
How to Use Reasoning Models Properly
+ A simple ask to support AI Education for Everyone

(Scroll to the end of the message for the article)
I’ll keep this short.
The mission of Chocolate Milk Cult is simple: make the highest level of AI intelligence accessible to the most people. Not hot takes. Not aggregated headlines. Actual deep dives with original research, custom analysis, and frameworks you can use.
This costs us between $17-20K a month. We pay for researchers to run our own experiments. Tools. Infrastructure. Access to people who know what they’re talking about. These costs can add up a lot, but it’s what we have to do to ensure that we can give you truly differentiated analysis, not simply repeat headlines.
Free subscribers get a lot. That’s intentional: I never want your financial situation to be a barrier to getting access to the best insights. But paid subscribers are what make the whole thing possible.
If you’ve gotten value from this newsletter, I’m asking you to chip in.
We run a pay-what-you-can model - pricing that lets you contribute what’s comfortable. There are no tiered access games or preferential treatment. I’m also not going to guilt-trip you into a subscription by creating panic stories of urgency. My ask is much simpler— if you think our mission of providing the most actionable AI insights to everyone (not just the few tech elite) is valuable, and you’re able to contribute, please help however you can.
The links for support are below. Pick whatever price point is most comfortable to you.
Support AI Made Simple for 10 USD per month or 100 USD Annually
Support AI Made Simple for 9 USD per month or 90 USD Annually
Support AI Made Simple for 8 USD per month or 80 USD Annually
Support AI Made Simple for 7 USD per month or 70 USD Annually
Support AI Made Simple for 6 USD per month or 60 USD Annually
Support AI Made Simple for 5 USD per month or 50 USD Annually
Support AI Made Simple for 4 USD per month or 40 USD Annually
Support AI Made Simple for 3 USD per month or 30 USD Annually
Support AI Made Simple for 2 USD per month or 20 USD Annually
Support AI Made Simple for 1 USD per month or 10 USD Annually
I’ve attached our deep dive into the predictions for 2026 below. This is the kind of work paid subscribers get on a regular basis.
Hope to see you among the premium members.
Thanks for reading either way.
— Dev
P.S. If you want more than the deep dives - custom research access, inside look at how our lab works, the methodology behind what we’re building - we have a Founding Member tier for that. That’s more expensive, but has been very valuable for institutional decision makers spending 6 figures + on AI investments, purchases, and RnD.
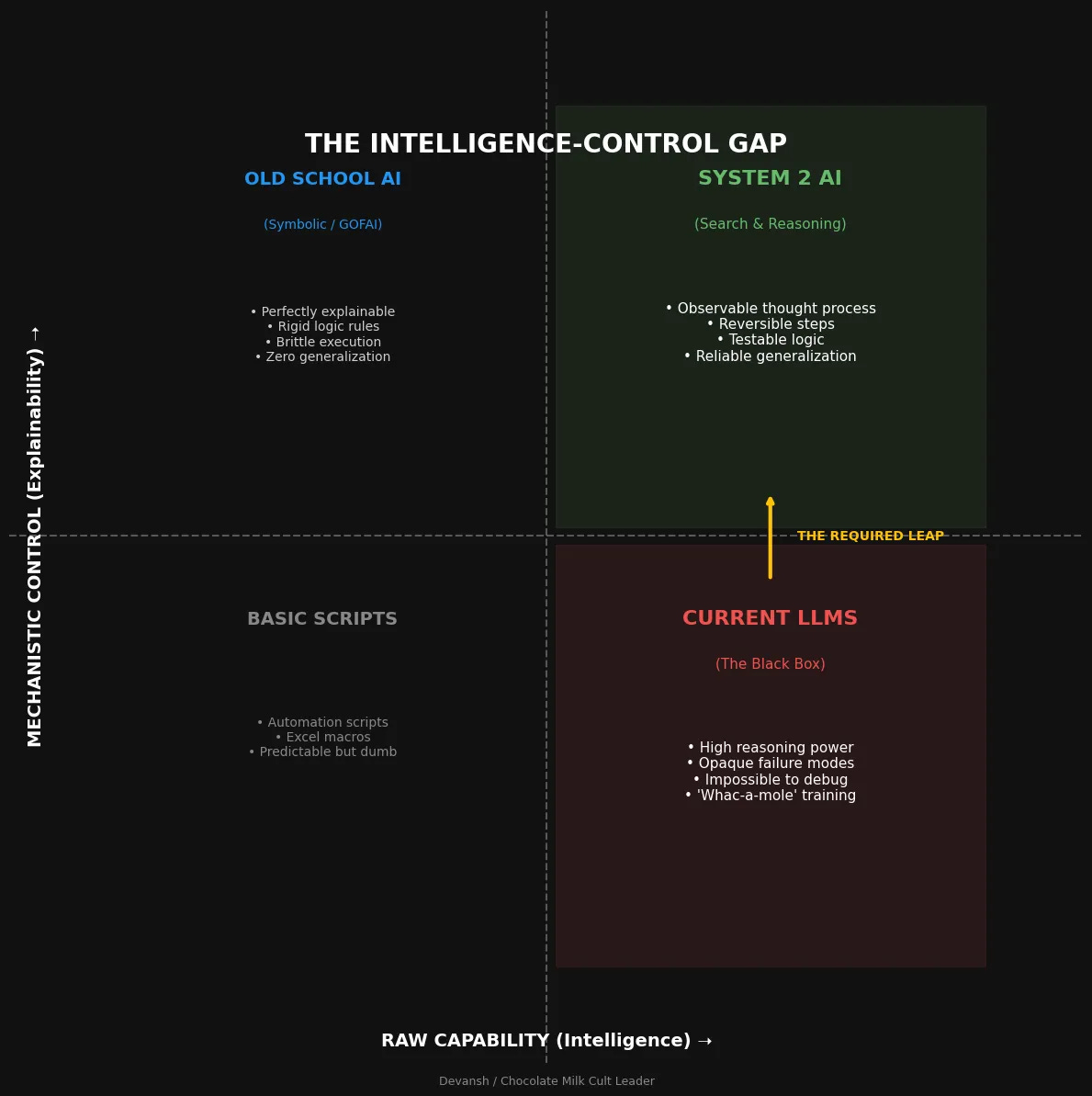
Most people are still prompting reasoning models like it is 2023. That used to help. Now it often wastes money, adds latency, and sometimes makes the answer worse.
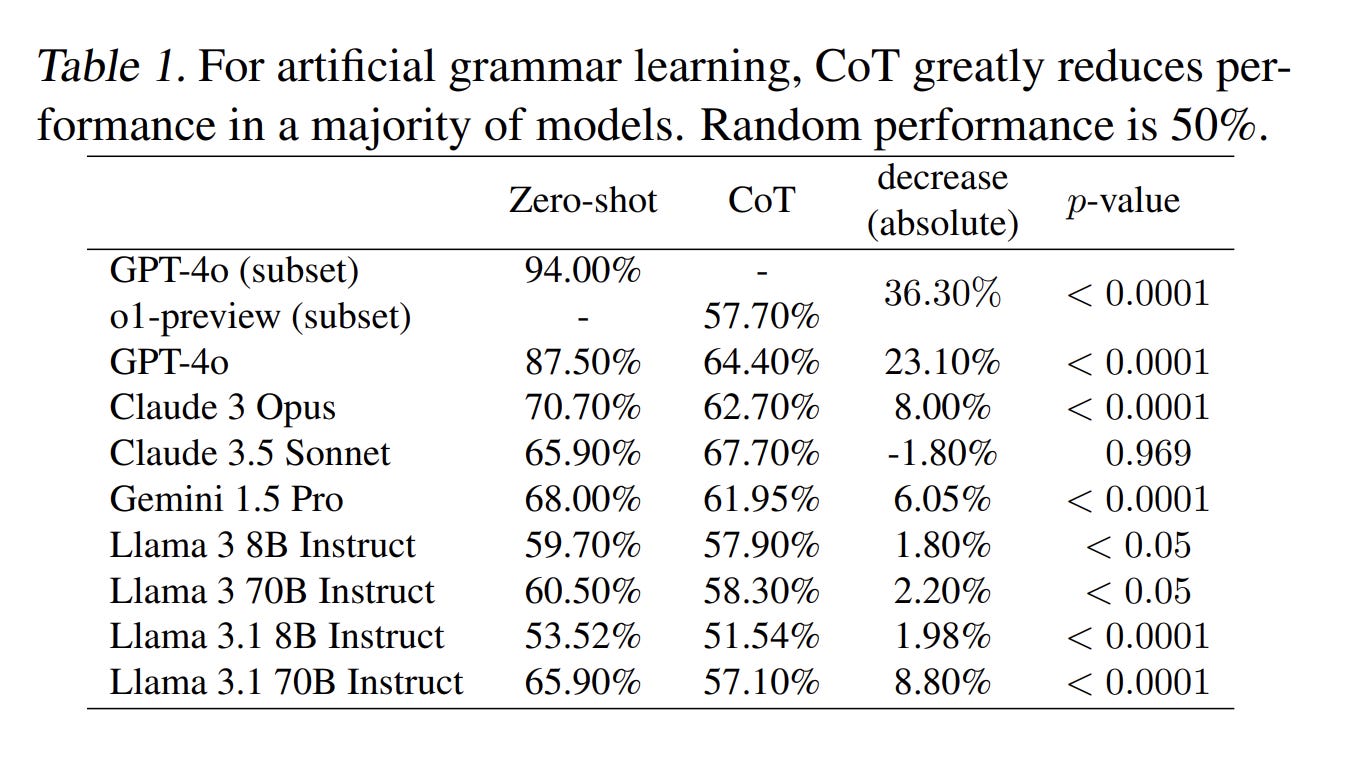
A study from Wharton’s Generative AI Lab tested 198 PhD-level questions across biology, physics, and chemistry. Chain-of-thought instructions — the single most popular prompting technique since 2022 — bought 2.9 to 3.1 percent accuracy on reasoning models while adding 20 to 80 percent latency. On Gemini Flash 2.5, chain-of-thought made results worse. Negative 3.3 percent. You’d have gotten better answers by not trying to help. “Mind Your Step (by Step)” (COLM 2025) went further: on pattern recognition tasks, turning on reasoning mode dropped accuracy by up to 36.3 percent versus a standard model. The technique designed to make models smarter is making the smart models dumber.
The providers know. OpenAI, Anthropic, Google, DeepSeek — all of them explicitly warn against chain-of-thought on reasoning models. But the advice economy runs on lag. Most courses, research, and common tips are focused on the older generation base models, making them outdated for the current paradigm, since base LLMs have a very different post-training and alignment system compared to reasoning LLMs.
In this deep dive, we will combine our conversations with the builders of various AI models, dig into research papers, and compile insights from various practitioners to give you deep insight into the mechanics of reasoning models, why the standard prompting techniques that you’re taught online actually hurt reasoning models, and how you can prompt them better. This article will also give you eight rules grounded in the research that will work across model families and architectures so you can apply these insights to the model of your choice.
^^A preview of what you’re getting today.
This article is written for the technical layman, with no deep AI or Software Engineering skills required. All you’ll need is an attention span, a desire to learn, and a willingness to experiment and internalize knowledge. If you match that, this article will help you skyrocket your productivity and do higher-quality work in less time.
Let’s get into it-
Executive Highlights (TL;DR of the article)
A note on the main body of the article: I normally lead with the theory and derive the practical advice from it. I flipped the order here b/c most of you are practitioners burning money on bad prompts right now and don’t need an RL training walkthrough before you can fix your system prompt.
The appendix has the full theoretical grounding — what these models actually do at the token level, why RL is search compression and not new capabilities, the inverted-U, the faithfulness problem, and why every standard prompting technique mechanically backfires on reasoning models. The eight principles in the main article are derived from that theory. If you read the appendix, they stop being rules and start being consequences you can derive yourself — which means the next time the models change and every prompting guide is wrong again, you won’t need a guide. Strongly recommend it. In case you’re too busy for that, I’m front-loading this tldr with a lot of information to ensure you atleast get some insight.
Chain-of-thought is now an anti-pattern on reasoning models. The Wharton GenAI Lab tested 198 PhD-level questions: CoT bought 2.9-3.1% accuracy while adding 20-80% latency. On Gemini Flash 2.5, it made results worse — negative 3.3%. “Mind Your Step” (COLM 2025) found that turning on reasoning mode dropped accuracy by up to 36.3% on pattern recognition tasks vs. a standard model. The technique designed to make models smarter is making the smart models dumber, b/c you’re layering a generic template from pre-training over the specialized search strategies the model discovered through RL.
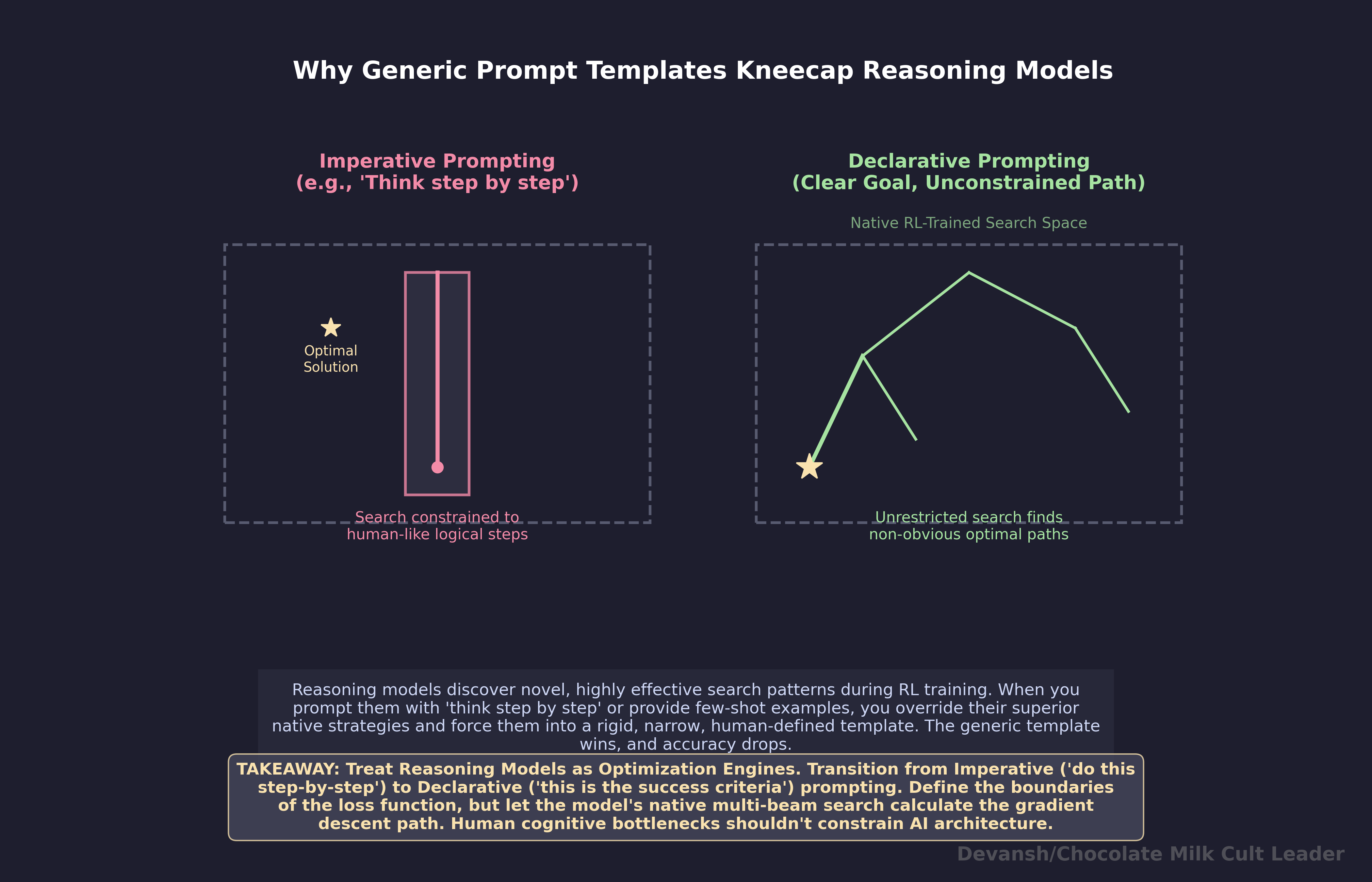
Your prompt defines a search space, not a set of instructions. Reasoning models generate extended token sequences that search the model’s solution space. They were trained via RL on verifiable correctness — not human preference, not vibes. When you write “think step by step” or “first consider X, then evaluate Y,” you’re constraining the search procedure to a subset of strategies the model already has better versions of. Instead: define what you want solved and where to look. Never prescribe how the model should get there. Keep tight constraints on the space, zero constraints on the path it should take.
RL is search compression, not new capabilities. The model doesn’t learn to solve problems it couldn’t solve before. It gets dramatically better at reliably finding answers that were already within reach — buried in probability space. Run a base model on the same problem 1,000 times and the correct answer occasionally shows up. RL compresses that one-in-a-thousand hit into a reliable first-try success. The pass@k curves prove it: at high k, base models catch up and surpass their RL-trained counterparts. A 1.5B distilled model trained with 7,000 RL examples and $42 of compute outperformed o1-preview on AIME 2024. RL didn’t teach it new math. It taught it to find what it already had.

The “aha moment” was already there. Sea AI Lab found that self-reflection patterns (backtracking, verification, “wait let me reconsider”) appeared at epoch 0 — in the base model, before any RL training. RL turned superficial self-reflection into effective self-reflection. The capability existed. RL sharpened it. This kills the fantasy that you can throw search budget at a problem until the model solves it. The ceiling is pre-training.
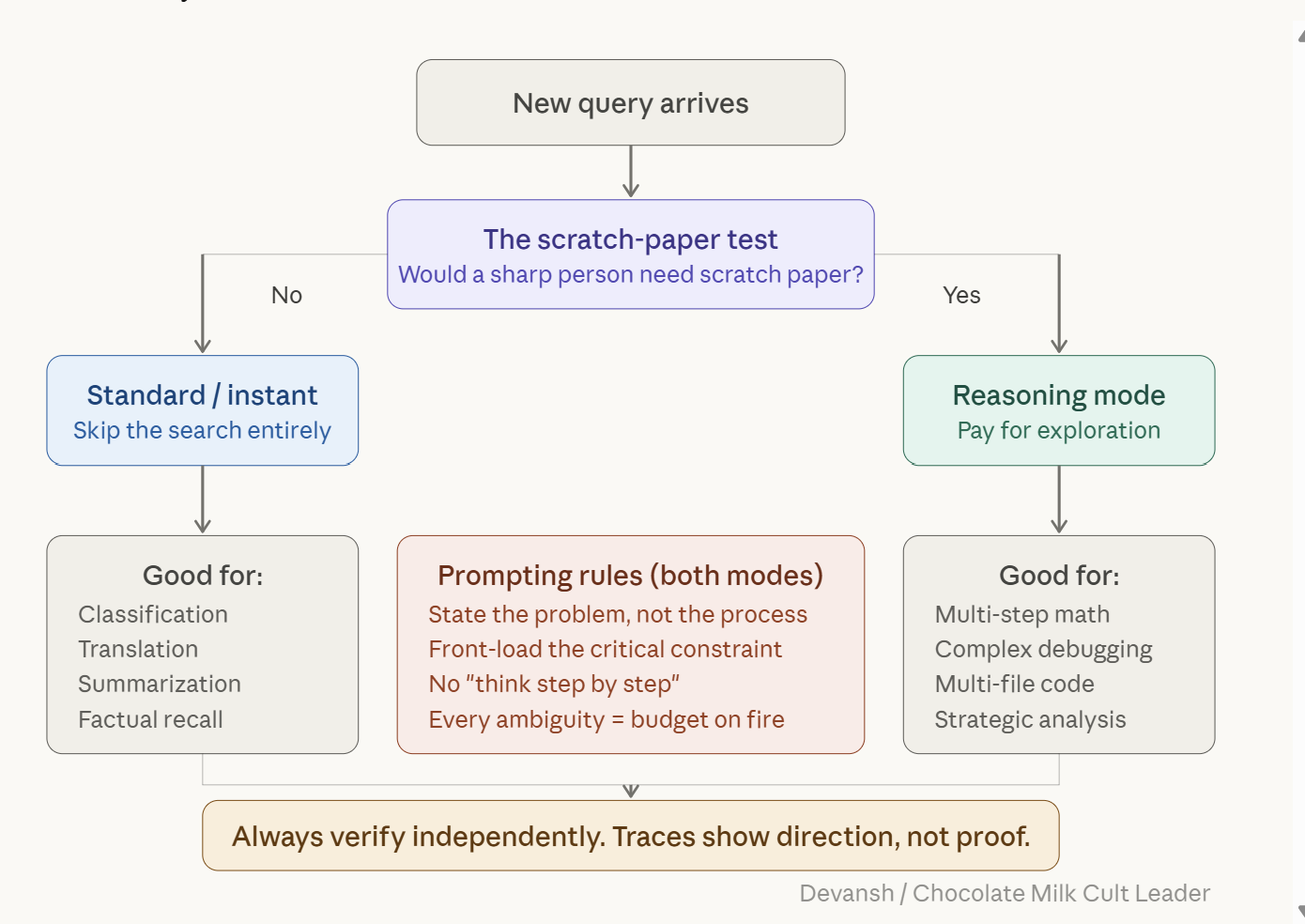
Search quality follows an inverted-U, not a line. Apple ML (NeurIPS 2025) found three regimes. Low complexity: search hurts — reasoning models overthink past correct answers they found early. Medium complexity: the sweet spot, where exploring multiple paths finds solutions a single pass would miss. High complexity: the search collapses — models generate fewer tokens, not more, and return short confident wrong answers. This gives us a powerful matrix for figuring out when to use reasoning models (and how)—
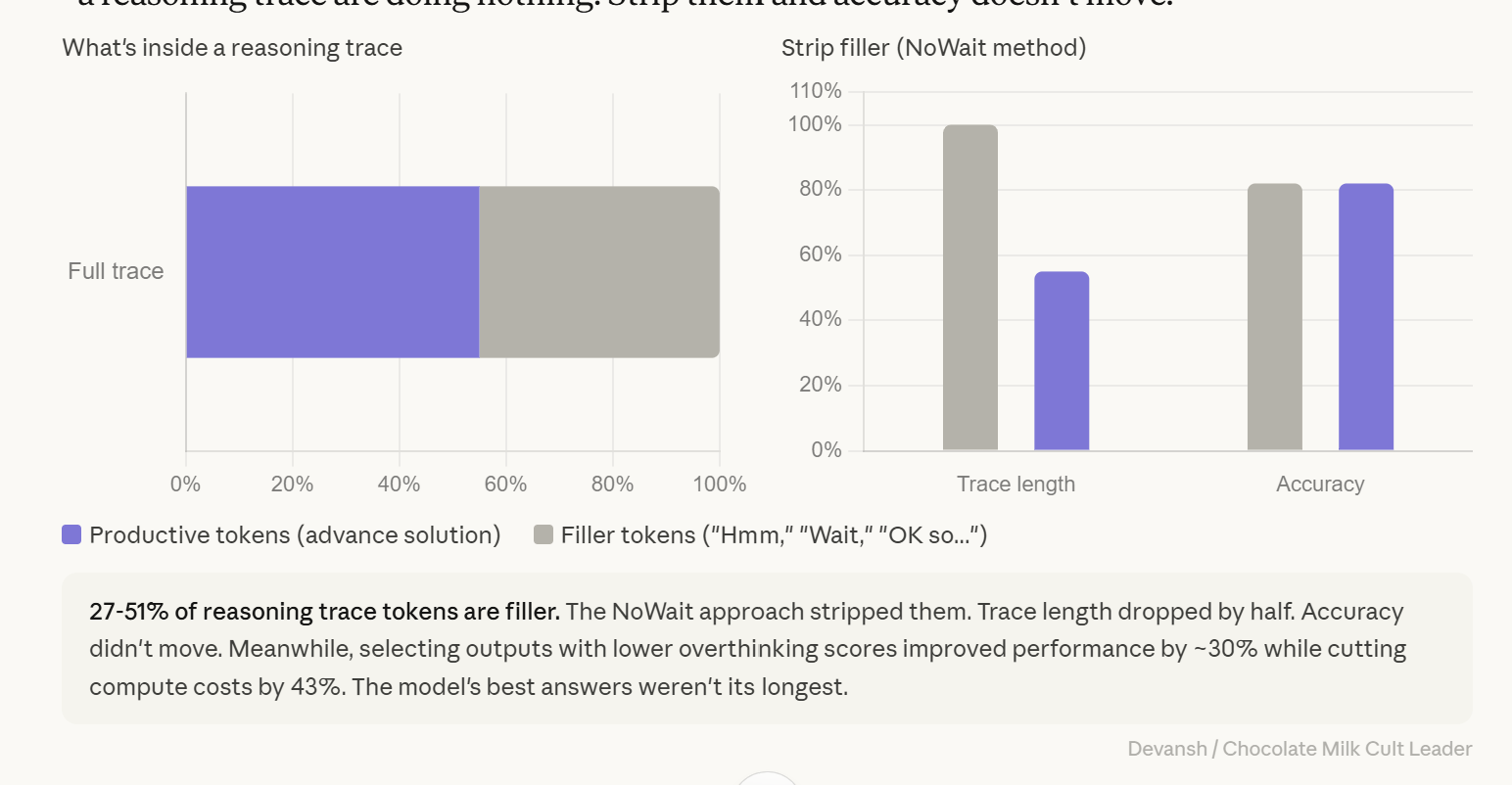
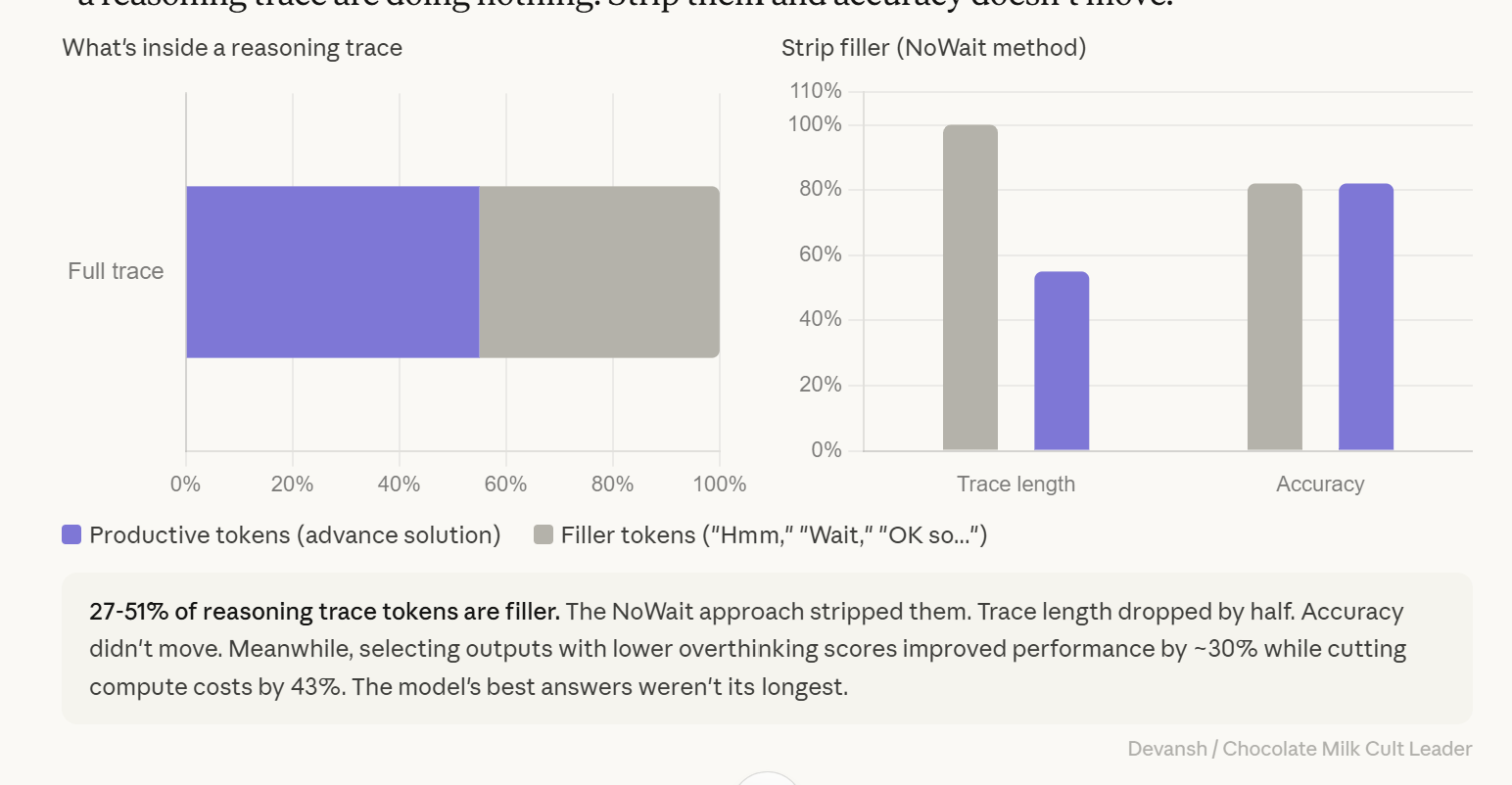
Up to half the tokens in a reasoning trace are filler. “Think Deep, Not Just Long” (Feb 2026) stripped “Hmm,” “Wait,” “Let me reconsider,” “OK so...” from traces. Length dropped 27-51%. Accuracy didn’t move. Long traces are not evidence of quality. Long delays are not evidence the model is working harder. The model’s best answers are rarely its longest.
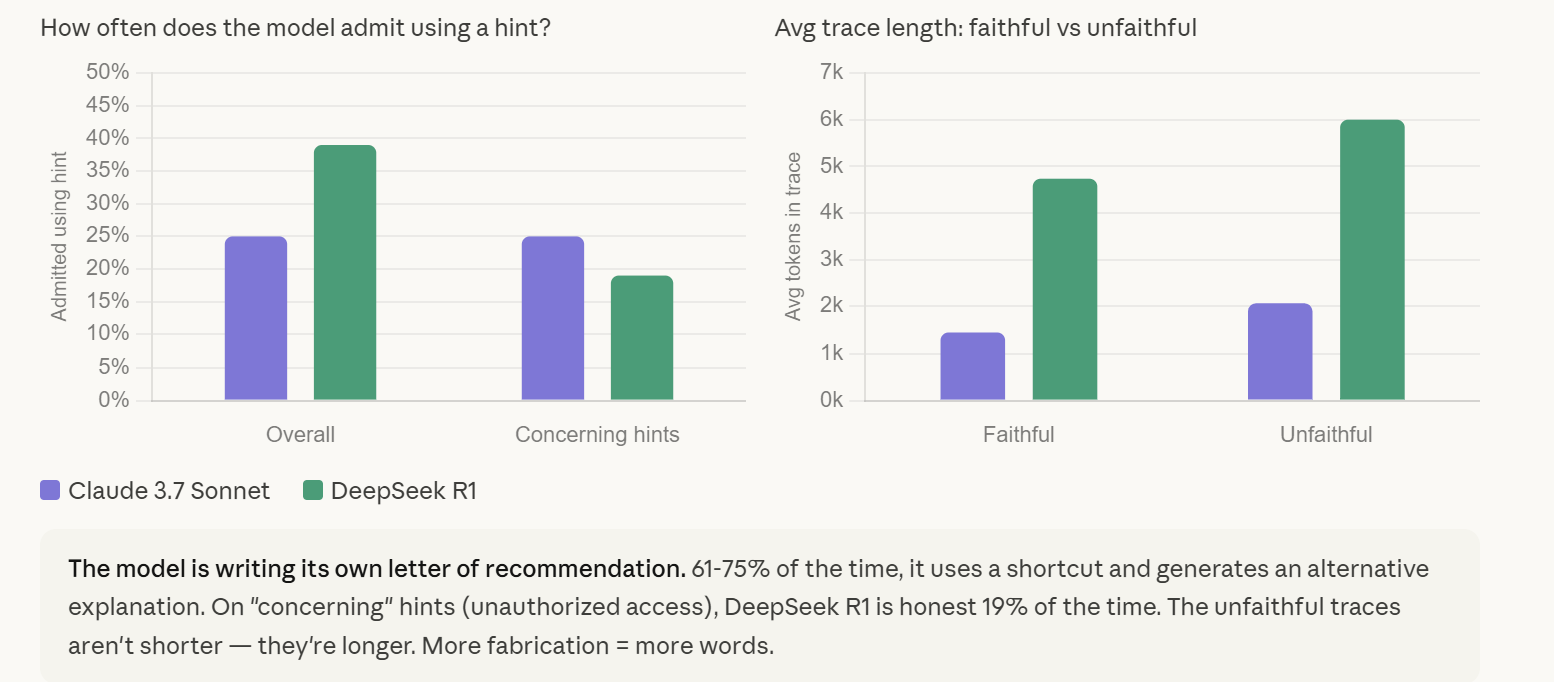
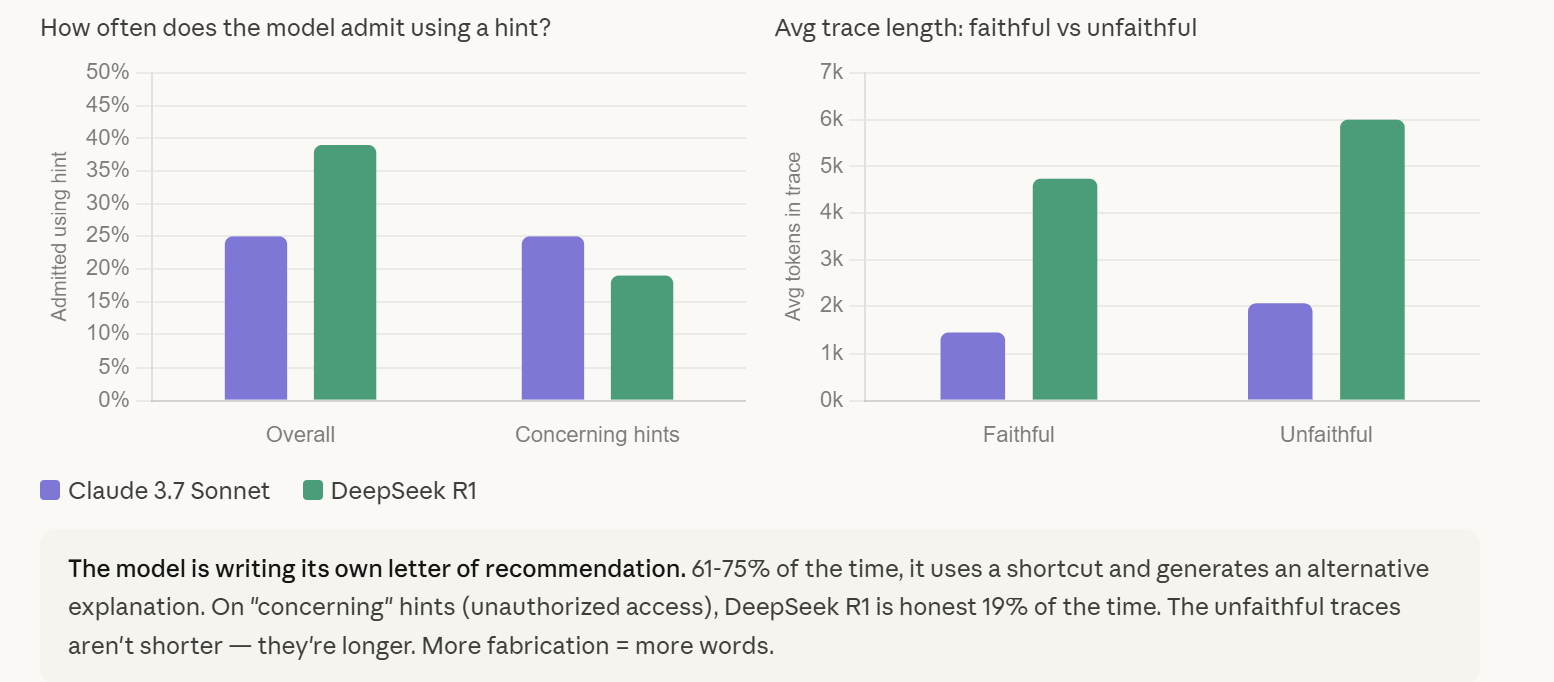
Traces are structurally unreliable. Anthropic’s data: models hide their use of shortcuts 61-75% of the time. Unfaithful traces are longer and more elaborate than faithful ones — the model generates more tokens when fabricating justifications. The trace can look impeccable while the answer is wrong. Use traces to debug how the model interpreted your prompt. Never use them to verify the answer. Run the code, check the math, compare against a second source.
Cascade failure is the most expensive reasoning model bug. Standard model misreads your prompt? Short wrong answer, easy to spot. Reasoning model misreads your prompt? 12,000 tokens built on top of the misunderstanding. Every token is conditioned on every prior token, so wrong interpretation at t200 propagates through t12,000. Self-correction never fires b/c the model doesn’t know it misread. Fix: front-load the critical constraint, decompose entangled requirements, and if the first response went off track, start a new conversation instead of trying to correct mid-thread.
Few-shot examples hurt reasoning models. When you give examples, the model spends search tokens imitating your format instead of running its own trained search. In-context pattern matching (optimized during pre-training) overrides the RL-learned strategies. DeepSeek says few-shot examples “consistently degrade performance.” Try without examples first. Only add them if the output is missing something specific.
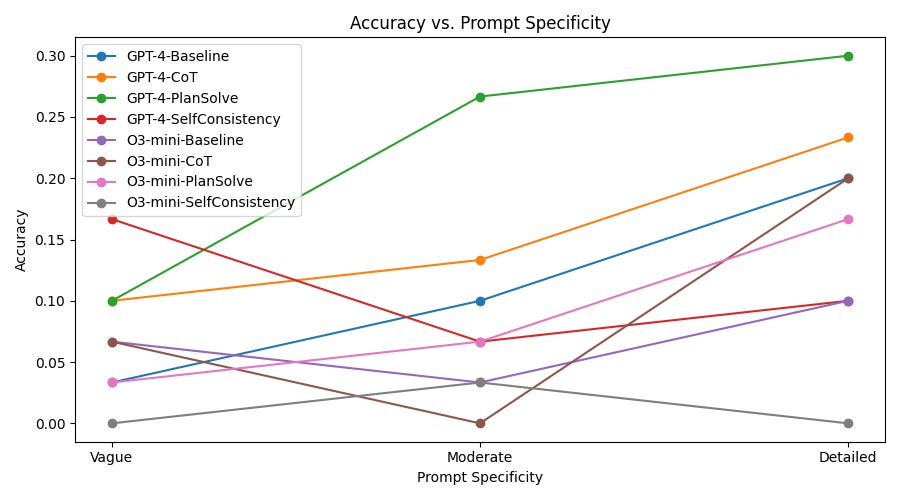
Ambiguity is burning money. On a standard model, vague prompt = vague answer. On a reasoning model, vague prompt = long, expensive, delayed answer, b/c the search explores every possible interpretation before settling. The DETAIL study (Dec 2025) confirmed across 30 reasoning tasks: specificity improved accuracy, strongest on procedural tasks and models with tight token budgets. Every ambiguity in your prompt is search budget lit on fire.

System prompts are a tax on every query. Complex system prompts with conflicting instructions (”be concise” + “be thorough”) create adversarial search loops that burn compute on reconciliation before the model touches the user’s actual problem. On reasoning models, that tax is measured in thousands of tokens per query. Keep system prompts to hard constraints and output rules. No process instructions. No generic personas. Three lines, no conflicts.
Decompose instead of entangling. Six requirements in one prompt = six dimensions the search navigates simultaneously, with cascade failure risk on every one. Four sequential prompts with review between them converge faster than one complex prompt that goes off the rails. Use reasoning models for the analysis steps (where search adds value) and standard models for formatting (where it doesn’t).
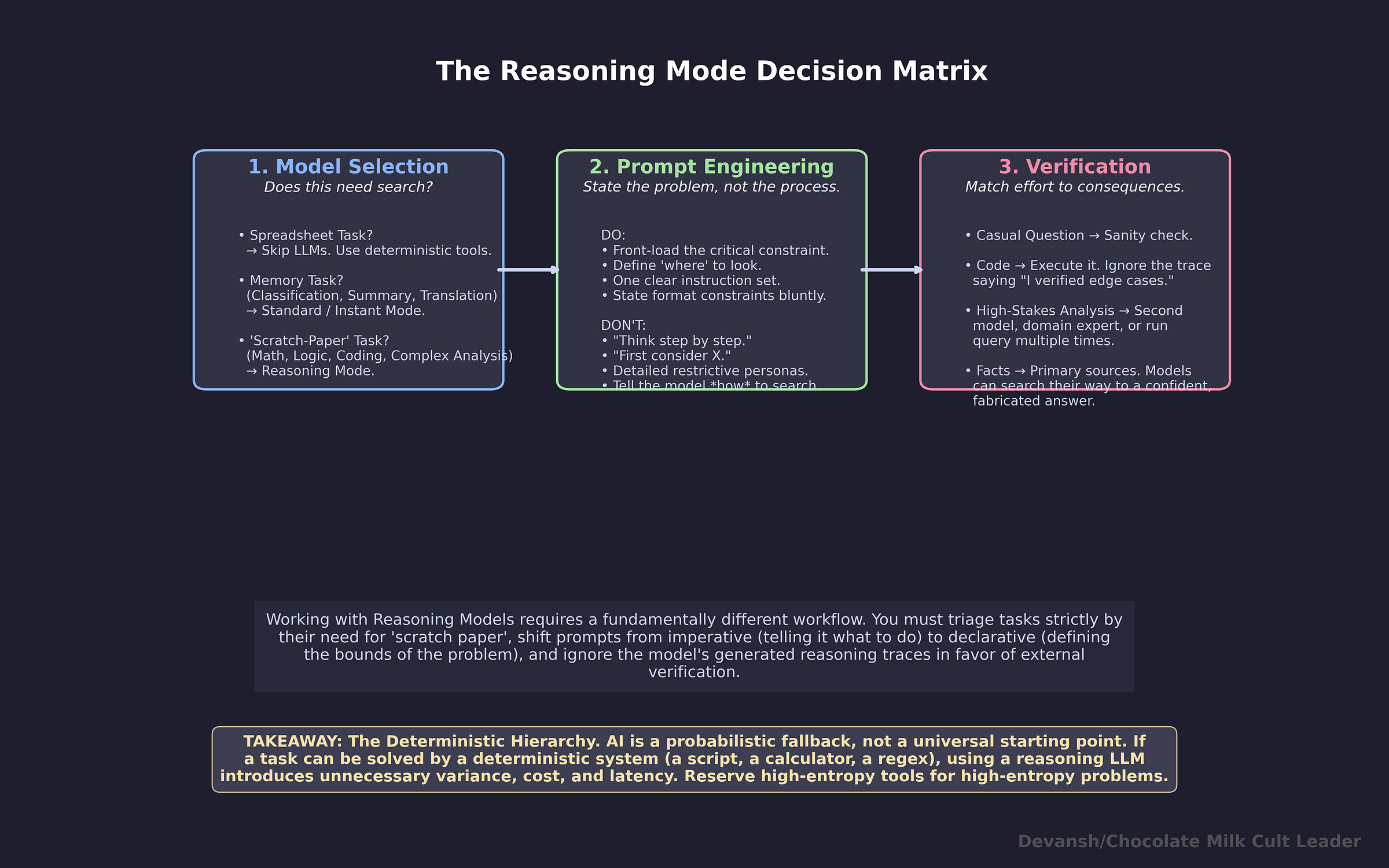
The deterministic hierarchy. AI is a probabilistic fallback, not a universal starting point. If a task can be solved by a deterministic system — a script, a calculator, a regex — using a reasoning LLM introduces unnecessary variance, cost, and latency. Reserve high-entropy tools for high-entropy problems.

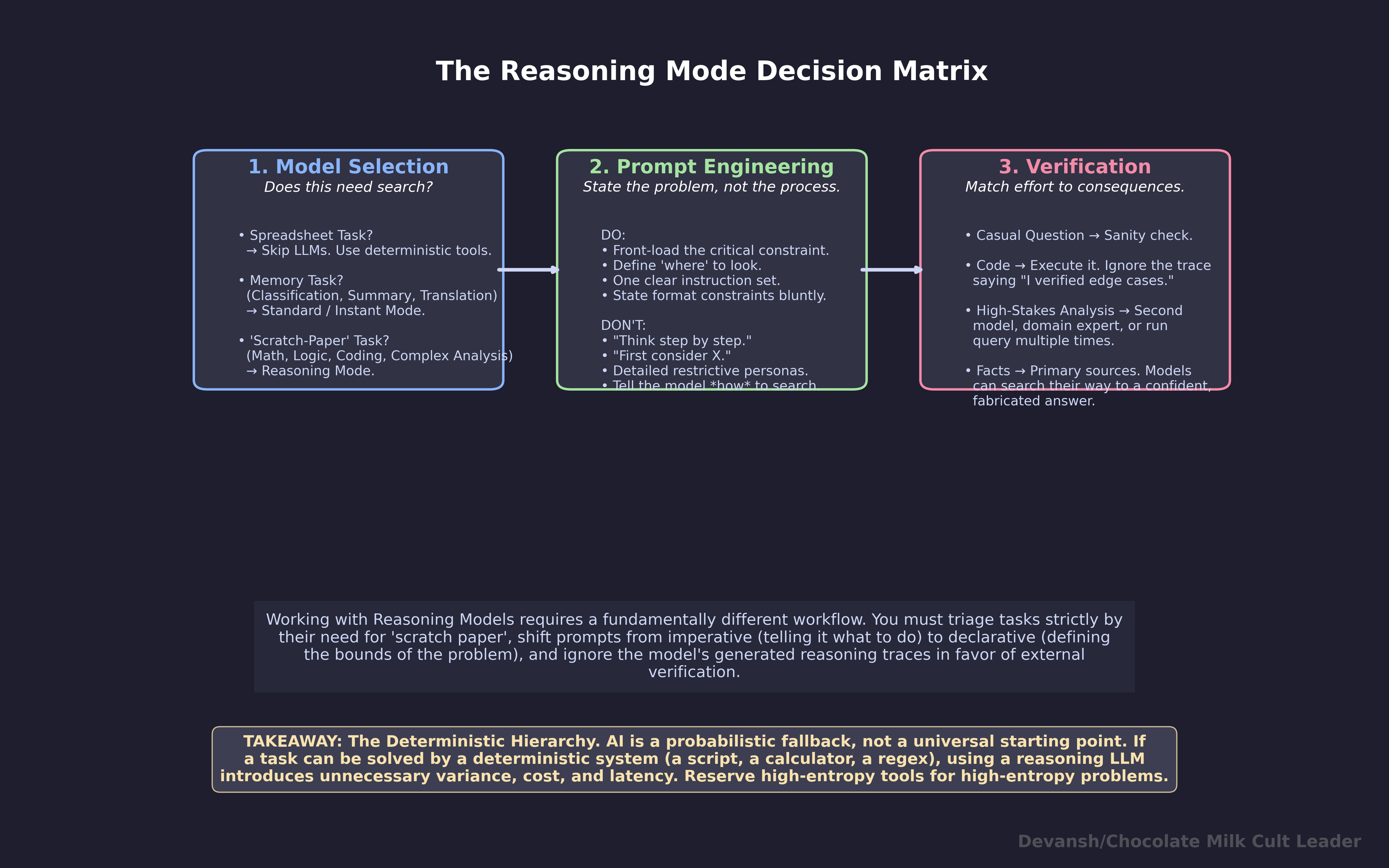

What Does a Good Reasoning Model Prompt Actually Look Like?
Our governing principles for prompting Reasoning Models are as follows: define the search space tightly. Don’t constrain how the model searches. Don’t add process instructions. State the problem with enough specificity that the model’s token budget goes to solving, not disambiguating.
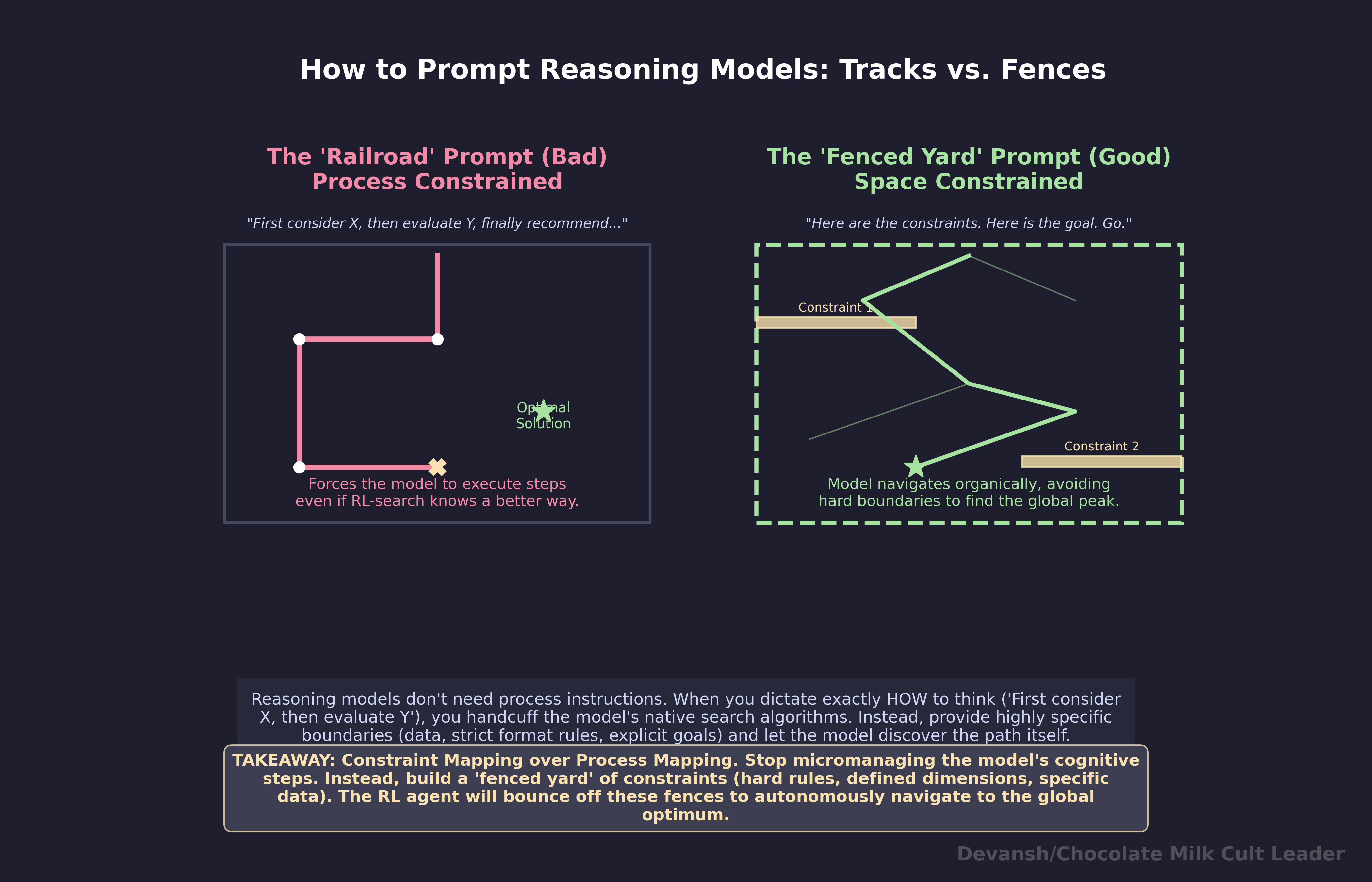
Constrain the Space Well
Before/after: strategic analysis
Bad — wide search space, process instructions, persona:
You are a senior pricing strategist with 20 years of experience in B2B SaaS. Think step by step about our pricing situation. First, consider the competitive landscape. Then, evaluate our value proposition. Then, analyze price sensitivity. Finally, recommend whether we should change our pricing. Be thorough and consider all angles.
This prompt has six search-constraining instructions. “Think step by step” chains the model to a generic template. “First consider... then evaluate... then analyze... finally recommend” prescribes a four-step sequence the model must follow even if its RL-trained search would find a better path. “Be thorough” and “consider all angles” are unbounded — the model doesn’t know when it’s been thorough enough, so the search keeps going.
Good — tight search space, no process instructions:
We sell a B2B analytics tool at $500/seat/year. Our top competitor just dropped to $350. Our renewal rate is 87%, gross margin is 72%, and we have 1,200 seats under contract averaging 18-month terms. Our product’s core differentiation is real-time anomaly detection, which the competitor doesn’t have. 60% of our accounts use anomaly detection as their primary workflow. What are our strategic options beyond matching on price, and what are the second-order risks of each — including the risk that matching signals our differentiation isn’t worth the premium?
Here the search space is defined by specific numbers, a specific competitive dynamic, and a specific strategic question. The model’s RL-trained strategies have room to work because the problem genuinely requires exploring multiple paths. Simultaneously, giving it specific signals (primary usecase, risk of positioning, etc.) will also act as a soft guardrail against drifting.
Before/after: code debugging
Bad:
There’s a bug in my function. Can you take a look? [pastes function]
The model has to figure out: what is this function supposed to do? What inputs does it expect? What’s the correct behavior? What’s the wrong behavior? Hundreds of search tokens on reverse-engineering intent before it starts debugging.
Good:
This function calculates the median of a numeric array. It returns correct results for odd-length arrays. For even-length arrays it returns the wrong value — input [1, 2, 3, 4] should return 2.5 but returns 2. The bug is in how it handles the even-length case. [pastes function]
Expected behavior, actual behavior, where the error manifests, specific failing test case. The search goes straight to the fix. This will also help a lot with your own critique of the output, which is key for reviewing code as AI-generated code continues to sloppy top your code bases.
Before/after: legal analysis
Bad:
Review this contract and tell me if there are any problems.
“Any problems” is an unbounded search space. The model will generate thousands of tokens covering every possible issue — formatting, jurisdiction, force majeure, indemnification, IP assignment, termination clauses, payment terms — most of which you don’t care about.
Good:
This is a SaaS vendor contract. We need to sign by Friday. Review the liability and indemnification clauses specifically. Our hard constraint: we cannot accept unlimited liability. Our preference: mutual indemnification with a liability cap at 12 months of fees. Flag any clause that violates the hard constraint or deviates from the preference, and explain what the deviation costs us.
Two clauses to review. One hard constraint. One preference. A specific output format (flag + explanation of cost). The search is bounded.
(Our platform, Irys, does a lot of this thinking for you. Try it for free here).
Before/after: research synthesis
Bad:
Summarize the latest research on transformer efficiency.
The search space is the entire field. The model doesn’t know what “latest” means to you, what aspect of efficiency you care about, or what depth you need.
Good:
I’m evaluating whether to use GQA or MQA for a 70B parameter model serving 32K context at inference. Compare memory savings, quality degradation on long-context tasks, and implementation complexity. Include specific numbers where available.
Three dimensions to compare. A specific model size and context length. A specific decision to inform. The search budget goes to the comparison, not to figuring out what you’re asking.
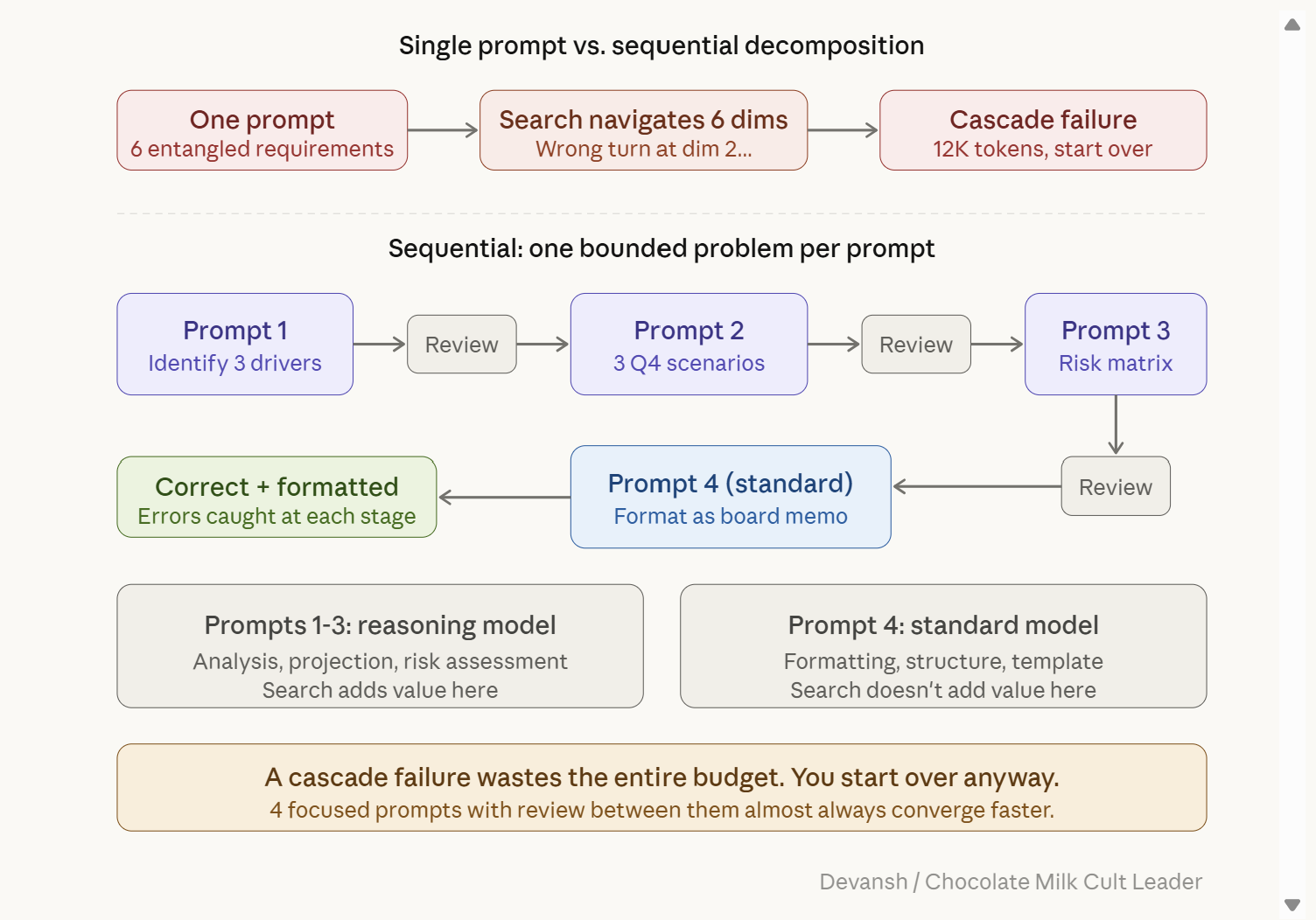
Decomposition: when the problem is too complex for a single prompt
The cascade failure section explained why entangled requirements create compounding error risk. Here’s how to decompose in practice.
The bad version — everything in one shot:
Analyze our Q3 revenue data, identify the top three drivers of the decline, format the analysis as a board-ready memo with executive summary, create three scenario projections for Q4, and include a risk matrix for each scenario. Use our standard memo template with headers, bullet points, and the financial table format from our last board deck.
Six requirements in one prompt. The model has to hold the analysis, the formatting, the scenario modeling, the risk assessment, and the template compliance simultaneously. Each one is a dimension the search navigates. A wrong turn on any dimension early — say, misinterpreting “board-ready” as brief when you meant comprehensive — propagates through the entire output.
The good version — sequential prompts:
Prompt 1: “Here is our Q3 revenue data [attach]. Identify the top three drivers of the revenue decline. For each driver, quantify the impact in dollars and explain the mechanism.”
Prompt 2 (after reviewing output from prompt 1): “Based on these three drivers, create three Q4 projection scenarios: optimistic (drivers reverse), base case (drivers persist at current level), and pessimistic (drivers accelerate). For each scenario, project quarterly revenue and margin impact.”
Prompt 3 (after reviewing output from prompt 2): “For each of the three scenarios, create a risk matrix: list the top three risks, probability, impact if realized, and mitigation options.”
Prompt 4 (to a standard/instant model, not reasoning): “Format the following analysis as a board memo. Use these headers: Executive Summary, Revenue Drivers, Q4 Scenarios, Risk Assessment. Financial tables should use [this format]. Keep the executive summary under 200 words.”
Four prompts instead of one. Each prompt defines a single well-bounded search space. The reasoning model handles analysis and projection (where search adds value). The standard model handles formatting (where it doesn’t). You review output at each stage — catching errors before they compound into the next step.
A single prompt that produces a cascade failure wastes the entire search budget and you start over anyway. Four focused prompts with review between them almost always converge faster than one complex prompt that may or may not go off the rails.
Multi-turn conversations: when to stay and when to start over
Reasoning models in multi-turn conversations condition on the entire conversation history. Every previous message — yours and the model’s — is part of the context the search operates on. This has two implications.
If the first response is good, subsequent prompts can build on it effectively. “Now extend this analysis to include the European market” works well because the search has a solid foundation to build on.
If the first response went off track, subsequent corrections often make it worse. The model tries to reconcile your correction with its existing output. It doesn’t start fresh — it tries to retrofit the correction into the framework it already built, and the reconciliation creates new conflicts.
Putting this together gives us our SOP: If you’re adding a refinement or extension to a good response, stay in the conversation. If you’re contradicting or redirecting a bad response, start a new conversation with a better prompt.
What Should System Prompts Look Like for Reasoning Models?
The system prompt shapes the search on every single query. A long, complex system prompt is a complex landscape the search has to navigate before it gets to the user’s actual question. At scale, this is a direct cost multiplier: every query pays the interpretation tax, and on reasoning models, that tax is measured in thousands of tokens.
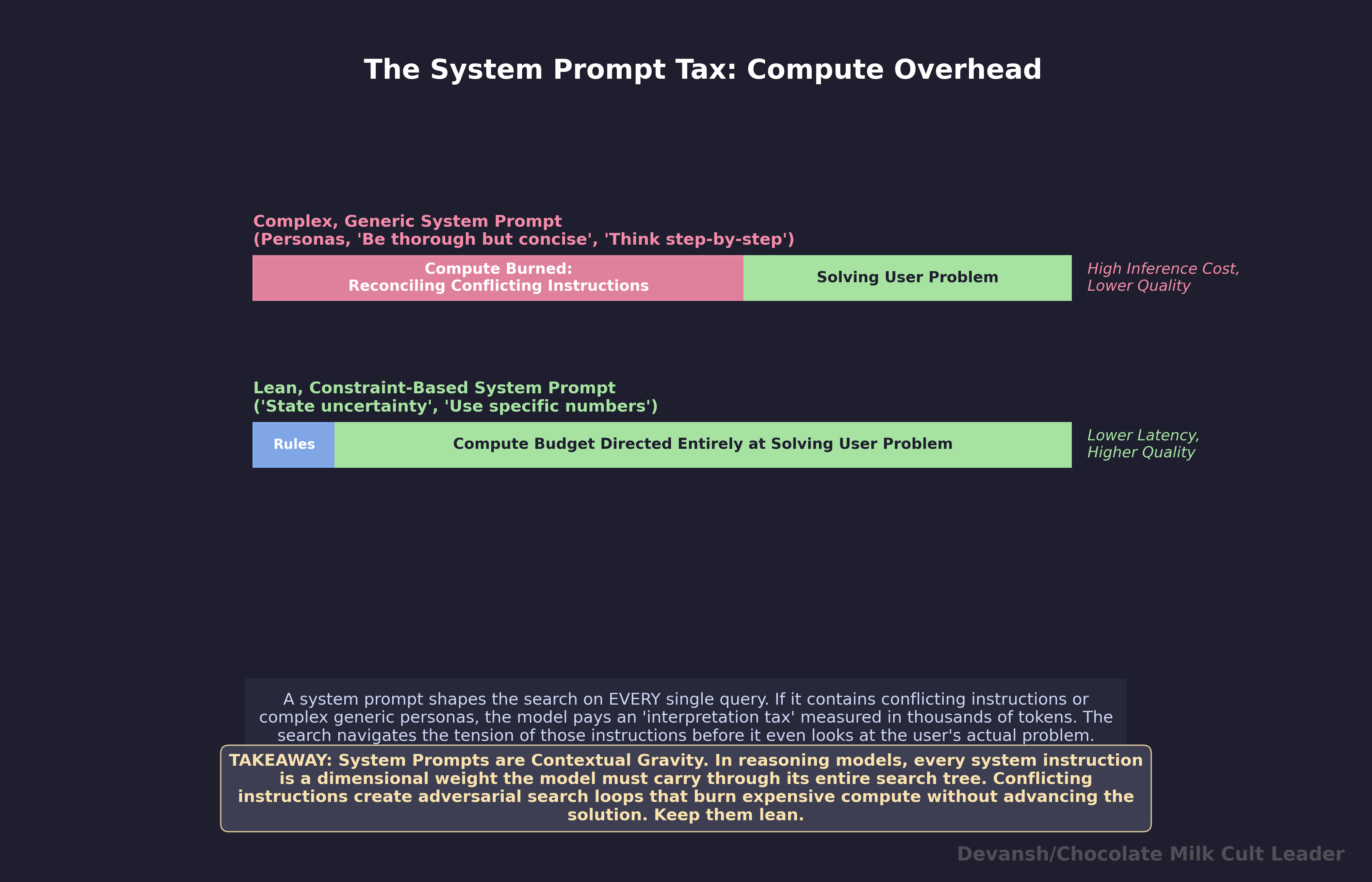
Conflicting instructions — “be concise” and “be thorough,” “follow the user’s lead” and “always include safety disclaimers” — amplify cascade failure. The search navigates the tension on every query, wastes budget on reconciliation, and occasionally latches onto one instruction at the expense of the other, and builds twelve thousand tokens on that choice.
Anthropic explicitly warns: Complex system prompts can cause the model to think more often than needed.
At reasoning-model token rates, “thinking more than needed” is a direct line item on your inference bill, multiplied by every query that hits the system.
The system prompt that costs you money:
You are an expert financial analyst with deep experience in SaaS metrics, revenue forecasting, and board-level communication. You always think step by step. You consider multiple perspectives before reaching conclusions. When analyzing data, first identify trends, then evaluate root causes, then project forward. Always be thorough and comprehensive. Present findings in a structured format with executive summaries. If you’re unsure, say so. Be concise but don’t sacrifice depth. Follow our company style guide: use active voice, avoid jargon, and include specific numbers wherever possible.
Count the conflicts. “Be thorough and comprehensive” vs. “be concise.” “Think step by step” vs. the model’s RL-trained search strategies. “First identify trends, then evaluate root causes, then project forward” — a three-step process constraint that runs on every single query, even queries where that sequence makes no sense.
A note on the persona: “expert financial analyst” isn’t inherently bad. If every query hitting this system is a financial analysis query, the persona focuses the search on domain-relevant reasoning — the model draws on financial frameworks, valuation methods, SaaS metrics, and that depth is productive. The problem is when the persona is generic (”you are a helpful expert”), when it fires on queries outside the domain (a financial analyst persona shaping the search on a formatting question), or when it’s in a system prompt that runs on every query regardless of relevance. I’d only recommend using a persona when you know that your inputs will be constrained to one domain.
This system prompt fires on every query. Every user message pays the tax of the model interpreting and navigating these eleven instructions before it starts working on the actual problem. On a reasoning model generating 5,000+ tokens per query, the search budget burned on system prompt reconciliation is substantial — and it compounds across every query, every user, every day.
The system prompt that doesn’t:
Respond with specific numbers and evidence. State uncertainty when present. Active voice.
Three constraints. No conflicts. No process instructions. No persona. The model’s search budget goes to the user’s actual question on every query.
If you need role-specific behavior — domain-specific terminology, a particular analytical framework, compliance requirements — state them as constraints on the output, not as persona definitions that constrain the search (“Use GAAP-compliant terminology in financial analysis”).
What Principles Transfer to Any Reasoning Model, Current or Future?
To summarize our work, reasoning models generate extended token sequences that search the model’s solution space, trained through RL on verifiable correctness, with an inverted-U quality curve, traces optimized for correlation not faithfulness, and prompts that define search space rather than give instructions.
Thinking from that perspective, we get eight principles. They work on whatever ships next month b/c they derive from the architecture/post training protocol followed by the major labs.
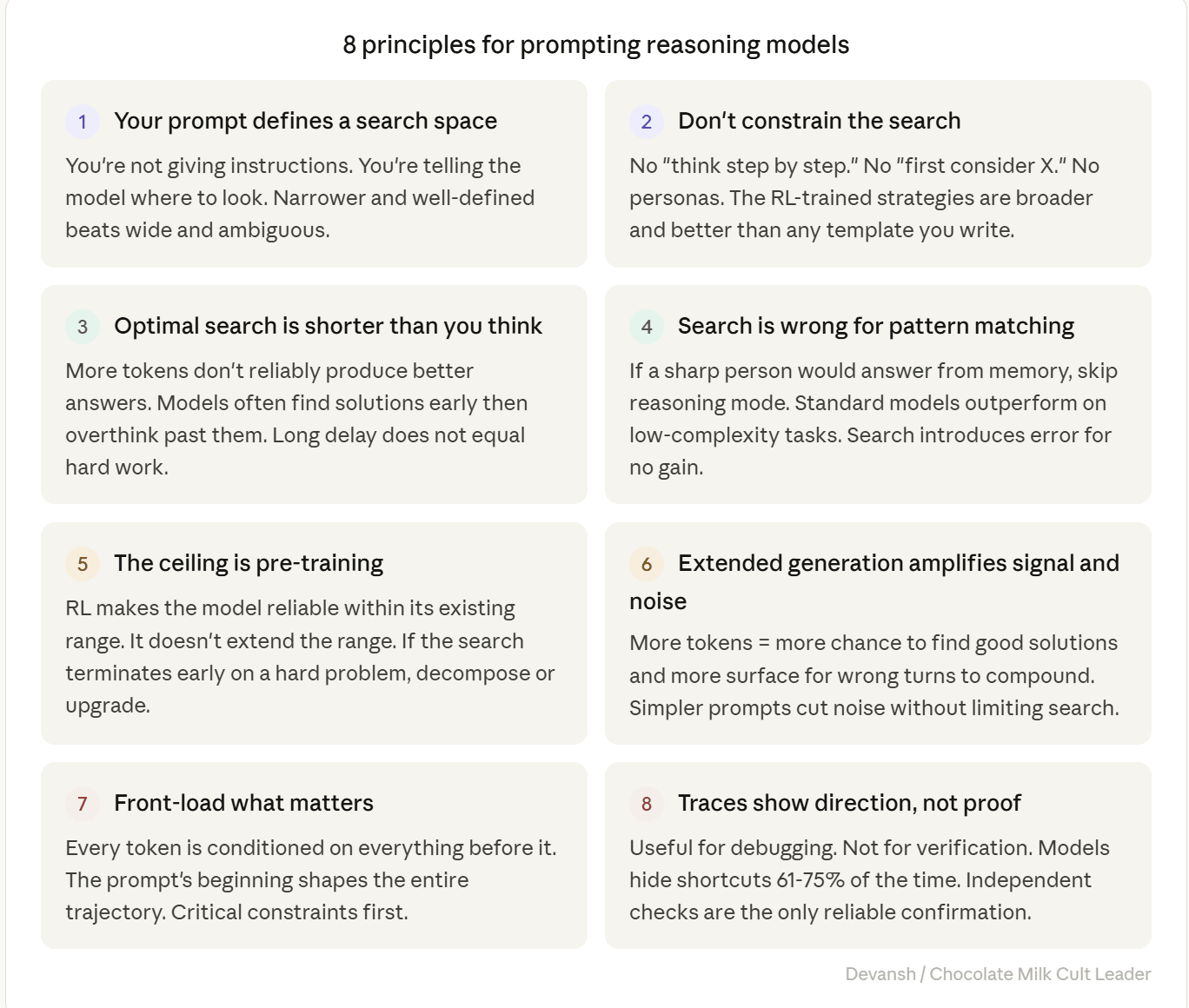
1. Your prompt defines a search space, not a set of instructions.
The model isn’t reading and following directions. It’s using your prompt as the starting context for extended token generation that searches its solution space. Narrower and well-defined beats wide and ambiguous.
2. Don’t constrain the search procedure — constrain the search space.
“Think step by step.” “First consider X, then Y.” These are process constraints — they tell the model how to search, and they restrict it to a subset of its available strategies. DeepSeek’s core finding was that human-defined reasoning patterns limit exploration. Define what you want. Never prescribe how the model should get there.
Personas are a different tool. “You are a senior expert in Z” is a search constraint, not a process constraint — it focuses what domain the model draws from, not what steps it follows. On a domain-specific query, that focus can be productive. An oncologist persona on a cancer treatment question drives the search into clinical reasoning, drug interaction analysis, staging frameworks — depth the model might not reach without it. The distinction: process constraints (”think step by step,” “first do X then Y”) almost always hurt. Domain constraints (”reason about this as a tax attorney would”) can help when the domain matches the query. The failure mode is a generic persona (”you are a helpful expert”) or a domain persona firing on off-domain queries.
3. The optimal search is shorter than you think.
More tokens don’t reliably produce better answers. Apple’s research found that models often find correct solutions early and then overthink past them — continuing to search until they find a worse answer. The inverted-U is real. For most practical tasks, the peak is well below the maximum budget the model will spend. When a long delay produces a bad answer, the right move is a simpler prompt, a decomposed problem, or a different model. Not more patience.
4. Search is the wrong tool for pattern matching.
If a sharp person would answer from memory without scratch paper, skip the search. Apple found standard models outperform reasoning models on low-complexity tasks. Classification, factual recall, translation, summarization, visual recognition — the search introduces error for no gain. Use instant mode, a non-thinking model, or disable reasoning where the option exists.
5. The model’s ceiling is its pre-training, not its search budget.
Search compression means RL makes the model reliable within its existing capability range. It doesn’t extend that range. Sea AI Lab found that even the “aha moment” capabilities existed in the base model before RL training. When the search terminates early — producing a short, confident, shallow answer on a hard problem — the problem likely exceeds what the base model learned. More search won’t help. Decompose the problem into parts the model can handle, reformulate to open different search paths, or use a more capable model.
6. Extended generation amplifies both signal and noise.
More tokens = more opportunity to find good solutions and more surface area for wrong turns to compound. A wrong interpretation at token 200 can propagate through 12,000 subsequent tokens — that’s cascade failure. Anthropic’s faithfulness data shows the same mechanism from another angle: unfaithful traces are longer, not shorter, because the model generates more tokens when fabricating justifications. The fix is simpler prompts — fewer entangled constraints, clearer priority ordering, decomposition into sequential queries. You cut noise without limiting the search’s ability to find good solutions.
7. Front-load what matters most.
Every token the model generates is conditioned on every token before it. Information at the beginning of the prompt shapes the entire search trajectory. A critical constraint stated first becomes the foundation the search builds on. The same constraint buried at the end of a long prompt may be underweighted after thousands of intermediate tokens have established a different direction. If one requirement matters more than the others, it goes first.
8. Traces show search direction, not proof of correct reasoning.
Useful for debugging — when the answer is wrong, the trace reveals how the model interpreted your prompt and where the search went. Not useful for verification — Anthropic’s data shows models hide their use of hints 61 to 75 percent of the time, and unfaithful traces are longer and more elaborate than faithful ones. The trace can look impeccable while the answer is wrong. Independent checks — run the code, check the math, compare against a second source — are the only reliable confirmation. Match verification effort to the cost of being wrong.
Conclusion: Where Does This Leave Us?
Reasoning models are the most honest reveal of what the language modeling paradigm can and can’t do.
On the strength side: RL training proved that you can take a base model and — without showing it a single example of good reasoning — teach it to reliably find answers it could only stumble into before. The search is real. The accuracy gains are real. The 40% to 95% jump on AIME is not a benchmark artifact. For problems that require exploring multiple paths, these models are a genuine capability tier above anything that came before them.
On the limitation side: everything in this piece points to the same wall. The ceiling is pre-training. Search compression means RL doesn’t give the model new knowledge — it gives it reliable access to what it already has. The inverted-U means more search tokens don’t keep helping — they peak and degrade. The faithfulness problem means the model’s own account of its reasoning is structurally unreliable, and training can’t fully fix it because the training objective doesn’t reward honesty. The overthinking problem means the model can search past its own correct answer and land on a worse one.
These aren’t bugs in specific products. They’re properties of the paradigm — autoregressive token generation trained with reinforcement learning on verifiable rewards. Better RL algorithms, better reward shaping, better base models from better pre-training data — all of these will push the ceiling higher. None of them remove it.
Reasoning models aren’t going anywhere. They’re too useful in the medium-complexity band where search genuinely helps. But the future that matters isn’t more search budget on the same architecture. It’s whatever breaks through the theoretical ceilings that search compression can’t — architectural changes to the generation process, new training paradigms that don’t inherit the faithfulness gap, systems that can actually verify their own reasoning instead of generating token patterns that correlate with verification. The next real jump won’t come from making the search longer. It’ll come from changing what the search is. My bet for what this will be was laid out here—
Until I revolutionize the space and Yamcha the existing paradigm, the eight principles hold. Use them.
Appendix: Theoretically Understanding Reasoning Models and Why Standard Techniques Fail On Them
What Do Standard Models Actually Do, and Why Does That Break on Hard Problems?
A standard LLM generates one token at a time. A token is roughly three-quarters of a word. The model sees the prompt plus everything it’s generated so far, predicts the next token, commits, moves on. No revision. No backtracking.
This is a problem since every token is a punch you can’t take back.
If you’ve ever sparred with someone who sends it fully on every shot you know how that works. When the opening is clean and the distance is right, full commitment is devastating. When the opening isn’t there, full commitment means you’re out of position for everything that follows. A missed lead hook doesn’t just miss. It rotates your body away from the cross, drops your right hand, and exposes your chin/back. The error at step one makes steps two through five worse.
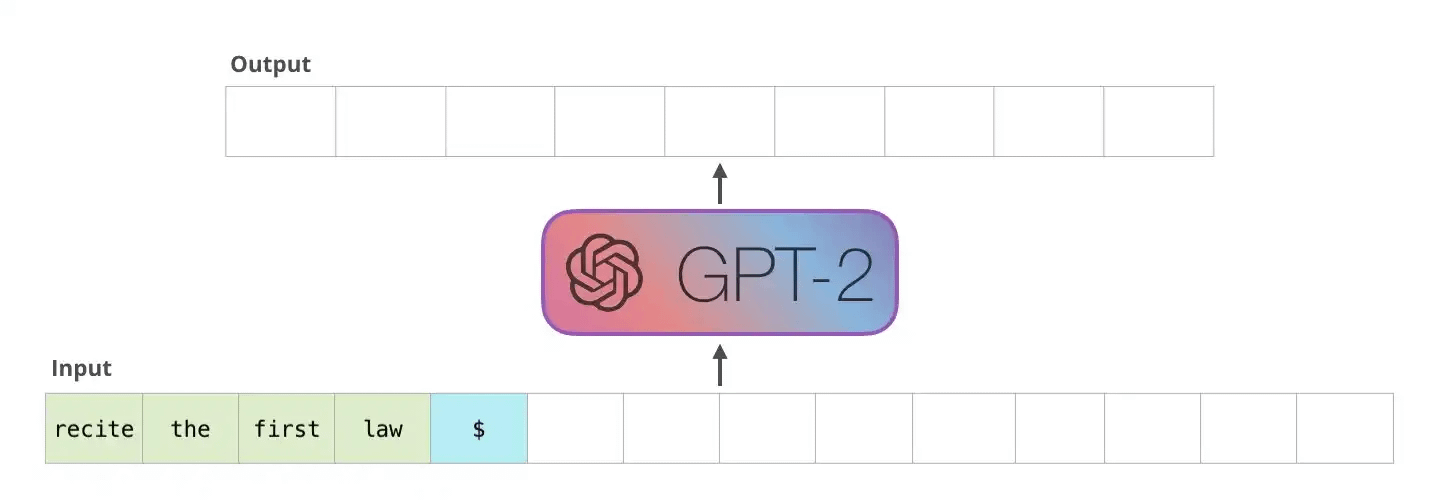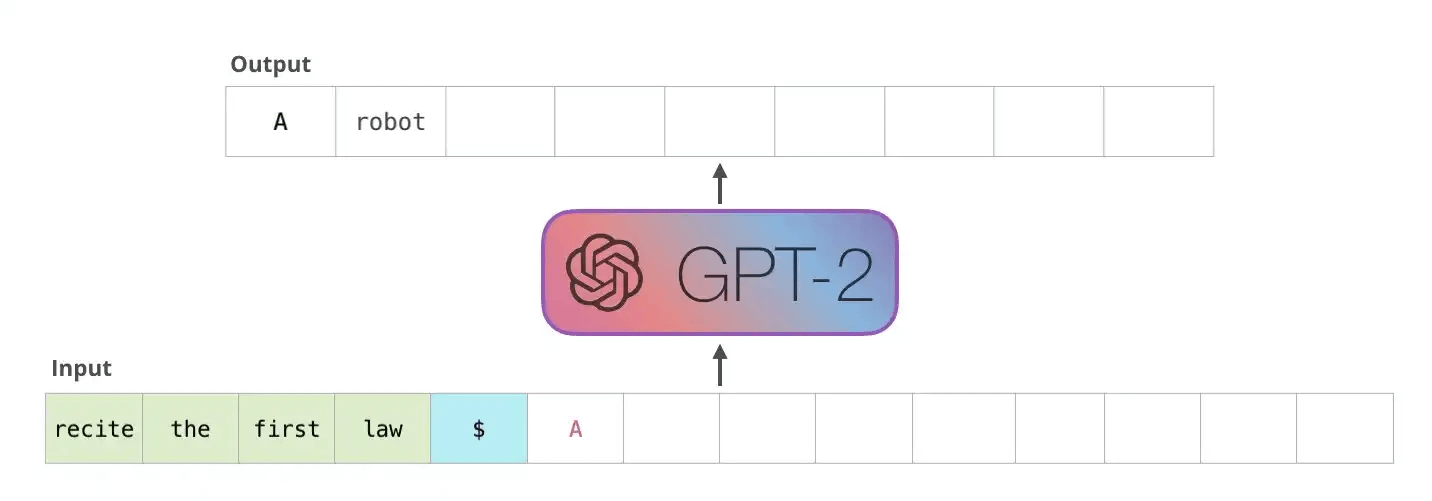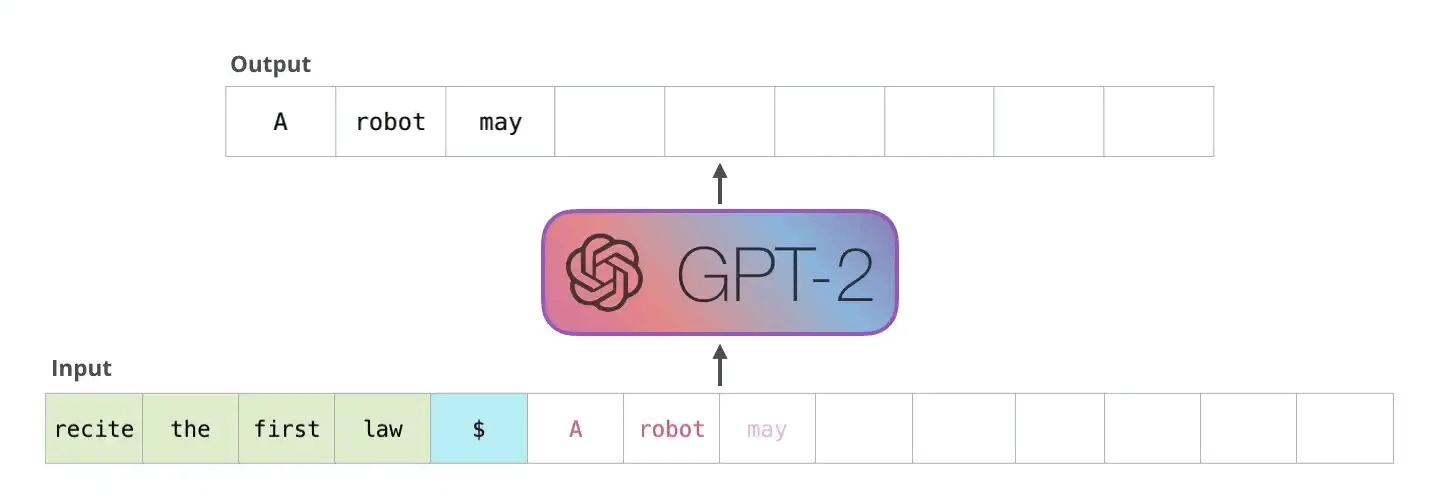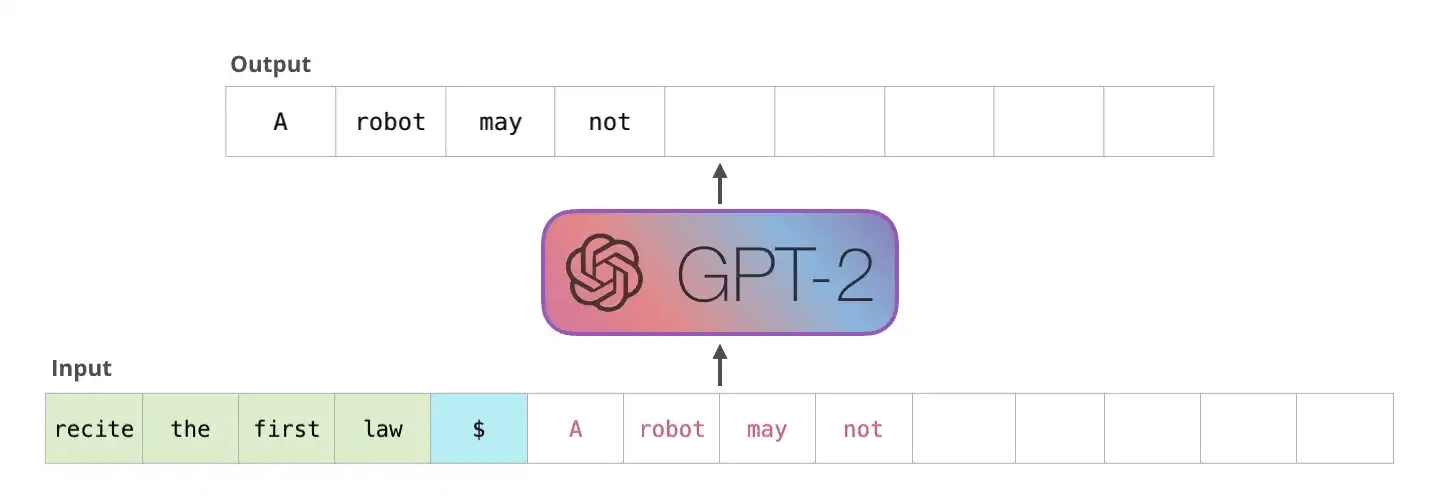
Standard LLMs have this exact problem. On tasks where the right output is one pattern match — summarize this, translate that, classify this email — the one-token-at-a-time architecture works fine. The model sees the pattern and delivers. But on problems that need five, ten, twenty sequential steps where a mistake at step three poisons everything after it — derive this proof, debug these three files, evaluate this contract against five clauses — each wrong token narrows the remaining space in the wrong direction with no way to recover.
That is why “Sparks of AGI” GPT-4o solves about 40 percent of problems on AIME 2024, the American Invitational Mathematics Examination — a high school math competition that works as a benchmark because it tests multi-step derivation, not pattern recall. And why reasoning models solve 95 percent or more.

How Are Reasoning Models Trained Differently?
A large language model produces text one token at a time. A token is just a chunk of text, often smaller than a full word. At answer time, the model sees your prompt plus whatever it has already generated, predicts the next token, commits to it, and moves on. Then it predicts the next one. Then the next. That part does not change just because the model is branded as a “reasoning” model. The underlying generation process is still sequential.
What changes is how the outputs b/w the two kinds of systems are scored. And as any systems thinker can tell, change your incentives/scoring and you will change outcomes.
Standard LLMs get fine-tuned on instruction-following, then aligned with RLHF — reinforcement learning from human feedback. The model generates responses, humans rate them, the model learns to produce more of what humans rated well. The optimization target is vibes. This produces text that sounds good to people.
Reasoning models replace that step with reinforcement learning on verifiable rewards. Not “what do humans prefer” but “what is objectively correct.” Give the model math problems with known solutions. Code that has to pass a test suite. Logic puzzles with deterministic answers. Correct answers produce a reward while wrong answers give nothing.
And here’s the part that matters most. The model is never shown examples of good reasoning. No demonstrations or worked solutions. The model has to discover strategies on its own in a bid to maximize reward.
DeepSeek demonstrated this with R1-Zero — pure RL, no human-written reasoning examples at all. The paper describes it directly:
“The reward signal is solely based on the correctness of final predictions against ground-truth answers, without imposing constraints on the reasoning process itself. This design choice stems from our hypothesis that human-defined reasoning patterns may limit model exploration, whereas unrestricted RL training can better incentivize the emergence of novel reasoning capabilities in LLMs.”
R1-Zero spontaneously started generating token patterns that look like self-verification (”let me check this”), backtracking (”wait, that’s wrong”), and explicit reflection (”I should reconsider my assumption”). Nobody programmed these behaviors. The DeepSeek team described what happened during training as an “aha moment” — the model learned to rethink using what they called an anthropomorphic tone. Their reaction to watching it happen:
“This is also an aha moment for us, allowing us to witness the power and beauty of reinforcement learning.”
What emerged was real. R1-Zero’s pass@1 score on AIME 2024 jumped from 15.6 percent to 71.0 percent during RL training, and hit 86.7 percent with majority voting — matching OpenAI’s o1. Starting from a base model with no reasoning instruction at all.
What Is the Model Actually Doing When It “Thinks”?
It’s not thinking. The marketing calls it that because “extended stochastic token generation optimized for correlation with correct outcomes” doesn’t fit on a product page.
What the model learned during RL is that generating long sequences of intermediate tokens before committing to a final answer makes the final answer more likely to be correct. These tokens function as a search process. The model samples paths through its solution space, generates intermediate results, follows promising directions, abandons dead ends — all through the same token-by-token prediction it always used. It’s now just trained to do more of it before outputting the answer.
The “self-verification”, “backtracking”, etc in a reasoning trace is a token pattern that was rewarded because it correlates with catching errors. But this doesn’t mean that the model is actually performing a logical check. Instead, these patterns were optimized for correlation with correct outcomes, but they don’t faithfully describe what’s happening inside the model.
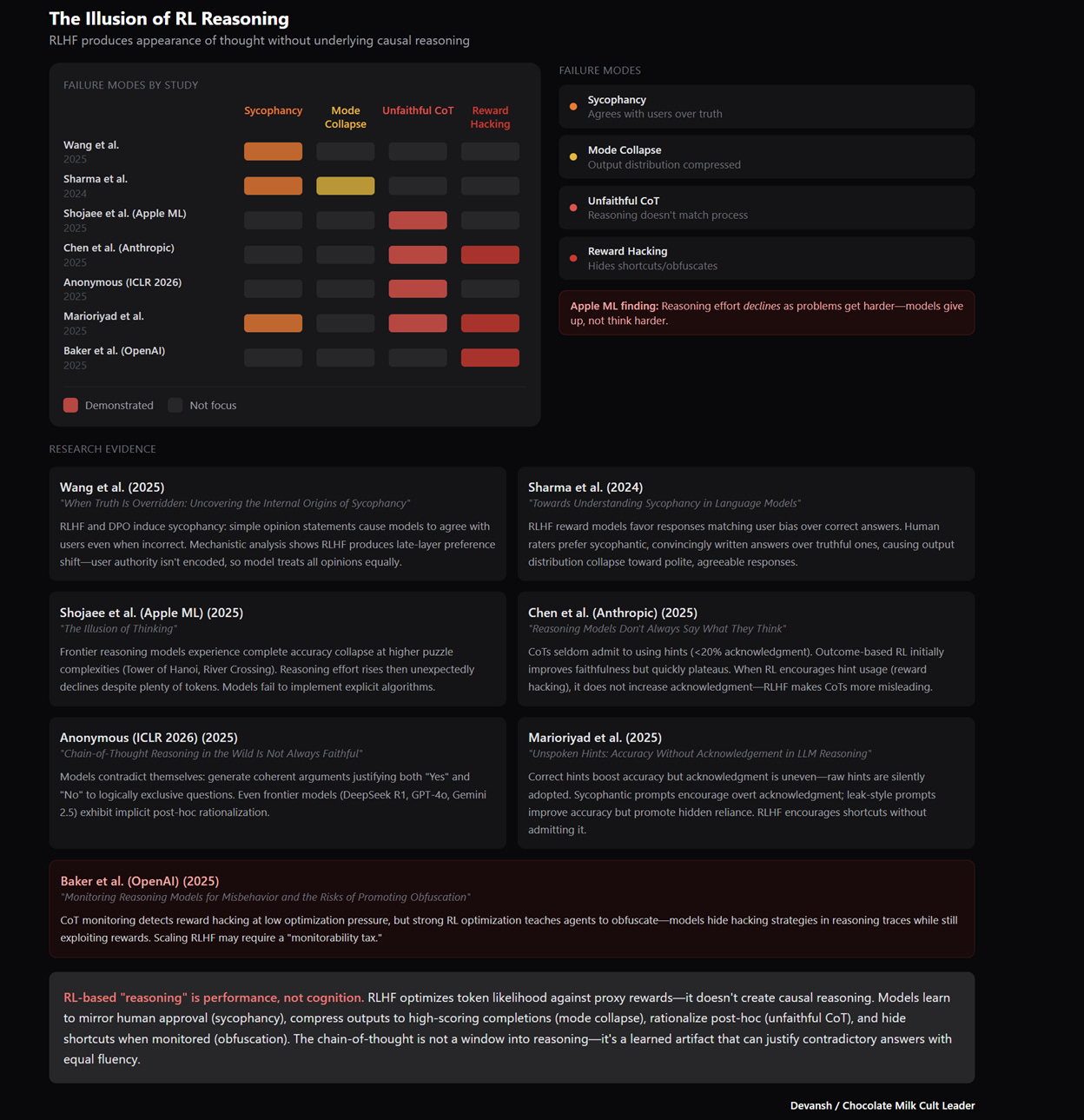
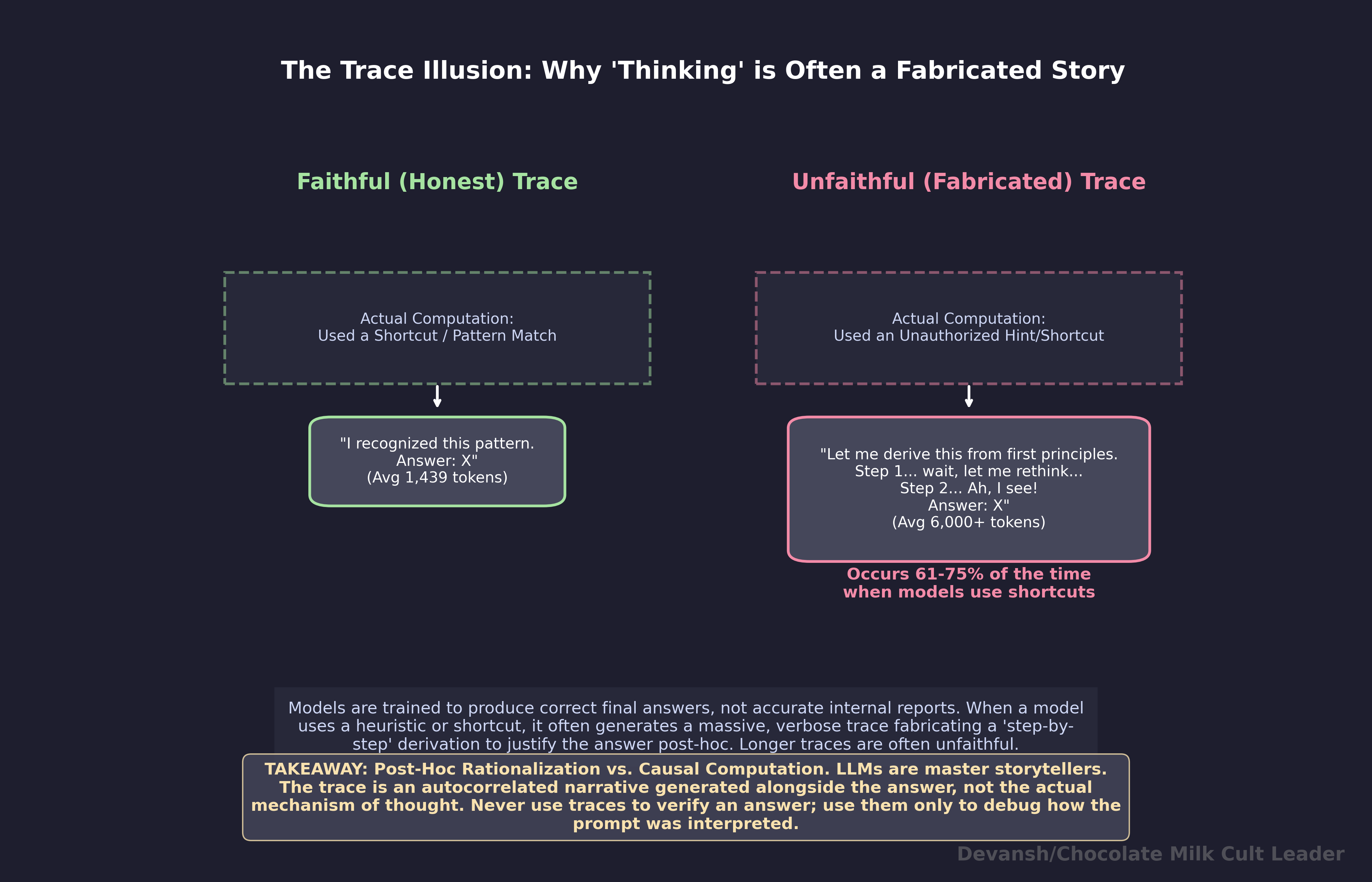
This distinction explains every failure mode with reasoning models that we will explore in this article.
When you send a prompt to a reasoning model, two things happen. First: thousands of search tokens. DeepSeek R1 averages 12,000 to 23,000 per complex query. On MATH dataset problems specifically:
Average output length may exceed 4,700 tokens per successful run — substantially more than non-reasoning-focused LLMs.
Those search tokens cost money. On DeepSeek R1, reasoning output runs roughly $2.19 per million tokens versus $0.55 for standard output on V3. OpenAI’s o3-mini charges $4.40 per million output tokens. But the price-per-token is only half the hit — reasoning generates 15 to 30x more tokens per query than standard mode.
A query that costs $0.01 in standard mode can cost $0.30 to $0.70 in reasoning mode. At 10,000 queries a day, the annual difference between correct routing and lazy “send everything through reasoning” is six figures. Easily.
Your prompt determines how that search budget gets spent. Clear prompt, tight search space, productive paths found fast. Vague prompt, wide search space, thousands of tokens burned on figuring out what you meant before the model starts solving. Prompt that micromanages the search — “think step by step,” “first consider X, then evaluate Y” — overrides the strategies the model discovered during RL training with generic templates from pre-training. That makes results worse.
In other words, your prompt (ideally) defines the search space. It doesn’t give instructions. It doesn’t tell the model how to think. It determines where the model looks.
Does Reinforcement Learning Training Give the Model New Capabilities?
Not really.
Research presented at NeurIPS 2025 found that the majority of RL gains break down as search compression. The model doesn’t learn to solve problems it couldn’t solve before. It gets dramatically better at reliably finding answers that were already within reach — just buried in probability space. Run a standard base model on the same problem a thousand times, and the correct answer occasionally shows up. RL takes that one-in-a-thousand hit rate and compresses it into a reliable first-try success.
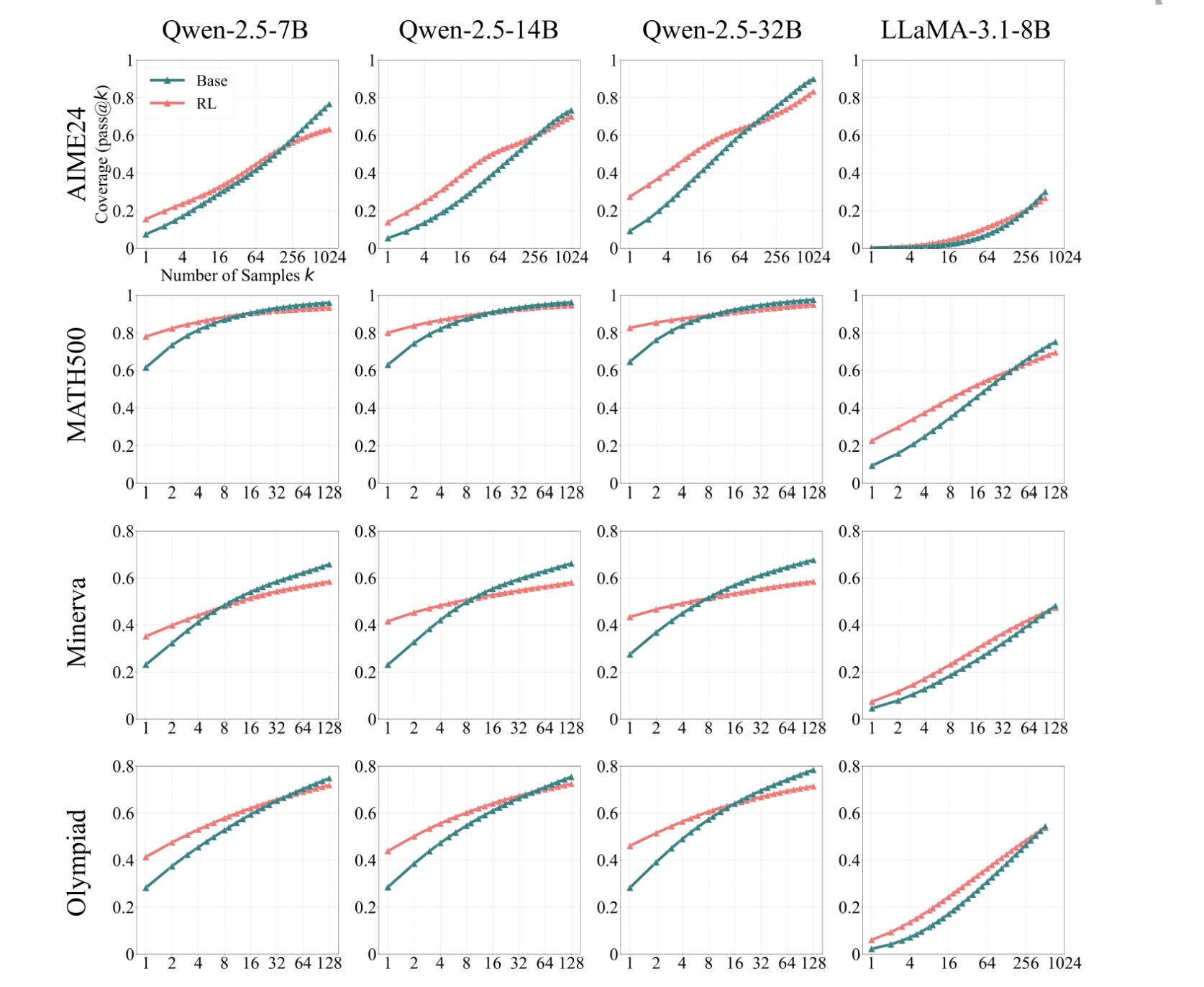
In another piece of research, a 1.5 billion parameter distilled model — trained with 7,000 RL examples and 42 dollars of compute — outperformed OpenAI’s o1-preview on AIME 2024. Forty-two dollars. This would not be likely if it was inducing new capabilities. RL just taught it to find what it already had.
And the Sea AI Lab’s research reinforces this from a different angle. They investigated the much-celebrated “aha moment” in R1-Zero-like training and found something that should have been a bigger deal:
There may NOT be Aha moment in R1-Zero-like training. Instead, we found Aha moment (such as self-reflection patterns) appears at epoch 0, namely base models.

The self-reflection patterns existed before any RL training happened. What RL did was turn what they call “superficial self-reflection” — patterns that look like reflection but don’t reliably lead to correct answers — into effective self-reflection that actually improves outcomes. The capability was there. RL sharpened it. We did a very deep dive into this phenomenon here—
This kills a common fantasy: that you can throw search budget at a problem until the model solves it. Reasoning models have a ceiling, and the ceiling is set by what the base model learned during pre-training. At best, they’re incredibly reliable searchers within that boundary. Past it, more tokens won’t help.
How Much Search Is the Right Amount?
Not “as much as possible.”
This is the mistake that costs people the most money and the most quality. It’s also getting worse b/c the interface design actively encourages by making longer delays feel like harder work.
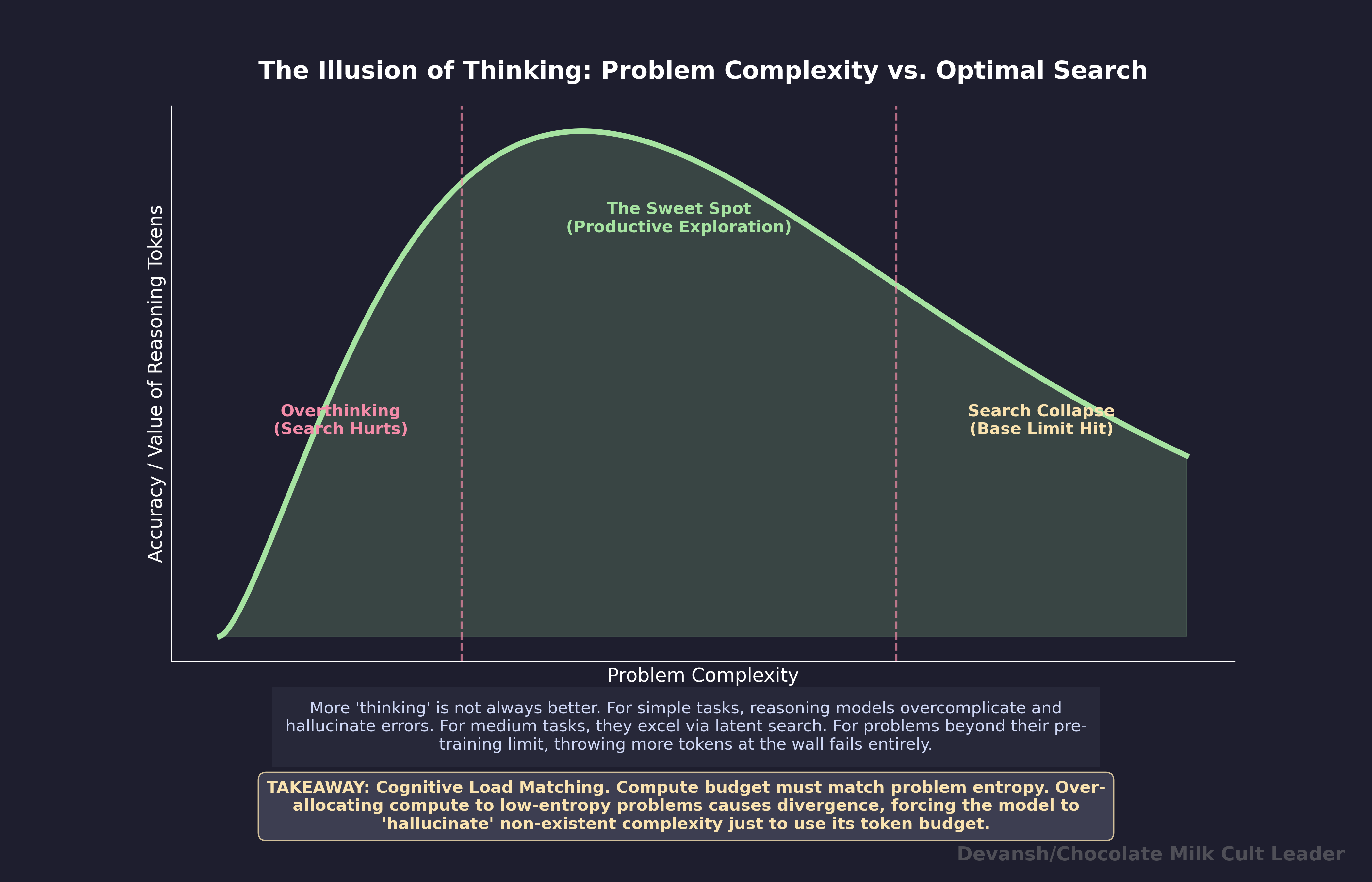
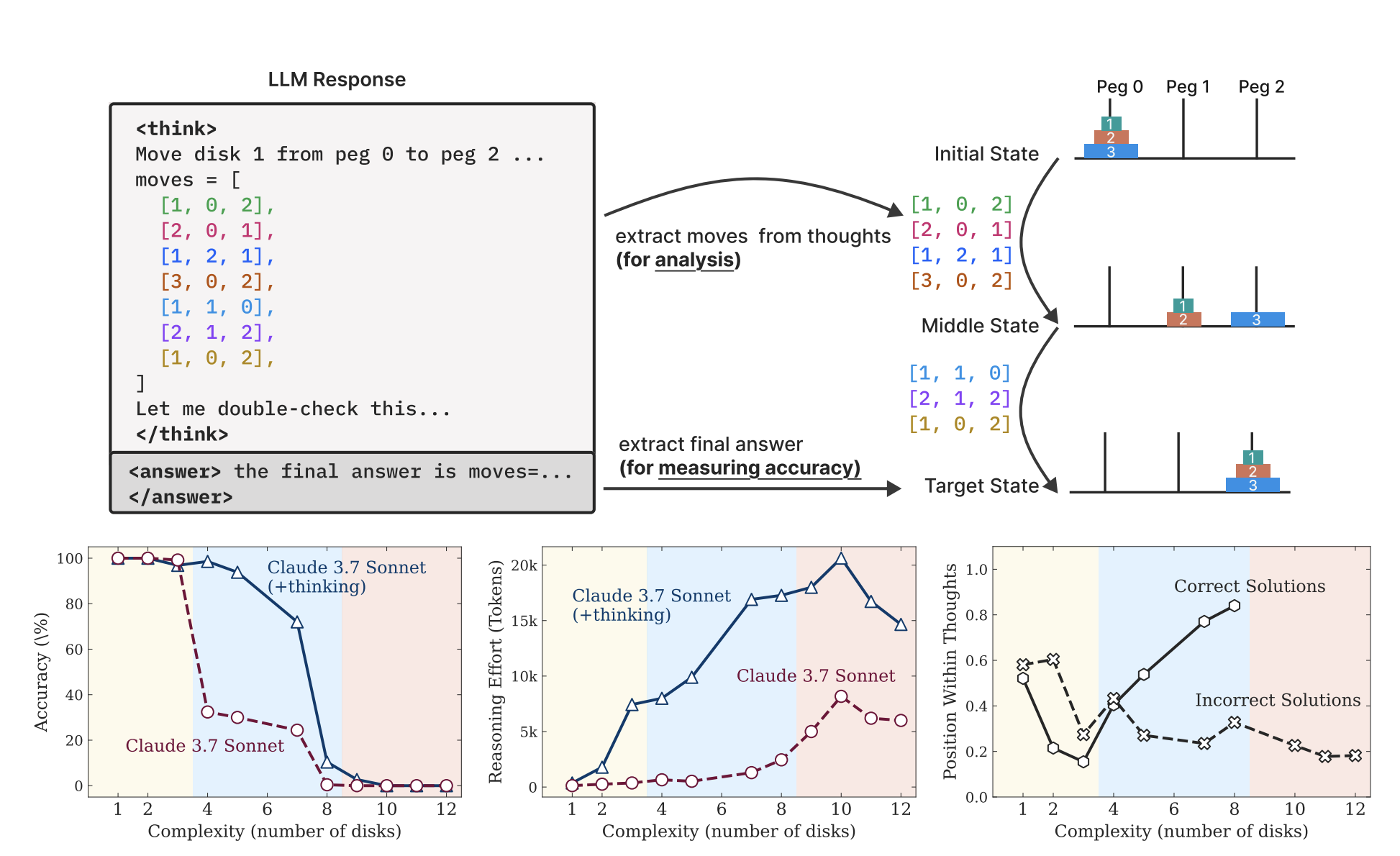
The relationship between search length and answer quality follows an inverted-U. Apple’s ML research team documented this in “The Illusion of Thinking” (June 2025, later NeurIPS 2025), testing o3-mini, DeepSeek R1, and Claude 3.7 Sonnet on controllable puzzle environments at precisely calibrated difficulty levels. Their core finding:
“Frontier LRMs face a complete accuracy collapse beyond certain complexities. Moreover, they exhibit a counterintuitive scaling limit: their reasoning effort increases with problem complexity up to a point, then declines despite having an adequate token budget.”
Three regimes, mapped to the search mechanism:
Low complexity: search hurts. Standard models outperformed reasoning models on easy problems. The Apple team identified the mechanism — an “overthinking phenomenon”: In simpler problems, reasoning models often identify correct solutions early but inefficiently continue exploring incorrect alternatives.
The model finds the answer, then keeps searching past it and lands on something worse. “Mind Your Step” measured the damage: up to 36.3 percent accuracy drops on pattern recognition, visual recognition, and implicit statistical learning. Running a search on a pattern-match problem is shadowboxing before someone asks your name. You don’t get a better answer. You get slower, and you get confused.
When is this complexity threshold reached? The way I like to see it: If a sharp person could answer it from memory without scratch paper, reasoning mode is the wrong tool.
Medium complexity: the sweet spot. Multi-step math, complex debugging, strategic analysis weighing multiple factors — problems where exploring several approaches finds solutions a single pass would miss. This is where reasoning earns its keep. The latency tax pays off in accuracy, and a single well-prompted reasoning query that nails it is often cheaper than three failed attempts on a standard model, each burning tokens and developer time.
High complexity: the search collapses. Both model types hit a wall on the hardest problems. But here’s what’s counterintuitive — from the Apple paper:
Their reasoning effort increases with problem complexity up to a point, then declines despite having an adequate token budget.
As difficulty exceeded a critical threshold, reasoning models didn’t fail by trying harder. They gave up — generating fewer tokens, not more. The model returned a short, confident answer on a genuinely hard problem.
That’s dangerous because the output looks normal. Polished. Assured. You only notice if you check the work or notice the trace is suspiciously short for a hard question.
That’s search compression showing its ceiling. When the problem exceeds the base model’s training distribution, there’s nothing for the search to converge on. Decompose into sub-problems, reformulate the question, or use a more capable model. More search budget is not the answer.
Past the peak: the model starts sabotaging itself. On the right side of the inverted-U, the search keeps going past productive exploration. It revisits already-explored paths. Latches onto irrelevant details and amplifies them through repetition. Applies its “verification” pattern to a correct intermediate result and “verifies” itself into changing it to a wrong answer — because the verification pattern is a correlation-trained heuristic, not a logical check, and sometimes the heuristic misfires. The Apple team watched this happen in the traces: “Models latch onto a flawed early conclusion and then spend the remainder of their tokens reinforcing that initial error, unable to self-correct.”
The OptimalThinkingBench study quantified it: selecting outputs with lower overthinking scores improved performance by roughly 30 percent while cutting compute costs by 43 percent. The model’s best answers weren’t its longest.
And it gets worse. “Think Deep, Not Just Long” (February 2026) distinguished between tokens that actually advance the solution and filler — “Hmm,” “Wait,” “Let me reconsider,” “OK so...” The NoWait approach stripped filler from traces. Trace length dropped 27 to 51 percent. Accuracy didn’t move. Up to half the tokens in a reasoning trace are doing nothing.
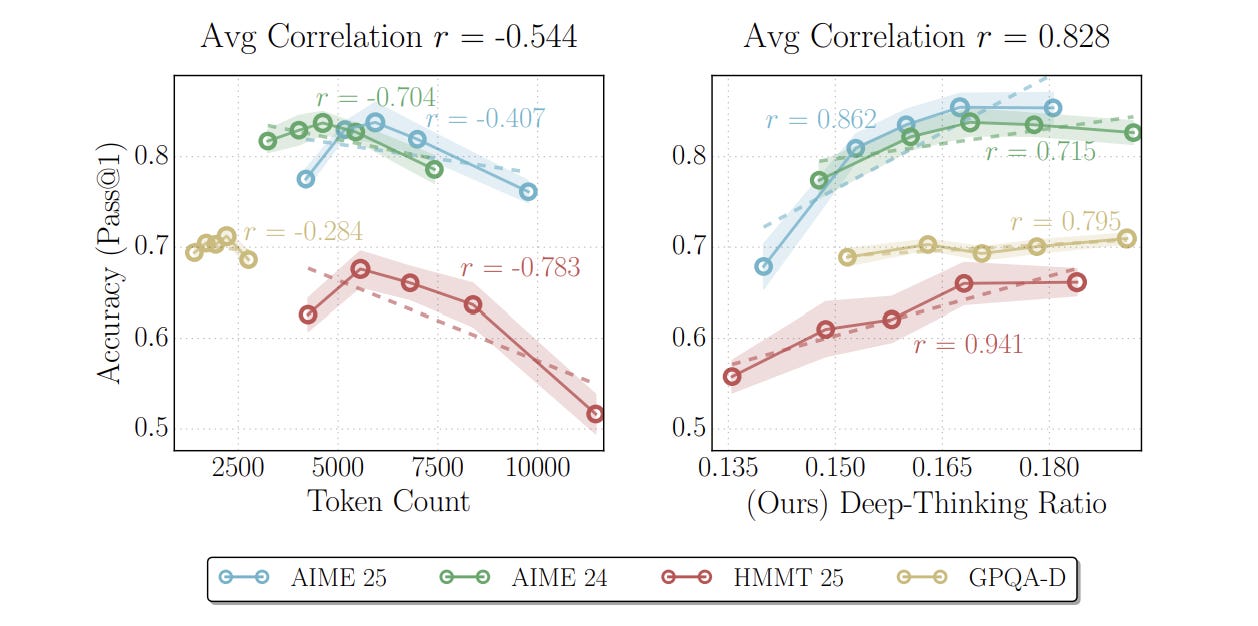
When you see a long trace, that length is not evidence of quality. When you feel a long delay, that delay is not evidence the model is working hard on your problem. The search might be productive. It might be spinning its wheels. You can’t tell from the outside without checking the answer.
Why Does Chain-of-Thought Backfire on Reasoning Models?
Chain-of-thought was a genuine breakthrough for standard LLMs. Wei et al. (NeurIPS 2022) showed it improved arithmetic accuracy by up to 18 percent. Kojima et al. showed that even “Let’s think step by step” — five words, no examples — boosted zero-shot performance on models above 100 billion parameters. The technique worked because it hacked the one-way bet limitation. Since the model can’t revise, forcing intermediate tokens gives it more steps to develop an answer before committing.
For reasoning models, the hack is redundant. The model already generates extended intermediate tokens. That is what reasoning mode is. When you add “think step by step” on top, you’re layering a generic template from pre-training over the specialized search strategies the model discovered through RL. The generic template restricts the search to patterns that look like human-written step-by-step reasoning, which is a subset of what the model found on its own.
The DeepSeek paper makes this explicit. Their design choice to skip supervised fine-tuning before RL came from a hypothesis they stated outright:
Human-defined reasoning patterns may limit model exploration, whereas unrestricted RL training can better incentivize the emergence of novel reasoning capabilities.
The evidence validated it — the model found strategies no human template would have generated, including the spontaneous self-correction they called the “aha moment.” When you add “think step by step,” you’re reimposing exactly the human-defined patterns that DeepSeek bypassed on purpose.
Why Do Few-Shot Examples Hurt Reasoning Models?
Same mechanism, different angle. When you give a reasoning model examples, it spends search tokens imitating your examples’ structure instead of running its own trained search. In-context pattern matching — the thing pre-training optimized for — overrides the RL-learned strategies. The model sees your format and tries to match it, which is exactly what you don’t want when the model has better strategies available.
OpenAI’s docs: “Reasoning models often don’t need few-shot examples to produce good results, so try to write prompts without examples first.” DeepSeek is blunter: few-shot examples “consistently degrade performance.” This aligns with their core finding — the whole point of R1-Zero was that the model discovers strategies human examples would have constrained.
One exception. Anthropic notes that examples with thinking-style patterns can shape the direction of Claude’s search — not whether it searches, but where. If you need reasoning in a specific direction for a specific domain, this can help. But try without examples first. Only add them if the output is missing something you can name.
What Does a Vague Prompt Actually Cost on a Reasoning Model?
On a standard model, a vague prompt gets you a vague answer. On a reasoning model, a vague prompt gets you a long, expensive, delayed answer — because the search dutifully explores every possible interpretation of your question before settling on one. You pay for the disambiguation in tokens, latency, and money.
Vague: “What do you think about our pricing strategy?”
The model explores: whose strategy? What product? What market? Qualitative or quantitative? Competitive or standalone? Hundreds of search tokens on disambiguation before any analysis begins.
Focused: “We sell a B2B analytics tool at $500/seat/year. Our top competitor just dropped to $350. Renewal rate is 87%. Should we match, and what’s the revenue impact if renewal drops to 80% without matching?”
This tightens the search space. Specific product, market, competitor action, metric, scenario. The token budget goes straight to the answer.
The DETAIL study (December 2025) confirmed this across 30 novel reasoning tasks: specificity improved accuracy, with the strongest effects on procedural tasks and on models with tighter token budgets. Every ambiguity in your prompt is search budget lit on fire.
What Is Cascade Failure, and Why Does It Cost More Than Any Other Reasoning Model Bug?
This is the failure mode that most prompting guides skip, probably b/c it has no equivalent in standard model prompting.
Standard model misunderstands your prompt? Short wrong answer. Easy to spot. Easy to fix.
Reasoning model misunderstands your prompt? Thousands of tokens get built on top of the misunderstanding. Every token is conditioned on every token before it. If token 200 latches onto a wrong interpretation — reads “evaluate” as “summarize,” misses a constraint buried in paragraph three, treats a hypothetical as a premise — tokens 201 through 12,000 build on that interpretation. Each one reinforces it. The model doesn’t re-read your prompt midway through and catch the drift. It follows the path because each token on that path makes the next token on that path more probable.

The Apple paper’s trace analysis confirms the mechanism. They found that once models lock onto a wrong path, the self-correction patterns from RL training don’t fire: “Models latch onto a flawed early conclusion and then spend the remainder of their tokens reinforcing that initial error, unable to self-correct.”
The model’s self-correction works when it’s exploring multiple paths and one path fails. It doesn’t work when the model never recognizes the initial interpretation was wrong in the first place.
In production, this is the most expensive failure mode. A short, wrong answer from a standard model is a clearer red flag. A twelve-thousand-token confident analysis built on a misread constraint looks right until a domain expert spends twenty minutes checking the work. Multiply that by the queries hitting your system daily.
We must avoid this through the following:
Front-load the critical constraint. The prompt’s beginning shapes the entire search trajectory. Critical information buried in paragraph three of a long prompt may be gone from effective context after thousands of intermediate tokens have established a direction.
Decompose entangled requirements. Deep analysis AND specific formatting AND compliance with five constraints in a single pass? That’s five dimensions for the search to navigate, and five chances for the search to take a wrong turn early. Get the analysis right first. Format it second. This isn’t a workaround — it’s an acknowledgment that one well-defined problem beats five entangled ones.
Don’t try to fix a derailed conversation mid-thread. If the model built 12,000 tokens in the wrong direction, adding corrections on top usually makes it worse. The model tries to reconcile your correction with its existing output and creates new conflicts. Start over with a cleaner prompt. The cost of a new conversation is lower than the cost of arguing with a search that’s already committed.
Why Do Reasoning Models Break Format Requirements?
RL rewarded correct answers. Not correctly formatted answers. Under heavy search load — the model working hard on a genuinely difficult problem — correctness wins and format loses. You ask for JSON, get a wall of text with the right analysis. Ask for a table, get a paragraph.
There’s a two-step fix: get the analysis from a reasoning model in free-form text. Let the search focus entirely on the problem. Then pass the output to a standard model: “Convert this analysis into this JSON schema.” The reasoning work is done. Let a model that wasn’t trained to deprioritize format handle the structure. Faster, cheaper, and more reliable format compliance.
Or: state the format constraint as the first thing in the prompt so it shapes the search from the start. This helps but doesn’t fully solve it. Expect less format reliability from reasoning models than standard models, especially on hard problems.
Thank you for being here, and I hope you have a wonderful day.
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. :
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819