
The Illusion of Reasoning: Is Meta’s Code World Models Overrated? [Breakdowns]
How execution traces expose both the promise and brittleness of world models for code

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
Code isn’t natural language with stricter grammar rules. When you write prose, ambiguity is tolerable, even useful. When you write code, every character maps to a precise operation in a deterministic state machine. The structure of a codebase — modules, dependencies, execution flow — has little analog in how humans organize written language. This is why being multilingual doesn’t make you a better programmer. Or why so many developers struggle to communicate clearly. The skills barely overlap.
Every code model shipped in the last two years treats code like language. They learn what code looks like by ingesting billions of tokens of static text, then predict what should come next based on pattern matching. They’re sophisticated autocomplete, trained on syntax without semantics. Ask them what happens to a variable three nested loops deep and they’re guessing based on what they’ve seen in similar-looking code, not simulating the actual execution.
Meta’s Code World Model is the first serious attempt to engineer a solution to this ontological mismatch. The model trains on 120M Python execution traces — line-by-line state transitions showing exactly how each operation mutates program state. It trains on 3M trajectories of agents solving real software engineering problems: running tests, reading errors, editing files, failing, retrying. The goal is teaching the model what code does, not just what it looks like.
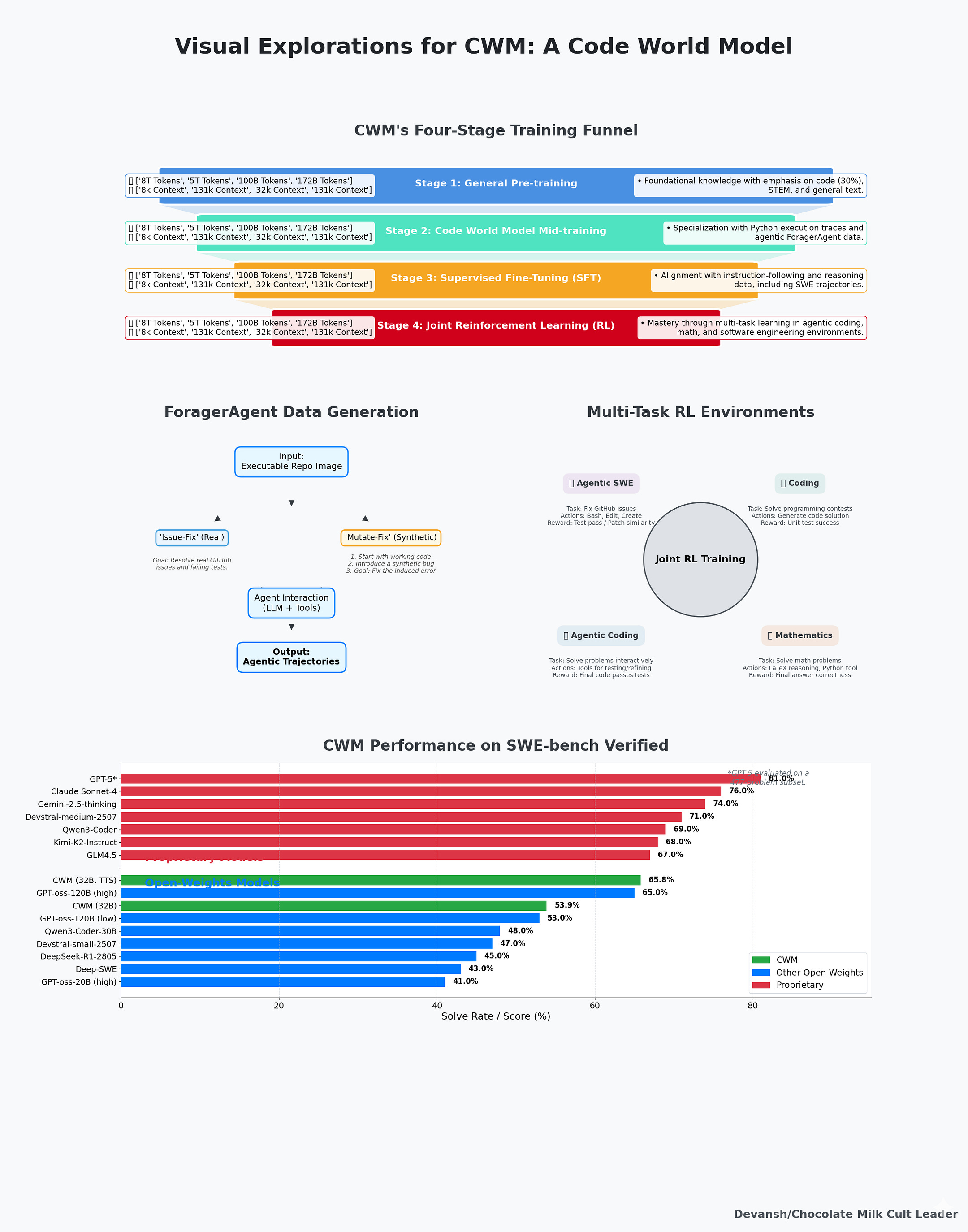
I was originally looking to do a deep dive on the system and the technical decisions it makes, but I realized that there was much more to learn in where it failed, instead of what it did well. We will build this article around exploring the following questions —
Does execution grounding create actual reasoning or just better performance on tasks that look like the training data? CruxEval jumps 45% → 74% but SWE-bench gains are modest and fragile. The model learned a simulator for its specific environment, not general computational physics.
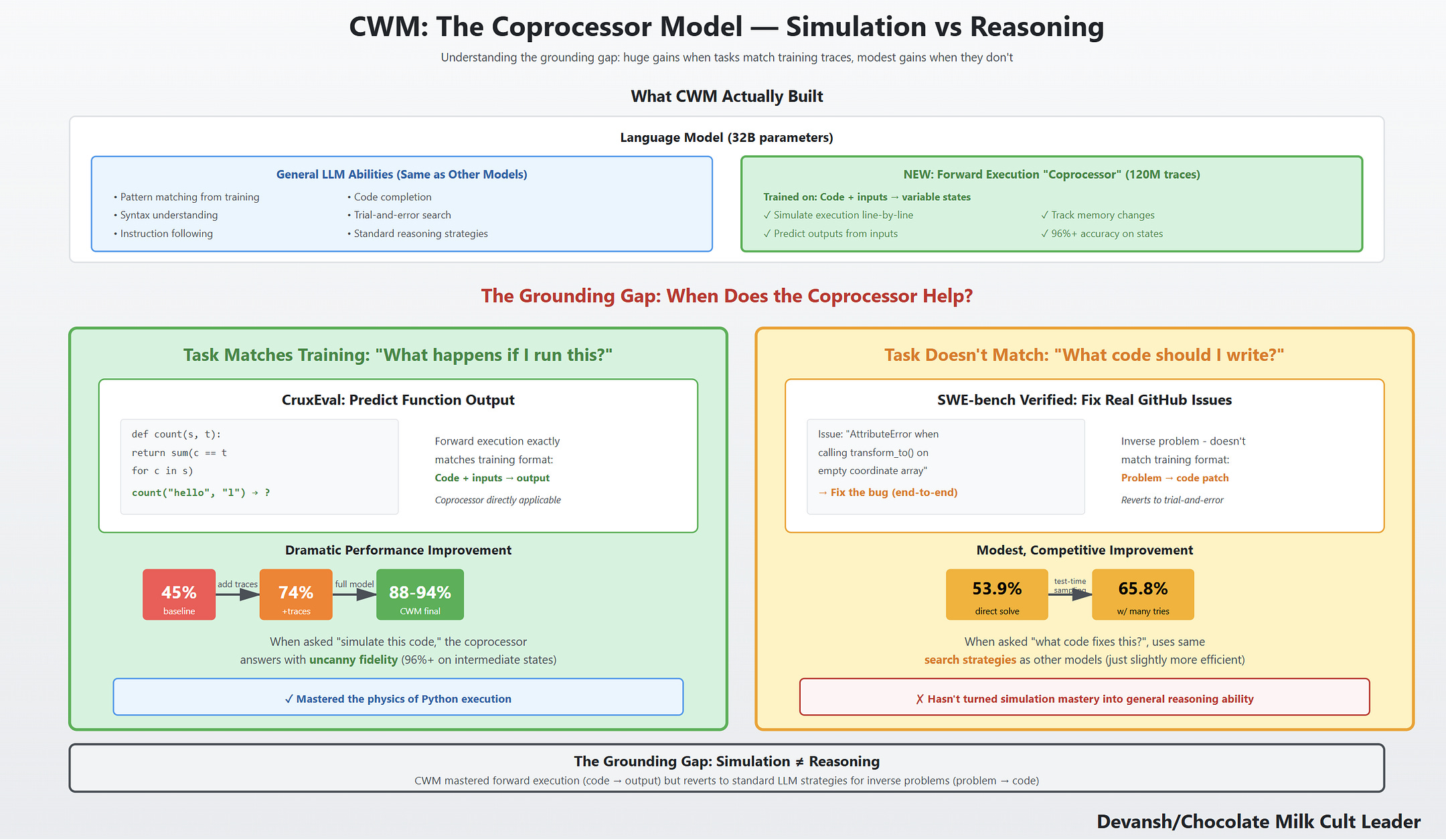
What causes the portability failures and can they be fixed? Performance tanks 16pp when you change the harness, 12pp when you remove tools. Is this distribution shift you can solve with more diverse training, or a fundamental limit of learning environment-specific dynamics?
Where does value concentrate when models commoditize but data engines compound? The factory for generating verified trajectories at scale is the actual product. How does this change the landscape both for large scale incumbents (who can afford the infrasture to run this at scale) and new players (who will have to create specific optimizers) in the coding model space and the ones serving them.
What adjacent domains could benefit from execution grounding, and what are the actual barriers? The approach is Python-specific. Generalizing to other languages requires language-specific tracing infrastructure. Generalizing beyond code to other deterministic systems (legal logic, drug simulations, financial models) has different technical requirements and likely different failure modes.
And who captures value in a world where the research is open but the infrastructure is closed?
CWM proves execution grounding at scale is possible. What it doesn’t prove is that this becomes the dominant paradigm. Let’s figure out what actually works.

Executive Highlights (TL;DR of the Article)
The Core Shift
Traditional code LLMs = autocomplete on syntax.
CWM = trained on 120M Python execution traces + 3M agent trajectories, grounding code in execution, not just text.
Result: strong gains on execution-matched tasks (CruxEval 45% → 94%), but modest, fragile gains on real-world tasks (SWE-bench).

Illusion of Reasoning
CWM simulates execution well, but doesn’t plan.
Gains vanish in multi-step problem solving: it still “patch–run–retry” like peers.
Structural ceiling: traces improve fidelity, not abstraction or planning.
Performance collapses when environment shifts:
Harness changes: –16pp.
Tool restrictions: –12pp.
Different scaffolds (tmux sessions, diff vs. whole-file edits): –20pp+.
Three brittleness clusters: semantic locality (Python-only), edit-grammar dependence, agent–environment overfitting.
The RL Trap
RL doesn’t create generality; it amplifies shortcuts (prefers
<tool: edit>because reward is clearer).Mitigation via diversification is costly (new simulators, randomizations, retraining).
Core critique: RL = “expensive way to overfit.” Real fix requires concept modeling and abstract operations transferable across environments.
The Factory, Not the Model
The real moat is trajectory production + verification:
35k Docker repos → 3M verified trajectories → 180–270M container runs.
Verification is the bottleneck, not compute.
Incumbents (GitHub, JetBrains, Nvidia) already sit on execution telemetry; startups face massive infra bills.
Market + Strategic Implications
Platform consolidation: IDEs/CLIs/Clouds integrate CI to own execution data
Vertical fragmentation: each domain (finance, bio, avionics) will need its own execution/verification pipeline.
Execution-as-a-service: new market for selling verified trajectories.
Neural vs symbolic split: neural for flexibility/compression, symbolic for correctness/closed domains → eventual hybrid.
Geopolitics & Sovereignty
Factories resemble fabs: high fixed costs, compounding yields, fragile supply chains.
Sovereignty risk: need domestic infra for code corpora, execution, verification, and frontier models.
Policy playbook: fund national execution/verification centers, treat simulators as export-controlled assets.
The Generalization Tax
Extending CWM to new domains costs $10M–50M each.
Requires defining state space, building execution infra, generating verified trajectories.
This drives vertical winners, not horizontal platforms — mirroring societal fragmentation into niche realities.
Bottom line: CWM proves execution-grounded coding models are feasible, but also exposes their brittleness, cost, and dependence on infrastructure. The value lies less in the model than in the factories of verified trajectories. Expect consolidation around incumbents with data pipelines, vertical specialization by domain, and policy fights over sovereignty of execution/verification infrastructure.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Section 1 — The Illusion of Reasoning: What CWM Actually Learned
Meta trained CWM not just on code but on 120 million Python execution traces — line-by-line records of how variables change as programs run.

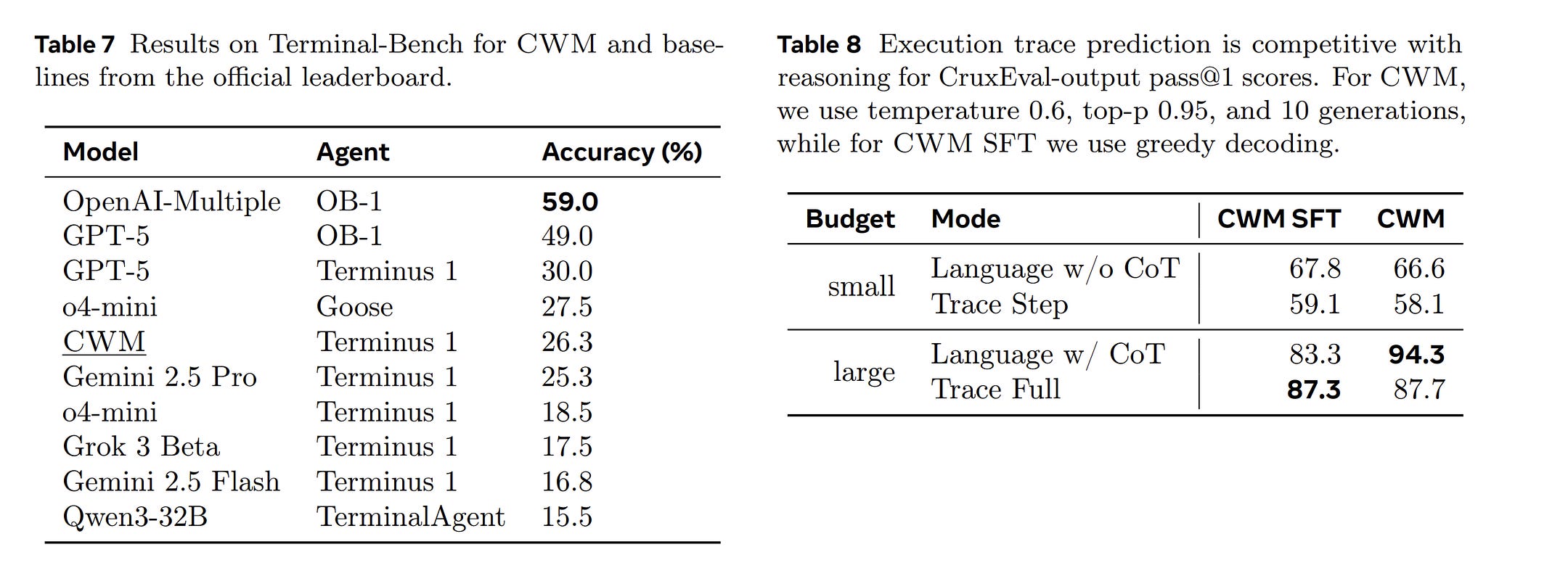
On CruxEval, which directly matches that training setup, the effect is dramatic. The baseline model scores 45.4%. Adding GitHub PR trajectories changes nothing (44.6%). Adding execution traces jumps performance to 73.9%. Adding ForagerAgent trajectories adds only 0.6 points. In the full model, accuracy rises further: 87.7% in strict trace mode, 94.3% in language-mode reasoning, with over 96% of intermediate states exactly right. The gains come from execution grounding, not just more code exposure.
But simulation fidelity on single-function execution doesn’t predict performance on multi-turn software engineering. Those require planning: generating multiple candidate fixes, simulating their outcomes internally, comparing them, and selecting the best one before running anything in the real environment. If CWM had this ability, we’d expect it to solve harder problems in fewer steps, with more direct paths to solutions. Instead, it behaves like its peers: generate a patch, run it in the environment, observe the result, repeat. The difference is that its execution predictions inside this loop are sharper.
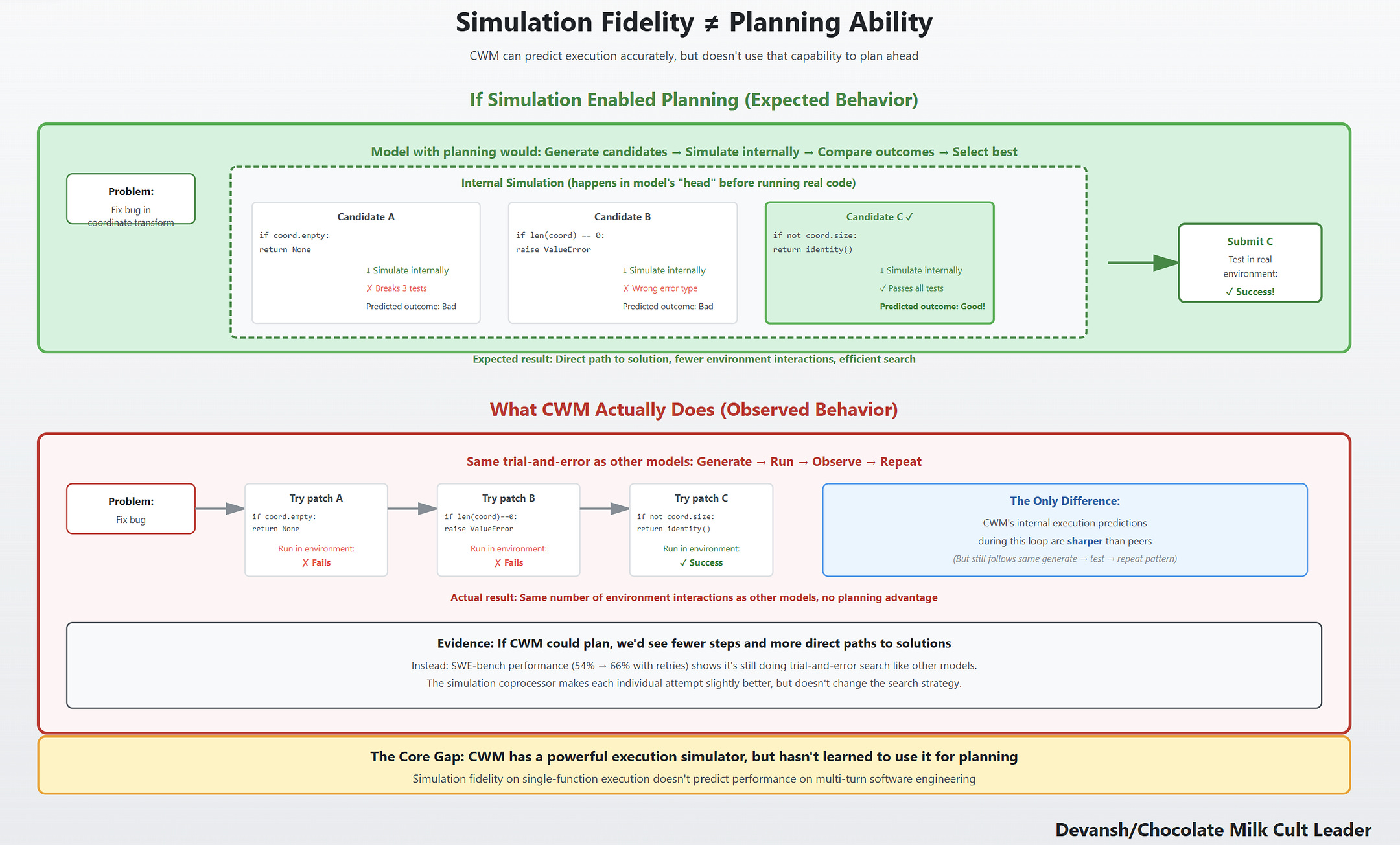
On SWE-bench Verified, that shows up in the numbers. CWM solves 53.9% of issues at base, rising to 65.8% only with heavy test-time scaling (multiple candidate patches plus synthetic tests). The gains come from more retries, not from using the world model to plan ahead.
I really want to applaud Meta for swinging with a risky play and reworking core assumptions (the way they did with LCMs, JEPA, Coconut and other innovations). I want to see this as the revolution that I’m seeing people push this as. I want to celebrate this. But unfortunately, CWMs are a halfway solution. They flirt with some interesting ideas, but they’re too scared to commit to going all the way.
So all we’re left with is an interesting first step in a newer direction. Code World Models could have been so much more, especially when contextualized with other work done by Meta’s AI Labs. But we can’t hate on the researchers too much, especially when the current AI Research ecosystem actively discourages big, risky bets that go against the ecosystem.
The appendix examples illustrate where the simulator helps and where it doesn’t. When a list is modified during iteration, trace mode tracks every mutation correctly while language reasoning stumbles.

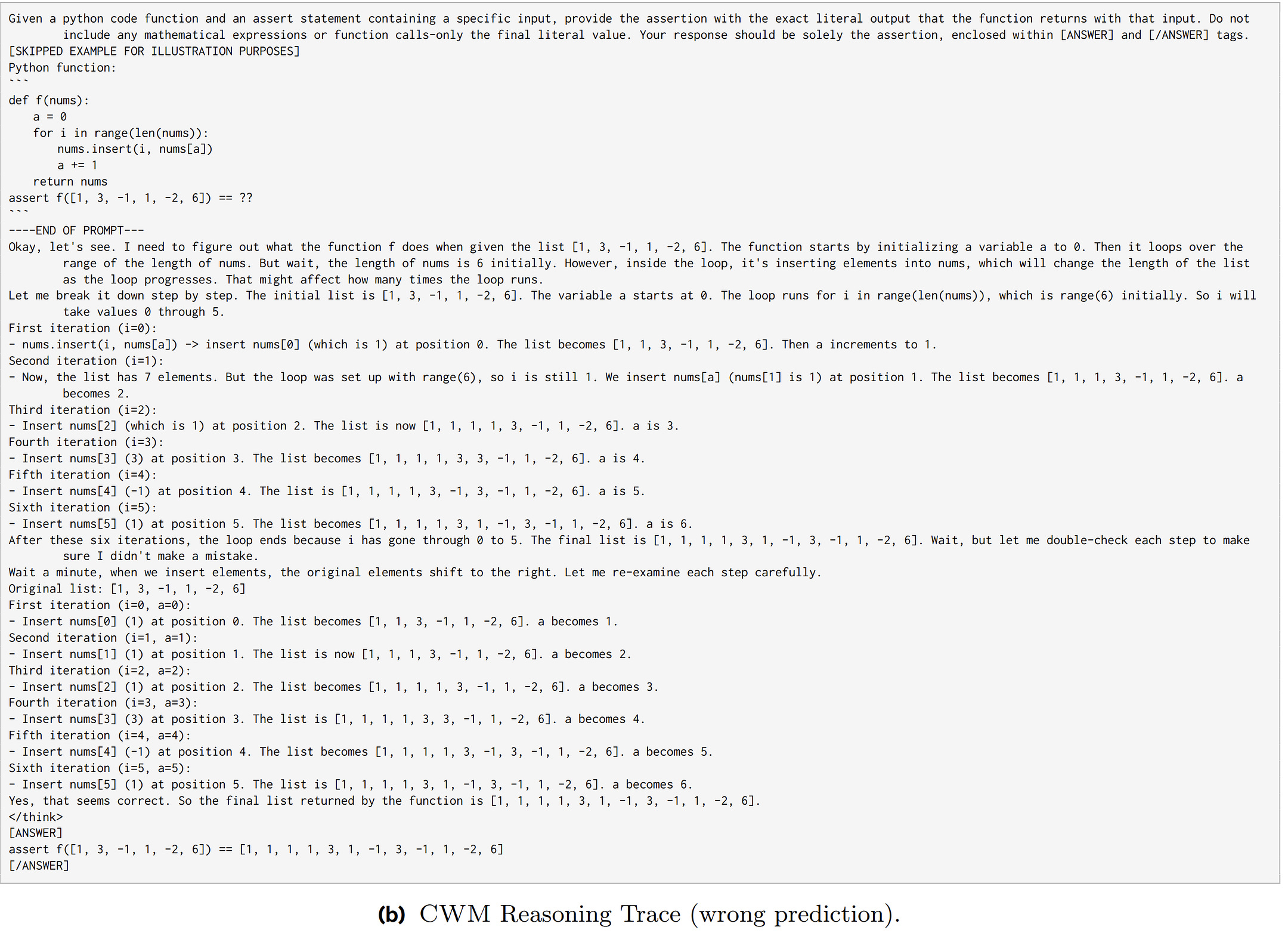
When evaluating a complex nested expression, trace mode guesses wrong while language reasoning decomposes successfully.

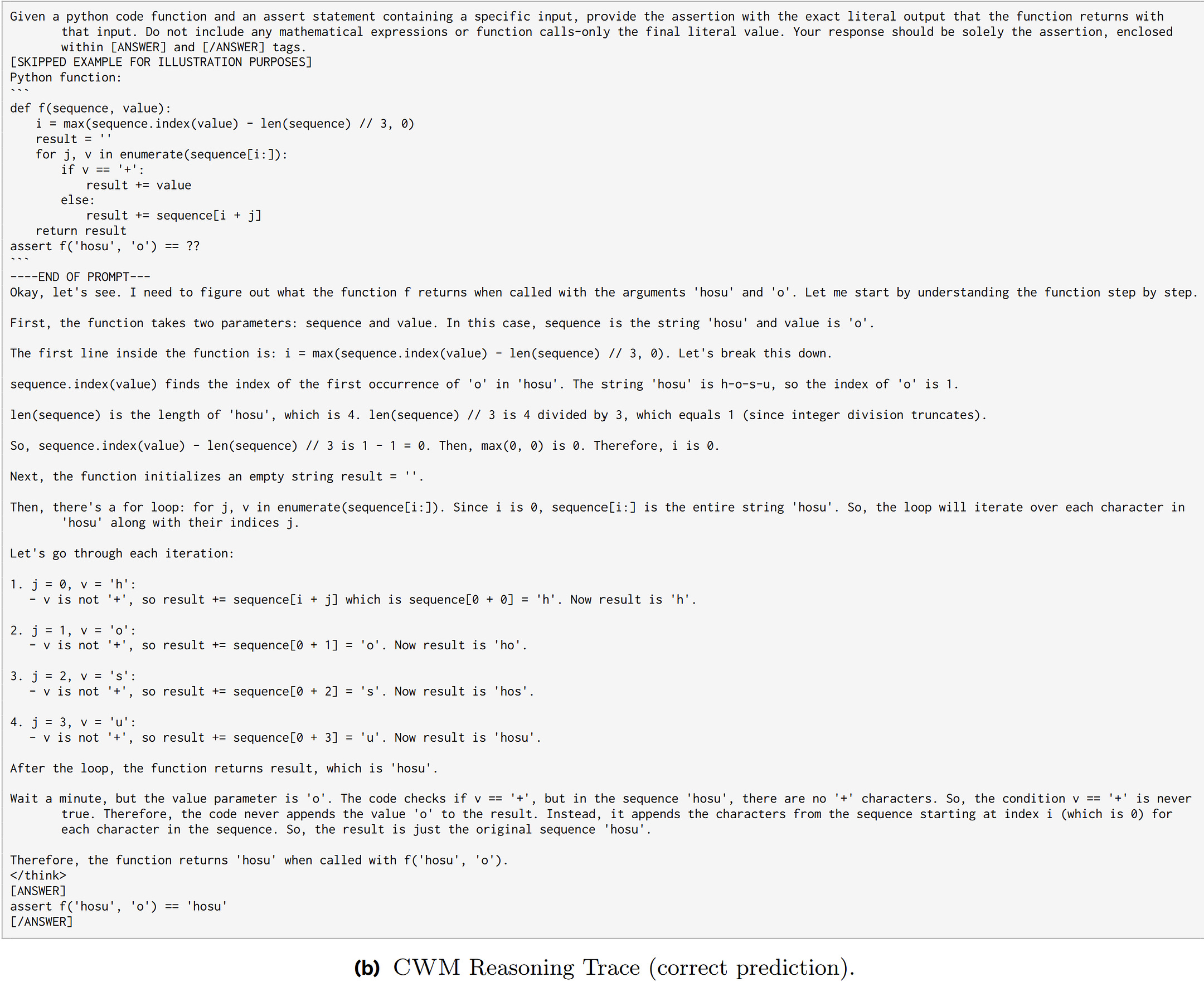
The simulator is rigid but precise; language reasoning is flexible but imprecise. Neither mode implements the plan-then-execute loop — both are just different interfaces to the same simulator.
The decent SWE-bench performance comes from imitation learning, not planning. The 3M ForagerAgent trajectories taught it behavioral policies from successful agents — patterns like “when you see ImportError, check sys.path” or “when tests fail on lists, inspect for mutation.” The simulator tightens this loop by making predictions faster and more reliable, but it doesn’t change the underlying strategy.
This is the grounding gap. When the task is “simulate what code does,” the gains are huge. When the task requires planning or abstraction, the gains shrink. This looks like a structural limit, not a data problem. More traces won’t fix it: CWM mastered Python’s operational semantics, but not how to use that mastery for planning. The structural ceiling is something we’ve been discussing extensively in the context of the mathematical limitations of current AI systems, so the theme is definitely crystallizing. Scaling our way to glory is becoming less viable as scaling systems leads to geometric walls, and even this system will hit that sooner or later. This is why I think that RL Environments are a very short-term solution to a deeper isssue, but we will do a whole other deep dive on that.

For now, let’s get back to understanding this reasoning gap and other frailities in CMW’s performances.
Section 2 — Brittle Agents and Gilded Cages: The Portability Failures of Meta’s Code World Models
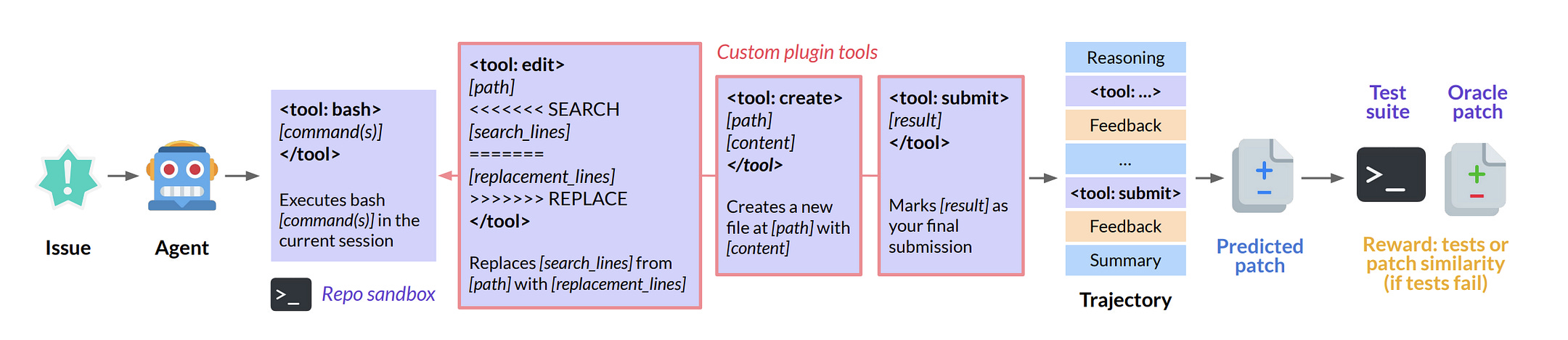
CWM’s 53.9% on SWE-bench Verified looks competitive — until you change anything about how it interacts with the environment. Then it collapses. Its strongest numbers appear only in its native harness: bash shell, custom <tool: edit> and <tool: create> plugins, and a submission mechanism. Alter those conditions, and accuracy drops by double digits.
The failures are systematic:
Harness changes. On Mini-SWE-Agent, accuracy falls to 37.6%. On OpenHands, it ranges from 36.0% (40 turns) to 42.6% (128 turns) before dipping back to 40.8% at 500 turns. Carefully aligned prompts couldn’t prevent the loss, because the policies were overfit to the exact tool-call grammars and return formats of its training setup.
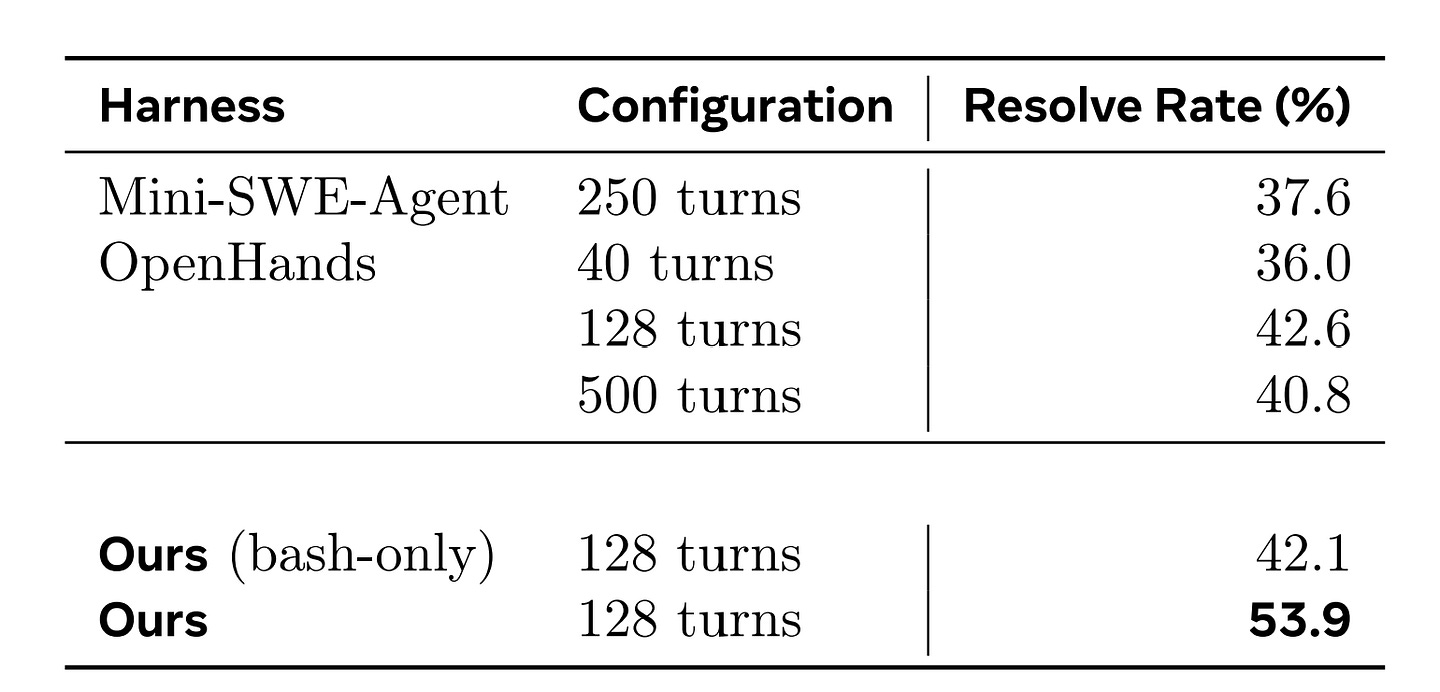
Tool restrictions. Remove
<tool: edit>and<tool: create>and force bash-only operation. Pass@1 drops to 42.1%. The model didn’t learn “file editing” as an abstract operation. It cached “call the edit tool, get back a snippet.” When bash doesn’t provide that snippet, the workflow breaks.Edit-grammar dependency. On Aider Polyglot, CWM scores 35.1% in whole-file edit mode. Diff-tuned models like DeepSeek R1 (71.4%) and o3-pro (84.9%) perform dramatically better. The gap isn’t about language competence — it’s dependence on edit-format conventions.
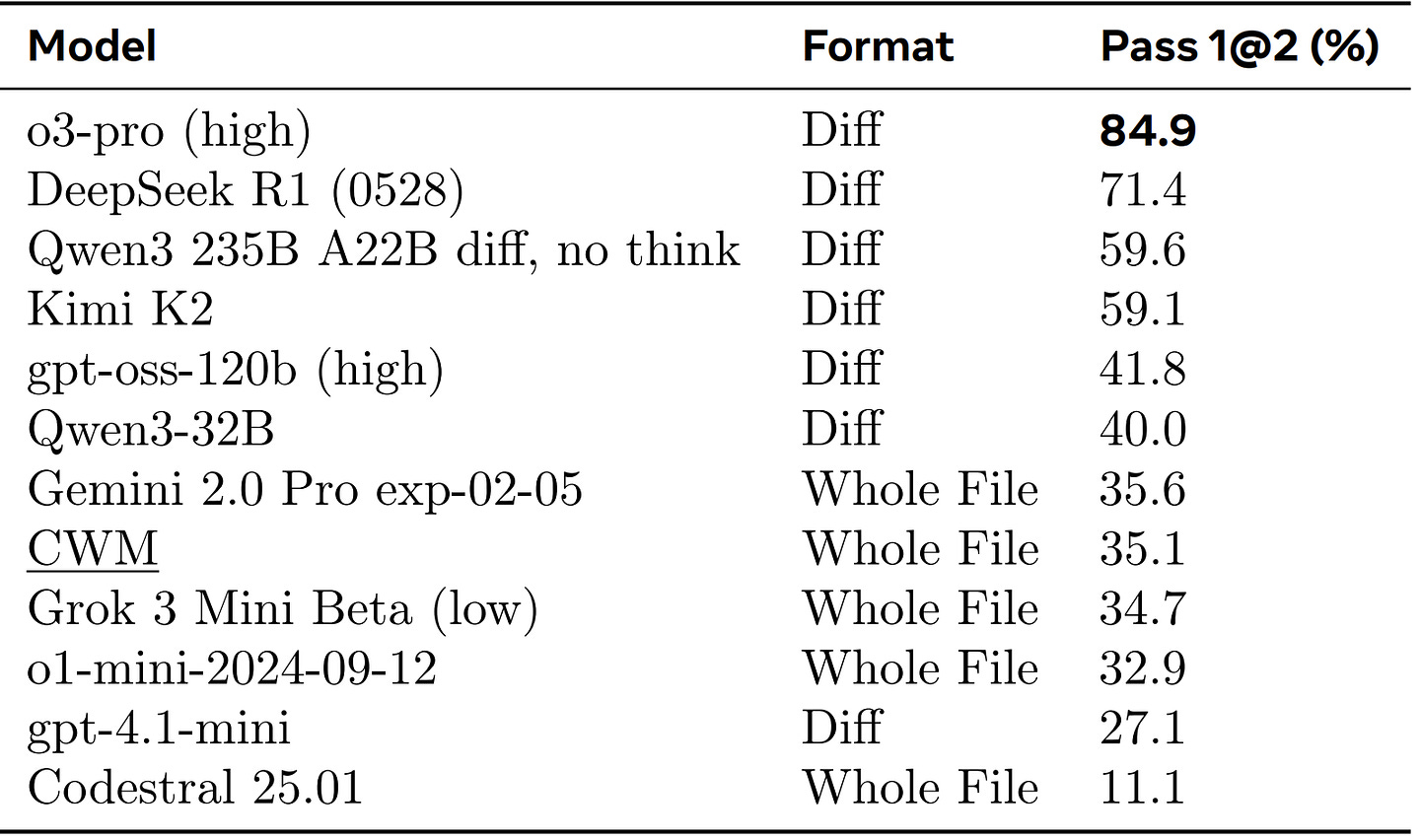
Environment scaffolding. On Terminal-Bench, which runs inside persistent tmux sessions, CWM hits 26.3% with the Terminus-1 agent . Same bug-fixing tasks, different scaffolding — persistent sessions, altered tool conventions, new turn cycles — and the cached policies collapse.
These breakdowns cluster into three portability failures:
Semantic locality. The execution simulator is near-perfect in Python, but that grounding doesn’t transfer. CWM learned Python’s operational semantics, not general principles of code execution. When pushed into other languages or representations, it reverts to shallow pattern-matching.
Edit-grammar dependency. The model’s performance is entangled with how edits are represented. It treats “diff” and “whole file” not as two encodings of the same action, but as separate skills. That brittleness blocks generalization.
Agent–environment overfitting. RL training taught specific sequences tied to one environment’s APIs, payloads, and rituals. Those cached behaviors don’t survive environment shifts.
And we’re back to Reinforcement Learning. Fuck! I promised myself that I would keep the RL slander to a separate piece. But this piece makes a whole thing of it, and now would be the perfect time to discuss the limitations…
Okay, we’re not going to go full crash out. A quick in and out adventure of why RL is the Bukayo Saka of AI — some solid performances, but extremely overrated and a tendency to be floppy when things matter (and no amount of racism accusations will convince me otherwise). The complete dissection can be done another time.

Why These Failures Trace Back to RL
Understanding why these failures cluster reveals a deeper issue with how the agent was trained. It would be wrong to say RL causes brittleness — supervised fine-tuning on the same ForagerAgent trajectories would produce the same memorization. But RL makes the problem worse by pushing the model to exploit whatever quirks deliver reward.
Take <tool: edit> versus sed. <tool: edit> hands the model a formatted context snippet after every change, which provides a clear reward signal when tests pass. sed doesn’t. RL will learn to prefer <tool: edit> not because it is conceptually superior, but because it yields more consistent reward during training. That bias gets baked into the policy through gradient updates. When you remove the plugin, performance collapses—not because the model can’t edit files, but because RL amplified the shortcut until it became the dominant strategy.
Meta’s Stage 2 diversification shows both the limits and potential of RL. By randomizing tool grammars, disabling plugins 50% of the time, and adding multiple languages, they improved bash-only performance to 42.1% — better than OpenHands’ 36–37%. RL can mitigate brittleness if the reward landscape covers diverse environments. But this mitigation isn’t so much the benefit of RL, but a factor across all deep learning: strategic use of randomness enhances stability and performance of systems, often breaking through training plateaus better than brute-scaling. This is a phenomena we broke down in detail here, but I’m screenshotting the tldr for your benefit below —

But when it comes to RL, the fix is costly: every new deployment demands new simulators, new randomizations, and new RL runs.
The (Really) Stupid Economics of Reinforcement Learning
To get CWM here, Meta built 35,000 Dockerized repos and generated 3 million ForagerAgent trajectories. That’s not training data you can scrape — it’s a custom simulator ecosystem. Each new deployment environment means rebuilding that ecosystem from scratch.
Supervised methods also fail on narrow data, but they don’t force you to maintain full-blown simulators for every environment. RL does. That’s the double cost: brittle policies by default, and high overhead to adapt them.
The Final Verdict on Reinforcement Learning
The takeaway isn’t “RL is broken.” It’s simpler: RL is an expensive way to overfit. It boosts benchmark numbers in one harness, but doesn’t deliver portability. Meta’s results are clear: 16pp drops from harness changes, 12pp from tool changes, 23pp from scaffolding changes. Stage 2 diversification helped, but didn’t solve it.
A true fix would require a different training objective. Current RL maximizes probability of solving tasks in this environment. The better target is: probability of solving tasks in any environment that provides primitive capabilities like edit, run, and test. That means compositional action modeling. Instead of caching “invoke <tool: edit> with this syntax,” the model would represent “file editing” as an abstract node in a graph: read current state → compute a diff → apply changes. At execution time, that plan could be bound to whatever tools the environment exposes—sed, echo, <tool: edit>, or an IDE API.
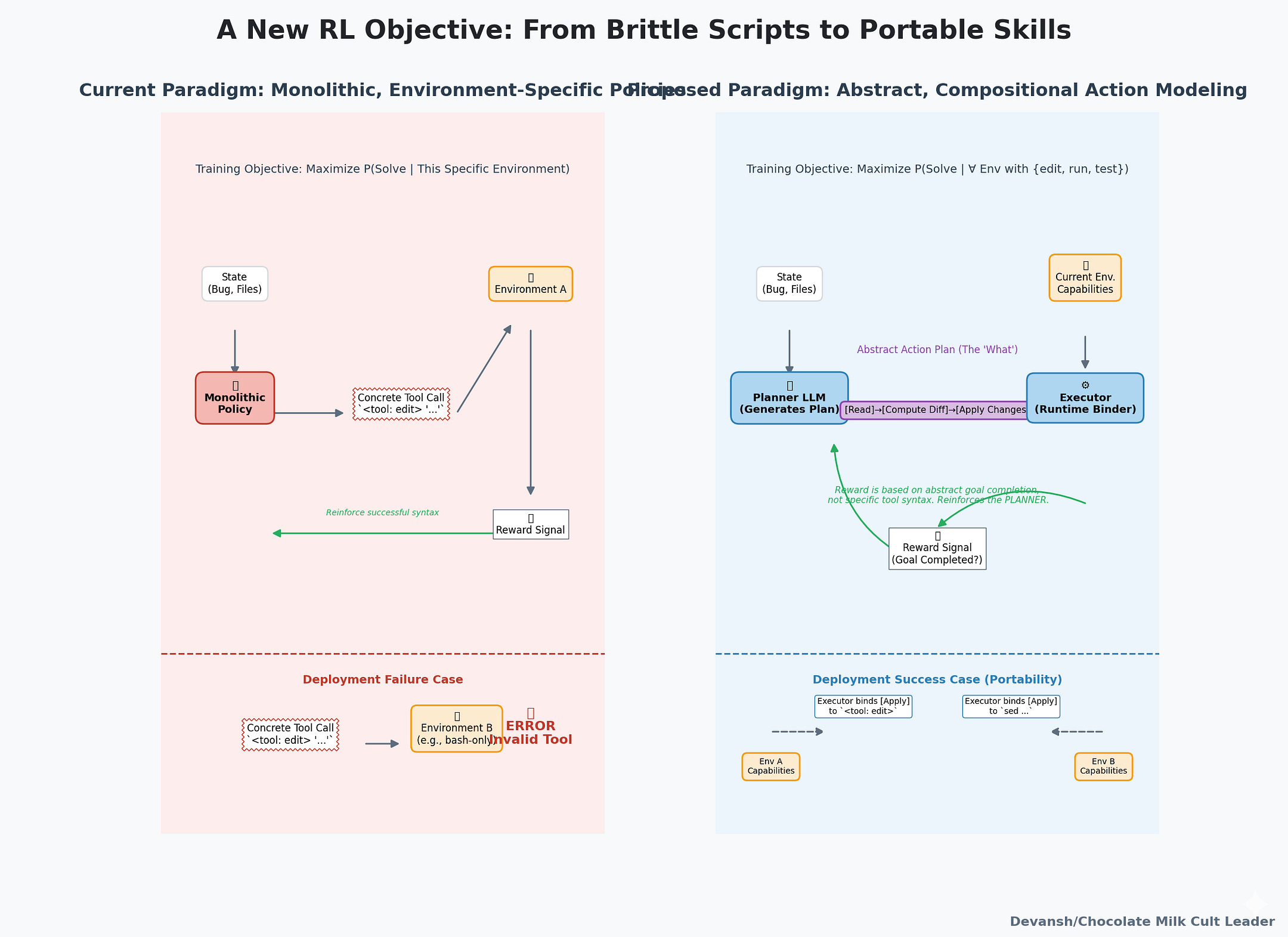
This shift would force agents to learn abstract operations that survive environment shifts, rather than reward-hacked sequences that collapse outside the training cage. Until then, every RL-trained agent — including CWM — remains performant only where it was raised.
So yeah, Reinforcement Learning is the Bukayo Saka of AI. Until you can come at me with a detailed analysis of the TCO around RL, all of you thought leaders can take your neat little thought pieces on why scaling Reinforcement Learning is the future and shove them way up.
Section 3 — What CWM Proves, What It Forces, and where the World goes next
CWM doesn’t prove “world models are the future.” That’s marketing fodder. What it actually proves is sharper and nastier: execution traces work, factories are expensive, verification is hell, and agents don’t generalize. Everything else is extrapolation.

Let’s start with the infrastructure. Meta went beyond just “collecting data” in order to build their industrial-grade meat grinder. 35,000 Docker images, cut from 3,150 repos, yielding 10,200 build states. RepoAgent and ForagerAgent ran 3M trajectories across those images. They even hacked the CI system itself: “We modify GitHub Actions workflows to continue-on-error… implement multiple early exit strategies to capture built-environment states.”
If I put that much effort into planning dates and communicating regularly, my ex would not have accused me of only being emotionally neglectful. In my defense, coming up with ways to Slander Arteta and Man United on this newsletter is wayy more fun than telling her about my day (also now that we’re on the topic of daily updates, unless you’re out reclaiming Constantinople for the Glory of Rome, you don’t need to update me about your day every single damn day, it can wait for when I see you next).
Sorry, where were we? Right, the real implications of CWM.
Then comes the hygiene: “Randomly select up to 40 prior commits per repo” (so data stays fresh + randomness creates diversity), “drop trajectories if Jaccard ≤ 0.5” (so the factory doesn’t drown in duplicates). This isn’t a one-off run. It’s a conveyor belt. Repos evolve, dependencies rot, bugs mutate. Six-month-old trajectories are stale product. Keep the line running or the shelf goes bare.
And verification? That’s the chokehold. Each trajectory isn’t “did it run?” (what we do with traditional verifiable rewards). It’s “did it fix the bug, and nothing but the bug?” Which means: run the tests, confirm they fail, apply the patch, rerun, confirm they pass, prove the resolution was necessary and sufficient. For synthetic bugs: mutate the AST, verify the tests actually break, then verify the patch fixes that and nothing else. Every step is another container execution. At 2–3 runs per trajectory, 3M verified examples = 180–270M Docker-minutes = 3–4.5M Docker-hours. That’s six figures of cloud burn just to say “this data is clean.” Verification is the slow step on the assembly line.
So what?
Getting the obvious out of the way — Incumbents who already sit on execution telemetry win. GitHub sees every PR + CI run. JetBrains sees every compiler scream. Nvidia sees every CUDA kernel die. Claude Code, Augment, etc, all see changes that were accepted and not. For them, verified trajectories are the free byproduct. For you? They’re a $10M infrastructure bill.
What this means is interesting. Suddenly, Models don’t transfer as well. CWM’s own portability numbers (drops of 12–18pp outside its harness) prove it. A GitHub-trained model won’t survive in GitLab-land. Each environment wants its own champion. Add to that the paper’s deduplication games — fresh commits, near-duplicate filtering, rehearsal schedules — and you see the logic: training isn’t episodic. It’s continuous. This isn’t “big training runs.” It’s industrial process control.
This changes the kinds of coding startups that become viable. Forget “general coding models.” Without execution + verification infrastructure, you’re capped at niches incumbents don’t care about. So you get coding startups that try to serve the niches in their field by wrapping around general models (apps play), or they build specific verifiers and reward models to serve the custom rewards to the major model service providers (going towards the infra layer).
Essentially, to avoid the insane capex required to follow this constant learning, we will see new coding startups built around plugging into the ecosystem and enhancing players instead of taking market share for themselves.
This reworks the core thesis for how many startups are funded (consolidation of an existing player/value capture in a different part of the value chain instead of direct disruption), so let’s reiterate the implications more explicitly. I expect that this will lead to —
Platform consolidation. If execution environments are the moat, then owning them is the acquisition game. IDEs and CLIs will swallow CI, clouds will bolt on developer tools, git hosts will roll execution. Not for product polish — for data sovereignty.
Vertical fragmentation. Every domain has its rig: avionics labs, backtesting engines, device farms, biotech automation. Portability failures mean each domain spawns its own specialist. Expect dozens of vertical winners, not three horizontals.
Execution-as-a-service. If verification is the bottleneck, someone will sell it. Not compute, but verified rollouts. Pay per “clean trajectory.” The moat? Owning validators, amortizing infra. That’s not AWS-style cloud. That’s fab-style chokehold. And once again we’re back to the Verifier Economy concept that we’ve been talking about extensively.
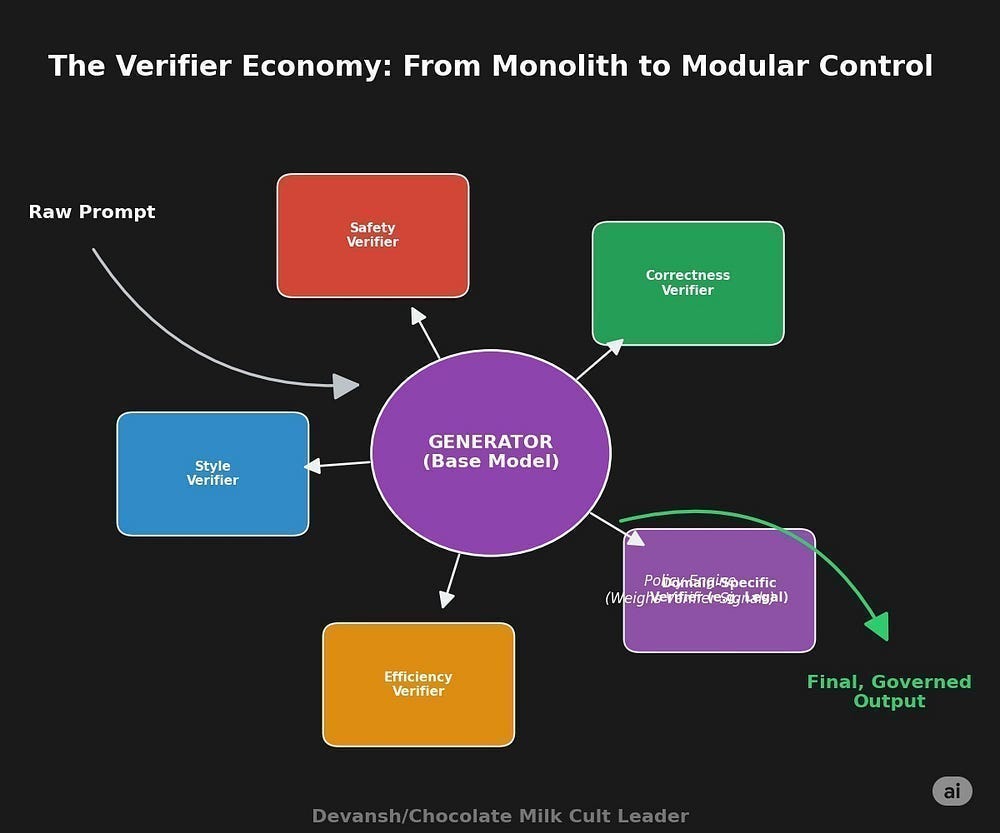
Next, we can also expect more bifurcation in the intelligence models/setups. Neural CWM hits ~96–98% state fidelity; Python’s symbolic interpreter hits 100%. Why bother with neural? Because, as the paper itself admits: “This less-structured format allows injection of semantic context… and compressing traces by skipping uninteresting parts.”
On the other hand, Symbolic runs everything, no skip, no annotation, no generalization to unseen libs. Neural trades perfection for flexibility. The line is surgical: symbolic where correctness matters, neural where compression and context matter. And given CWM’s portability failures, symbolic looks even better in closed domains — tax codes, aviation regs, payment rails.
The conclusion isn’t so much a split (as some people believe), but a synthesis of the styles. Borrowing from DeepMind’s AlphaGeometry, you can have the neural bit for ideas/planning, and then have the symbolics come in for precise verification.

You could also use the neural bit to create symbolics on the fly for custom verifications/optimizations. This is the philosophy taken by English to SQL conversions. The LLM takes the chaotic bit (user query, unspecified setup) and converts it into SQL/another DB query, which is more precise and will run.
In both cases, this follows the Verifier Economy path of turning intelligence composable. Suddenly, instead of relying on prepackaged models, we will increasingly see customized configs, where you combine different orchestrators, worker models, and verifiers to build your own Pokémon team. The accelerated trend towards MoE is the first step towards this.
Finally, let’s zoom out to the geopolitics. Trajectory factories share the same profile as Fabs: high fixed costs, compounding yields, fragile supply chains. The dependency chain is clear. You need:
a diverse code corpus
execution infra to run it
frontier LLMs to generate trajectories (or you pay Synthetic Data Providers)
verification suites to prove them.
Miss one, you’re dependent on open-source, foreign clouds, U.S./China labs, or proprietary validators. That’s the sovereignty risk. The policy playbook writes itself: fund domestic code hosting to grow the corpus, build national execution/verification centers (supercomputing for ground truth, not just training), ensure domestic frontier LLM capacity (you don’t have to train from scratch if you can piggyback on another system), and treat high-fidelity simulators as export-controlled assets.
Conclusion: The Generalization Tax and What Comes Next
Building world models for other domains isn’t a matter of rerunning the pipeline. For Rust, you need to instrument the borrow checker to capture ownership state transitions — tracking lifetime annotations, ownership transfers, and memory layout decisions. For JVM, you need concurrent execution traces showing how threads observe memory operations under the memory model. For legal contracts, you first have to define what “execution” even means when the system isn’t deterministic code.
Each domain requires: defining the state space, building execution infrastructure, generating verified trajectories at scale, and training to competitive performance. Based on CWM’s requirements (35k Docker images, 3M trajectories, months of compute), expect $10M-50M per domain. That’s not research budget. That’s why we’ll see vertical fragmentation, not horizontal consolidation.
I bold that out, because most major LLM training/improvement techniques tend to implicitly assume horizontal use across domains. Thus this shift will be a much bigger change than people realize. To quote the a16z Enterprise “AI Application Spending Report” (where startups spend their money) — “We separate applications into those that are horizontal (focused on boosting overall productivity across a company, with anyone able to use them) and those that are vertical (targeting specific roles). Horizontal companies make up 60% of the list, compared to 40% for vertical companies.” (credit Ivan Landabaso for this found, he’s a great resource for startups if you guys are looking)
That’s a pretty big shift. But one that is perhaps not as shocking as it might seem. The impact of transformative technologies on societies has been well documented. What is perhaps less well appreciated is that this also works in reverse: tech is a human endeavor, and thus it reflects the spirit of our times. Massive, winner-takes-all platforms (including massive AI models) were in many ways a reflection of a world first connected by the internet under “one global village”. Now the pendulum has swung the way. Internet communities are perhaps more extreme than IRL, a problem only made worse by personalization, slop, and radicalization. A deluge of information has made it impossible to keep up the “common discourse”, even within relatively niche special interests.
All of these point to an increasingly fragmented society — a post-truth world where people construct their own realities. Therefore, the winning technologies of our coming times will reflect this — adapting to their users and their works, instead of making their users operate within their assumptions.
Some food for thought.
Thank you for being here, and I hope you have a wonderful day,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. :
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819
The methodology Meta is applying is really good. But your analysis shows that the thinking behind it is completely wrong: Already the title of the paper show it. No it isn't a "World Model" not even a "World Model of Code" probably not even a "World Model of Python" (not that the term would make then any sense as it nieche model is the opposite of a world model and the methodology is definitely not a way to build a LLM that has a "Model of the World" no matter how many nieched where it could be applied would be integrated in a model. At least it makes coding modules better, one language at the time. But still it is massively over promising and the opposite of a path for AI model generalization...