
LeCun’s Alternative Future: A Gentle Guide to World-Model AI [Guest]
An accessible walkthrough of the architectures beyond today’s LLMs—and how they reshape what it means to co-create with AI.


It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
Barak Epstein has been a senior technology leader for over a decade. He has led efforts in Cloud Computing and Infrastructure at Dell and now at Google. Currently, he is leading efforts to leverage Parallel Filesystems to AI and HPC workloads on Google Cloud. Barak and I have had several interesting conversations about infrastructure, strategy, and how investments in large-scale computing can introduce new paradigms for next-gen AI (instead of just enabling more of the same, which has been the current approach). Some of you may remember his excellent guest post last year, where he talked about how it was important to go beyond surface level discussions around AI to think about how advancements in AI capabilities would redefine our relationships with it (and even our own identity about ourselves and our abilities).
Barak combines his experience as an educator and product manager to present us with an accessible mental model for how next-generation AI might work and how humans might collaborate with it. It breaks down joint embeddings, energy-based models, and world-model planning in a way that anyone can follow, and it frames them around a useful idea: how to think like an “AI co-creator” instead of a casual user. This article will help you develop the intuition for how the next generation of AI will work, laying the foundation for our eventual deep dives.
This is a refined and updated version of a post from my blog, Tao of AI, where we discuss the interaction between deep technical evolution in AI and its impact on social domains, such as business, government, defense, and the professions. I’m very delighted to be posting again at Artificial Intelligence Made Simple. Please come join our conversation.
Yann LeCun, Chief Scientist of Meta AI, has spent several years evangelizing–and then developing (1, 2, 3)–an architectural alternative to LLMs, that he argues will help define the future of AI. Perhaps another day, I’ll strive to comment intelligently on whether he’s right or not, but for today I want to apply a more pragmatic lens: assuming that LeCun is right, how would that change the recommendations we’ve provided about how to become an AI Co-Creator? The goal is to think about how we would optimally interact with a specific, novel underlying model architecture. First, we’ll get to know the innovations that LeCun promotes. Then, we’ll apply the lens of the “AI co-creator”—discussed in my recent post on The New Literacy—to these new architectures.
Key definitions
AI Model User: A person or organization that interacts with an AI at the surface level, providing a prompt and hoping for a correct final output. Their focus is on the result.
AI Co-Creator: A person or organization that actively steers the AI’s reasoning process. They understand the AI’s underlying architecture and provide goals, constraints, and feedback to shape the process of reaching a solution.
Here’s a slide of LeCun’s that I think I’ve seen on social media (and which I then screenshotted from this presentation hosted by the National University of Singapore.):
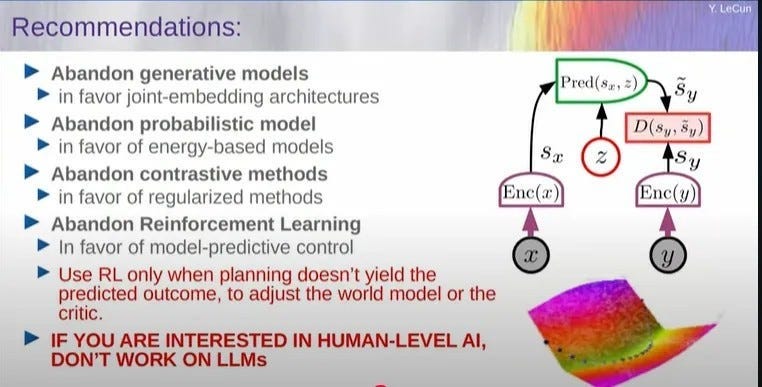
Let’s break down each of the recommendations shown on the slide.
The New Co-Creator: Prompting Beyond Text
1. Abandon Generative Models in favor of Joint-Embedding Architectures
Description: Today’s dominant LLMs are generative models. They are trained to predict the next word in a sequence, effectively generating new text by using statistical patterns learned from vast amounts of data. LeCun proposes a move to joint-embedding architectures, where the model learns a shared representation (an “embedding”) for specific data sets/types. Instead of just modeling text, it would learn how text, images, sound, and a physical state (like the position of an object) all relate to each other in a common space. There isn’t just a word mapped into its place in the world of language, the word is also mapped (via its association to an embedding) into a representation of its place in the physical world.
Intuition: LeCun’s core belief (reflected in the writings of many others–search on ‘embodied AI’--to be fair) is that generative models are like brilliant but isolated poets. They can produce beautiful, coherent text, but they have no grounding in the real world. A human understands that the word “apple” is connected to the experience of seeing, touching, and tasting a physical object. A generative LLM only knows its statistical relationship to other words like “pie,” “red,” and “tree.” By learning a joint embedding, an AI would build a multi-modal internal map of reality, allowing it to reason about the world in a way that goes beyond mere language. It would be able to connect the word “apple” to a visual representation of an apple, a simulation of it rolling off a table, and the sound of it crunching when bitten. This is core to the development of a “world model”.
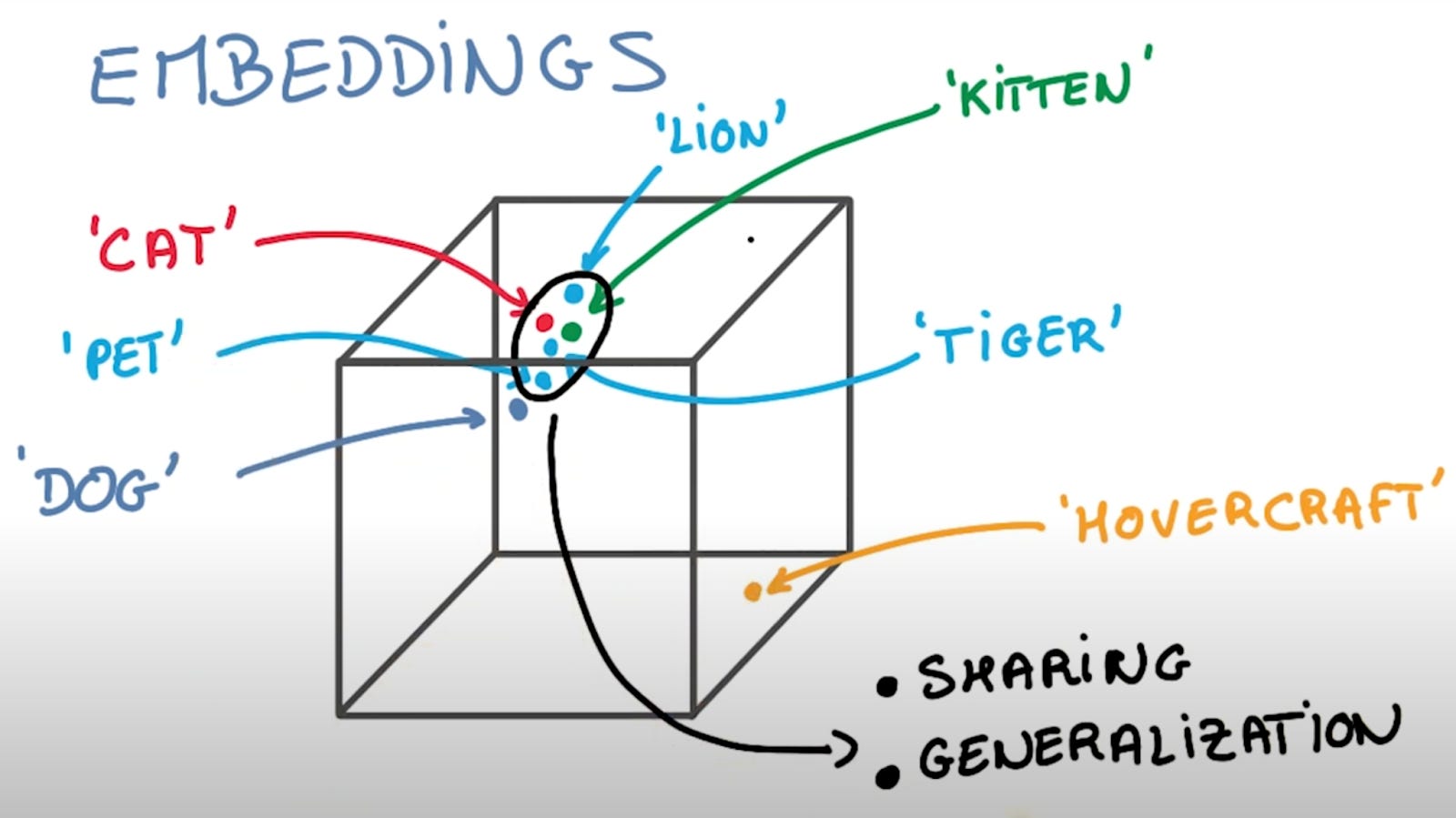
This screenshot from a video at aionlinecourse.com builds the intuition of how embeddings encode and then compare sets of characteristics of words/objects, to allow for the query/identification of diverse groupings. E.g. “cat” and “kitten” both purr and hunt mice; “cat”, “tiger”, and “lion” have a narrower (but still broad) set of commonalities in encoded characteristics (The grouping with “pet” is a bit more nuanced, so let’s leave that aside 🙂). Specific encoded characteristics do not necessarily have to be queried in each attempt to identify relationships.
2. Abandon Probabilistic Models in favor of Energy-Based Models
Description: LeCun argues that Energy-Based Models (EBMs) will supersede Large Language Models (LLMs) because they learn to build a fundamental understanding of what is plausible, rather than just predicting what is probable.
An LLM is trained using an error function that measures how wrong its prediction for the next word is. The model’s goal is to minimize this error, making its output as close as possible to the training data.
An EBM, on the other hand, learns a single-number energy function. The model’s goal is to make the energy low for plausible, desirable data (like a realistic image) and high for anything that is implausible or undesirable. It doesn’t need to know the exact probability of every single outcome; it only needs to learn the underlying rules and dependencies—the “latent variables”—that make data seem plausible.
Intuition: Think of the difference as two different ways of using a map and a compass to navigate.
The LLM’s Journey: An LLM is given a topographic map of a single mountain. The height of the mountain at any point represents the model’s prediction error. Its sole mission is to use a compass to navigate downhill and find the lowest point, which represents the most accurate predictions. It’s a master of downhill travel but learns nothing about the world beyond the one mountain it’s been given.
The EBM’s Journey: An EBM is given a magical map and is told to build an entire new continent. It learns to actively sculpt the landscape, pushing down valleys where plausible and realistic data can be found and raising high peaks for all the impossible and nonsensical data. The “compass” it uses is its energy function, which guides it to create a world where all the “good” information resides in low, comfortable valleys. The model’s goal is not just to find a low point, but to create a new, coherent map of reality itself.
An LLM uses its map to find a single correct answer, while an EBM learns to build the map of a plausible world. It follows that a traditional AI model might be able to tell you the probability of a few outcomes, while an EBM can make broader judgments: By developing a “map of reality” (via the implicit “functions” thereof), an EMB-trained AI can:
Make Judgments: Quickly identify an impossible or dangerous situation (a high-energy state).
Plan: Find a plausible, low-energy path to a desired outcome.
Reason: Understand the underlying principles of a system, like the physics of how an object moves or how a liquid flows.
This kind of first-principles understanding, LeCun argues is essential for building an AI that can interact efficiently, safely, and more directly, with an unpredictable world.
3. Abandon Contrastive Methods in favor of Regularized Methods
Description: Contrastive learning teaches a model by showing it positive and negative pairs. For example, it might learn that a picture of a cat is a “positive” match for the word “cat,” but a picture of a dog is a “negative” match. Regularized methods (specifically LeCun’s “self-supervised learning“ approach), provide the model with a correct input and task it with predicting a masked-out portion, forcing the model to infer the missing information in a plausible way.
Intuition: While contrastive methods are effective for learning to distinguish between things, they are limited. They rely on the human designer to provide a good set of negative examples. A regularized approach, in contrast, forces the model to learn a deeper, more generalizable model of the world by simply masking out parts of an input and asking it to fill in the blanks. For example, given a video of a ball rolling behind an object, the model’s task would be to predict where the ball will reappear. This forces the AI to develop a robust internal model of physics and object permanence, a more generalized and fundamental skill than telling a cat from a dog. This is a core part of building a world model.
4. Abandon Reinforcement Learning (RL) in favor of Model-Predictive Control
Description: Reinforcement learning (RL) trains an agent by providing rewards and penalties for its actions. The agent explores the world by trial and error to maximize its cumulative reward. Model-predictive control uses an agent’s internal world model to simulate the consequences of its actions before it acts. It can test out millions of “what if” scenarios in its head and choose the best course of action without needing to physically perform the action in the real world.
Reinforcement Learning (RL) operates on a simple principle: learn from experience. The agent takes an action, the environment responds with a new state, and the agent receives a reward or penalty for its action. Think of it like a toddler learning how to negotiate with its parents. The toddler, or agent, doesn’t start with a plan; it tries things out and learns which actions lead to the most treats (or highest rewards) over time. This process is a continuous loop of “act, observe, get feedback,” and the toddler’s goal is to discover a strategy, or “policy,” that maximizes its total cumulative reward. This trial-and-error approach has led to breakthroughs in chess and Go, where the rules and environment are perfectly defined, it can become quite challenging in the real world.
For a self-driving car, “experience” could mean millions of miles of dangerous driving to learn not to crash. This is where RL is considered “brittle”—it can’t easily adapt to situations it hasn’t seen before. The car would be like a new driver learning to navigate the world by repeatedly making mistakes.
Model-predictive control (MPC) is a strategy that focuses on planning for the future. It works by using an internal “world model” that acts as a simulator. Instead of acting blindly, the agent can test out a series of potential actions virtually and see the results within its internal model.
Imagine you’re at a an amusement part and want to go on the greatest number of rides and to ensure that you go on at least three of the scariest rides. But you only have two hours.
An MPC approach would involve your brain quickly simulating a few paths: “If I go on the most popular ride, I might end up in line for a long time.”, “These three rides are very close to each other, so I might concentrate my activity in that area.”
The brain uses its understanding of the world—its world model—to predict these outcomes before you even take a step. It then selects the best path to achieve the goal. This ability to look ahead and simulate outcomes is what makes MPC distinctive.
Building our intuition
Let’s look at how MPC and RL simulations differ as a means to build our intuition about how MPC and RL operate.
MPC are active participants in the inferencing/decision-making process. The agent has a pre-existing world model and uses it to simulate a wide range of future possibilities. It’s like running a flight simulator before a real flight. The goal is to find the best sequence of actions to take right now to achieve a specific goal, all within the safety of the model. These simulations are a core part of the decision-making process, allowing the agent to evaluate the consequences of its actions before committing to them in the real world.
RL Simulations are used to generate more “experience” for the agent to learn from. The simulations are used to train the agent’s policy in a virtual environment. The agent doesn’t use the simulation to plan its next move in the moment; it The agent uses the simulation as an extension of training, and as a means of building a better overall strategy for future decision-making.
In Summary: RL may use simulations for offline policy training. MPC uses its internal model for on-the-fly decision-making.
Note: LeCun acknowledges a small role for RL, suggesting it be used to refine the world model only when a real-world outcome doesn’t match the model’s internal prediction.
LeCun’s position is that while LLMs are impressive feats of engineering, they are fundamentally limited because they lack a world model. They are masters of syntax and semantics but have no true understanding of the reality the language describes. He sees them as a stepping stone, not the final destination.
The New Co-Creator: Prompting Beyond Text
A shift from LLMs to world-model-based AI would fundamentally change how we interact with these systems. The “new literacy” for an AI Co-Creator, in this context, would not be about prompting with words alone, but with a richer, multi-modal language. It might even be difficult to interact with such models without developing an AI Co-Creator mindset.
Let’s outline a framework for co-creating and then apply this in a few examples:
A Framework for Co-Creator Queries
To move from simply using a model to co-creating with it, your queries should be built around four key principles: defining the goal, providing rich context, specifying constraints, and iterating with precision.
1. Define the Goal, Not Just the Output
An AI Model User asks for a specific thing. A Co-Creator defines a successful outcome. This shifts the AI from a generator to a problem-solver.
User Query: “Create a 3D model of an office chair.”
Co-Creator Goal: “Design a chair that can support up to 300 lbs. and whose wheels roll smoothly on various surfaces.”
As seen with the logistics company, the goal wasn’t just to move a robot, but to “reduce the total time by 20%.” The goal includes the performance criteria.
2. Provide Multi-Modal Context
Don’t just rely on text. AI that understands the world needs world-like inputs. A Co-Creator provides a richer set of starting materials.
User Query: Relies on a single text prompt.
Co-Creator Context: Combines multiple inputs.
Visual Data: Sam’s hand-drawn sketch. The robot’s live video stream.
Textual Data: Sam’s paragraph describing the chair’s aesthetic.
Spatial Data: The warehouse’s real-time 3D map.
By providing more context, you narrow the solution space and anchor the AI’s “imagination” in reality.
3. Specify Constraints and Rules (Build the “World”)
This is the most critical step. A Co-Creator provides the AI with the rules of the world it needs to operate in. This is how the AI’s “internal world model” becomes useful.
User Query: Ignores physical reality. The generated chair might look good but would collapse.
Co-Creator Constraints: Defines the physics and boundaries.
Physical Laws: Sam provides a simple physics simulation (pulling on the armrest). The logistics platform defines the robot’s arm strength, speed, and grip force.
Performance Metrics: The chair must support 300 lbs. The robot’s task must be 20% faster.
These constraints force the AI to produce solutions that are not just visually plausible but functionally viable.
4. Iterate and Refine, Don’t Just Regenerate
When the output is flawed, a User asks the AI to “try again.” A Co-Creator identifies the specific error and provides a targeted correction, guiding the AI’s reasoning.
User Iteration: “That’s not right, generate another one.” (Brute-force)
Co-Creator Refinement: “Increase the tensile strength of the armrest material by 15% and re-run the stability simulation.” (Surgical correction)
This method is far more efficient. You are debugging the AI’s simulation, not just rolling the dice on a new generation. As you noted, this mirrors the expert prompting required in complex scientific experiments, where researchers steer the AI’s logic by pointing out specific, subtle errors.
Case Studies in AI Co-creation with a World Model
Case Study A: The Product Designer
Sam, a product designer, initially approaches an AI model as a simple generator. He types a text prompt: “Create a 3D model of a sleek, modern office chair with a chrome base.” The model produces a visually striking image, but it’s an illusion of a product. The chair’s arms are too thin to support any weight, and the base mechanism is physically impossible. He has a picture, not a design.
Shifting his approach, Sam becomes a co-creator. He starts by defining a clear goal: to design a chair that is not only aesthetically pleasing but can also safely support up to 300 lbs.
To give the AI the necessary context, he uploads a rough, hand-drawn sketch of his idea along with a paragraph describing the target aesthetic. He then establishes the physical constraints of the design world, defining the properties of the materials and even running a simple simulation to test the armrest’s rigidity.
The AI, now operating within these rules, doesn’t just generate an image; it designs a solution. It runs internal simulations, adjusting material thickness to meet the weight constraint and refining the wheel mechanics for a smooth roll.
When the AI’s initial design reveals a potential weak point, Sam doesn’t start over. He refines the process with a targeted command: “Increase the tensile strength of the armrest material by 15% and re-run the stability simulation.” Sam’s role has transformed from a prompter into a curator, guiding the AI’s problem-solving process to create a viable, functional product.
Case Study B: The Logistics Company
A logistics company’s warehouse robot initially learns its job through pure reinforcement learning. It’s a slow, brute-force process of trial and error, where the robot eventually finds an efficient path after countless inefficient attempts and collisions with shelves. The system is brittle and difficult to scale.
The company evolves by implementing a platform that treats its AI as a co-creator with a powerful internal world model. A human operator no longer plots a path but sets a high-level goal: “Retrieve item A from location X and place it in location Y, reducing the total time by 20%.”
The platform translates this objective into a continuous stream of context for the AI. This includes a live 3D map of the warehouse, video from the robot’s cameras, and the pre-defined physical constraints of the robot itself—its speed, arm strength, and grip force. The AI now understands its environment and its own limitations.
With this information, the AI’s world model simulates thousands of potential paths in a fraction of a second, anticipating collisions and optimizing every movement before the robot even begins. The process of refinement is constant; if a stray pallet appears in its path, the model instantly re-calculates the optimal route. The company has moved beyond brute-force learning to intelligent, predictive planning, allowing them to scale their operations safely and efficiently.
The Tao of AI: Join a Community of AI Co-Creators
The future of AI is a topic of intense discussion. Don’t sit it out.
What do you see as the single biggest challenge in making the transition from an AI user to a true “AI Co-Creator”?
Looking at these evolving architectures, which do you believe is the most revolutionary step away from today’s LLMs, and why?
Please share your thoughts and join the conversation in the comments below or–even better-in the Tao of AI Chat.
Thank you for being here, and I hope you have a wonderful day.
Dev <3
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819
 | A guest post by
|
Insightful. I'm curious if the world-model approach you discuss has particular advantages for ethical AI develpoment, given the focus on comprehensive understanding, or if it introduces its own set of unique challenges beyond just scaling infrastructure. Also, glad to see my future contributions will be supporting a very important cause, because who doesn't love chocolate milk.