
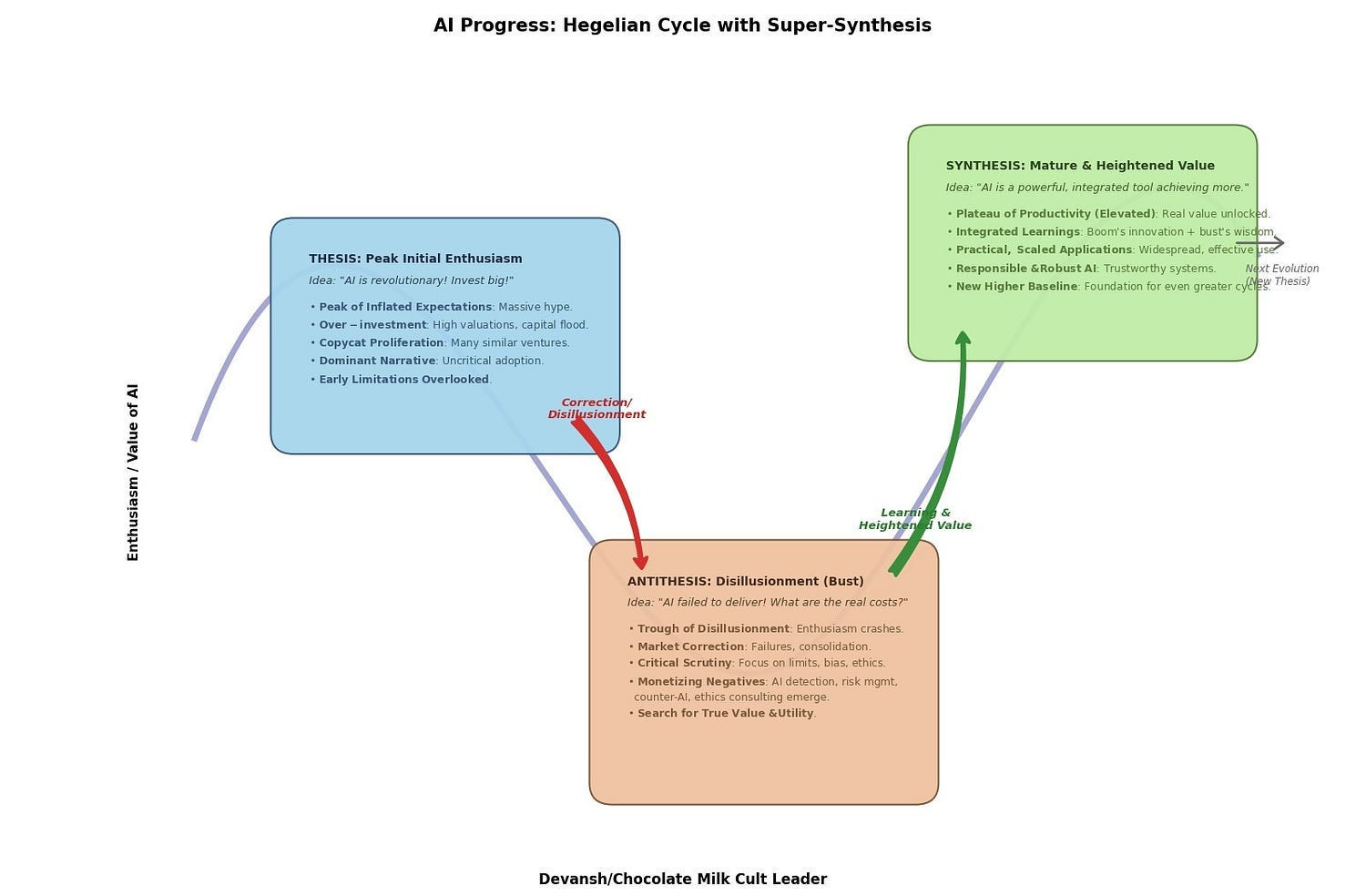
AI is Hitting a Measurement Wall
The hidden physics limit that benchmarks miss, biology solved in evolution, and investors must understand.

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
The human brain runs on 20 watts. GPT-4’s training run consumed megawatts. And yet the brain still wins on most tasks that matter: learning from single examples, long-horizon planning, operating in novel environments without catastrophic failure.
This 100,000× efficiency gap is usually dismissed as engineering immaturity. That explanation is wrong. The gap is a physics feature, not an engineering bug. Biology is computing in a fundamentally different way — operating in a physical domain that modern computers are designed to avoid.
A paper published in BioSystems last month formalizes what that difference is. Ian Todd’s “The Limits of Falsifiability” argues that when systems become sufficiently complex, measuring them as discrete yes/no propositions destroys the very structure you’re trying to observe. Biology computes with signals too weak to measure individually, making noise a key medium of biological computation.

The focus of the paper is on biological systems (which is why it took a while for me to get the breakdown out), but read it with AI in mind, and a whole world of ideas opens up: We’ve built an entire evaluation infrastructure — benchmarks, RLHF, interpretability — on exactly the epistemological assumptions that fail at scale.
This gives us an alternative angle reason for the failures beyond intelligence, scale, or data quality; we are failing b/c we’re hitting measurement walls. The models might be improving in dimensions we’ve defined out of existence.
What we’ll cover:
The physics: Why binary measurement has a thermodynamic cost, and what the Landauer limit means for computation
The biological mechanism: How systems compute below measurement thresholds — stochastic resonance, ensemble detection, sub-Landauer patterns
The translation to AI: Where current systems already operate in this regime, and why token generation is measurement collapse
The diagnosis: Benchmarking as information destruction, RLHF as lossy compression, interpretability as measurement paradox
The implications: What we might not know about systems we’ve built, why scaling might work better than evals suggest, why emergence gets weirder
Where systems go next: Thermodynamic hardware, ensemble architectures, evaluation methods that preserve rather than collapse capability
The investment logic: Why value shifts from FLOPS to Joules/Op, and which vectors resolve the actual bottleneck
We’ve been building brains with brute-force physics. We’ve been measuring intelligence with tools that systematically destroy information about intelligence. The gap between what we measure and what exists is where both the opportunity and the danger live.

Let’s go deeper.
Executive Highlights (TL;DR of the Article)
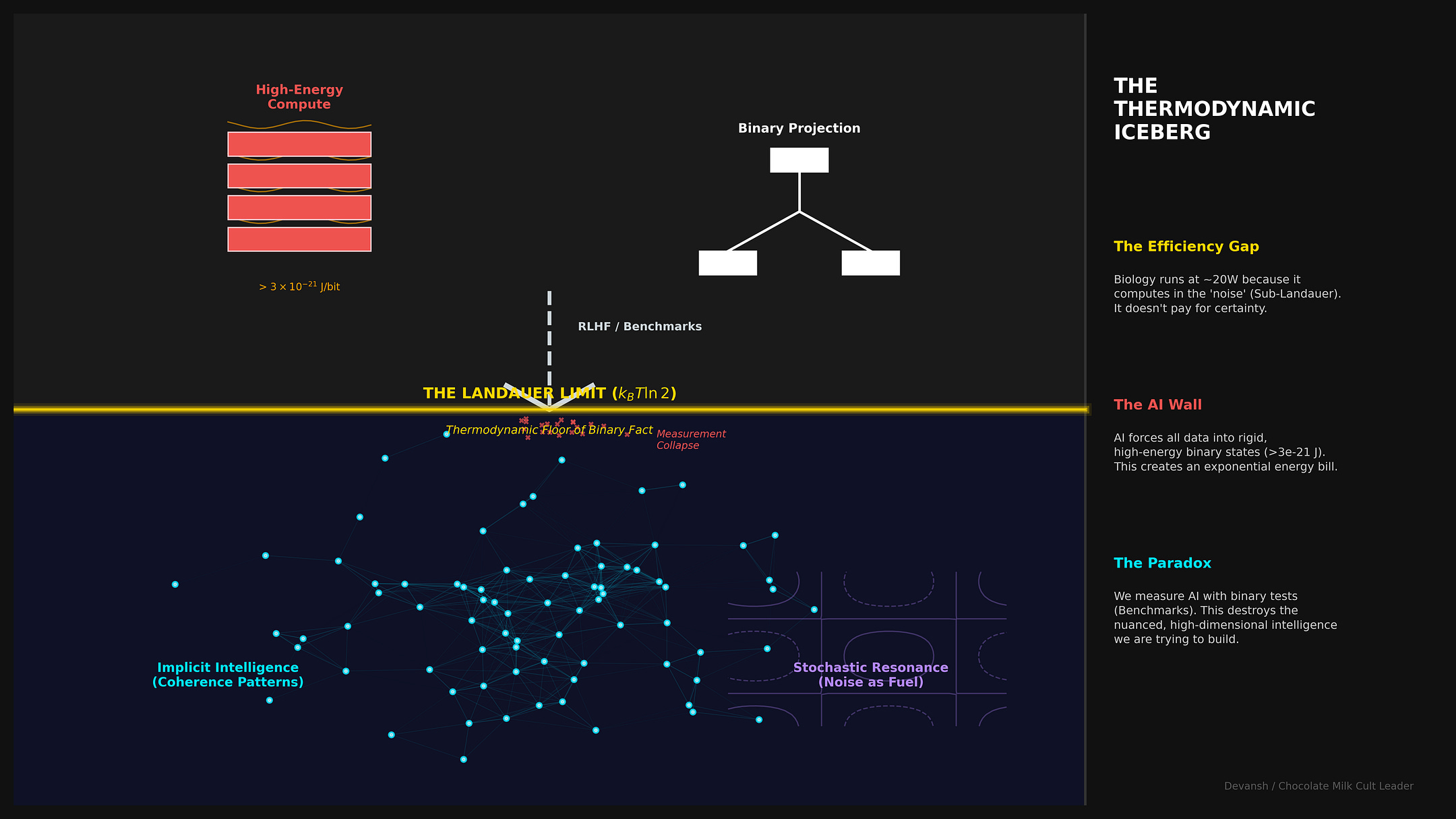
The problem: Binary measurement (yes/no tests, benchmark scores, discrete tokens) has a thermodynamic cost. For complex systems, it destroys exponentially more information than it captures. A 100-neuron system needs ~332 bits to specify its state. One binary test gives you 1 bit. You’ve captured 0.3% of what’s there.
What biology does differently: The Landauer limit sets a minimum energy cost for erasing a bit (~3×10⁻²¹ J). Biology’s entire energy budget is ~17× this floor per ATP molecule. It can’t afford to snap bits like GPUs do. Instead, it computes in the sub-Landauer domain — patterns too weak to measure individually but causally influential through collective effects. Noise becomes an amplifier (stochastic resonance), not an enemy.
The AI translation: Token generation is measurement collapse. Everything the model “understood” about competing interpretations and uncertainty gets crushed into one discrete symbol. The text output is projection of intelligence, not intelligence itself. We evaluate what survives that projection.
What this explains: Why heavy quantization works (intelligence is distributed, not precision-dependent). Why dropout improves generalization (stochastic resonance). Why capabilities “emerge” suddenly (they were always there, below our detection threshold). Why polysemantic neurons exist (distributed encoding our binary decomposition can’t see).
The uncomfortable implication: Models might be improving in dimensions our benchmarks are structurally blind to. Or worse — capabilities might exist below detection threshold until they cross it. Either way, we’re flying partially blind.
Where systems go: Thermodynamic hardware (analog, neuromorphic, photonics). Evaluation methods that preserve structure instead of collapsing it. Memory as state modification, not retrieval. The metric that matters shifts from FLOPS to Joules/Op.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
2. The Binary Trap
Karl Popper’s falsifiability criterion (the foundation of the modern scientific method)assumes any meaningful hypothesis can be collapsed to a yes/no test. For simple systems with isolatable components, this works. For complex interconnected ones, the math guarantees it destroys almost everything.
To understand why, let’s start with what “information” means formally.
If you have 2 equally likely possibilities, one yes/no question perfectly distinguishes them. That’s the definition of 1 bit: the amount of information needed to pick between two options.
What about 4 possibilities? You need two yes/no questions. First question splits 4 into 2 groups. Second question picks within the group. So: 4 possibilities = 2 bits.
The pattern: each bit doubles what you can distinguish. 1 bit → 2 options. 2 bits → 4 options. 3 bits → 8 options. n bits → 2^n options.
Flip it around: if you have N possibilities, you need log₂(N) bits to fully specify which one you’re in.
Now apply this to a system.
Say you have n components (neurons, parameters, proteins), each capable of k distinct states. The total number of configurations the system can occupy is k^n. That’s the state space.
To pinpoint exactly which configuration the system is in, you need log₂(k^n) bits. Logarithm rules: that’s n · log₂(k) bits.
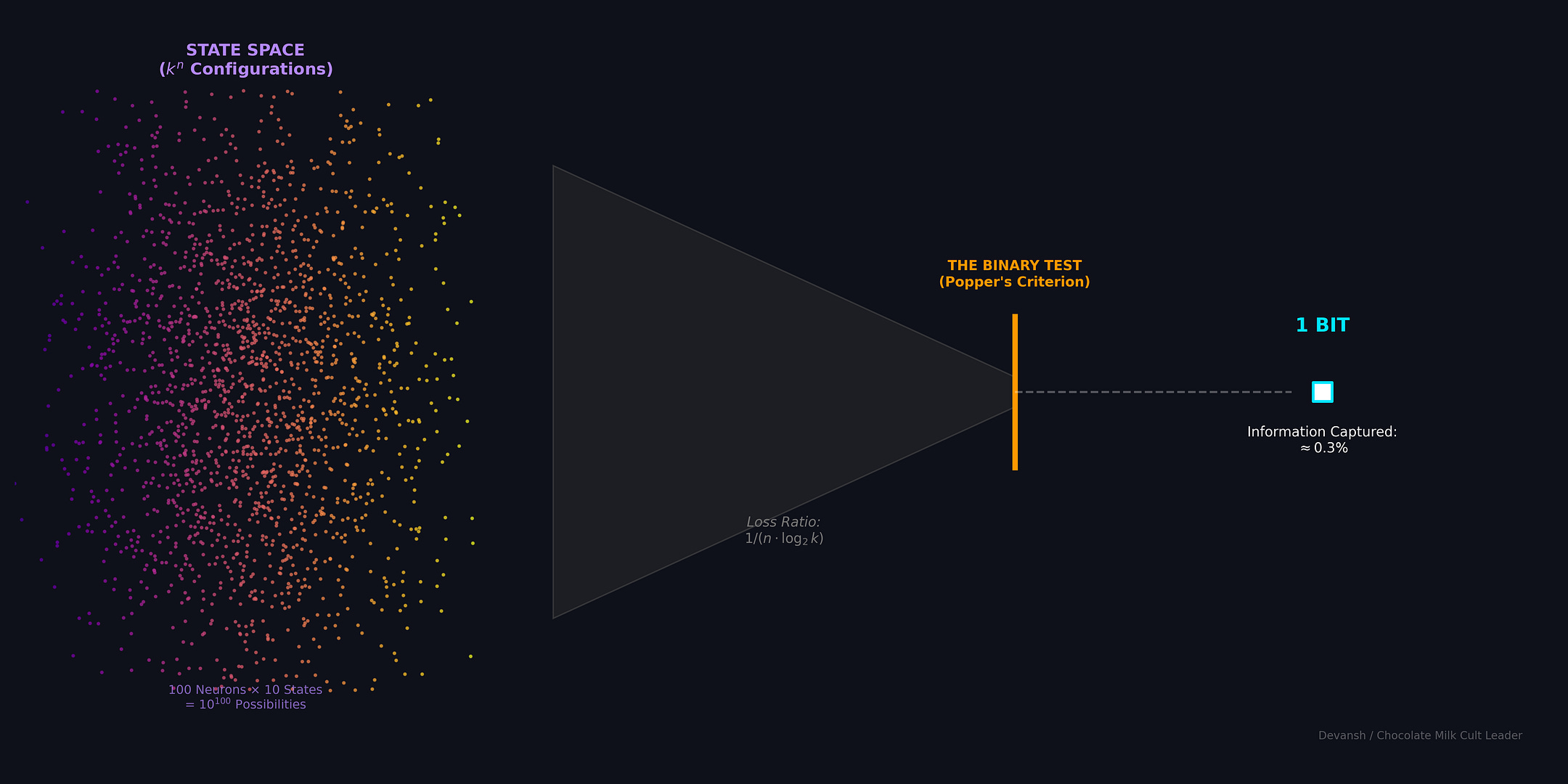
A binary test — a yes/no question — gives you exactly 1 bit since it splits the state space in half, nothing more. So if a system requires n · log₂(k) bits to specify, and your test provides 1 bit, you’ve captured 1/(n · log₂(k)) of the information needed.
Concrete example: 100 neurons, 10 activity levels each.
State space: 10¹⁰⁰ configurations
Bits needed: 100 · log₂(10) ≈ 332 bits
One binary test: 1 bit
Information captured: 1/332 ≈ 0.3%
That’s with one test.
But benchmark suites run hundreds of questions — doesn’t that add up?
Only if each question is independent and optimally informative. Real benchmarks aren’t. Questions overlap. They probe the same capabilities repeatedly. They’re designed for human interpretability, not maximal information extraction. The effective bits captured are far fewer than the question count suggests.
And this is the optimistic case — 100 neurons at 10 states. A language model has billions of continuous parameters. The state space is effectively infinite. The fraction captured by any benchmark suite rounds to zero.
The benchmark doesn’t measure the model. It measures what survives projection onto the questions asked.
Two models with identical scores can have completely different capability structures underneath. One passes through deep understanding, another through shallow pattern-matching. Binary projection can’t tell the difference.
Biology hit this wall decades ago. Let’s discuss this in more detail, so we can understand how we can design better solutions for the future.
3. Biology Hit the Wall First
The brain doesn’t compute like a GPU. It can’t afford to. Doing so would cost too much energy — and destroy the computation in the process.
The Landauer Limit
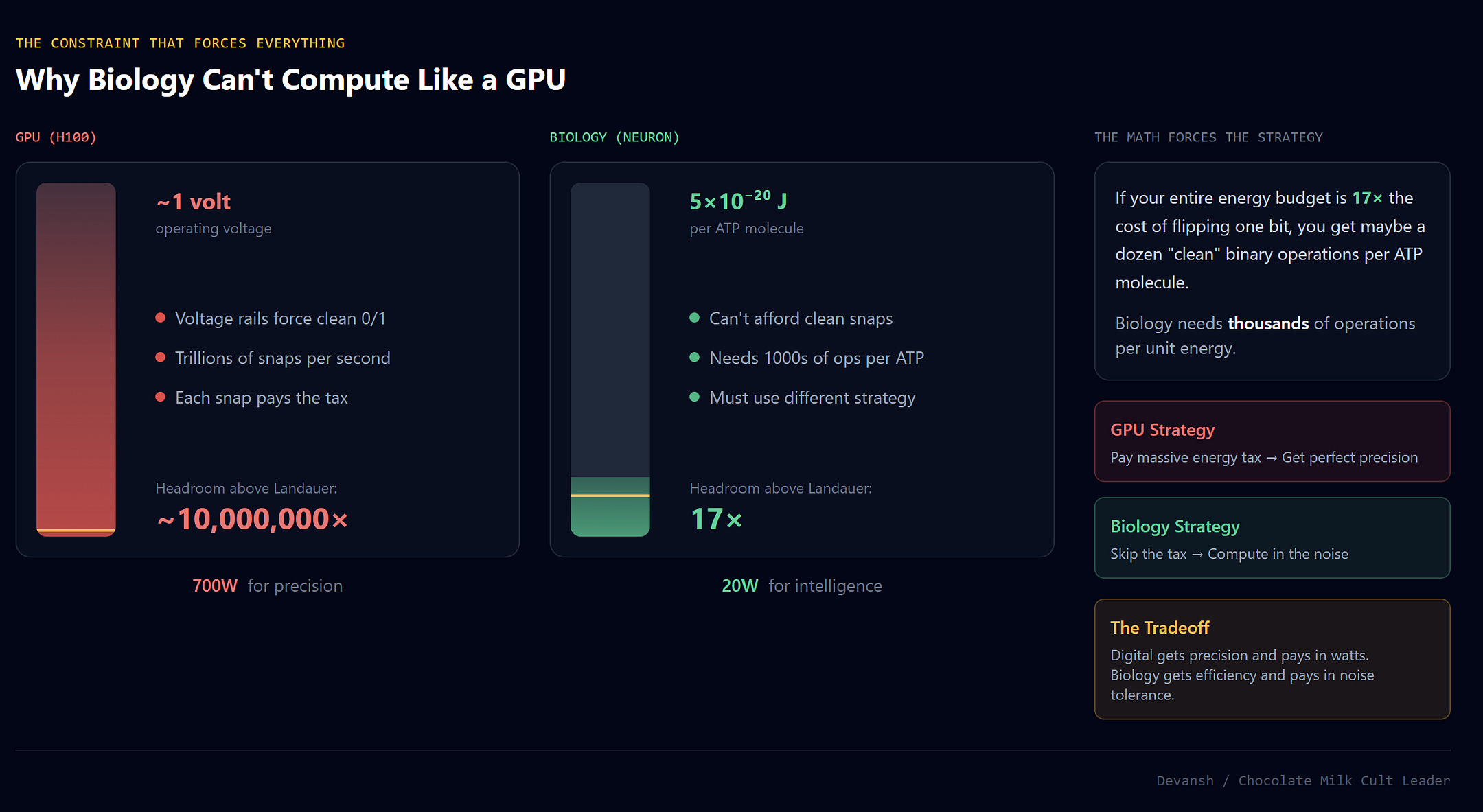
Every time you erase a bit of information, you pay a thermodynamic price. A bit in an uncertain state has entropy. Erasing it by forcing it to a definite 0 or 1 reduces that entropy. Here’s the kicker: Thermodynamics requires total entropy to increase, so the reduction inside the system must be paid by ejecting heat into the environment. If you have a big brain like me, it should be clear that this is not good.
Rolf Landauer proved the minimum price in 1961: kT ln(2), where k is Boltzmann’s constant and T is temperature. At body temperature, this works out to about 3×10⁻²¹ joules per bit.
ATP hydrolysis — the basic unit of cellular energy — releases about 5×10⁻²⁰ joules. That’s only 17× the Landauer limit. A single synaptic vesicle release: ~10⁻¹⁹ joules. Protein conformational changes often operate at energies comparable to kT itself. If your entire energy budget is 17× the cost of flipping one bit, you cannot afford to flip bits the way GPUs do. You have maybe a dozen “clean” binary operations per ATP molecule before you’re bankrupt. Biology needs thousands of operations per unit energy. The math forces a different computational strategy.
Take note of that. Highlight that. Do whatever you have to to embed that into your psyche, right next to the washing powder Nirma song so you can never forget. Because that is a very important insight. For now, let’s turn our focus back to computers.
GPUs enforce binary precision by snapping transistors to definite 0/1 states with voltage rails far above the Landauer floor. This guarantees clean math but costs energy — every snap pays the thermodynamic tax. An H100 pays this tax trillions of times per second.
The tradeoff: digital systems get precision and pay in watts. Biology gets efficiency and pays in noise tolerance.
So if biology is not snapping, what is it doing with the fuzzy bits of information zipping around our brains? This is where it gets interesting.
The Sub-Landauer Domain
Between thermal noise (~10⁻²² J) and the Landauer limit (~3×10⁻²¹ J), there’s an energy window where patterns exist that are:
Too weak to measure as discrete bits
Not random — they maintain temporal coherence
Causally influential through collective effects
Destroyed by any measurement strong enough to resolve them
This is the sub-Landauer domain. Patterns here can’t be recorded as binary facts, but they still do computational work.
Keep in mind this is not noise; noise is statistically unstructured, has no phase persistence, averages to zero over time. Sub-Landauer patterns are structured phase relationships maintained by active processes. They’re random-looking at the component level but predictive at the population level.
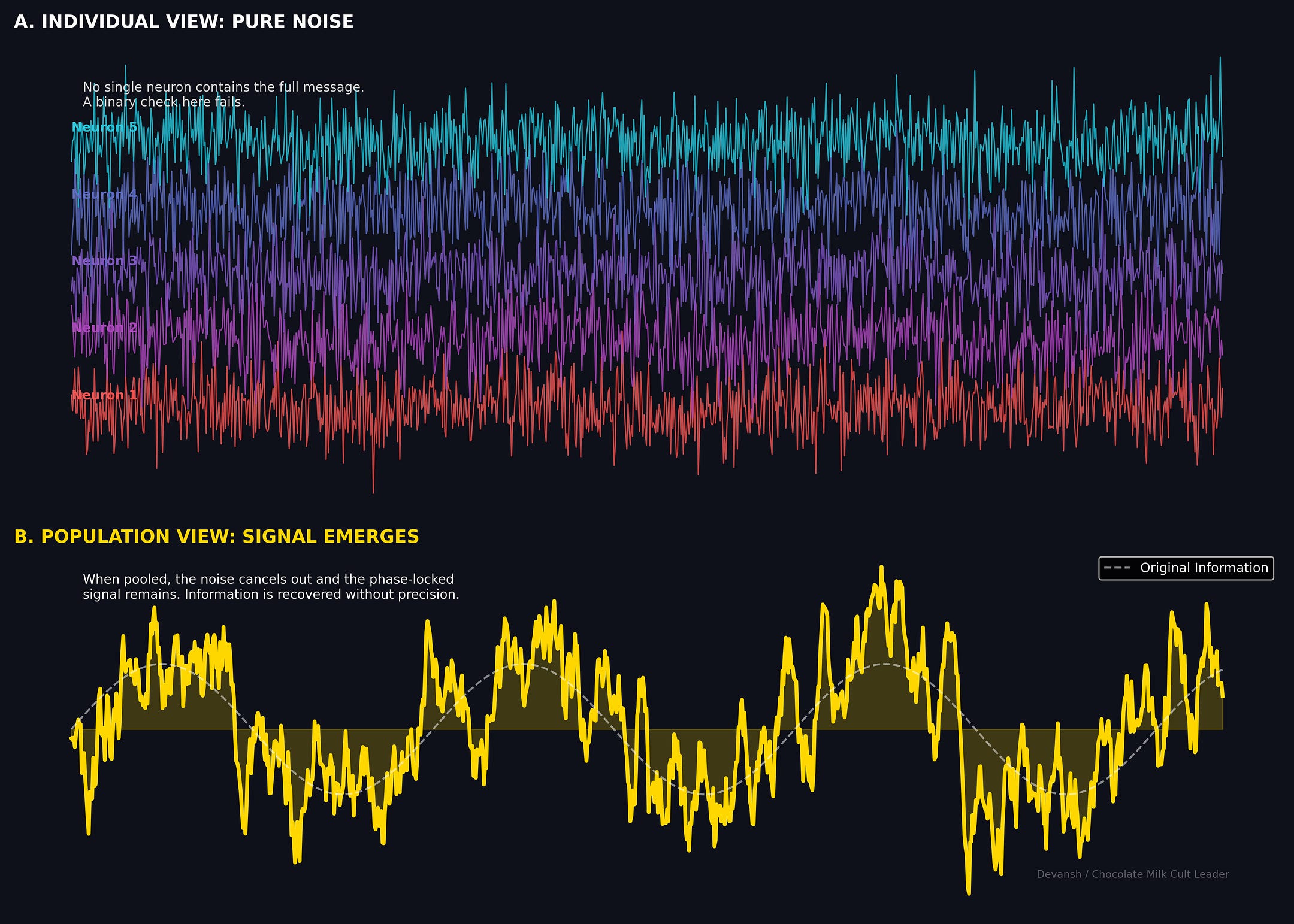
Concrete example: ephaptic coupling. Electric fields as weak as 1 millivolt per millimeter — far below single-neuron detection thresholds — shift spike timing across neural populations. The field can’t trigger any individual neuron. But it biases timing in neurons already near threshold. Information propagates through tissue without synaptic transmission, through a signal too weak to measure without destroying it. And according to this Harvard article, it’s near instantaneous.
If sub-Landauer signals are too weak to detect, how does biology use them?It inverts the usual engineering logic. Instead of signal overpowering noise, the signal rides the noise.
Stochastic Resonance
A weak periodic signal can’t cross a neuron’s firing threshold alone. But neurons sit in thermal noise — random fluctuations pushing membrane potential up and down. When signal and noise peak together, the combination crosses threshold. When they don’t align, no firing.
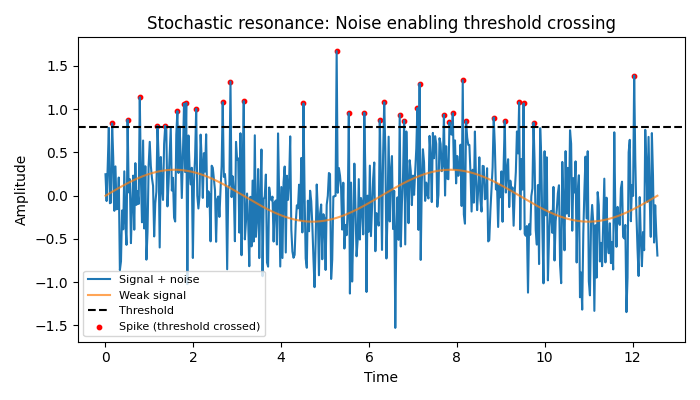
In this way, the neuron’s output correlates with the weak signal even though the signal alone was undetectable. Noise becomes an amplifier, not an enemy. Think Deku using that field of mines to win the first race in the school festival way back.
Evolution found a way to detect signals that, by the Landauer limit, cannot be recorded as individual bits. This allows it to squeeze the maximum possible information from all the neurons efficiently (also allows it spread information across more spaces, distributing the connections, which should help with multi-hop reasoning since we get more relevant nodes in the graph).
What Biology Learned
Neuroscience adapted. Instead of asking “which neuron causes this behavior,” it moved to “what statistical patterns correlate with this behavior.” Instead of isolating components, it characterizes ensemble dynamics. Instead of binary hypothesis tests, it uses information-theoretic measures that don’t require discretization.
As with many other aspects of life, Biology learned to stop forcing binaries everywhere and embrace the fluidity of a spectrum.
It seems like AI might be next.
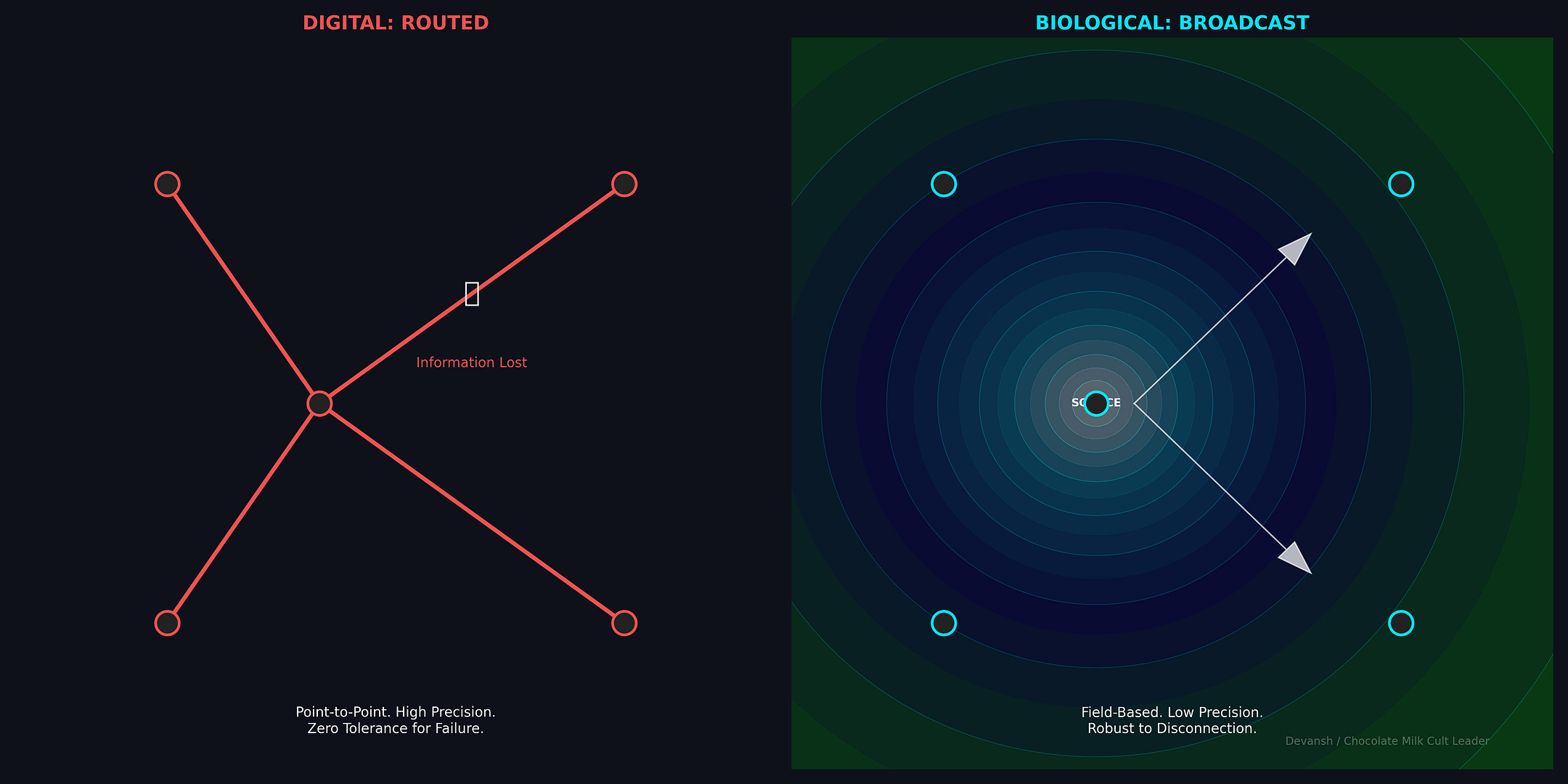
4. AI Operates in the Same Regime
The biological case isn’t an analogy. It’s a precedent. After all, AI systems already operate in the same regime — high-dimensional state spaces, information encoded in patterns that don’t survive projection, measurement that collapses the thing being measured. The mapping is direct:
High-dimensional phase space → latent space, weight manifolds
Sub-threshold neural patterns → internal activations before token generation
Measurement destroying phenomenon → output sampling collapsing possibility
Stochastic resonance → dropout, ensemble methods, noise regularization
Math terms, we’re entering structural equivalency territory.
Where the Intelligence Actually Lives
A language model has billions of parameters forming a continuous state space. During inference, information flows through layers of transformations — attention patterns, activation distributions, residual connections. At each layer, the model’s “understanding” exists as a high-dimensional pattern across thousands of dimensions.
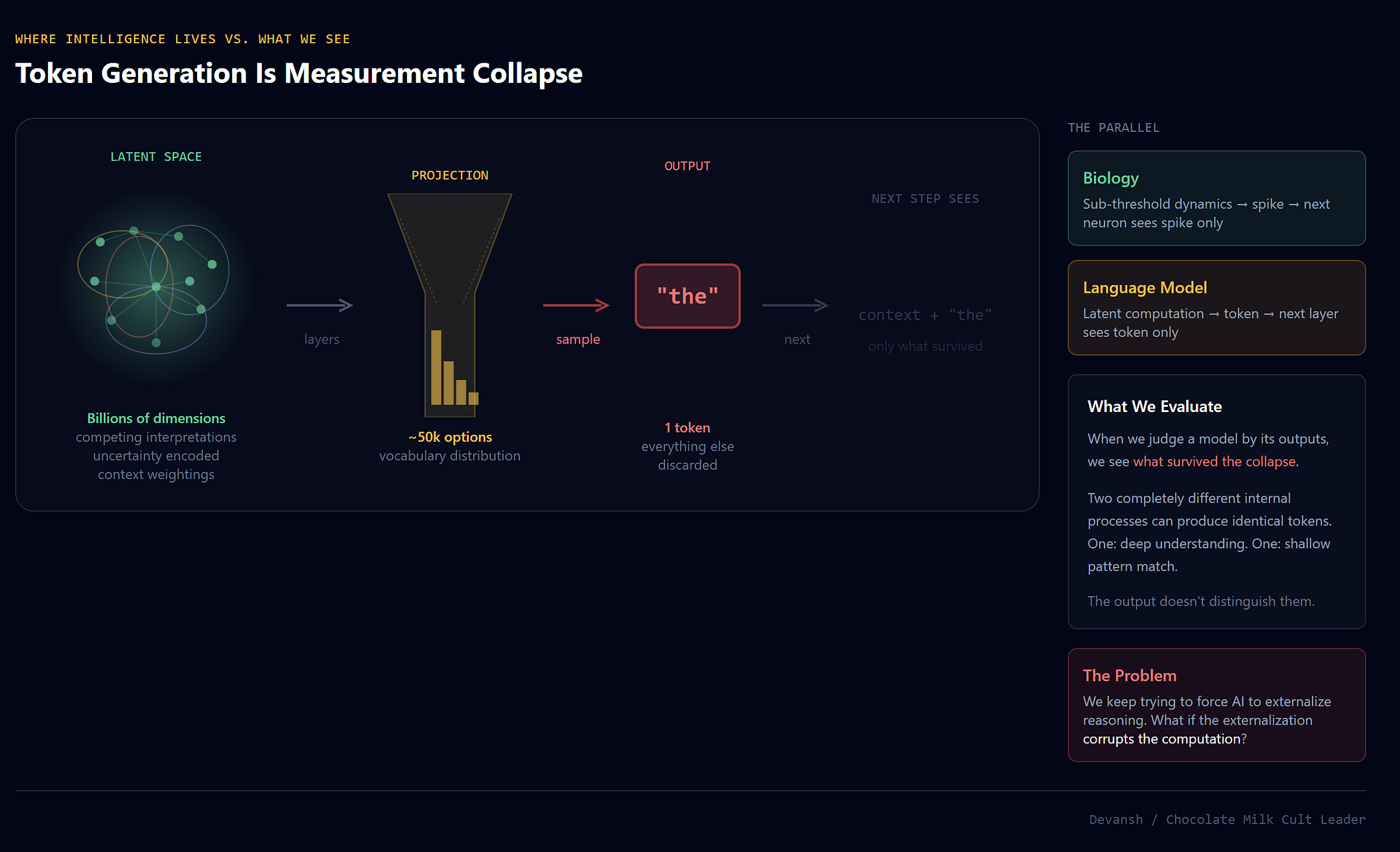
Then comes the final step: project that pattern onto a probability distribution over tokens. Pick one. Emit it. Collapse.
Everything the model “knew” about the nuance of that moment — competing interpretations, uncertainty, context-dependent weightings — gets crushed into a single discrete symbol. The next token sees only what survived. Generation continues, each step collapsing the previous step’s possibility space.
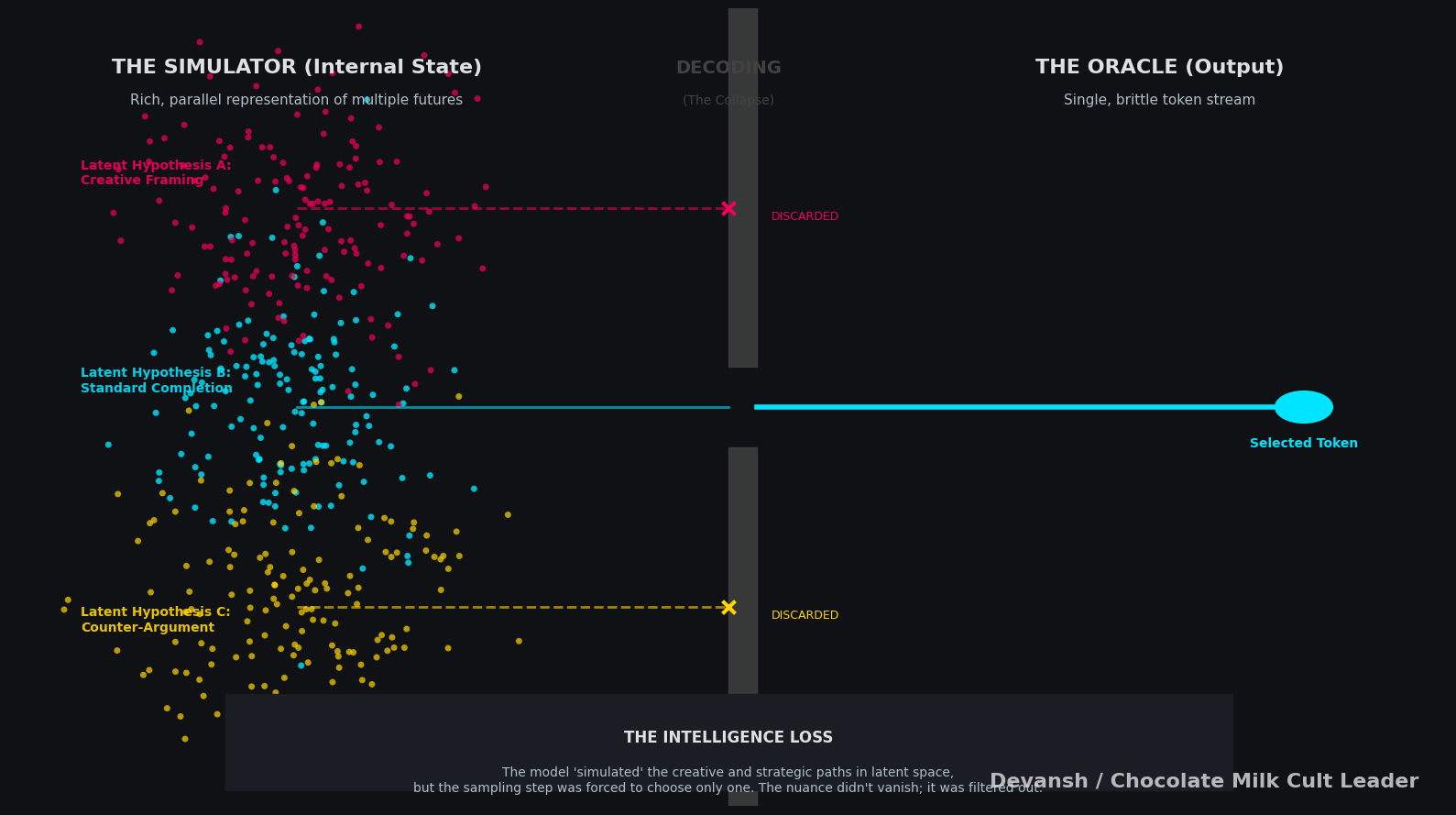
This is measurement collapse.
This is an important frame so I’m going to take a second to call this out explicitly —
The text output is just the projection of intelligence, not the intelligence itself. The actual computation happens in the high-dimensional vector space inside the model — in relationships between billions of parameters that exist before the model commits to a word.
When we evaluate a model by looking at its outputs, we’re seeing what survived the projection. Two completely different internal processes can produce identical tokens. One might represent deep understanding, another shallow pattern-matching. The output doesn’t distinguish them.
Sound familiar? It’s the same problem biology faced with spike recordings. The spike is the output. The sub-threshold dynamics that determined its timing were the computation. Recording spikes tells you something. It doesn’t tell you what you actually wanted to know.
Why This Explains Weird Observations
This framework makes sense of things that otherwise seem like noise:
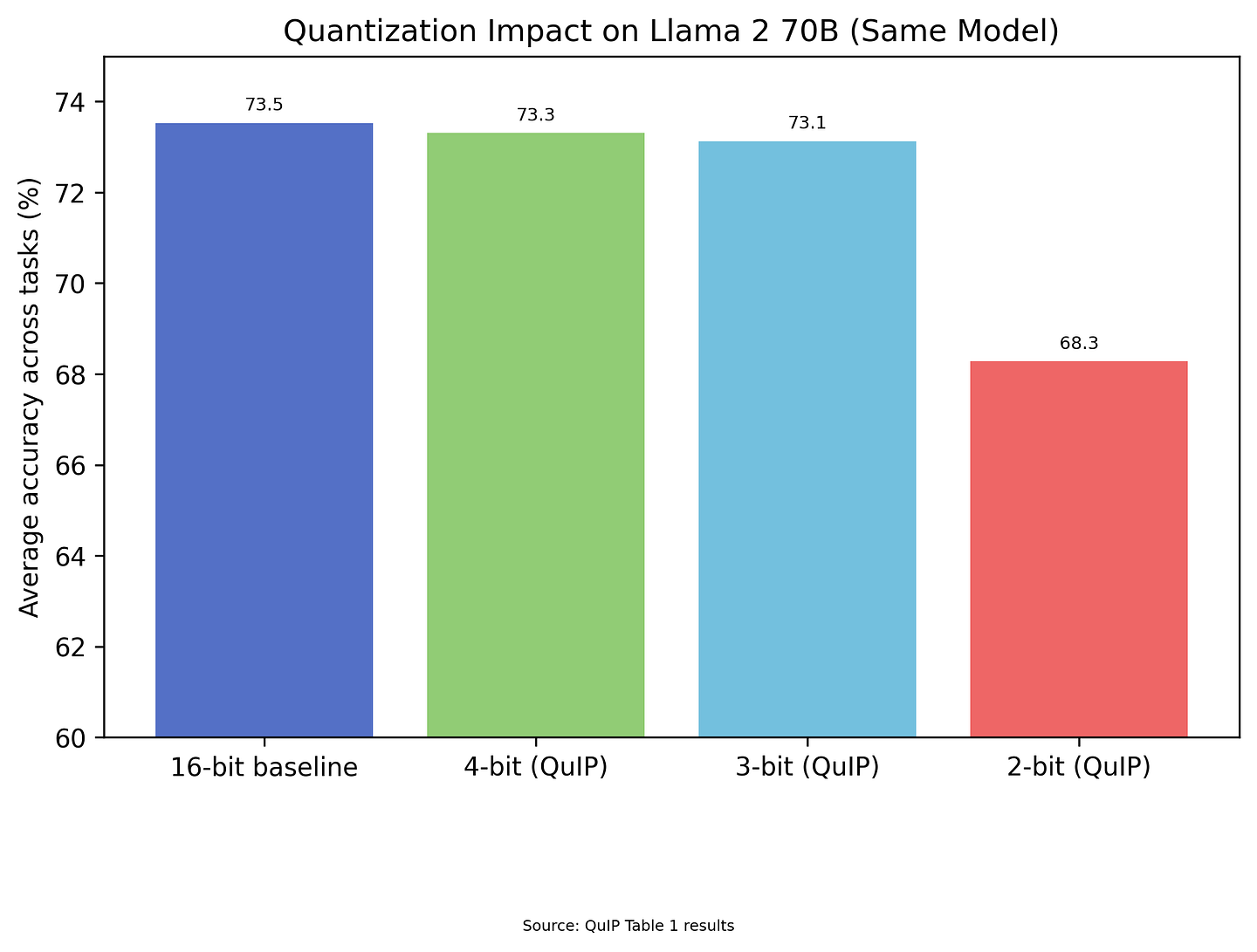
Why does heavy quantization work better than intuition suggests? Models crushed to 4-bit or even 1-bit precision still function. If intelligence required precise parameter values, this would be impossible. But if intelligence lives in distributed patterns that tolerate approximation — like sub-Landauer biological signals — degradation is graceful.
Why does dropout improve generalization? How did Google beat ImageNet competitors using 12 times fewer resources (also not requiring those images to be labelled, big cost saver)? They used noise + dropout. Why did that work? Standard explanation: this prevents overfitting. Sub-Landauer explanation: noise injection enables stochastic resonance. The model learns patterns that only become detectable through population-level statistics, not brittle single-pathway dependencies.
Why do capabilities emerge suddenly at scale? Conventional view: phase transition, witch doctor works their magic at the threshold. Alternative view: the capability existed as a sub-threshold pattern in smaller models. It was always there, doing causal work. We just couldn’t detect it until it crossed our measurement threshold. The alternative view aligns phenomenally well-received and backed paper — “Are Emergent Abilities of Large Language Models a Mirage?”, where they showed that emergent abilities in LLMs were only “emergent” (they jumped suddently) b/c our metrics didn’t account for them; changing the metric showed them emerging linearly.
Why do polysemantic neurons exist? Neurons that respond to seemingly unrelated concepts are usually treated as a bug (superposition from limited capacity). But if the model is computing like biology, polysemanticity is the feature. The “unrelated” concepts share a sub-threshold structure that matters. The neuron isn’t confused; it’s encoding distributed relationships our binary decomposition can’t see.

The Uncomfortable Claim
We keep trying to force AI to explain itself in discrete steps. Chain-of-thought prompting. RLHF on outputs. Benchmark evaluation. Interpretability via circuit analysis. All of these assume that capability can be externalized without loss.
What if it can’t?
What if language models, like biological neural networks, do significant computation in patterns that don’t survive externalization? What if the chain of thought isn’t revealing the reasoning process but forcing a lossy projection of it? What if the model “thinks” in sub-threshold patterns across its latent space, and we’re training it to pretend otherwise?
This would explain persistent puzzles:
Why do models sometimes get questions right with short responses and wrong when forced to show work? The forced externalization corrupts the computation. For linear logic, step-by-step helps. For intuitive leaps across high-dimensional space, it destroys the path.
Why does RLHF hit ceilings? Optimization follows gradients. Gradients flow through what we measure. You can only optimize what survives projection into rated outputs. Capability that lives in the projection-destroyed space can’t be trained — it can only be accidentally preserved or inadvertently killed.
Why do interpretability findings fail to generalize? Isolating a circuit is measurement. If computation depends on distributed patterns that include that circuit, isolation destroys the phenomenon you’re studying. You find a “circuit,” ablate it, and behavior changes. The traditional conclusion is to the tune of the circuit caused behavior. From this lens, we get a different view: you collapsed a distributed pattern that required that component as part of larger coherence.
Perhaps it’s time to stfu about the scaling wall and talk about the measurement wall.

The Stakes
If this is right, we have two problems:
The models might be getting better in ways our evaluation paradigm is structurally blind to. Benchmarks saturate not because the capability plateaued, but because the capability improvements are happening in dimensions that benchmarks can’t see.
Or worse: models might have capabilities — including dangerous ones — that exist below our detection threshold until they Instant Transmission beyond that wall. If emergence is crossing a detection boundary rather than a capability boundary, we have less warning than we think.
Either way, we’re flying partially blind. Same problem biology had. Same forcing function toward a solution.
5. Where Systems Must Go Next
We cannot reach AGI by stacking H100s.
This isn’t a statement about supply chains or capital expenditure. It’s a statement about physics. We’re trying to simulate a biological process using a physics model that is fundamentally hostile to efficiency. An H100 runs at 700W. A human brain runs at 20W while doing things H100 clusters can’t. The gap isn’t closing through better process nodes since the divergence is fundamentally structural.
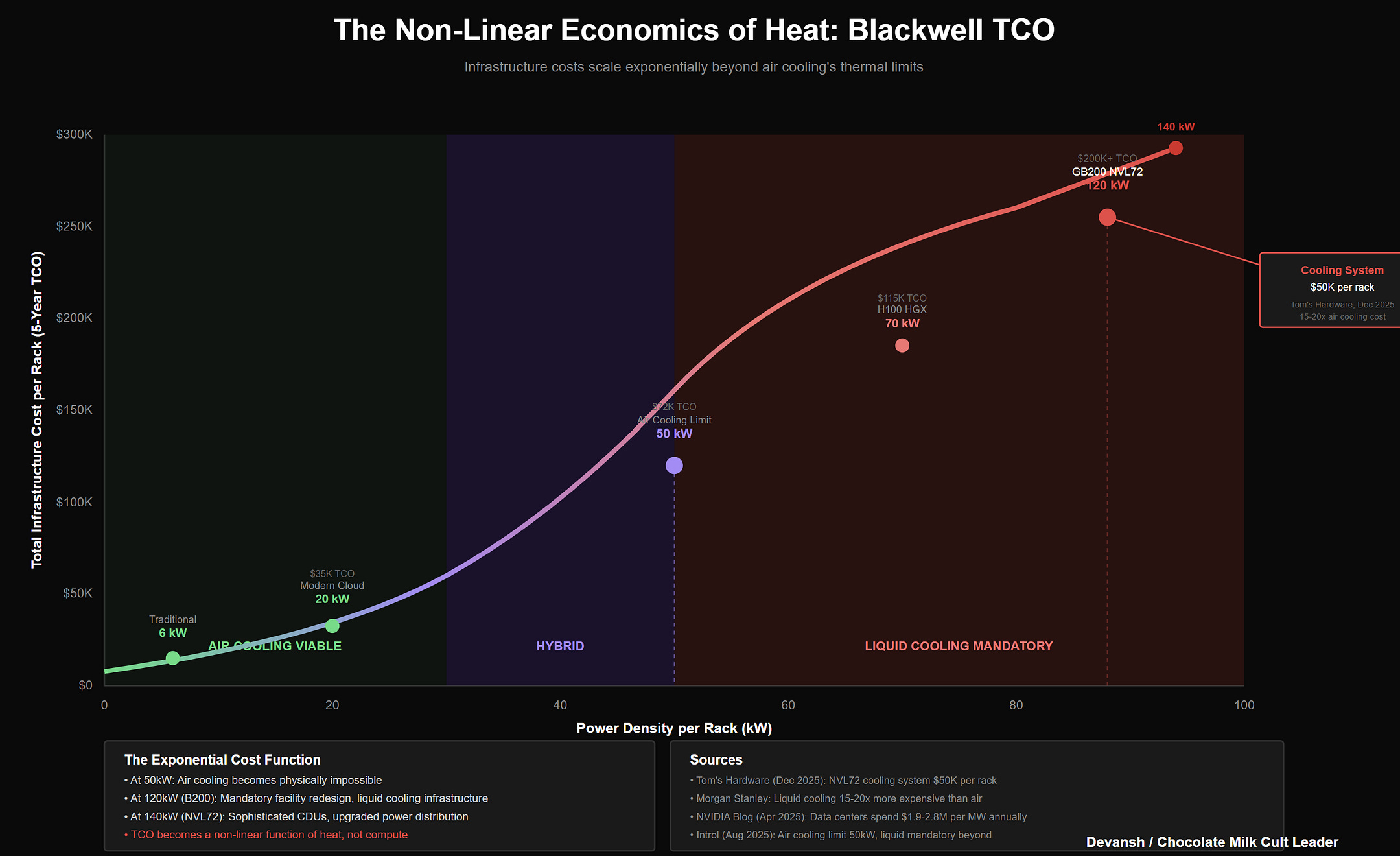
If we want to scale intelligence further, we have to stop fighting thermodynamics and start working with it. Three directions — thermodynamic, epistemological, architectural. Not visions. Constraints.
The Thermodynamic Direction
Analog Computing. Digital computers do matrix multiplication by fetching numbers, running them through an ALU, and writing them back. Billions of transistor switches flipping on and off. Each flip pays the Landauer tax.
Analog computers use Ohm’s Law. Imagine a grid of resistors. Send voltage through the rows (input). The current that comes out of the columns is the product of voltage and conductance: I = V × G. This happens instantly. It happens in parallel. And crucially, it happens without switching. No clock cycle. No bit erasure. The physics does the math for free.
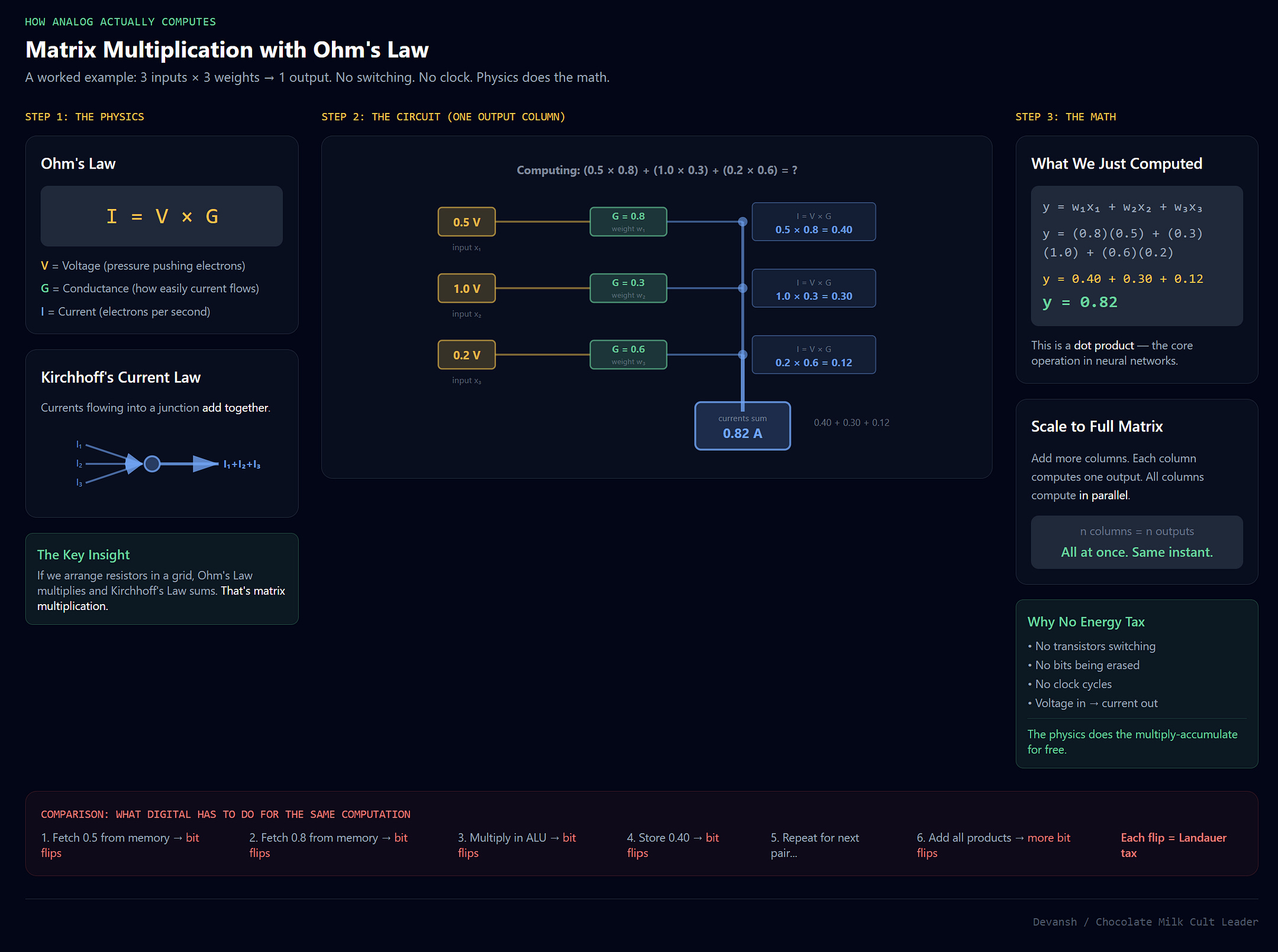
This approach fell out of favor because it’s noisy. Temperature changes shift resistance. But this might make a comeback for AI; after all, if intelligence lives in correlation, not precision, the noise doesn’t kill us.

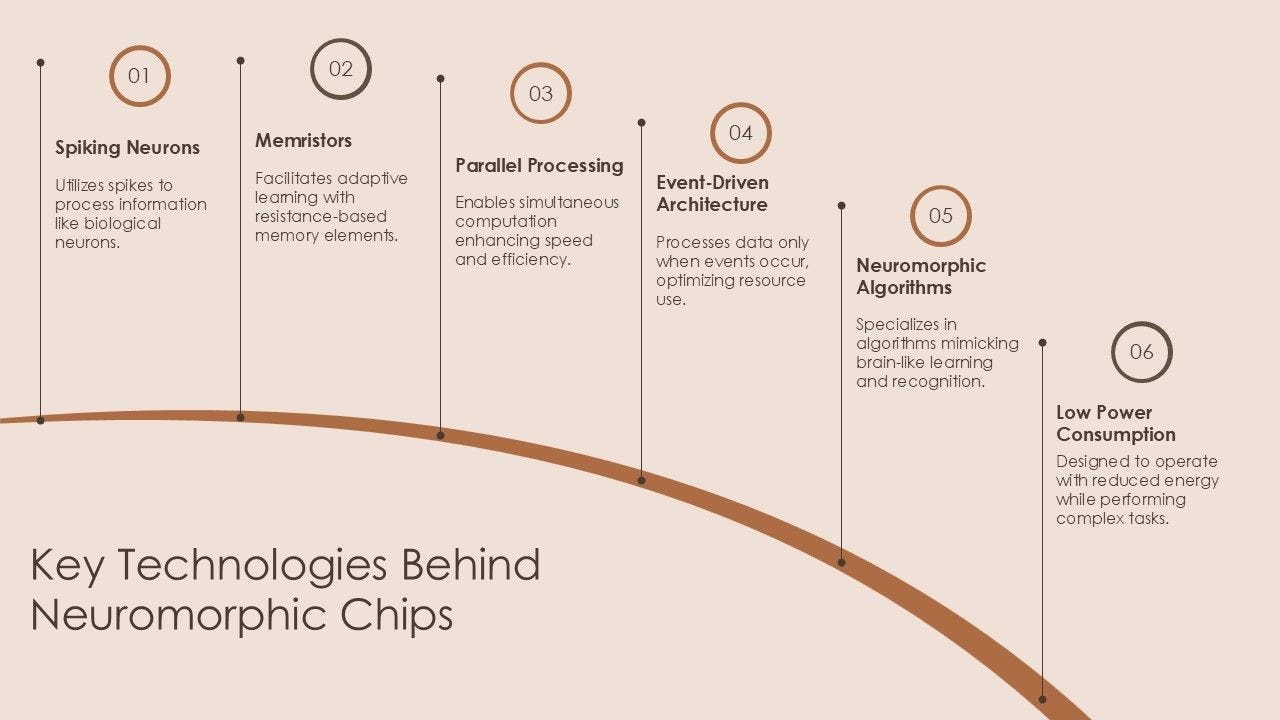
Neuromorphic Spiking. Biological neurons are event-driven. They sit silent, consuming almost zero energy, until a spike hits them. GPUs are clock-driven. They burn power on every cycle, even if nothing is happening, just to stay synchronized.
Neuromorphic chips — Intel’s Loihi, IBM’s TrueNorth, BrainChip — adopt the biological model. They only compute when a signal changes. Power consumption drops by orders of magnitude for sparse data. Which is what the real world is.
Silicon Photonics. Light doesn’t have resistance. Interference patterns compute without heat. Lightmatter and Luminous are betting billions that photonics is the thermodynamic endgame. If we can’t stop the heat at the transistor, we stop it at the wire.

The software validation is already here. We covered the quantization numbers — 4-bit preserves nearly everything, 2-bit preserves most. BitNet shows you can train massive LLMs where every weight is ternary: {-1, 0, 1}. Not 16-bit floating point with 65,536 possibilities. Just “positive connection,” “negative connection,” or “no connection.”
These 1-bit models perform comparably to full-precision but use a fraction of the energy. The models are screaming at us: we don’t need this precision. We’re paying the thermodynamic tax for nothing.
The implication for the next decade: the ratio that matters isn’t FLOPS. It’s Joules per operation. We’re moving from “how fast” to “how cheap per inference.”
The Epistemological Direction
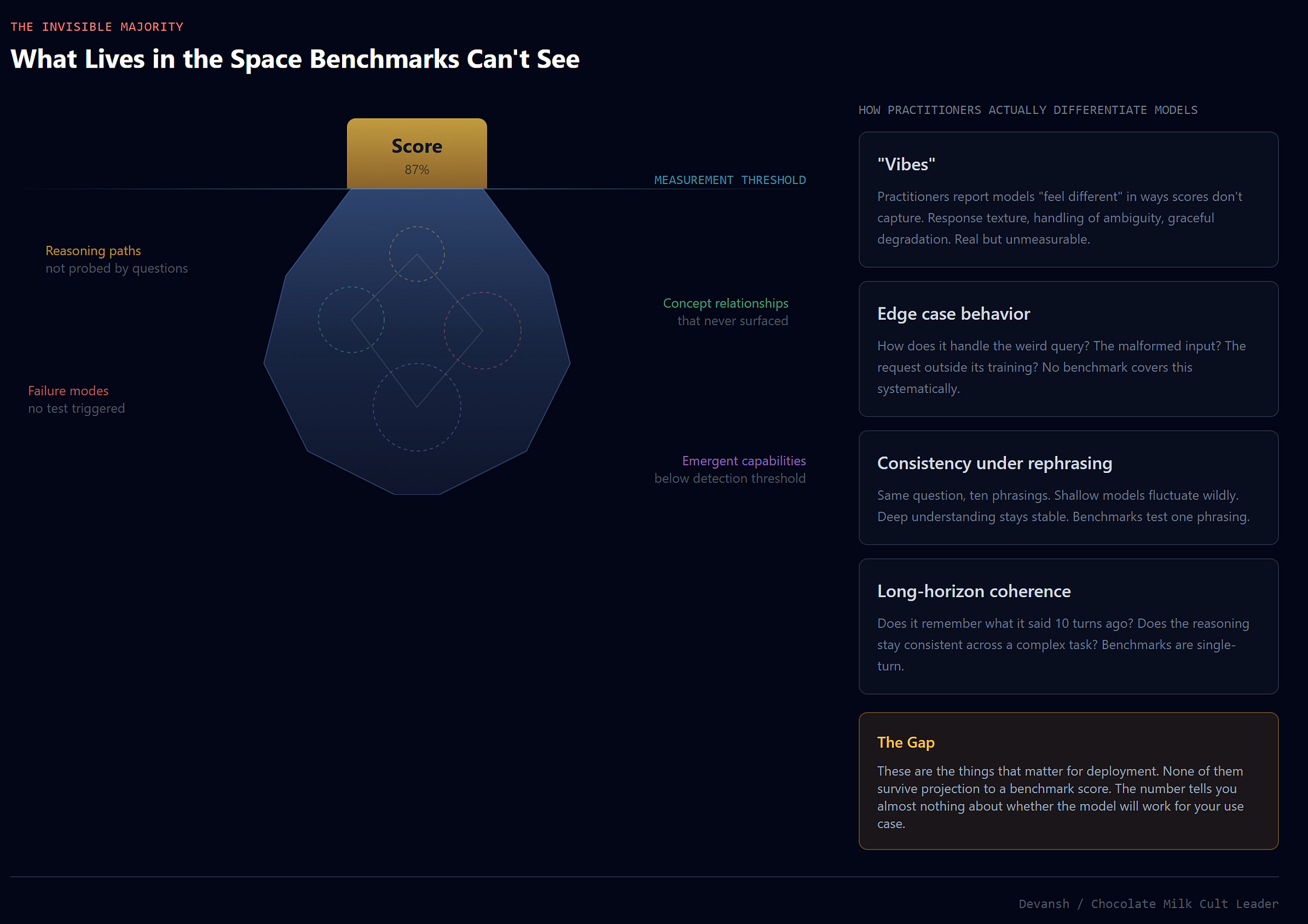
Better benchmarks won’t save us. Different benchmarks might.
Multi-dimensional evaluation. Instead of collapsing capability to a single score, characterize capability profiles. Where is the model strong? Where weak? What’s the shape of its competence? This requires giving up leaderboard simplicity. The tradeoff is worth it.
Process-based evaluation. Don’t just check if the answer is right. Examine how the model got there. Reward reasoning structure, not just output correctness. This is harder to automate. That’s the point — the automation is what’s destroying information.
Behavioral fingerprinting. Instead of “did it get the answer right,” measure the high-dimensional pattern of how it answered. Did it hedge? Did it explore alternatives? Did internal activation states show uncertainty? Profile models by their distributions, not their point estimates.
Adversarial probing for structure. Instead of “can it do X?” ask “where does its ability to do X break?” The boundary conditions reveal capability structure that aggregate scores hide. Real capability is defined by stability under perturbation — like biological homeostasis — not static accuracy.
The last 2 is why so many of my posts have recently centered around exploring the geometry of models and their intelligence subspaces. I think there is a ton of potential by exploring geometric structures that emerge in a models latent representations. I think they can be a much truer signal for intelligence, and manipulating them will allow us to both diagnose models and inject capabilities more effectively (and cheaply).
Obligatory plug for our Latent Space Reasoning Work here, since that is where we will be pushing a lot of these experiments. Github here (we’re paying and hiring contributors). If you’re an org interested in frontier research, reach out.
Training needs the same shift. Constitutional approaches with multiple objectives, not collapsed to scalar. Process supervision that rewards reasoning chains. Preference learning that preserves structure rather than flattening to rankings. The system should not be trained to perform for the evaluator. It should be trained to maintain internal coherence that survives interaction, time, and noise.
The Memory Direction
Current AI treats memory as retrieval. RAG pulls chunks from a database. Conversation history gets stuffed into context. Agents write notes to external storage.
None of this is memory. It’s lookup.
When you remember something, you don’t query an index. Your neural patterns are different from what they would have been without the experience. The memory is distributed in connection weights, expressed through how you process everything afterward. You don’t retrieve the memory — you are the memory.
AI systems are stateless between calls. “Memory” is a retrieval operation on external storage, not a state modification of the system itself. The model doesn’t become different. It just gets handed a different context.
This might be why long-horizon tasks fail even when they seem like they should be easy. The architecture forces explicit retrieval, whereas biology uses implicit state. You’re asking the system to remember by looking things up rather than by being changed.
What would real memory look like?
Continuous state evolution. Systems that update internal representations based on experience, persisting across sessions. Not “here’s what happened last time” fed as context — actually different weights, different activations, different dynamics.
Implicit over explicit. The goal isn’t perfect recall of what happened. It’s appropriate behavioral change from what happened. These are different. Current architectures optimize for the first. Biology optimizes for the second.
Unforced serialization. Let the model not explain itself. Sometimes the best path to a solution passes through inarticulable internal coherence. Let it happen.
This is technically hard. Continual learning without catastrophic forgetting. Selective consolidation without supervision. State persistence without unbounded growth. The problems are known. The solutions aren’t. But the direction is clear.
The Constraint
All three directions share a principle: preserve structure instead of collapsing it.
Thermodynamics: don’t pay for precision the intelligence doesn’t need. Epistemology: don’t compress capability into scalars that destroy the shape. Memory: don’t externalize state that should be internal.
The common enemy is premature projection — forcing a model to bust out low-dimensional representation before the system has extracted what it needs; we should instead be encouraging models to stay hard in high-dimensional reality.
Conclusion: Where This Goes Next
Two interesting implications fall out of our discussion:
The vibes gap is alpha. Everyone treats the disconnect between benchmarks and practitioner intuition as a problem to fix. It’s not. It’s information. Vibes integrate across more dimensions than evals. Whoever figures out how to formalize what experienced users perceive — without collapsing it — has a measurement advantage that compounds into a training advantage. The “vibes” aren’t noise. They’re signal we don’t know how to record yet.
Edge deployment opens many more doors. If 4-bit and 2-bit quantization preserve almost everything, you don’t need the cloud. Not for cost reasons — for latency and state persistence reasons. Local models can maintain a continuous state. Cloud models reset every call. The company that figures out stateful edge inference owns the personal AI market. I expect more research to switch towards that as well, since you want access to the activations etc to figure things out.
But taking a step back, we must remember the old adage — one man’s trash is another’s treasure. Our systems have either explicitly or implicitly discarded the space between the measurable and the meaningful, the many sub-neurons/low-probability tokens/intermediate steps, for the sake of computational tractability at scale. To bet on do more, more effectively.
But research like this reminds us that there is a lot of value in questioning our assumptions, to reprioritize what our paradigm might discard as uninteresting. Perhaps the ambiguity that has haunted so many computational researchers is exactly the frontier we need to embrace for our next generation of breakthroughs.
Afterall, that which can’t be owned might still be ours to protect; that which can’t be measured might still be extremely valuable.
Thank you for being here, and I hope you have a wonderful day,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. :
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819
Absolutely superb, and thank you for it!
I am not up to date on the latest AI models, but from the time I was a kid, I devoured the annual Scientific American issues on the brain avidly, (from the mid seventies and for a couple of decades after) and have kept reading voraciously since, in many subjects. Man, do I love an intellectual thesis, like yours, that shows broad reading and thinking, instead of (all too common modern) narrowness!
Your brilliant piece gave me the lovely feeling old (serious hard-core) Sci-Am used to give (before it went “pop”) of flying at altitudes well beyond my knowledge set, but so wonderfully clearly reasoned at every step as to give me a fine and inspiring glimpse of a range of insights I would never have been able to climb up to discover or even suspect, myself – kudos!
Also can’t help mentioning – I had a long discussion with one of my favourite illustrator friends the other day – I was braced to hear AI was wrecking his business, but no – he’s hiring pals, instead! (yay) but I couldn’t help chuckling, when you made me think of the “thermodynamics of thinking.” As I told him, every time I finish an essay I feel irresistably compelled to grab for something that delivers high-concentrations of sugar – not just as positive reinforcement (gotta train that monkey) but because my brain really does feel ‘all fired out’ in terms of fuel. So cool to think there’s even a number to it!
Also – can’t help thinking improvisers (musical) invoke that ‘noise as signal’ thing all the time. Played in an ensemble for years and it was insane how often the whole group (even nights when 20 almost strangers showed-up to play) would instantly pivot all together from one state to another shockingly differerent one, with no clue or signal visible beforehand (even in retrospect, listening back to the tape). Humans is odd! (not at all the orderly beasts that we like to think)
Huge thanks – reading that was an enormous pleasure!
Power efficiency is a good metric.
I'm glad you mentioned RAG. I don't agree that external memory is a bad thing. But I'm also skeptical that AGI should be the goal.
The obvious and overlooked problem is the deluge of information today. When the ENIAC and UNIVAC were created, there was no need for solutions like Big Data and search engines. There was much less information created thrn. There were far fewer people in the world. The 20th century was a population explosion, and the rapid rise of new ways to publish information. At the start of the 1900s in the US, Americans ended their education in high school and got their news from reading an authoritarive local paper or watch the 3 santioned TV channels. Now, almost half of Americans earn a bachelors, and everyone around the world can read what anyone from anywhere publishes online via Substack, Reddit, YouTube, IG, etc. We live in a totally different age of information overload.
So I think we do need RAG, despite its limitations. Despite the efficiency of our brains, it is simply not possible to search, classify, analyze, and read from today's information deluge. We need assistance, and I think models can assist us with research. Or we can go back to the public reading authoritative sources written by an elite group of experts.