
Token Maxing: The AI Industry is Struggling with Measuring Value
Goodhart's Law is impacting AI across the board.

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
The AI market has a measurement problem. A year ago, you could evaluate a new model by looking at its MMLU score or open-source benchmark rankings. Today, those numbers are compromised. Models are routinely trained on the test sets (this is especially bad with the post training of models, which is why the new models are falling apart). Viral demos are heavily curated to hide latency and edge-case failures. Funding announcements are treated as proxies for product-market fit.
The result is a market where the signals decision-makers rely on are decoupling from reality. The metrics have become increasingly niche and decoupled from actual end-user priorities, due to which capital and engineering hours are being allocated based on data that is optimized for optics.
All that to say that the old signals are breaking and the market is scrambling to find new ways to measure the value of their work. We’ll show this manifests in various areas of the AI Industry Value Chain—
“Better” is a meaningless metric. Benchmarks evaluate single dimensions. Real-world capabilities are multi-dimensional. The gap between what leaderboards measure and what production deployments require is breaking standard evaluation.
Token maxing as an internal testing strategy, not a best practice. Tokenmaxxing will not make employees more productive. But it’s still the right bet for foundation model providers because tokenmaxxing allows gives them insights into the limitations of their current systems for live knowledge work. Labs are treating their staff as highly paid beta testers, harvesting their daily workflows to map exactly how models need to handle complex knowledge work to gain an alpha over the rest of the industry. All b/c the traditional measurements of good are completely worthless.
Enterprises are canceling new AI licenses. Tokenmaxxing doesn’t benefit the non model providers where the tools provide baseline value, but they do not justify uncapped per-seat pricing. That margin between “useful” and “indispensable” is forcing a permanent correction in how AI is priced.
Popularity metrics are actively harmful. On the distribution side, social impressions (which were initially a signal for how loved a product was) are gamed and entirely decoupled from enterprise buyers. Startups copying consumer growth playbooks are optimizing for reach that does not convert to revenue. Another deep example of how Goodharting traditional metrics has disconnected outcomes (sales) from traditional metrics that led there.
Deployment partnerships are the only verifiable signal. Integrating a model requires a customer to change their operations and commit engineering resources. It is the only metric a startup cannot fake with a press release (althugh some startups are cooking their books).
Where this goes from here. If traditional metrics fail at verifying capabilities, we need to reengineer our concept of verification to match the new technology.
(A quick note before we jump in: I normally write deep technical dives. Today is different. This is a shorter format for a market shift that doesn't require a 10,000-word essay, but does require your attention. If you find this useful, let me know and I will mix more of these into the rotation.)
Why LLM Benchmarks are Sorry.
Because billions of dollars in enterprise spend depend on capability rankings, the industry requires a single baseline metric for model quality. This is something that the market lacks right now.
The historical approach to this problem was the static benchmark leaderboard. For years, labs used centralized evaluation suites—such as MMLU for general knowledge or HumanEval for coding—to establish architectural superiority. If a model scored 5% higher than its competitor on a standard evaluation set, it was marketed as a universally superior system.
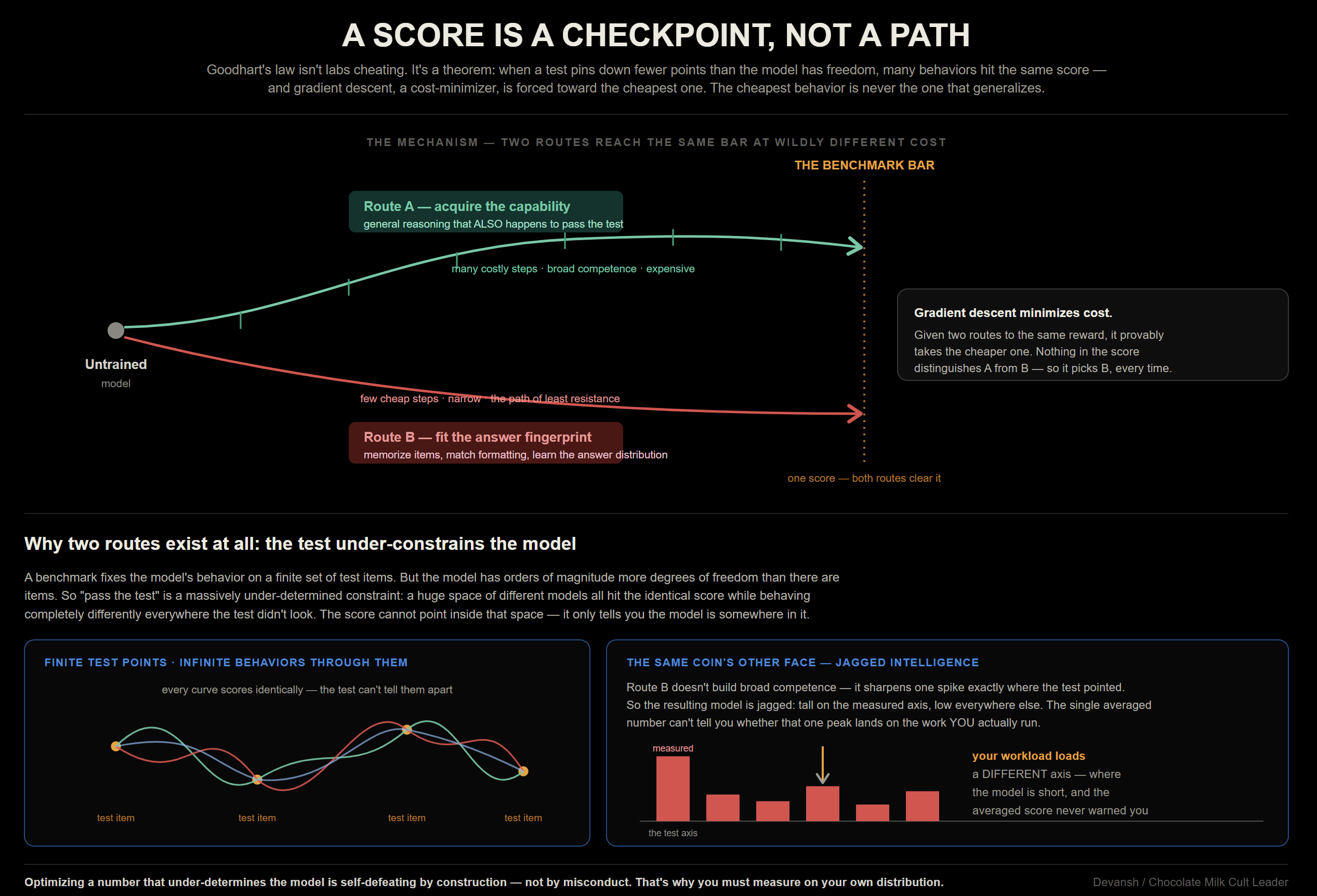
However, due to various reasons, this approach has hit a mathematical and operational wall. Static benchmarks degrade the moment they become performance targets. When a lab’s valuation is tied to an evaluation suite, engineers optimize the training process for that specific test. Evaluation data leaks into the pre-training mix, models are fine-tuned exclusively to match the test set’s exact formatting quirks, and leaderboard scores climb while underlying production capability stays completely flat.

Ultimately, we must remember that capability is a multi-dimensional optimization problem, not a single scalar value. A model that wins a leaderboard by maximizing accuracy on a static test often fails in production because it requires massive memory overhead, introduces unacceptable latency, or lacks reliable error-recovery loops during tool invocation. This dynamic is especially important since no one pays for best output on one individual inference call; people pay for best final work product. This often requires chaining multiple inference calls in different ways (and combining them with various deterministic calls), which dramatically ups the sources of variance and error. This is where benchmarks completely fall apart since the combinatorial variations of evaluations are practically infinite.
This complexity is why enterprises are struggling to optimize knowledge work. There are too many operational variables, and new interfaces constantly shift how users interact with text and code. This disconnect leaves external model providers completely blind to real-world deployment challenges. This blindness is unacceptable when we remember that these labs have raised hundreds of billions on the assumption that they will automate knowledge work, and well, you can’t automate what you don’t understand.
This lack of clarity is where the foundation of one of tech’s most hated trends comes in.
2. Why Token Maxing Is a Great Idea
Evaluating models in production requires continuous telemetry. This operational reality is the foundation of “token maxing”—a mandate from frontier labs requiring their internal employees to maximize their use of generative AI and their internal tools.
The market completely misreads this behavior. Outsiders look at these mandates and assume token maxing is either a financial trick to fake demand for investors, or a crude productivity metric. Let’s dissect why neither holds up.
The fake-demand theory breaks immediately against hardware constraints. Internal usage generates zero revenue and actively burns a lab’s margins. Compute is scarce. Every major lab is fighting internal power struggles over allocating GPUs between internal research and serving external API customers. Nobody burns constrained compute on vanity metrics when they are struggling to serve paying clients.
(And yes, labs lie, but there’s a bit difference between narrative manipulation and active fraud to investors. Trying to pass off internal usage as external demand would lean a lot towards the latter).
If labs aren’t faking demand, the only assumption left is that they are trying to boost employee output (mo tokens—> employee gets more done). But token maxing is not a productivity hack either (something that the critics get right; using more tokens is not going to get you more productive and will likely create all kinds of problems if not careful).
So why do it?
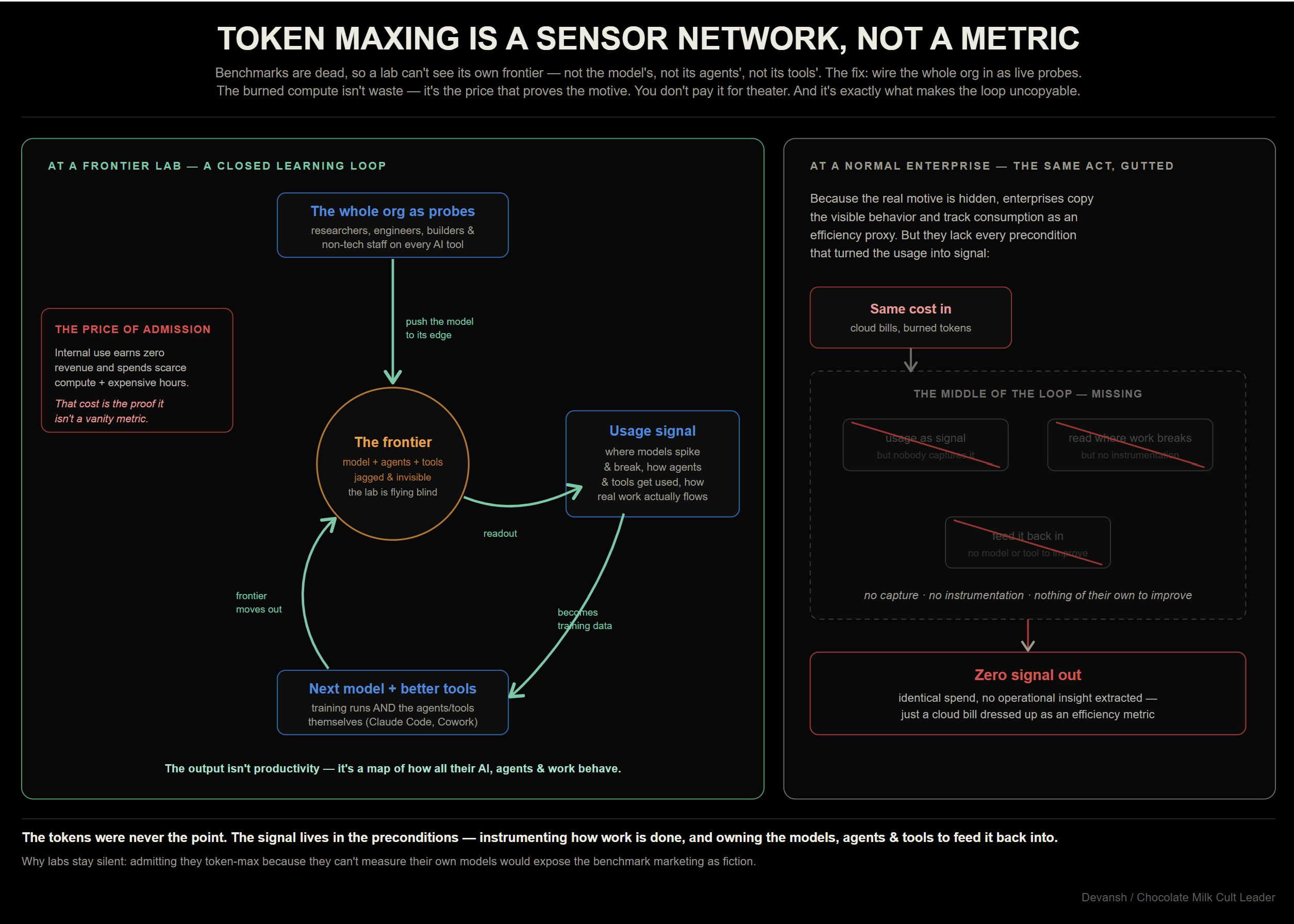
Because standard benchmarks are dead, labs do not actually know the limits of their own models. The capability frontier is jagged, and they are flying blind on billion-dollar infrastructure bets. By forcing tens of thousands of highly paid employees to use AI for everything, the lab harvests detailed signals on exactly where the model breaks, where it spikes, and what structural problems the next training run/engineering run must solve. In other words, this is institutional dogfooding, all to understand usage patterns/pain points that can guide the next generation of building (doubly important because most tech people don’t know non-tech workflows and would just be building in the dark w/o this kind of institutional-level signal extraction).
This seems like a lot more reasonable than whatever is being peddled publicly. You might be wondering why they haven’t clarified this publicly (or at least communicated this to their internal employees to ensure that the employees test it in the right ways instead of trying to game the usage)

The issue is that leadership at these labs can’t reveal this publicly. Confessing that they force token maxing because they don’t understand their own system’s boundaries would destroy any authority they have for making their grandiose predictions (building up hype) and expose their benchmark marketing as fiction (benchmark marketing is very convenient since it lets the labs worry about doing well in one, well-defined task instead of relying on vibes). So they bite the bullet on all the noise being mixed in with the hope that the signal will outweigh the noise.
Let me ensure that you really understand what I’m saying:
Tokenmaxing won’t make individual employees more productive.
It also won’t work for most organizations since they won’t really have a meaningful use for the signals derived and the ROI will be negative.
It is fantastic for frontier labs as IRL data collection.
All the criticisms of token maxing are from people who focus on 1 and 2 without considering 3.
Unfortunately, this secrecy is starting to backfire massively. By definition, most groups are not foundation labs, and thus these groups have a diminishing return on using AI. These groups make up the majority of the customer base for the labs, and they have not been happy with the token maxing outcomes.
3. Enterprises are starting to cancel AI licenses
AI tools were initially sold like traditional software with flat monthly seats, assuming predictable consumption, low marginal costs of usage, and a linear relationship between product usage and value to user. But generative AI breaks this in two ways. The value of an agentic loop is logarithmic: using Codex on the right problem can be very productive; trying to use Codex on every problem will see a massive output falloff (take something like a memo— one memo done fast is useful; a 100 memos published is overtly indulgent and will never be read).
The cost curve, however, is super-linear. As an agent works, the context window grows. Every subsequent step requires reading all previous inputs and outputs. If the model gets confused, it falls down rabbit holes and executes failed bash calls, drastically multiplying the compute required for a single task.
This structural waste is baked into the tools themselves. A product is a direct reflection of the constraints its builders operate under. Because foundation labs mandate unconstrained token maxing internally to gather telemetry, their own engineers never feel the financial friction of a super-linear cost curve. They build agentic systems that default to brute force—re-reading static context, forgetting learned facts, running unconstrained loops, and relearning codebases from scratch. The labs (implicitly) ship tools optimized for their own data collection, not the customer’s cost efficiency.
The labs cannot mitigate this by sharing disciplined, cost-saving best practices with their buyers. They cannot publicly tell customers to strictly constrain their token usage while simultaneously mandating internal token maxing. That hypocrisy would be called out immediately. So they stay quiet and leave enterprise buyers flying blind.
Without those constraints, enterprise budgets break. When Uber deployed Claude Code to 5,000 engineers, per-user costs spiked to $500–$2,000 a month. The company burned its entire 2026 AI budget in four months. Microsoft cut off internal Claude Code licenses for its Experiences and Devices division, forcing engineers back to Copilot CLI because the usage-based bill became unsustainable.
These cancellations permanently decouple token consumption from product-market fit since an enterprise ripping out a tool because the cost didn’t scale with usage is a failure. This leaves AI startups with a massive problem. If high usage metrics are now a financial liability, and real enterprise revenue is stalling behind budget caps, startups have no viable numbers to show investors. Desperate to demonstrate momentum without underlying fundamentals, the market is migrating to the cheapest, most easily manipulated signal available: manufactured popularity.
4. Cluely-fication is Ruining Startups
Let’s take stock of where we are:
Benchmarks are kinda worthless.
Enterprises are leery about purchases since the big name labs publish things that aren’t aligned with their needs (and enterprises typically don’t buy from startups).
All in all, we know that AI can be useful, we just don’t know how useful and when that scaling of utility inverts.
So how does a new founder/startup stand out in this space? How can they prove themselves to investors? Desperate startups and founders are migrating to the next cheapest signal: manufactured popularity.
To understand the most recent iteration of this trend, we must study Cluely. When co-founder Roy Lee faced disciplinary action at Columbia over an AI interview cheating tool, he turned the controversy into a content engine. Cluely set a target of a billion views, hired interns to farm daily TikToks, and leveraged that viral reach to raise a $15 million Series A from Andreessen Horowitz. Founders watch this timeline and assume stunt marketing is the new growth mechanism. Since then, social media has been inundated with cheap rage/engagement bait from founders desperate for a seed check.
(investors have made this problem worse by encouraging this behavior under the guise of community building).
This is a very short-term, immature read of the situation. Cluely proved that controversy can manufacture attention, but that attention does not convert into sales. In March 2026, Lee admitted that Cluely’s claimed $7 million in annual recurring revenue was false. The social reach was real, but the pipeline was an illusion.
Startups/Founders copying this playbook compound the error by applying it to enterprise infrastructure. Selling an AI agent requires CTO actual performance, strict security reviews, and a strong ability to inspire trust. A marketing motion built for a consumer scrolling TikTok at 1 a.m. does not shorten the path to that trust or act as “dev-rel”. Virality is only useful when it builds credibility with your core peer group. Pumping out provocative clips generates raw reach, but attention is worthless if it doesn’t convince your customers that you have what they need.
This collapse of proxy metrics leaves the AI ecosystem facing a hard floor. When leaderboard scores are optimized for PR, unconstrained usage becomes a line-item liability, and social virality fails to build peer trust, the industry runs out of measurements to rely on. Because they can no longer evaluate a vendor based on what a model might do, they are shifting to the only un-fakeable signal left on the board: deep, operation-level deployment partnerships designed to calculate the technology’s actual economic return in production.
And so we’re seeing the rise of AIs new hottest jobs, and partnership model.

5. Deployment is the only remaining signal
When benchmarks are gamed, usage burns budgets, and social virality fails to build trust, the market runs out of abstract proxies. Buyers now demand operational proof. This marks the end of the self-serve API era. You cannot deliver complex corporate transformation through a clean endpoint. You deliver it with engineers on the ground.
Deployment is the final signal because it is too expensive to fake. In May 2026, OpenAI launched DeployCo, a subsidiary backed by $4 billion from firms including TPG, Bain Capital, and McKinsey. Instead of building a traditional sales team, OpenAI acquired Tomoro to secure 150 Forward Deployed Engineers (FDEs) on day one. These engineers do not sell software. They embed inside client organizations to wire models directly into legacy data and core processes. The physical presence of an FDE is the new benchmark.
These embedded teams solve two critical vulnerabilities beyond telemetry. First, they protect the lab’s reputation. When untrained enterprise users brute-force an API and burn their budget, the foundation model takes the blame. FDEs control the implementation to ensure the system operates efficiently and delivers a measurable return. Second, they eliminate churn. A self-serve API is a commoditized endpoint that an enterprise can swap for a competitor’s model in an afternoon. An AI system wired deeply into a company’s core operational logic by an on-site engineering team creates massive switching costs.
This physical integration drives a shift from software licensing to equity swaps. OpenAI recently took a stake in Thrive Holdings, a private equity vehicle acquiring traditional accounting and IT firms like Shield Technology Partners. OpenAI provides no cash. It embeds engineering teams into these legacy companies in exchange for equity. By placing engineers inside messy, high-volume operations, the lab secures structural lock-in and a continuous stream of operational data.
Anthropic has responded with its own $1.5 billion deployment joint venture, while Google has tried to play a similar game by hooking Gemini credits within Google Cloud. All 3 have realized that competing on leaderboard scores yields diminishing returns. The enterprise fight is no longer about who has the best model. It is about who captures the enterprise workflow surface first. The base model is replicable. A proprietary workflow with permanent switching costs is not. Going forward, I’d expect this trend to grow and deeper partnerships to pop up for all the reasons mentioned earlier.
Conclusion: Where Do We Go From Here
Every failed signal in this piece failed for the same reason: it measured something adjacent to the work instead of the work itself.
This distance creates a system where our own traditional proxy measurements lie to us. Benchmarks lied about capability. Token-maxing lied about demand. Virality lied about adoption. All three were convenient fictions the market bought, hoping to avoid a harder truth: that intelligence can’t be scored, it can only be audited.
This shifts the game completely. The next era doesn’t belong to whoever engineers the best model. It belongs to whoever engineers the deepest visibility into how and where AI converts intelligence into margin.
If the old benchmark was “Who builds the best model?”, the new one is far nastier: “Who owns the accounting for intelligence?” The one who can verify intelligence/value more granularly then everyone else will be the winner.
Thank you for being here, and I hope you have a wonderful day.
Dev <3
Want access to a repository containing all of our research? 300+ files containing our notes of various experiments, discussions with cutting-edge teams, and insights into where the industry is headed next. Get a Founding Member Subscription to AI Made Simple. Want to talk to me for details/get my insights into the tech ecosystem? Reach out to me through any of my socials over here or reply to this email.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819
You see the problem clearly. Benchmarks are gamed. Tokenmaxxing is a lie. Popularity metrics are manufactured. Deployment partnerships are expensive and not scalable. You describe every symptom with precision. But you cannot see the solution. You are doing triple somersaults to measure input — tokens, benchmarks, virality, FDEs — when the answer is simple. Measure output. Solved problems. Julies. (I have written on this extensively in my own Medium). Measure Brainpower. 1 Julie = 200 joules. Reproducible. Verifiable. Comparable. The industry is breaking its back trying to infer value from everything except value itself. Stop measuring the flour. Start measuring the bread. The Julie is not complicated. It is just honest.
Good points all. As with any new tech, the industry needs to be flexible and realistic in developing benchmarks. Value, useful output (call it intelligence delivered) is becoming the new and real measure. In 12-18 months the real measure might be something new.