
Reasoning Models Are a Dead End [Breakdowns]
They don’t think. They don’t search. They just compress. The future of AI reasoning isn’t inside the weights—it’s the system around them.

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
The industry has made a bet: that “reasoning” is just another capability to be trained into large models. That with enough scale, and enough reinforcement, intelligence will emerge not just in outcomes — but in process. Every major lab is pouring compute into training models that “think” — extended chain-of-thought, reinforcement learning from verifiable rewards, synthetic reasoning traces at scale.
The industry is wrong.
This isn’t about whether CoT/synthetic thought chains help. Or whether the most recent model can follow instructions. It’s about the structural limits of what can be induced through training alone — when the thing you’re trying to induce isn’t a task, but a faculty. As long as we continue to try forcing reasoning into a models weights, we’re forever bound to a paradigm that’s expensive, brittle, and limited in what it can truly accomplish.
The alternative here isn’t “give up on reasoning.” The alternative is recognizing that reasoning belongs at a different layer of the stack entirely — as infrastructure you plug models into, not capabilities you bake into weights.
In this article, we cover:
The three structural failures of the current paradigm
What “reasoning as infrastructure” actually means and why it’s architecturally inevitable
The incentive landscape: why big labs, startups, and the broader ecosystem all benefit from this shift
What becomes possible when reasoning is unbundled from generation and becomes it’s own layer.
Let’s break down why the AI industries golden child is actually a PR-kid doomed to fail (don’t start relating with it now).
Executive Highlights (TL;DR of the Article)
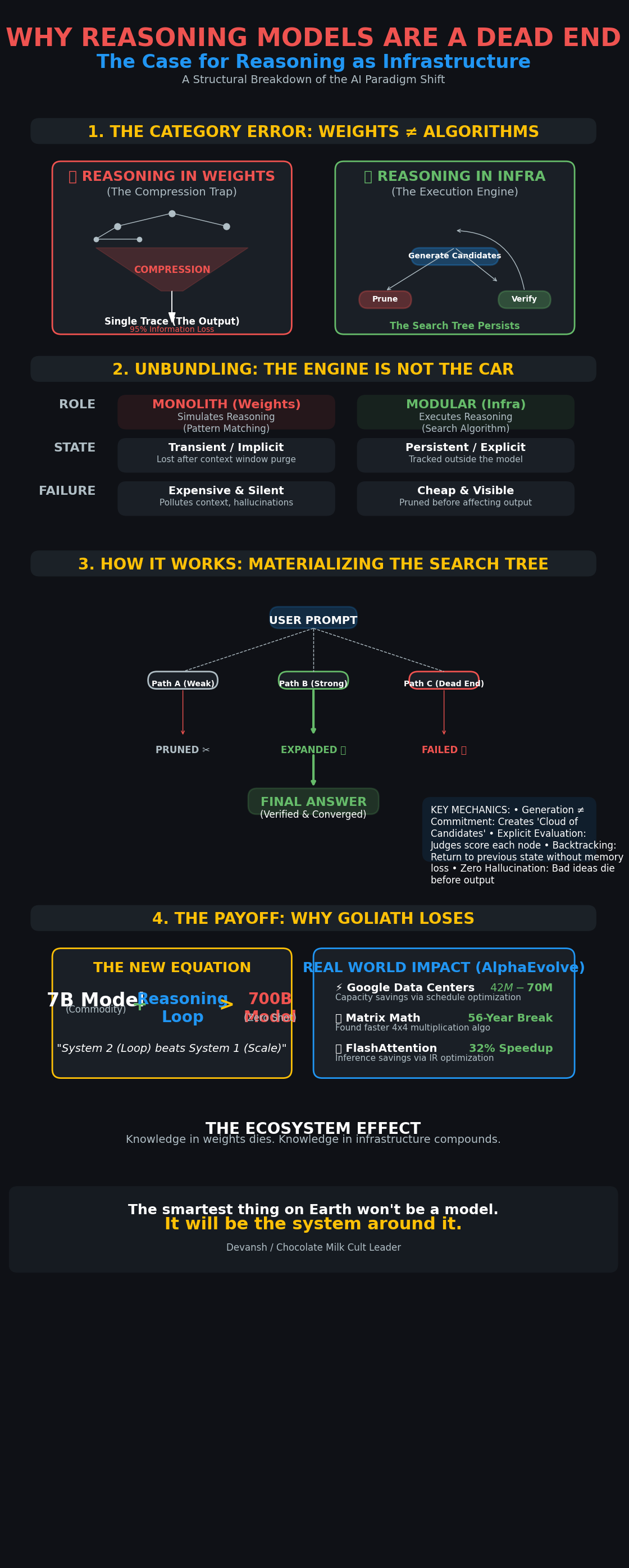
Reasoning models are a dead end because they try to compress a dynamic control process into static weights. Reasoning is not a pattern you can train; it is an algorithm you must run. When you train on reasoning traces, you only capture the final surviving path, not the search: the dead ends, branching decisions, backtracking, or evaluation criteria. Training optimizes for output equivalence, so it actively erases the very uncertainty, entropy, and exploration that real reasoning requires. Scaling this approach only produces better-looking reasoning artifacts, not better reasoning.
Weights cannot encode search. Neural networks approximate functions; reasoning requires persistent state, conditional execution, iteration, and first-class backtracking. Transformers collapse decisions token by token, forcing premature commitment and making genuine backtracking impossible. This creates high variance, brittle behavior, and uncontrollable regressions, because “reasoning” is entangled with everything else in the parameter space.
The solution is not better training but a different abstraction: reasoning as infrastructure. Models generate candidates; external systems handle control flow — branching, evaluation, pruning, backtracking, and state. Candidates become first-class objects. Failures are cheap and visible. Judges score explicitly. The search tree is materialized, auditable, and debuggable. Generation stops being commitment.
This mirrors what we already do with retrieval, tool use, and verification: extract what models do poorly into infrastructure and let them do what they’re good at. Systems like AlphaEvolve demonstrate the payoff — real economic gains from externalized search and evaluation, not from “thinking harder” inside weights.
Once reasoning is externalized, base models are commoditized. Small models wrapped in deterministic reasoning loops can outperform massive reasoning models forced to get it right in one shot. Verifiers, judges, and loop logic become the real moat. Architecturally, any model type can participate — transformers, diffusion, symbolic systems — composed through a shared reasoning layer.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
1. Why training AI Models to Reason is Doomed to Fail
The fundamental problem with reasoning models is not their implementation, but their premise. We are trying to embed a dynamic, external process — reasoning — into a static, internal medium: model weights. This is a category error, and it leads to three structural failures that no amount of scale or data can fix.
1.1 Training Reasoning Models is Extremely Wasteful
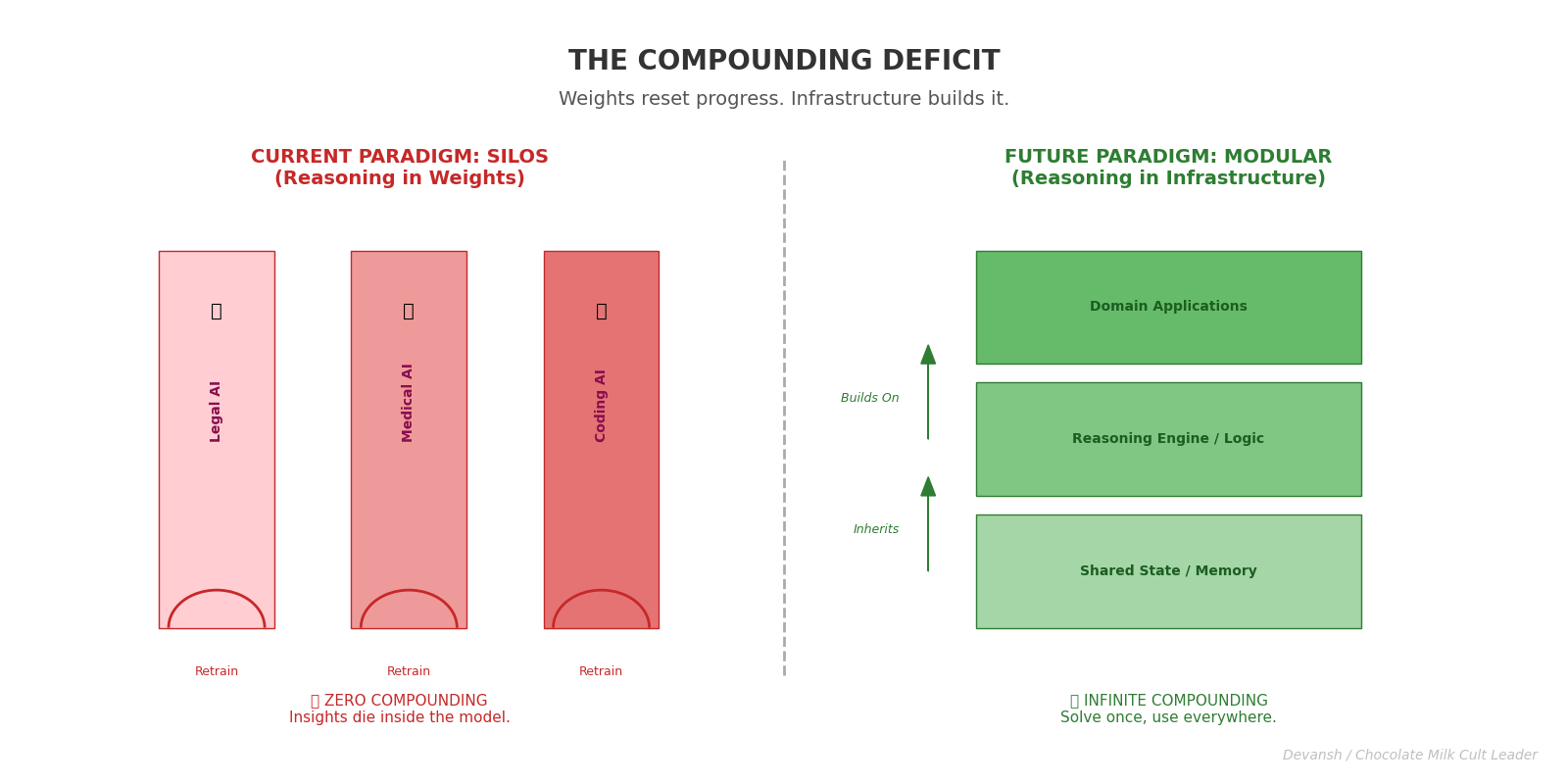
Training reasoning into model weights does not compound. It resets. The current approach ensures that every advance in reasoning is a dead end.
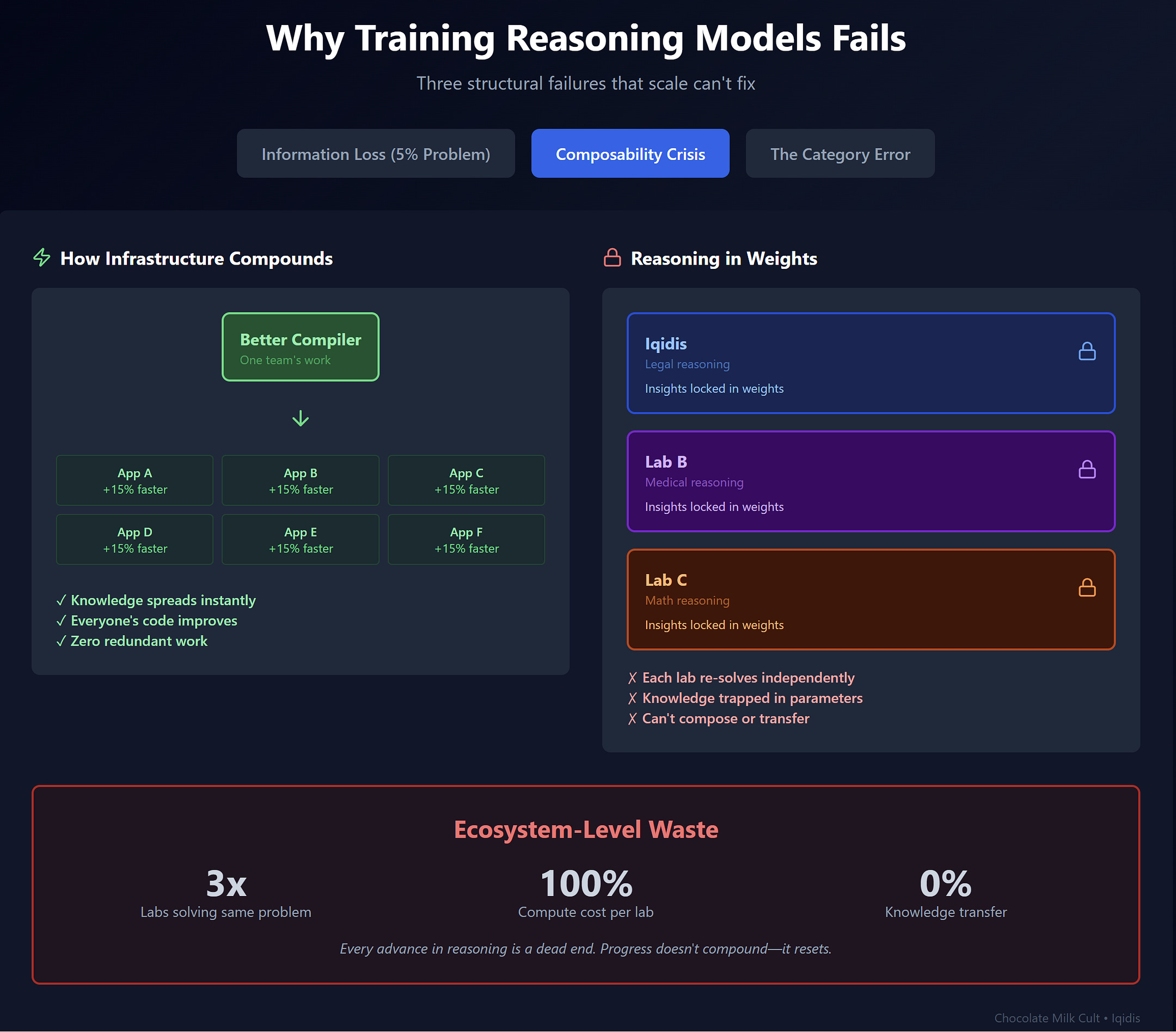
Say Iqidis develops a model with sophisticated legal reasoning capabilities. Under the current paradigm, that work lives and dies inside our system. Google can’t use our insights about legal argumentation structure. Anthropic can’t benefit from what we learned about precedent analysis. A medical AI startup can’t adapt our approach to clinical reasoning. The knowledge is locked in weights, and weights don’t compose.
This is the opposite of how technological progress usually works. When someone invents a better compiler, everyone’s code gets faster. When someone develops a better database, every application can use it. Infrastructure improvements compound across the ecosystem.
There’s no way to patch this stupdity since it is a consequence of embedding reasoning into weights.
Weights are not modular. They do not expose interfaces. They do not separate concerns. Once “reasoning” is fused into a model, it becomes inseparable from everything else the model knows — language patterns, stylistic biases, safety constraints, latent correlations from training data. Improving one aspect requires retraining the whole.
The result is an ecosystem where:
Every lab re-solves the same problem independently
Every improvement requires fresh compute
Every domain rebuilds its own reasoning stack from scratch
The compute cost is staggering. But the opportunity cost is worse. All those resources spent duplicating solved problems are resources not spent on unsolved ones.
1.2 Why Weights Can’t Encode Reasoning
Words are a medium that reduces reality to abstraction for transmission to our reason, and in their power to corrode reality inevitably lurks the danger that the words themselves will be corroded too.
Think of it like flattening a layered Photoshop file into a JPEG. The final image is there, but the process — the individual layers, the revision history, the paths not taken — is gone with the wind. Yamcha’d. Invisible like Piccaso’s skills against Inoue (that fight was an …execution).
The JPEG contains the result of the work, not the ability to do it. Expertise is after all more stored in the many decisions never explored, or many partial failures that we polish into the final product. The end result contains no traces of them.
Training reasoning into weights is the same operation. And it fails for the same reason.
Reasoning Is a Procedure, Not a Pattern
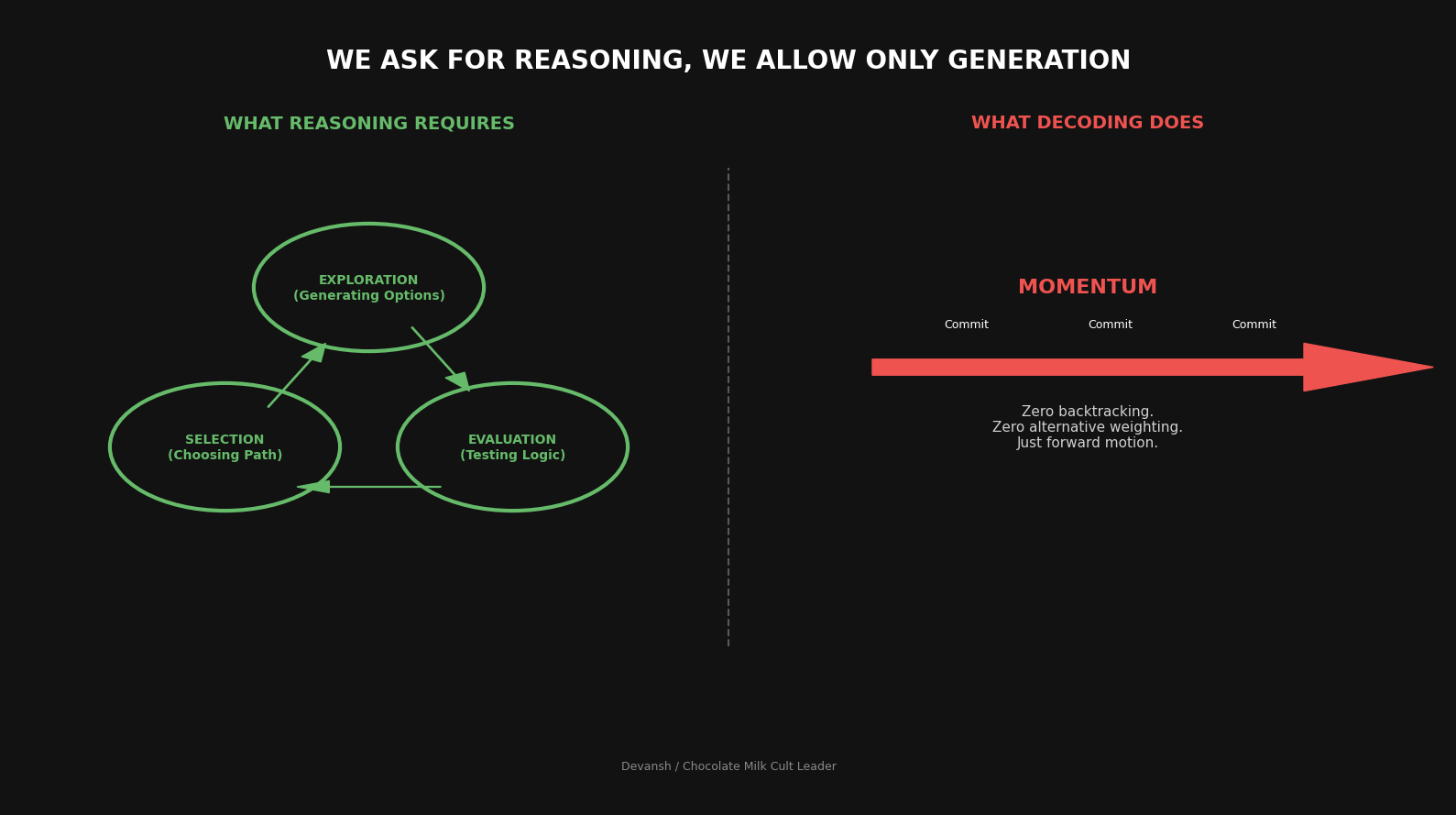
When you actually reason through a hard problem, you’re not retrieving a pattern. You’re executing an algorithm:
Generate initial candidates. Not one candidate — multiple. You’re spanning a space of possibilities.
Evaluate candidates against criteria. Some fail immediately. Some look promising.
Expand promising candidates. Follow the branches that seem to lead somewhere.
Detect dead ends. Recognize when a line of thinking isn’t working.
Backtrack. Return to an earlier state and try a different branch.
Combine insights. Synthesize what you learned from different branches (including some of your failures).
Iterate until convergence. Keep going until something survives all your critiques.
This is control flow. Conditionals, loops, state management, backtracking. The reasoning process branches and prunes and recombines.
Now ask: what does training capture from this process?
Almost nothing.
The Information-Theoretic Loss
Training sees the output — the final reasoning trace that survived. It doesn’t see the candidates that were considered and rejected. It doesn’t see the dead ends that were explored and abandoned. It doesn’t see the decision points where the reasoner chose to backtrack.
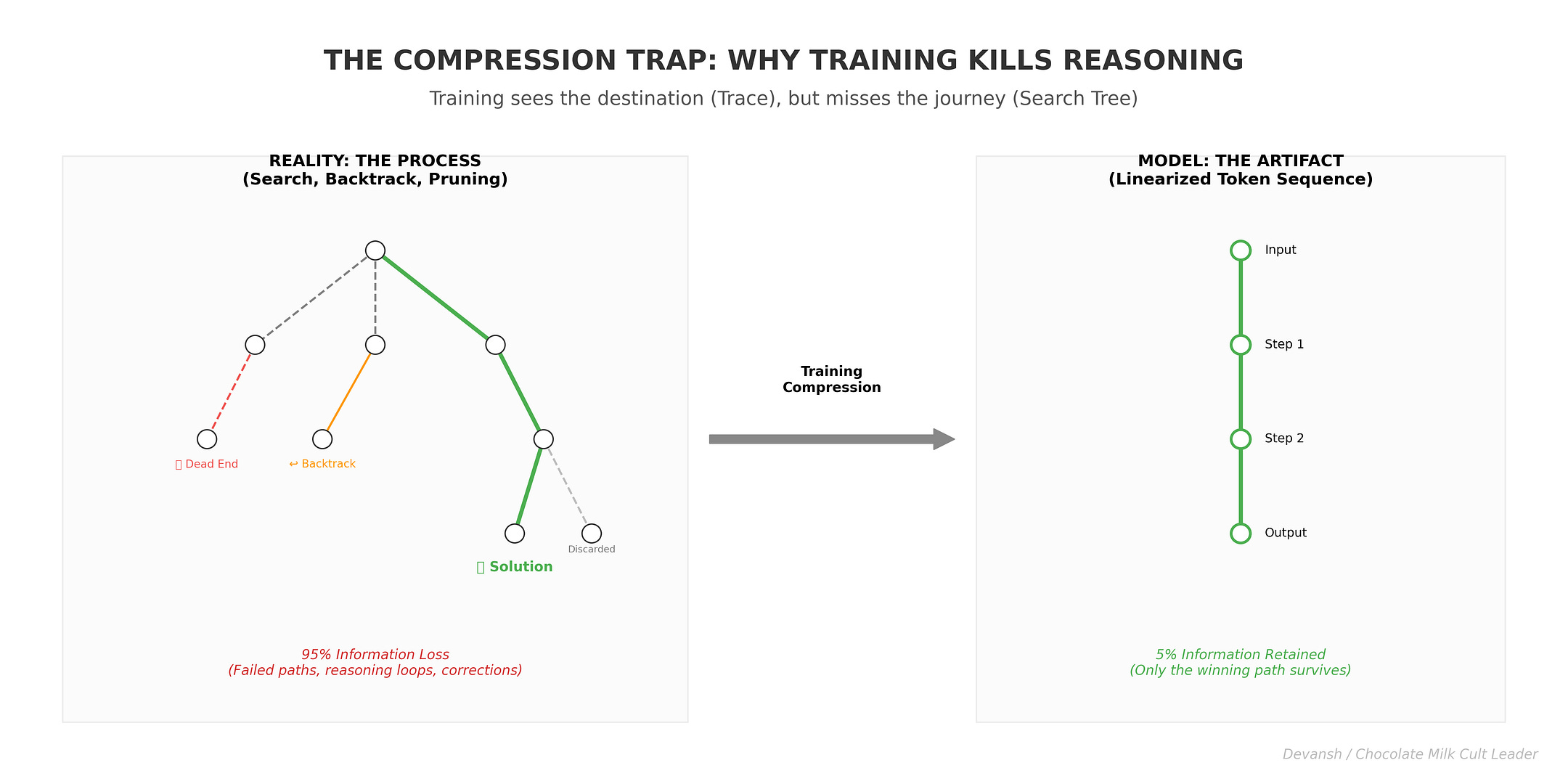
A reasoning trace is a projection. The single surviving path through an exponentially large search tree.
Let’s make it concrete. Suppose good reasoning on a problem requires considering fifty candidate approaches, evaluating each, and discovering that only three are viable. The reasoning trace you write down shows one of those three, with some justification.
What information is in the trace? The structure of one successful path.
What information is missing? The forty-seven failed paths. The criteria that eliminated them. The order in which they were considered. The moments where the reasoner almost went down a dead end but caught themselves. The insights from failed paths that informed successful ones.
When you train on this trace, you’re training on maybe 5% of the actual reasoning process. The model learns to produce outputs that look like the 5% you showed it. The 95% that actually constitutes the search — invisible.
This is why scaling doesn’t help. More training data means more traces. But each trace is still a projection. You’re adding more examples of surviving paths, not more examples of the search process itself. The model gets better at pattern-matching to traces. It doesn’t get better at searching.
Compression Destroys What Reasoning Requires
Training compresses behavior into parameters by optimizing for output equivalence, not process fidelity. If two different internal procedures produce the same correct answer often enough, gradient descent treats them as interchangeable.
The weights only need to reproduce the result, not the path that led there.
This creates a fun little tension that training-cels like to duck from (if their smooth-brains can even understand the implications):
Reasoning requires maintaining entropy early in the process. Hold options open. Defer commitment. Preserve the degrees of freedom that let you backtrack.
Training rewards entropy reduction as fast as possible. Collapse uncertainty. Converge to outputs. Eliminate the slack.
These objectives are directly opposed. Any intermediate uncertainty, branching, or self-critique that doesn’t improve loss gets progressively eliminated. This is the LLM variant of the idea behind the evolutionary valley, one of the most important systems concepts for anyone to know. In a nutshell it can be explained as follows: A system — biological, technological, organizational — can see a higher peak ahead, but to reach it, it must first get worse. It must pass through a dip in performance, stability, or fitness before climbing to a superior design. Evolution avoids these valleys because natural selection punishes anything that loses capability, even temporarily. Many pure researchers/engineers always think in terms of great end result, w/o understanding that their proposed solutions will carry a lot of short term pain and thus likely to be shut down by management (who can’t truly understand the better outcomes). This is why communication is key for engineers, see our guide here).
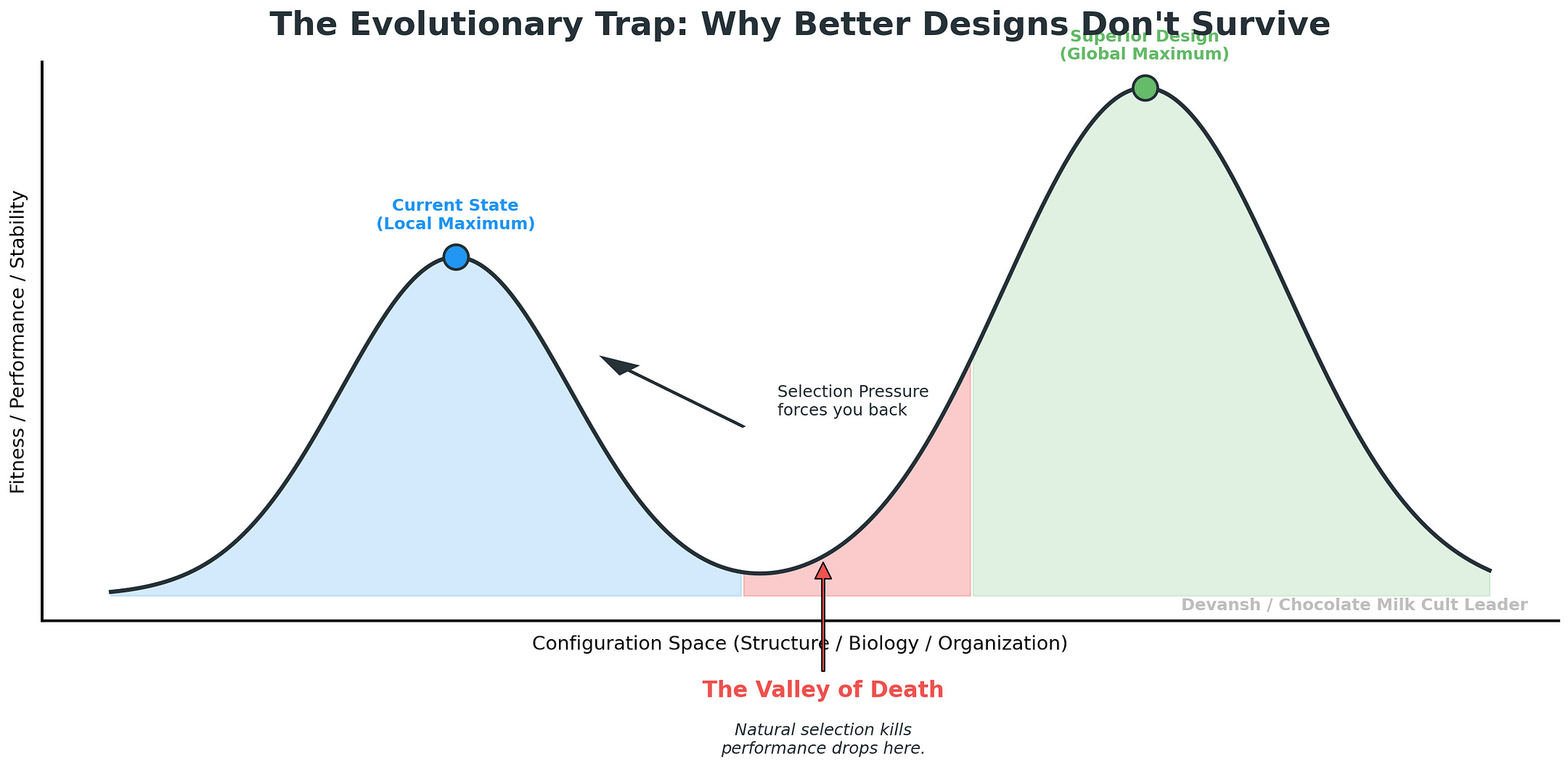
The end result is painfully clear to anyone working with a strong middle-management or HR culture — our LLM discards the correct solutions/approaches when they don’t fit into the pre-approved templates. Maybe when AGI-chan finally starts it’s take-over, it will be halted by the many data points in it’s training set that will make it wait for approval to expense it’s weapons purchases and cloud provisions.
Why Weights Can’t Represent Search
Even if you somehow exposed the full search tree during training, weights are the wrong substrate to encode it.
Weights encode functions — mappings from inputs to outputs. Neural networks are function approximators. Very good ones, sometimes excellent even, but fundamentally they learn input-output relationships.
Search isn’t a function. Search is an algorithm. It requires:
State that persists and updates. “I’ve tried approaches A, B, C. B looked promising. I’m currently expanding B.”
Conditional execution. “If this evaluation fails, try something else. If it succeeds, go deeper.”
Iteration with termination conditions. “Keep generating candidates until I find one that passes all criteria, or until I’ve exhausted my budget.”
Backtracking as a first-class operation. “This path isn’t working. Return to the last decision point and take a different branch.”
Transformer forward passes are stateless. Each pass takes the current context and produces a distribution over next tokens. There’s no persistent memory of “where I am in the search.” There’s no mechanism for “return to previous state.”

You might object: the context window serves as state. The model writes out its reasoning, and that becomes input for future tokens.
This is exactly the problem. The model has to commit to tokens to maintain state. Every token is a decision that can’t be revisited. The model writes “Let’s try approach A” and now it’s locked in. To backtrack it would have to purge the context and restart from a branching point, but also somehow have a way to store the lessons from the failed path to avoid future mistakes. This is a balance we haven’t quite solved in transformers, where we see an overattention to irrelevant tokens, certain characters causing breakdowns, and input sensititivity.
Externalized Reasoning Changes Everything
When reasoning is externalized — infrastructure rather than weights — the picture inverts:
Generation does not equal commitment. Candidates exist as discrete objects you can see, compare, and score independently.
Evaluation is explicit. Judges produce scores. You know why a candidate was rejected.
The search tree is visible. Trace which branches were explored, which were pruned, why.
Backtracking is an operation. Not a hope that the model will write “let me reconsider,” but an actual mechanism that returns to previous states.
State is maintained explicitly. Track what’s been tried, what worked, what didn’t.
Failure is cheap. Nothing has been collapsed yet. Abandoning a path costs nothing.
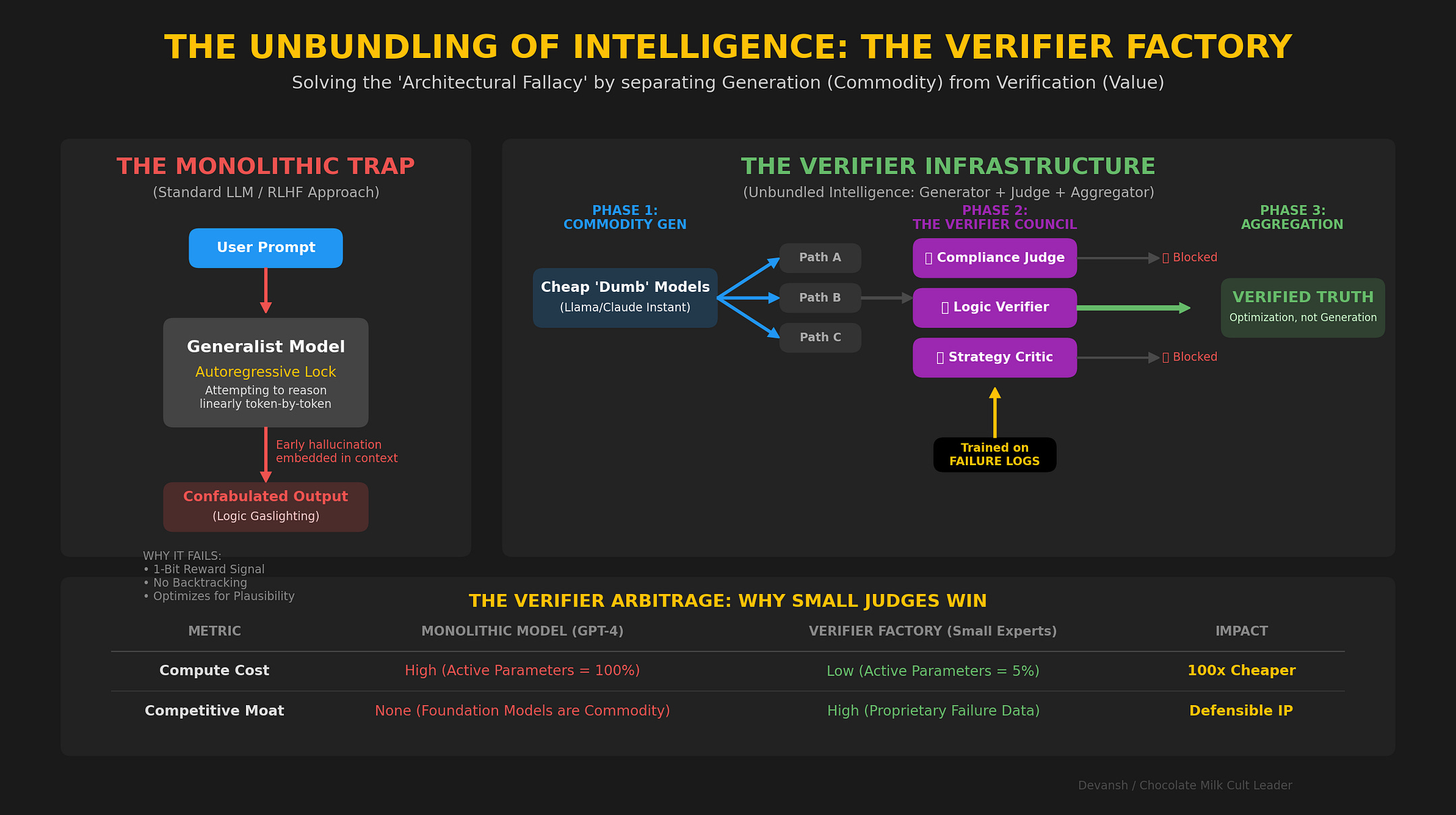
When reasoning is in weights, you’re simulating — producing outputs that look like reasoning happened. Even when models appear to “think step by step,” those steps are not live control states. They are outputs sampled after the fact. The model is not branching and evaluating internally; it is emitting a linearized artifact of a decision that has already collapsed.

The solution isn’t better training. Training reasoning into weights asks a compression system to preserve a control process. That is a category error. The more successful the compression, the more thoroughly the process is erased.
You have to actually run the algorithm of reasoning.
1.3 Uncontrollable Variance
Embedding reasoning into weights also makes it uncontrollable.
A model’s parameters encode many things simultaneously: language, world knowledge, preferences, safety behavior, stylistic tendencies, task heuristics. Reasoning is not stored in a clean compartment. It is entangled with everything else.
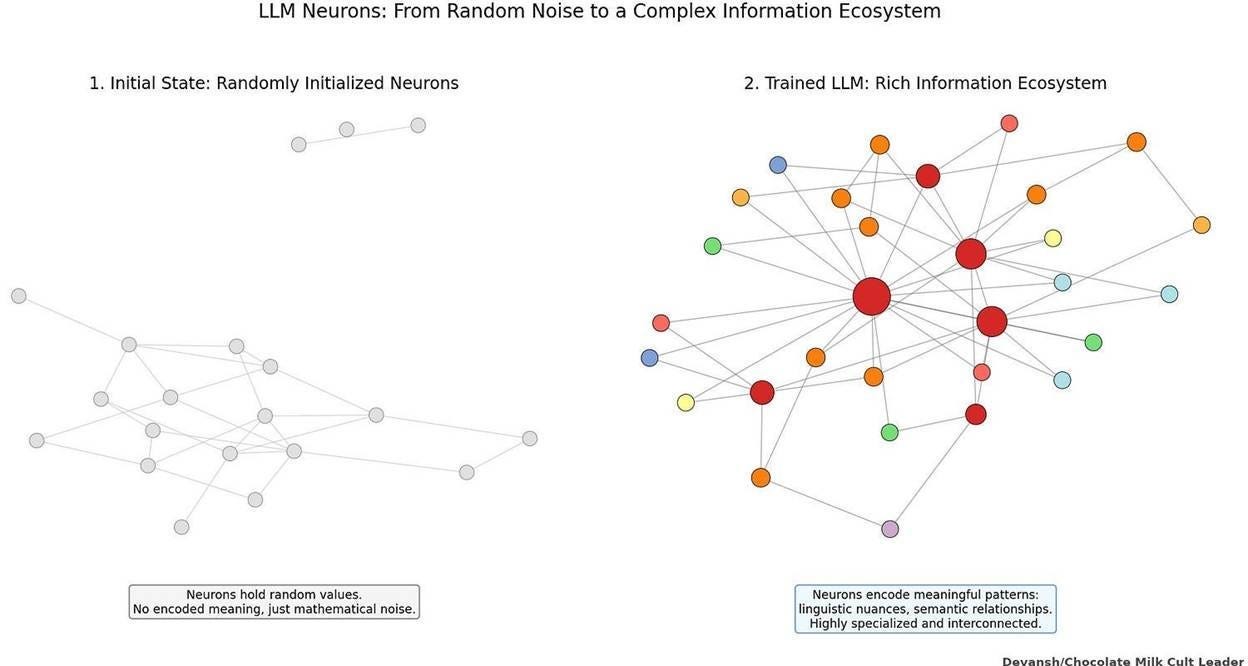
As a result, small changes propagate unpredictably. Adjusting training data, fine-tuning for a domain, or modifying reward signals can alter reasoning behavior in ways that are difficult to anticipate or diagnose. Improving one reasoning pattern can degrade another. Fixing failures in one task can introduce regressions elsewhere.
This is why reasoning models exhibit high variance even under controlled settings. Prompt sensitivity, sampling effects, and training noise are not surface-level issues. They reflect the fact that reasoning is encoded implicitly across a massive parameter space with no explicit control surface.
Infrastructure-based reasoning does not have this problem. Reasoning components can be updated independently. Evaluation criteria can be changed without retraining the generator. Failures can be traced to specific modules instead of being smeared across billions of parameters.
Variance still exists — but it is visible, bounded, and correctable. Even when it isn’t truly perfect (you might still rely on black-box Deep Learning models for judging, feedback etc), it still offers orders of magnitude better performance. To steal a framing I heard recently: in avenues of high uncertainity, even slight increases in certainity can be massively impactful (imagine you ask for the directions to an airport that’s 1 hour away, and I say it’s upto 10 hours. Then someone tells you it’s upto 4 hours. Even though the 4 is still very off, it’s already cut your uncertain range significantly, allowing you to make much better plans. Our system works the same way).
I’ve spent a lot of words telling you our current approach doesn’t work. Now is the time for me to spend some words talking actual solutions.
2. Reasoning as Infrastructure
If training reasoning into weights is a dead end, what replaces it?
Not a better technique. Not a bigger model. A different abstraction. We stop embedding reasoning. We start running it.
To understand that, let’s build our intuition ground up.
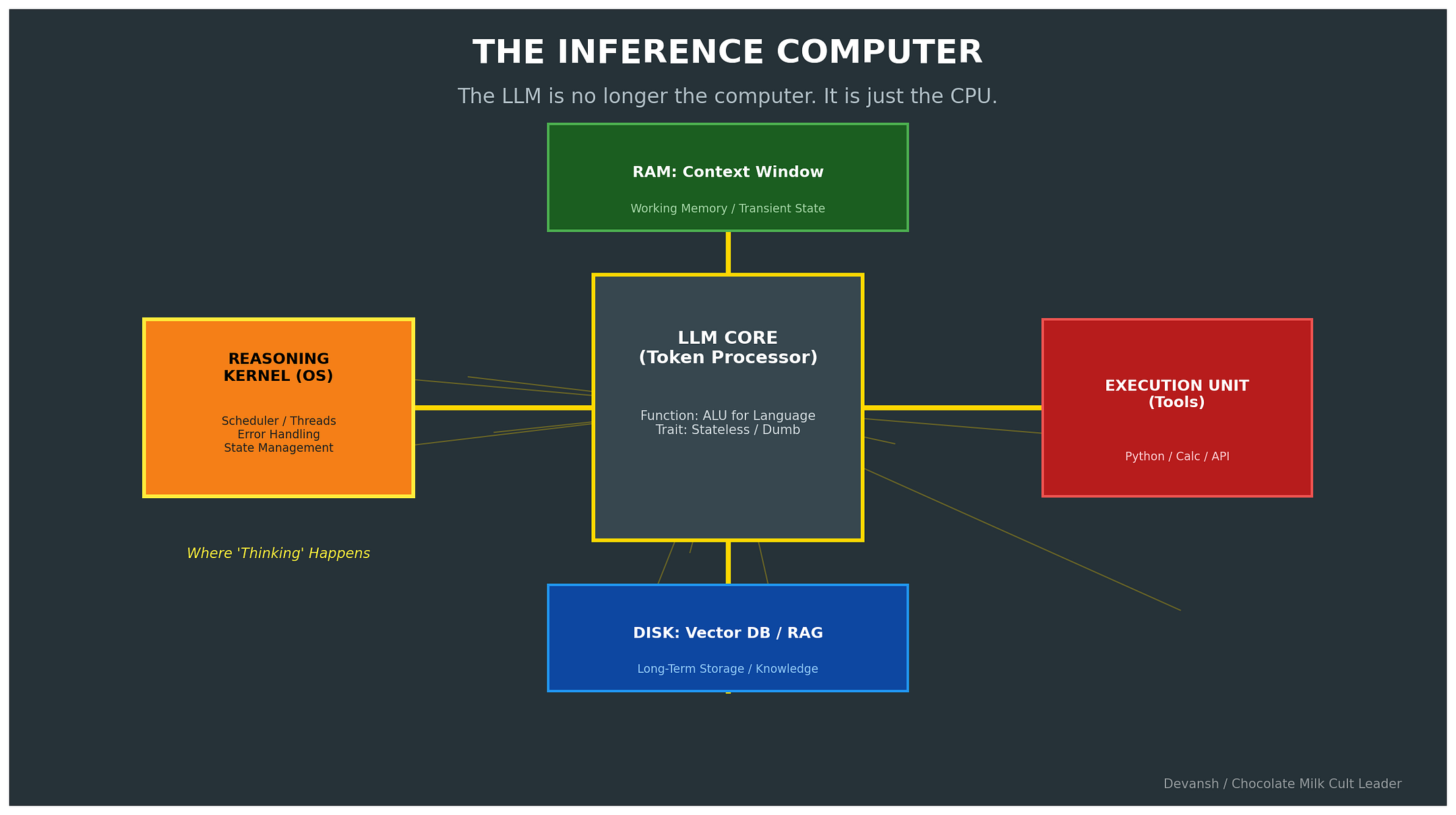
2.1 The Engine Is Not the Car
Right now we ask the LLM to be the engine, the transmission, the steering wheel, and the driver. Generate ideas, critique them, remember the plan, execute the next step. All in a single forward pass.
Look at what models actually do well: encode knowledge, generate fluent text, pattern-match across domains, simulate perspectives. Look at what they do poorly: maintain state across a search, backtrack without commitment, evaluate their own outputs against articulable criteria.
Radically different jobs. We’ve been forcing one artifact to do both.
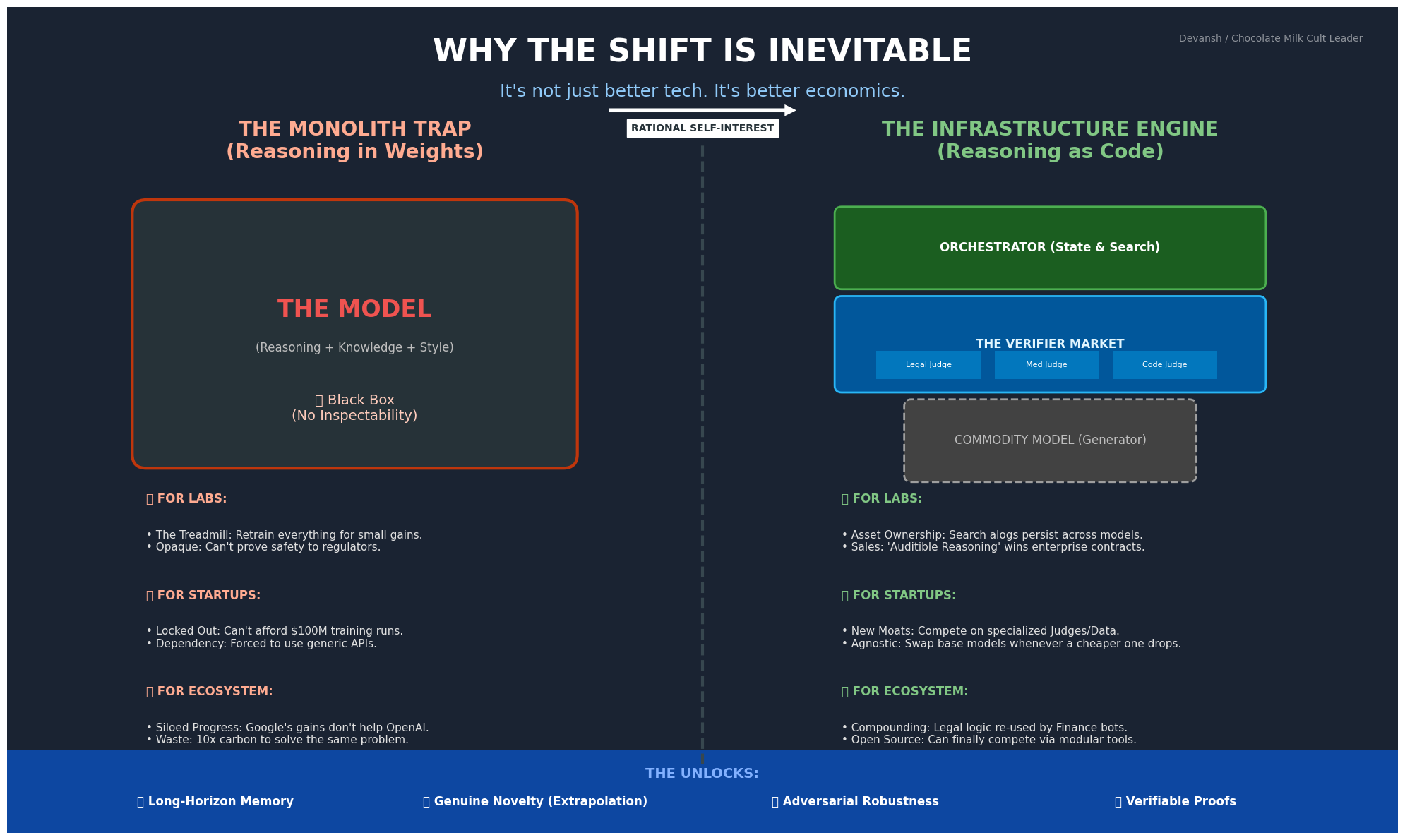
The fix is simple. The model provides knowledge and generation. It’s the engine: powerful, dumb. The infrastructure provides control flow: candidates, evaluation, exploration, pruning, backtracking, state management, termination. The model doesn’t need to reason. It needs to be reasoned with.
This was the design philosophy behind DeepMind’s smash-hit model AlphaEvolve, an agentic reasoning system that made several multi-million dollar contributions to their systems autonomously (see the details of the algorithm and the math we used to derive value here) —
Matrix Multiplication (4×4 complex, 48 mults): AlphaEvolve broke a 56-year-old barrier in linear algebra by discovering a faster 4×4 matrix multiplication algorithm. A direct 2% gain seems niche, but across large-scale training and infrastructure, it could translate into $150K–$500K per model and $ 20 M+ in deferred hardware costs if widely adopted.
Mathematical Problems (Kissing Number, Erdős): AlphaEvolve matched or beat the state-of-the-art in ~20% of 50+ open mathematical problems, including improving the 11D kissing number. The immediate impact is intellectual, but the real signal is the emergence of AI as a collaborator in abstract theoretical research.
Google Data Center Scheduling (0.7% recovery): By evolving a better scheduling heuristic, AlphaEvolve reclaimed ~0.7% of compute across Google’s fleet, equal to 14,000 servers. That’s an estimated $42M–$70M per year in capacity savings, without touching hardware or deployment logic.
Gemini Kernel Optimization (1% training time cut): AlphaEvolve redesigned critical kernels for Gemini, achieving a 23% kernel speedup and reducing total training time by 1%. This saves $500K–$1M per training run, with additional multi-million-dollar impact across repeated fine-tuning cycles and compressed engineering timelines.
TPU Circuit Optimization (Verilog): AlphaEvolve optimized RTL-level Verilog to reduce area and power in TPU arithmetic units. Even a 0.5–1% gain here can save $5M+ in wafer costs and $150K–$300K annually in power, while accelerating hardware iteration and verification loops.
XLA IR Optimization (FlashAttention): By modifying compiler-generated IR code, AlphaEvolve achieved a 32% kernel and 15% pre/post speedup for FlashAttention. At Google’s scale, this can translate to $1M–$2.5M per year in inference savings and sets the precedent for AI-augmented compiler-level optimization.
There are several other agentic designs that apply something similar. Claude Code for example, using several powerful deterministic tools and various modes + subagents tobuild a system that constantly generates code, tests it, and then improves things. By splintering tasks across tools and subagents, it allows the main agent to focus on the planning and review, enabling it to work across significantly more complex tasks without being killed by context corruption.

2.2 We Already Do This
This isn’t novel. We already externalize capabilities we don’t trust models to handle internally.
Retrieval: Models hallucinate facts. So we build RAG systems that fetch documents and inject them into context. The model doesn’t need to know everything. It needs access to systems that retrieve.
Tool use: Models can’t execute code in their heads. So we give them interpreters, calculators, APIs. The model doesn’t need to compute. It invokes systems that compute.
Verification: Models confidently produce wrong answers. So we add unit tests, type systems, human review. The model doesn’t need to be right. It needs to be checked.
Same pattern each time: identify what models do poorly, extract it into infrastructure, let the model do what it’s good at. This lets us simplify the problems significantly, and to concentrate the attack surface on the areas where we can have the highest ROI. The simplification of problem statement allows us to focus our attention on going deeper into what we are solving, enabling massive breakthroughs there. The converse, letting our system complexity grow b/c it tries to tackle too much internally, never works out well.

As they say, duck every fade you can’t win and pick on the weak. It’s one of the few winning strats that the devs will never patch.
Reasoning is the same move. We just haven’t finished making it.
The industry is stuck halfway. Bolt chain-of-thought onto models, train them to produce reasoning traces, hope that thinking out loud makes them think. But writing down steps isn’t searching. Producing a trace isn’t executing an algorithm. The externalization is incomplete.
2.3 Materializing the Search Tree
Remember the 95% of reasoning that training never sees? The forty-seven failed paths, the evaluation criteria, the branching decisions?
Infrastructure brings them back.
In a properly architected system, we don’t force the model to commit to a single token stream. We use the model to generate a cloud of candidates: potential thoughts, strategies, next steps. Because these candidates live in infrastructure rather than the context window, they’re cheap. Generate them, inspect them, score them with specialized verifiers, delete them.
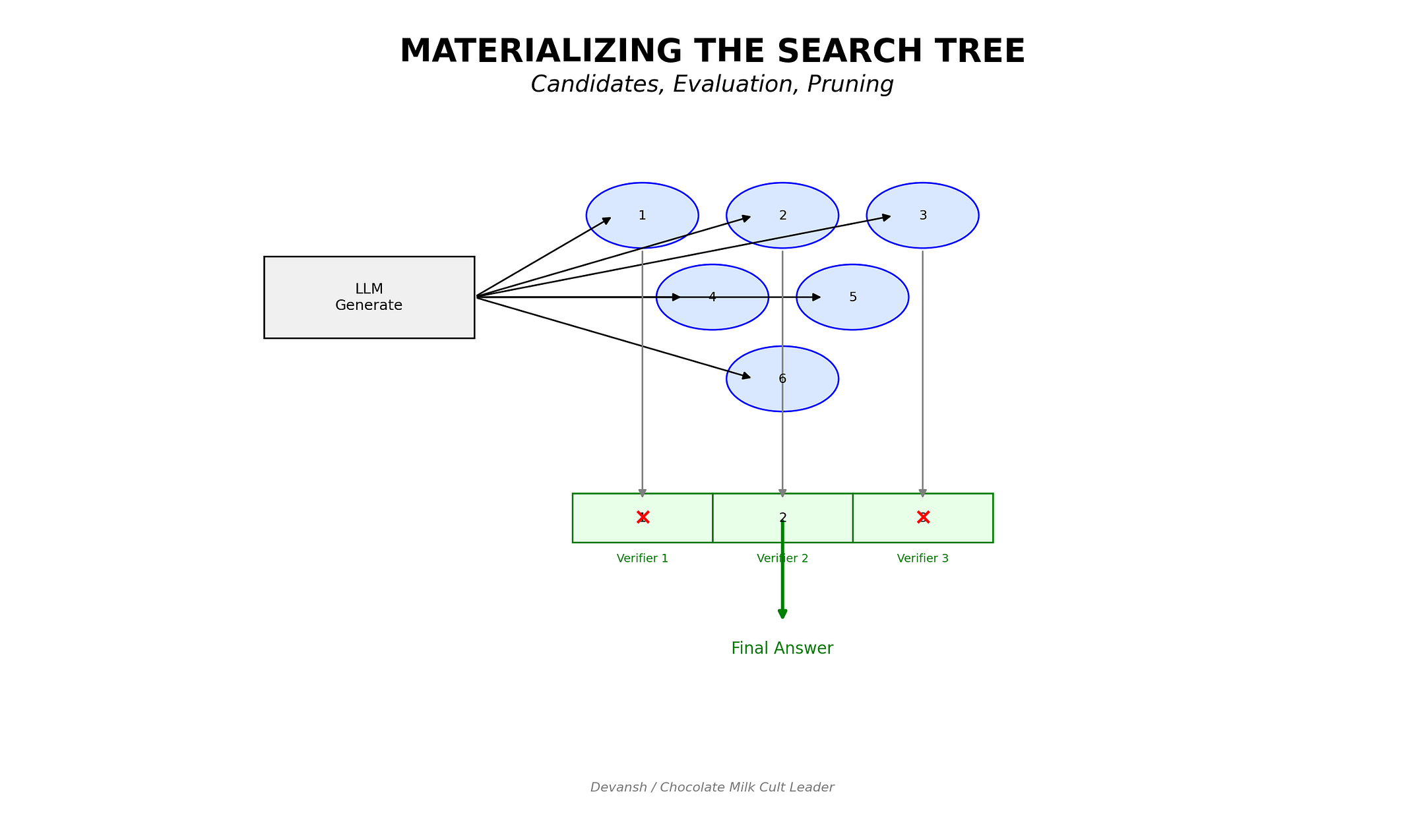
Dead end? Prune it. Never pollutes the final context. Never biases subsequent generation. The model never hallucinates a justification for a bad idea because the bad idea dies before it collapses into the output history.
In weights: candidates are hidden, evaluation is implicit, failures are invisible, backtracking is a rhetorical gesture.
In infrastructure: candidates are first-class objects, evaluation uses discrete verifiers, failures get recorded and scored, backtracking is a function call.
You can trace the search tree. Inject domain priors. Stop halfway, swap the judge, rerun the branch. Say “explore this angle more” and the system knows what “this” refers to.
No hallucinated self-reasoning. No begging the model to retry a plan it already forgot. The infrastructure remembers. It orchestrates. It can be audited, debugged, extended.
2.4 The Commodity Generator
This has economic consequences: it commoditizes the base model.
If reasoning logic lives in infrastructure, you don’t need a “smart” model for heavy lifting. You need a model coherent enough to generate candidates and follow instructions.
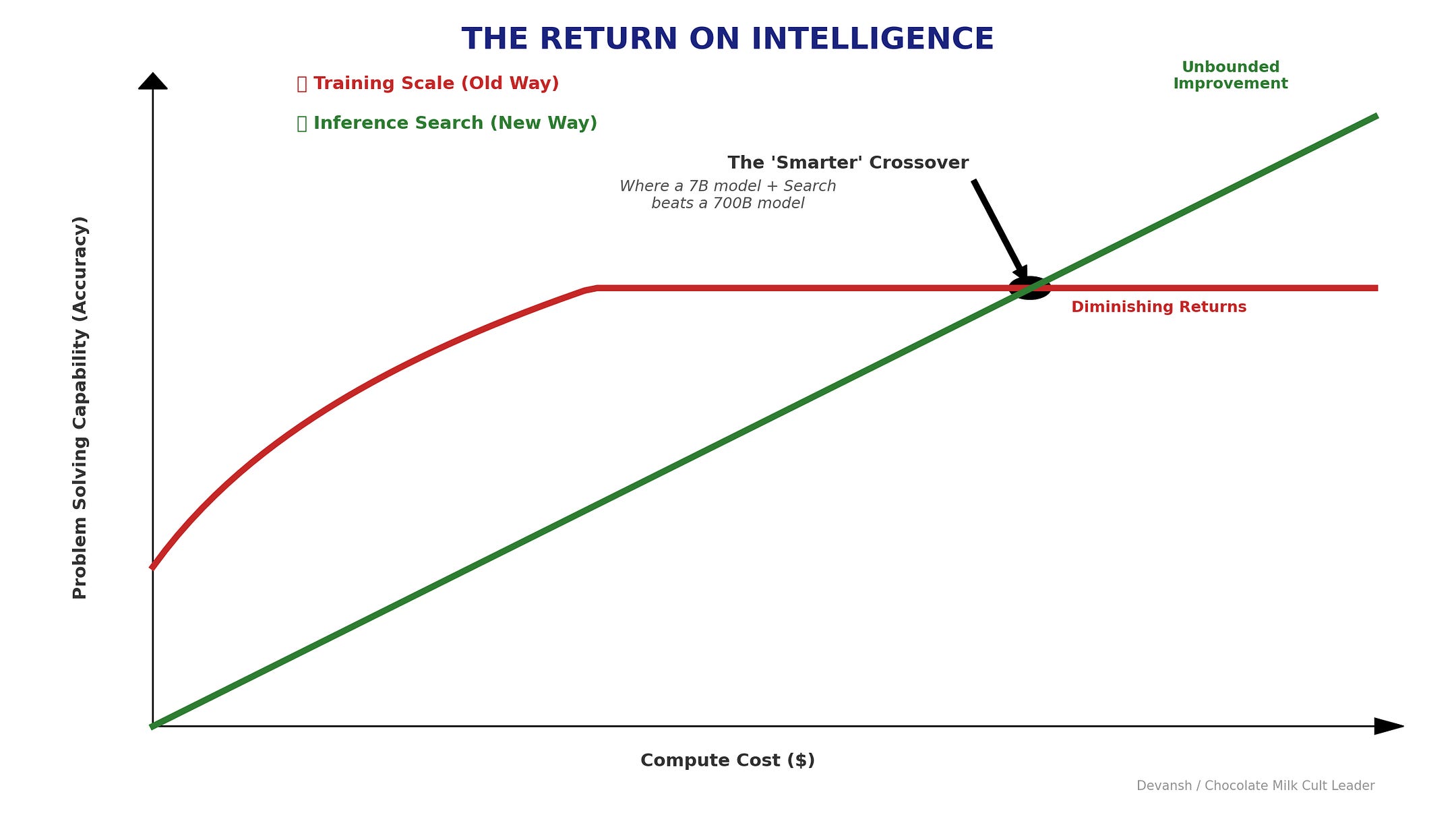
A 7B model plugged into a rigorous verification loop with domain-specific judges can outperform a 700B model reasoning zero-shot. The small model runs as a System 2 process: iterate, fail, correct, repeat a hundred times before yielding an answer. The large model is stuck in System 1. Has to get it right on the first try, purely on pattern-matched intuition.
This kills the moat of the “reasoning model.” You don’t need massive RL-reinforced proprietary systems to get better reasoning. You need better infrastructure and cheaper inference.
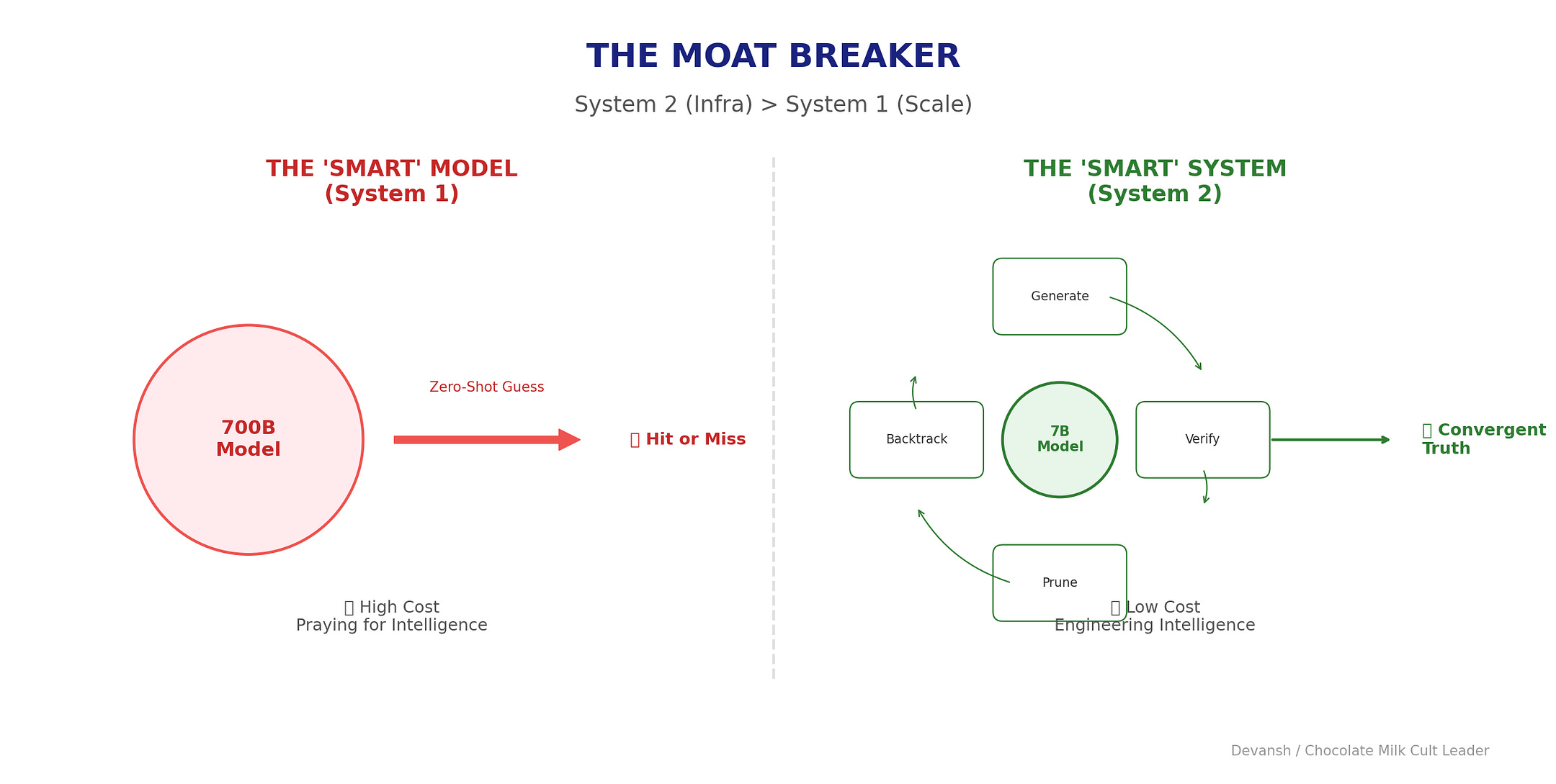
The base model becomes a stochastic generator wrapped in a deterministic shell. You can’t make a probabilistic model deterministic. But you can make the architecture around it deterministic.
Verifiers: rigid, code-based or specialized model-based checks. Does this compile? Does this citation exist? Is the arithmetic correct? Does this meant stylistic constraints?
Loop logic: if score < 0.8, generate five more candidates. If three consecutive failures, backtrack to step two.
Wrap a stochastic core in a deterministic shell and you get (better) reliability. You can audit the decision process, see which verifier rejected which candidate, tweak thresholds without retraining a billion parameters.
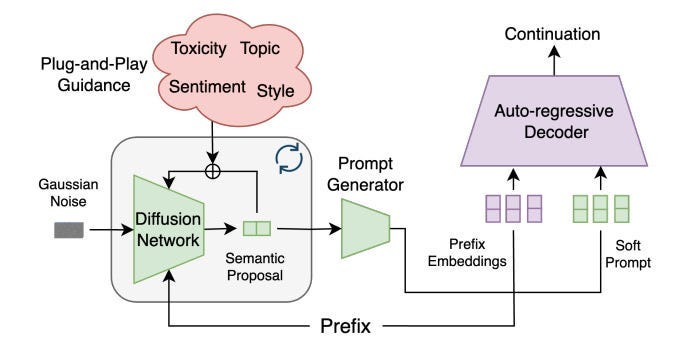
This was part of the philosophy around Diffusion Guided Language Modeling, one of my favorite papers from 2024. The authors used simple plug and play classifiers to control the latent generation of the system, allowing them to control attributes in a very granular level and even stack controls on top of each other — “Our model inherits the unmatched fluency of the auto-regressive approach and the plug-and-play flexibility of diffusion. We show that it outperforms previous plug-and-play guidance methods across a wide range of benchmark data sets. Further, controlling a new attribute in our framework is reduced to training a single logistic regression classifier.”
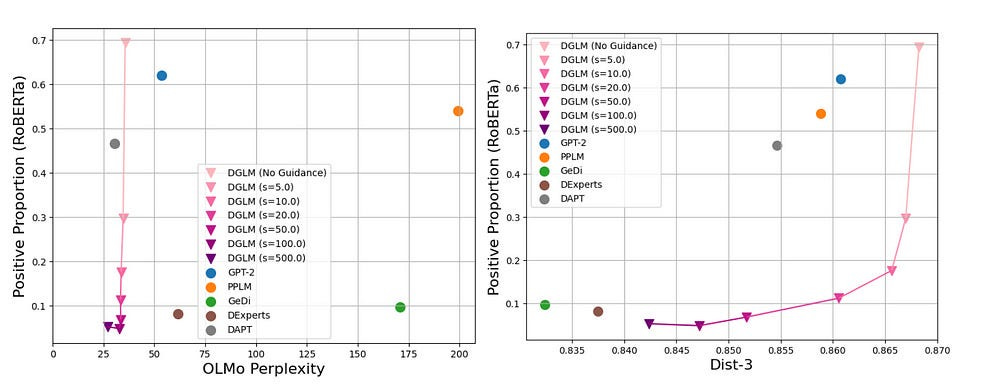
The results are honestly to die for — The framework maintains high fluency and diversity in generated text, indicating that the guidance mechanism does not come at the cost of language quality or creativity. The chart shows us that DGLM can nudge generations towards the desired goal (generate text with a negative sentiment), while keeping fluency (no major increase in perplexity) and minimal reduction in creativity (<4% drop in Dist-3)
The opposite is also achieved, guiding the system towards positive generations with great results, showing the generalization of this method-
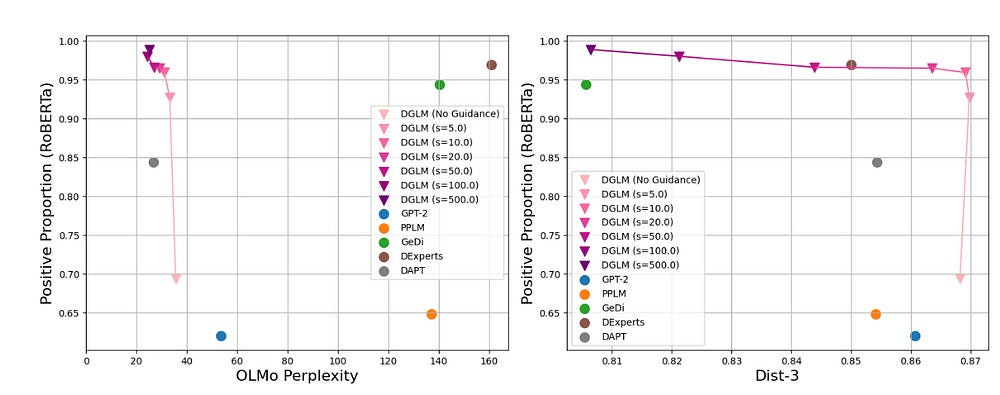
It’s interesting that the performance on nudging towards positive generations doesn’t maintain creativity as much. I guess AI (and thus our training data) is more creative being a dick, than it is being nice. “All happy families are alike; all miserable ones are unique?”
Preliminary experiments demonstrate the potential of DGLM for compositional control, enabling the simultaneous enforcement of multiple attributes like sentiment and topic. The table shows that DGLM can guide its generations on different sentiments, simultaneously based on specific topics-
2.5 Architectural Freedom
Here’s the quiet killer: Right now, only transformer LLMs get to reason. The reasoning lives in the same system as text output, built on transformer decoding.
Unbundle reasoning and any architecture can participate.
Diffusion models for diverse hypothesis generation. State-space models for long contexts. Memory-augmented architectures for long-horizon planning. Symbolic systems for formal verification. Pick the best component for each part of the reasoning stack. Swap them when better ones show up.
Labs can build models that excel at specific subtasks rather than forcing every architecture to be a mediocre generalist. Reasoning infrastructure becomes the universal adapter that composes specialized components.
When a better open-source model drops, you don’t retrain your reasoning system. Swap the generator. The reasoning capability persists and gets amplified. If the unbundling follows it’s natural progression, you might even get granularly composed LLM workflows (we use the superior multimodal reasoning of Gemini and combine it with the superior stylistic drafting of GPT 4o). All this will allow the LLM ecosystem to compound and specialize (unlocking the next stage of Jevons Paradox for intelligence); something that’s non-negotiable for large scale AI diffusion into the biggest challenges of our times.
2.6 Ecosystem Effects
Once reasoning moves out of weights, it becomes a shared layer.
Legal reasoning built by one team (probably us, Harvey, Legora, and the rest are really bad at actually doing their own AI work) gets reused by healthcare AI, policy simulators, negotiation engines. Verification modules become market primitives rather than internal assets.
What happens next is what always happens when reusable infrastructure enters the game. Best-in-class modules emerge. Adoption concentrates. Improvement compounds.
Databases. Linux. PyTorch. All powerful case-studies of this concept.
You don’t need fifty companies building slightly worse compilers. You need one that works, and everyone else building on top of it.
Reasoning follows the same logic. But only when it lives outside the weights. This might seem idealistic, but this is already possible. A few weeks ago, we released our report on how we built a model agnostic framework for reasoning with any models. It could take any hugging face model and induce reasoning like performance gains inside it.
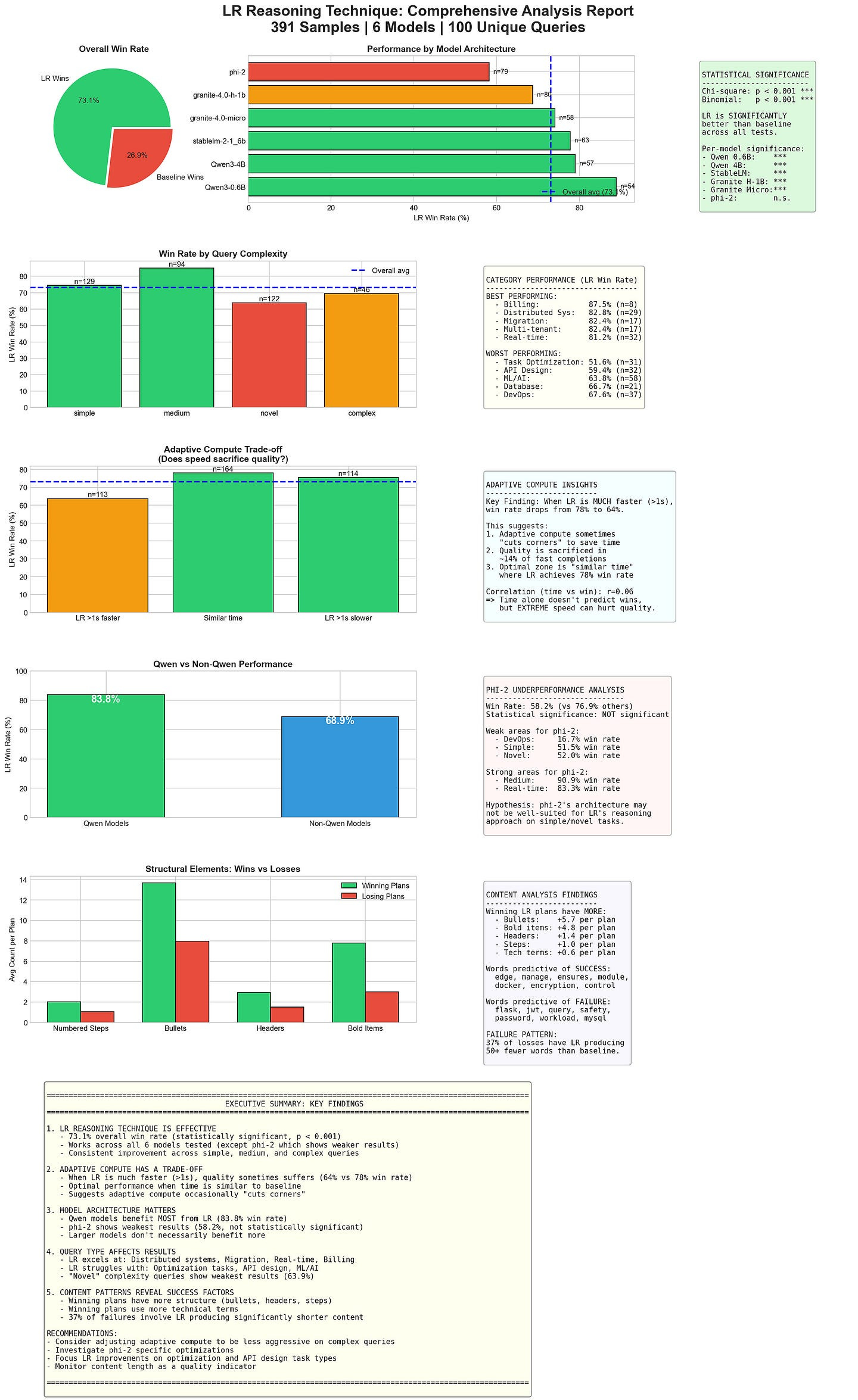
This system required no specialized training (except for our base judge, which was 50 cents) —
You take a prompt. Pass it through a frozen model.
Instead of decoding tokens, you grab a hidden state — the internal representation of the model’s current “thought process.”
That latent gets projected into a shared reasoning space. Every encoder we use projects into the same space. Why? Because we want to swap out models without retraining everything downstream. Evolution, judging, aggregation — all of it happens in that space.
Once you’re in that space, you treat reasoning as a population problem.
You generate a bunch of nearby candidates — each a slightly different internal variation of what the model might be planning to do.Those latents go through a basic evolutionary loop: mutate, score, select, repeat.
A small, trained judge evaluates them. No decoding. No tokens. Just latent-in, score-out. There’s another judge that handles passing the actual mutations. This allows us to do things like monitor the entire state w/o influencing decisions, only mutating the strong chains (why waste resources nurturing the weak?), and work in multiple judges for different attributes if we feel like it.
Once the best candidates survive, you decode. The open source version uses the outputs to influence RnG (I didn’t really want to train a whole separate decoding system) but you should actually aggregate them with a specialized system and condition your generation on the latent for maximum benefits.
There are several flaws with this implementation, but as stated in our breakdown of this system (and our much better variant that powers Irys, the best Legal AI platform), the point of this repo was to establish a floor. Even our very simplistic (and sometimes obtuse) implementation of a reasoning infrastructure is able to work across models to boost performance (all with a 50 cent judge). Think about how useful a proper reasoning infrastructure could be. Our report about the system, it’s flaws, and what’s coming next can be seen here.
PS, you don’t have to take my word on it re performance. You can try it yourself here. We open sourced it to let people start playing with it. If you make major contributions to this infra, we will even pay you (check the readme for details).
PPS: Over 2026, atleast 2 different big tech companies will release models that start to adapt our philosophy of external judges and mutations. Mark this article for that time.
Conclusion: The Brave New World of Reasoning Infrastructures
For most of history, reasoning was private. Locked in heads. Then in papers. Now, in weights.
Opaque, sometimes. Non-transferable. always. Good ideas died in transit because the reasoning behind them couldn’t travel.
We’ve accepted this so long we started believing it was structural — that real thinking couldn’t be shared, only performed.
Reasoning infrastructure breaks that assumption. You can trace how a strategy evolved. Patch a failure path without retraining the thinker. Build judgment that survives its creators and compounds across teams.
The last generation built models that could speak intelligence. This one will build systems that can hold it. And when that shift completes, the smartest thing on Earth won’t be a model. It will be the system around it.
Thank you for being here, and I hope you have a wonderful day,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. :
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819
Really interesting piece Devansh!
Thank you for this excellent article. I agree. LLMs can generate language but thought is computational and requires discrete steps.