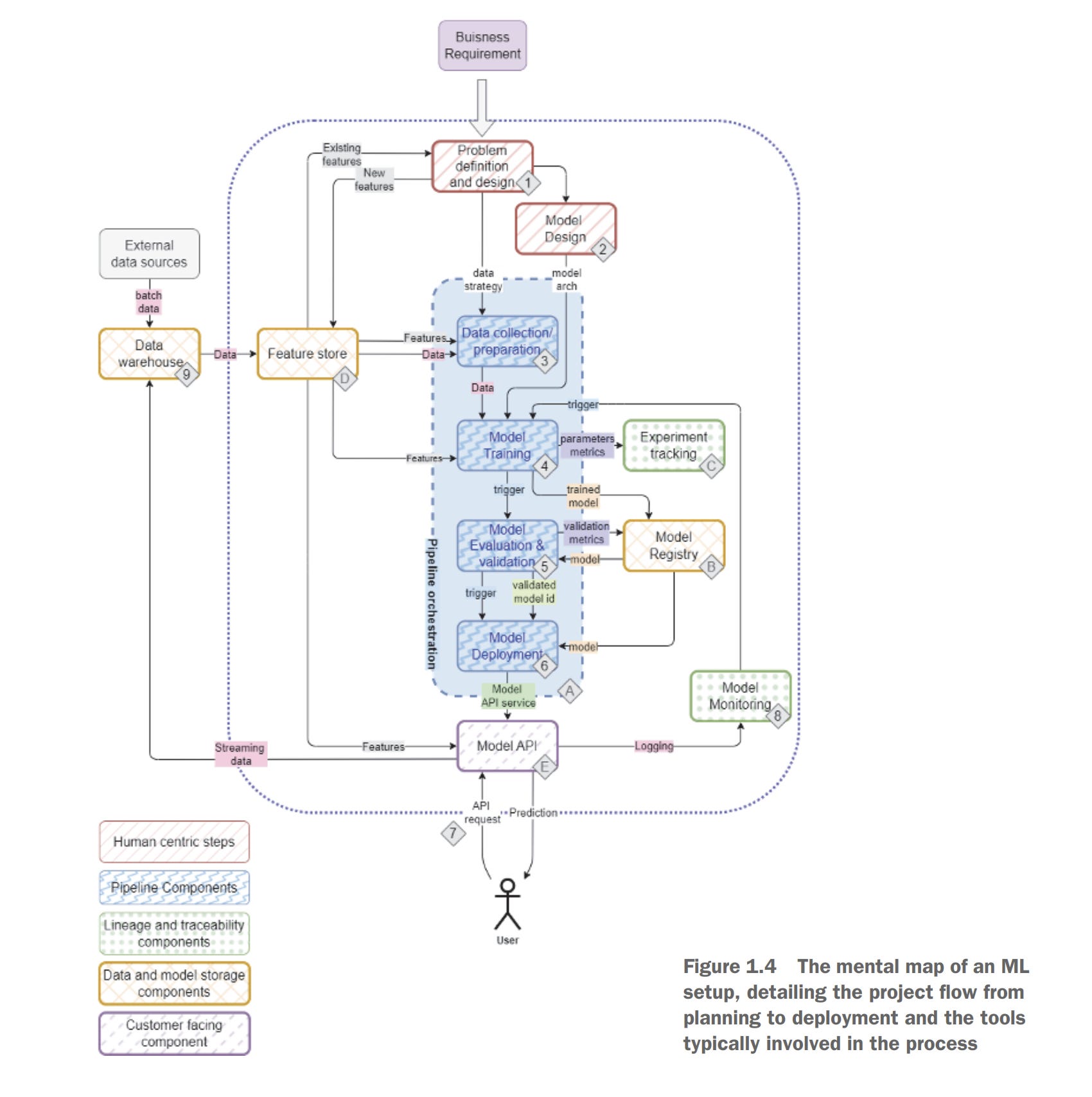
In the figure, infrastructure is tagged with a letter, and data components are tagged with a number. The order denotes the natural flow of how the components are introduced, as well as a normal flow of data in the pipeline.
Don’t worry if this seems too overwhelming! We’ll walk you through installing Kubeflow, followed by introducing its various features, starting with Jupyter Notebooks and then Kubeflow pipelines. Next, you’ll learn how to grow the ML platform. This will be driven by use cases where Kubeflow falls short. For example, Kubeflow doesn’t come with a feature store, an integral piece of software that stores curated features to train and serve ML features.
There is no one-size-fit-all ML platform architecture!
While we present an ML platform architecture, and even though we’ve been using this successfully in our respective organizations, there is no one-size-fit-all solution! The approach we’re taking in this book is to grow your ML platform incrementally, and this is what we heartily recommend when you embark on your MLE journey especially if you’re building it from scratch. Once you get experience putting an ML platform together by following through this book, you’ll be in a much better position to build your own ML platform that would fit the needs of your team and your organization.
1.3.1 Build vs. buy
In your organization, you might have already settled on an ML platform from a vendor such as SageMaker (if you’re on Amazon Web Services) or VertexAI (if you’re on Google Cloud), and wondering if you really need to go through the pain of setting up an ML platform.
We think it’s extremely valuable to go through setting up an ML platform from scratch at least once and grow the ML platform by integrating it with various open source libraries. We think that learning how to put together an ML platform and customize it to your own needs is an important skill to have and something that is not often covered anywhere else.
By the end of the exercise, you will gain a much deeper understanding of how the various tools in the ML platform work together and also overcome limitations when you encounter them.
A word about tool choices
Developers often have strong opinions about tool choices, and the ML space offers no shortage of options. The tools we recommend are not definitive solutions but starting points. We encourage you to experiment—try a tool for a few days with a proof of concept to determine whether it suits your needs. Early experimentation can reveal limitations that might otherwise become dealbreakers later.Here, we use different tools for the same objective, such as handling data drift, selecting the most suitable tool based on the specific use case. Our recommendations focus on open source tools with strong community support that have proven effective in production. Of course, we’ve had to customize them at times—that’s just part of being an MLE.
1.3.2 Recommended tools
It is not an exaggeration to say that the MLOps landscape is inundated with tools. We have stuck to what we think are the more stable choices and the ones we have had the most success using. While your mileage may vary, we still think this serves as a good starting point. The following lists the major tools that you’ll come across as you work through the project. We’ll go into detail about each of them later on, but it’s useful to get an overview of these.
ML PIPELINE AUTOMATION
To implement the MLOps life cycle, you’ll need tools for ML pipeline automation to glue all the stages together. We will use Kubeflow pipelines as an opinionated choice of tool that works well from our experiences, but there are other options that may work better for you. In Kubeflow pipelines, each stage in the ML life cycle is represented by what is called a pipeline component. Each pipeline component could potentially take data from a previous component and pass data along to downstream components once it completes its task (figure 1.5).
FEATURE STORES
Feature Stores have come to be an indispensable part of ML platforms. One of the core benefits of having a feature store is for data scientists and data analysts alike to share features, thereby saving time having to recreate them. These features can be used both for model training and model serving.
Feature stores come into play in the Data Collection and Preparation Phase. Figure 1.6 shows how feature stores take in data that has already been transformed, whether it’s simple data operations all the way to complex data manipulations requiring multiple joins across multiple sources. This transformed data is then ingested by the feature store.
Under the hood, most feature stores contain a
Feature server to serve features whether by REST or even gRPC
Feature registry to catalog all the features available
Feature storage as the persistence layer for features
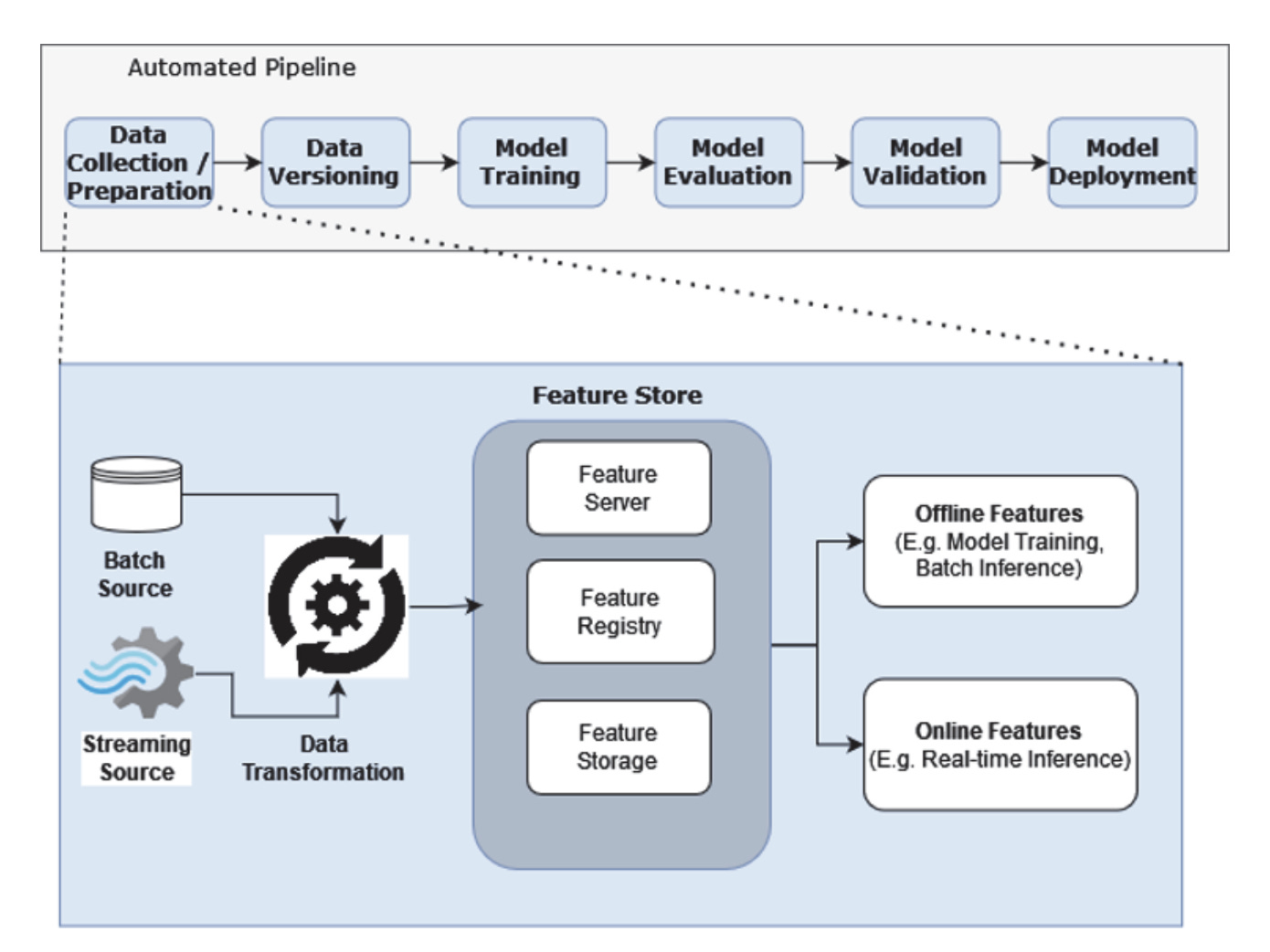
The feature store serves features in two modes: offline mainly for model training/batch inference, and online for real-time inference.
There is another big benefit of feature stores when you can serve features offline versus online, and that is to prevent training-serving skew. This phenomenon happens when there might be a discrepancy during the training phase versus what is seen during inference. How could this happen? One example could be a difference in the data transformations occurring during training compared to what is done during inference. This is a very easy thing to overlook, and feature stores very neatly solves this pain point. We will explore feature stores more in the coming chapters where you’ll learn to exploit them in your ML projects.
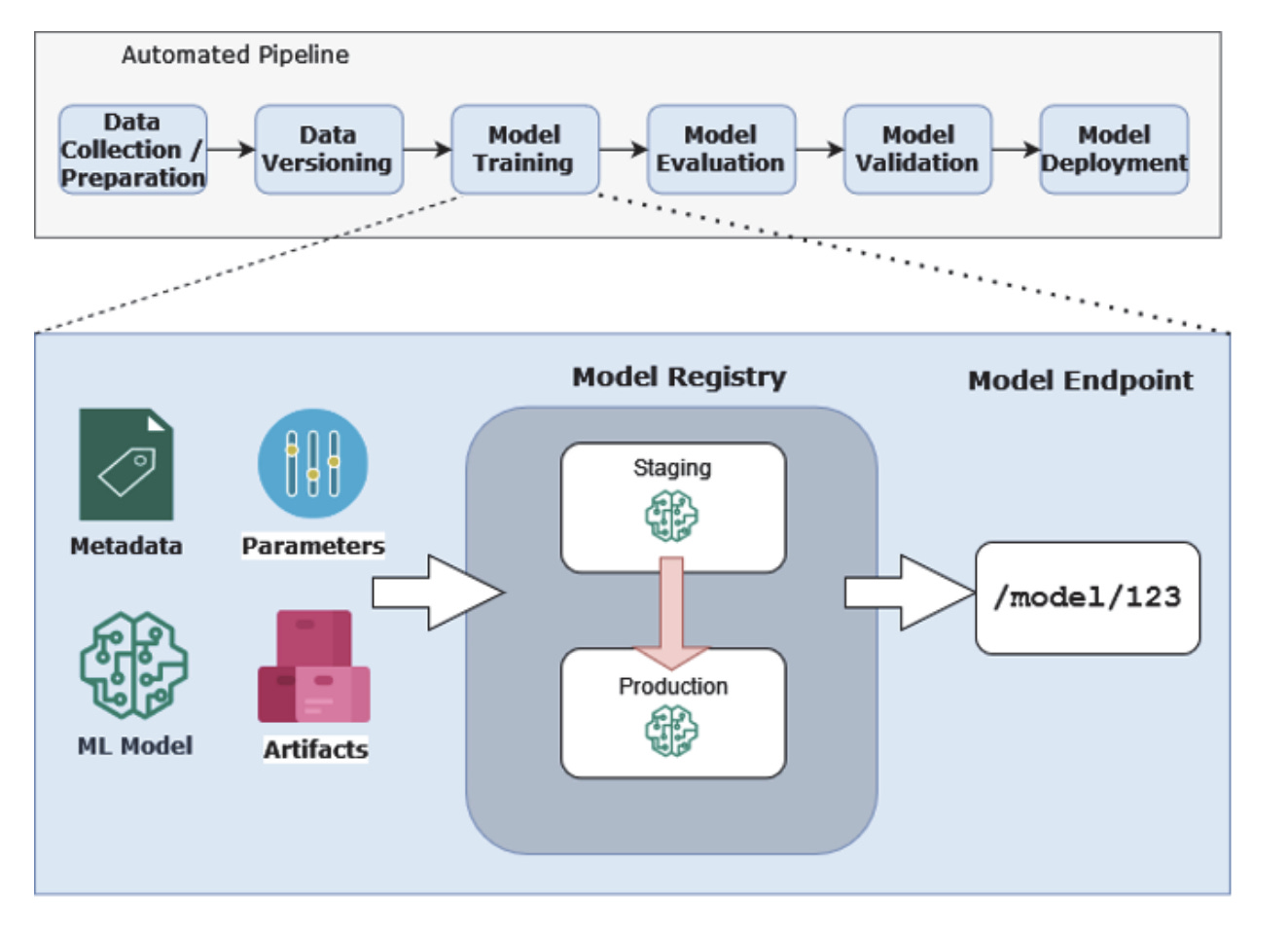
MODEL REGISTRY
The outputs of a model training run include not only the trained model but also artifacts such as images of plots, metadata, hyperparameters used for training, and so on. To ensure reproducibility, each training run needs to capture all the things mentioned above.
One of the use cases that a model registry enables is to promote models from staging to production. You can even have it set up so that the ML service serves the ML model from the model registry (figure 1.7).
MODEL DEPLOYMENT
Model deployment is integrating a model into a production environment (this could be your Dev/Staging environment, too) where it can receive input and return an output. In essence, model deployment is making your model available for others to consume.
Model deployment is very much engineering-centric. You have to think about portability (usually solved with containerization), scalability (with Kubernetes, you can potentially scale the ML service with multiple replicas), performance (would the model benefit from GPUs/better CPUs and more RAM), and reliability. Ideally, you’ll want to automate this as much as possible using CI/CD (Continuous Integration and Continuous Delivery/Deployment). For example, each time code changes, you’d want CI/CD to build and deploy a new ML model (figure 1.8).
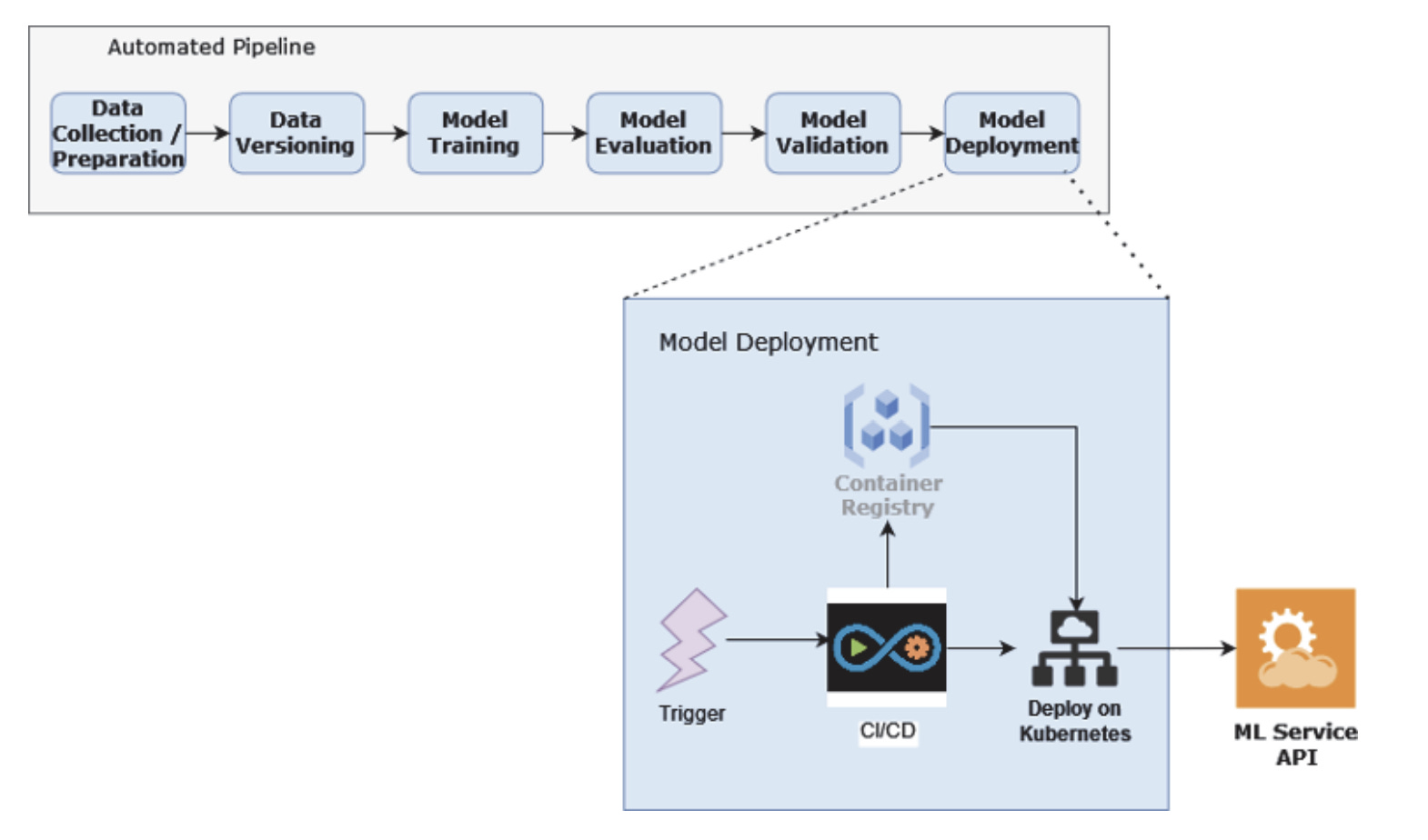
The figure demonstrates how automated model deployment can be set up. A trigger to CI/CD would automatically build the Docker container for the ML service and push it to the container registry. After that, the Kubernetes deployment manifests can be created that reference the Docker image that has just been built. Applying these manifests would then result in the updated ML service being deployed. Of course, we’re leaving out quite a bit of detail here, but you’ll see how all these fall into place once we get to the model deployment sections of the respective projects.
1.4 Building ML systems
With a solid ML platform as our foundation, we’re ready to tackle real-world ML projects with confidence. We’ll present two distinct types of ML systems that showcase different challenges you’ll encounter in production: one dealing with images and another with tabular data. These projects will help you build confidence in handling diverse ML challenges, while reinforcing the patterns and practices that make ML systems reliable.
It is highly likely that either or none of the projects match the problems that you are handling in your organization, but we’re willing to bet if you look past the superficial differences, you’ll find a lot of commonalities that can be applied to your project, which is the entire point of introducing the projects. As you work through the projects, imagine that we are in a pair-programming setting or in a room thinking through system design.
We’ll work through each of the essential parts of the ML life cycle and finish off with the more operational side of things, namely monitoring (both the data and model), and model explainability.
1.4.1 Introducing the ML Projects
One of our core aims here is to provide you with as close to a real-life experience as possible in building ML systems from start to finish. To that end, we present you with two projects. In them, we take you through the full ML life cycle, from data preparation to monitoring and finally model retirement. The projects aim to give you a breadth of experience across common ML flavors, and while we may not cover every kind of ML project, we believe that the projects we’ve selected are a good representation of ML problems in the real world.
Certain tools will be used again (such as Kubeflow pipelines), while in other instances, we’ll consider the challenges and shortcomings of the previously introduced tool and offer an alternative. Each project will follow the ML project life cycle and progressively introduce the different tools as our use cases grow. The projects are also designed to reinforce the following observations:
ML projects are seldom linear and instead highly iterative. Sometimes, you’ll have to revisit previous steps, reconsider assumptions and rethink models. For example, when a model doesn’t do as well as expected during training, it might be that you have to revisit the data preparation step. We’ll try to bake in scenarios like that, too, so you’ll get to experience for yourself which parts need to be tweaked and how to do it.
Project requirements change over time as the project naturally evolves. This usually means reconsidering the current solution and being creative in exploring other tools and techniques.
The core MLOps concepts are vital in almost any type, domain, or stage of a large-scale ML project. Depending on the context, some steps may be skipped or combined with others, but thinking along the lines of these core concepts helps provide structure to large ML projects and in our experience provides a good engineering framework.
These projects are inspired by some of the ones we’ve encountered at our work, albeit a slightly stripped-down version. However, the steps and the thought process are almost identical, and we’re confident that you’d be able to apply them to your projects, too.
PROJECT 1: BUILDING AN OCR SYSTEM
OCR is a very common use case for ML systems. In this project, we’ll start with the problem statement of detecting identification cards. We’ll figure out how to build out a dataset and then train an image detector that can detect identification cards. Next, we’ll use an open source library to build out an initial implementation and then fine-tune it with a labeled dataset. Finally, we’ll deploy it as a service.
PROJECT 2: MOVIE RECOMMENDER
The second project will be a movie recommendation service. While the steps and core ideas remain the same as the OCR example, tabular data has some interesting nuances and tooling requirements. Tabular data also makes it easier to illustrate some concepts such as feature stores, drift detection, model testing, and observability. Tabular data also has the advantage of being already in a numerical (or it can be easily converted to a numerical feature) format.
If you’re bored of these, we have a guide to figuring out projects that will help you stand out by building practical skills used in IRL work. You can see them here—
How to build a side-project to get a job in Machine Learning

“Hey Devansh, I’m trying to get my first job in Machine Learning, any advice?”.
Thank you for being here, and I hope you have a wonderful day,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. :
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819
Thnx for this post. This comment is a bit of a repeat from one I made on your post of the second chapter. I think the authors were mislaid as the original chapter (from Build a Machine Learning Platform - From Scratch (Ch.1) titled Getting started with MLOps and ML engineering was re-compiled (the Manning Engineering AI at Scale compilation). I think the source lists Tan Wei Hao, Benjamin, Padmanabhan, Shanoop, and Mallya, Varun as authors. The second compilations only mentions Tan Wei Hao, Benjamin in a blurb before the chapter, not in the front matter (unless I missed it), and your post mentions none of them (again, unless I missed it). It Would be great to see them properly credited — both for readers who want to dig deeper into the source material, and because they did a the heavy lifting. I always urge authors I work with to be fastidious in crediting their sources and hope they can receive the same. Crucial for young authors getting started. Example only:
Tan Wei Hao, Benjamin, Padmanabhan, Shanoop, & Mallya, Varun. (2025). Getting started with MLOps and ML engineering (from Build a Machine Learning Platform—From Scratch (Ch.1). In Devansh Devansh (Pasha) & Manning (Eds.), Engineering AI at Scale: Platforms, RAG, Agents, and Reliability (Online). Manning Publications.
Thanks for making this content more accessible either way. Leo
The learning path is very cool!