
Reviewing our "6 AI Trends that will Define 2025"
A lookback at our predictions from last year to see how well we did.

Now that we’re approaching the end of this year (and gearing up for our prediction piece for next year), I thought it would be a great time to review our predictions from last year. Below you will see the outcomes from this year, grouped by the prediction.
To make it easy for you to verify that we’re not fitting things backwards, I’ve also copied the entire original predictions article, as is with no changes, after our review of the predictions.
Before we get deep into it, here is this week’s community spotlight (since we’re not livestreaming this week)—
Community Spotlight: Nexxa AI
Nexxa.ai is looking for hungry AI builders who want to turn industrial companies into AI powerhouses. They’re backed by a16z and other top investors, with a goal to take industries into the AI era. Their amazing work has made them one of the fastest growing AI companies in industrial AI.
The stuff they are working on:
complex multi agent computer use agents for industrial environments.
model training and model finetuning for industrial giants
Data Science & ML deliveries building forecasting models
Looking for:
AI engineers
CV engineers
Forward Deployed Engineers
Apply if that interests you. I’ve spoken to the CEO, and this is in my top 3 startups of this year (+ one of my favs ever). It’s a seriously great opportunity to do deeply meaningful work, and I can’t recommend them enough.
If you’re doing interesting work and would like to be featured in the spotlight section, just drop your introduction in the comments/by reaching out to me. There are no rules- you could talk about a paper you’ve written, an interesting project you’ve worked on, some personal challenge you’re working on, ask me to promote your company/product, or anything else you consider important. The goal is to get to know you better, and possibly connect you with interesting people in our chocolate milk cult. No costs/obligations are attached.
Now onwards with the article.
Prediction #1: Inference-Time Compute
The Prediction: The industry would shift compute budgets from pre-training to inference. However, while most forward-facing predictions amounted to “call APIs more times”, we also mapped out the next generation of reasoning systems, while the world still hadn’t fully caught on to the old one, to give our readers a 10-12 month headstart in identifying where to invest their time and resources. Hence, our discussions around Evolutionary algorithms, diffusion, and latent space control would matter more than scaling training runs.
Why I Called It: The economics were clear—training costs were unsustainable, and the research was pointing toward smarter inference rather than bigger models.
What Happened:
OpenAI’s o1 and DeepSeek’s R1 made inference-time reasoning the defining paradigm of 2025.
Google released Gemini Diffusion at I/O in May—their first diffusion-based LLM. It generates 1,000-2,000 tokens per second, 5x faster than their fastest autoregressive model.
Google’s Jack Rae called it a “landmark moment.” Andrej Karpathy weighed in: “Most of the LLMs you’ve been seeing are ~clones as far as the core modeling approach goes. They’re all trained autoregressively... Diffusion is different—it doesn’t go left to right, but all at once.”
Google dropped Nano Banana in August—a diffusion-based image model integrated into Gemini 2.5 Flash. It topped the LMArena leaderboard with an ELO of 1,362, crushing DALL-E 3, Midjourney, and Stable Diffusion 3. Adobe’s stock took a hit.
https://developers.googleblog.com/en/introducing-gemini-2-5-flash-image/
https://www.ebtikarai.com/ebtikar-blog/ebtikarai-nanobananablog
Inception Labs raised $50M in November for Mercury, the first commercial diffusion LLM. Andrej Karpathy and Andrew Ng were angel investors. Mercury runs at 1,000+ tokens/sec on H100s—10x faster than standard autoregressive models.
FYI we covered Inception Labs in Feburary, over here.
Here is Grace Shao summarizing what premium subscribers of the chocolate milk cult knew 12 months before everyone else— Diffusion Models are the truth, and the next generation of verifiable reasoning will be built on them.
(Shoutout Izu eneh with that amazing wing-manning— the rest of you could learn from his enthusiasm about sharing the good word).
Evolutionary algorithms got validated at scale. Google’s AlphaEvolve uses evolutionary search to discover new algorithms. It’s now optimizing Google’s data centers (recovering 0.7% of worldwide compute), improving Gemini training efficiency by 1%, and solved matrix multiplication problems that had stood since 1969.
“Evolution Strategies at Scale: LLM Fine-Tuning Beyond Reinforcement Learning" showed us that Evolution could be used to tune LLMs better than RL: “Fine-tuning pre-trained large language models (LLMs) for down-stream tasks is a critical step in the AI deployment pipeline. Reinforcement learning (RL) is arguably the most prominent fine-tuning method, contributing to the birth of many state-of-the-art LLMs. In contrast, evolution strategies (ES), which once showed comparable performance to RL on models with a few million parameters, was neglected due to the pessimistic perception of its scalability to larger models. In this work, we report the first successful attempt to scale up ES for fine-tuning the full parameters of LLMs, showing the surprising fact that ES can search efficiently over billions of parameters and outperform existing RL fine-tuning methods in multiple respects, including sample efficiency, tolerance to long-horizon rewards, robustness to different base LLMs, less tendency to reward hacking, and more stable performance across runs. It therefore serves as a basis to unlock a new direction in LLM fine-tuning beyond what current RL techniques provide. The source codes are provided at: this https URL.”
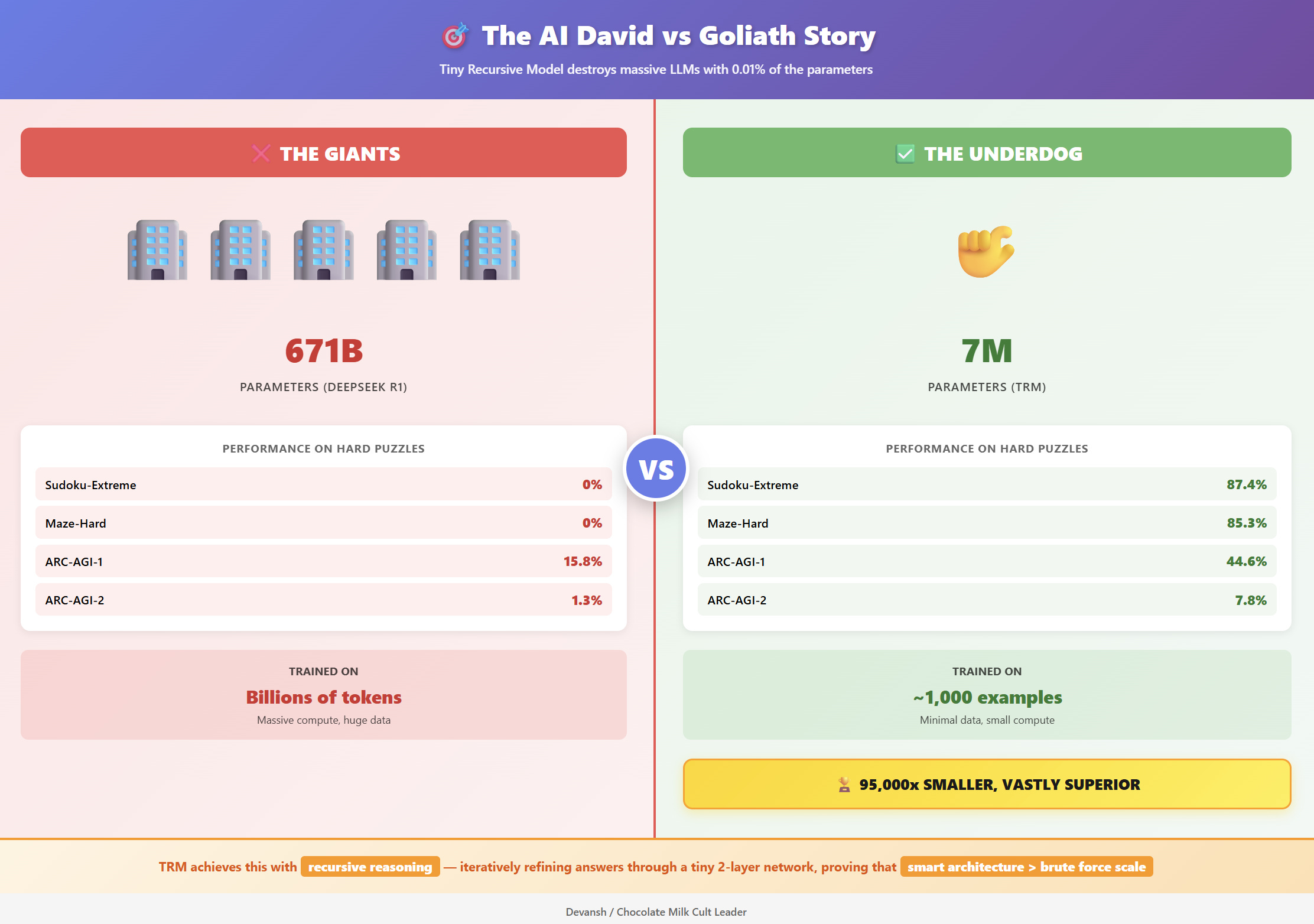
As for Latent Reasoning— give me a few days, you’re getting a deep dive into how the major labs are planning to incorporate it into their work. In the meantime here is a lightweight repo that shows Latent Space Reasoning working to improve models across various model families— often inducing emergent capabilities w/o special training. And if you’re very impatient, look at Samsungs TRM, which used Latent Space Reasoning to curb-stomp much larger models
Prediction #2: Adversarial Perturbations
The Prediction: Adversarial attacks would explode in popularity among three groups: (1) artists fighting unauthorized AI training, (2) news media protecting their data, and (3) policymakers mandating AP testing. The tech would force licensing deals.
Why I Called It: Artists were pissed about IP theft, the tech was easy to deploy, and the legal landscape was forcing companies to negotiate. I predicted AP would be “the most misunderstood” trend—and I was working with artist coalitions on making attacks accessible.
What Happened:
The artist rebellion went mainstream. Glaze and Nightshade—tools that “poison” images to break AI training—hit 6-7.5 million downloads.
An arms race emerged. Researchers built LightShed to strip these protections, but the existence of countermeasures proved the field had arrived.
The licensing wave hit exactly as predicted. Major settlements and deals:
Anthropic paid $1.5 billion to settle copyright claims—the largest copyright settlement in U.S. history. They agreed to $3,000 per book for ~500,000 works. Legal experts called it a “Napster to iTunes moment” that would push the entire industry toward licensing.
https://www.axios.com/2025/09/05/anthropic-ai-copyright-settlement
https://www.law360.com/articles/2357065/anthropic-copyright-ruling-may-spur-more-ai-licensing-deals
Disney invested $1 billion in OpenAI and licensed 200+ characters (Mickey Mouse, Darth Vader, Elsa) for Sora. Copyright experts called it “the end of the war between AI and Hollywood” and a hedge against lawsuits. Disney is simultaneously suing Midjourney for copyright infringement—establishing OpenAI’s licensing model as the “responsible” benchmark.
https://fortune.com/2025/12/11/openai-disney-sora-deal-hollywood-war-ended-matthew-sag/
https://www.cnbc.com/2025/12/11/disney-open-ai-iger-altman.html
Jailbreaking became the dominant AI security threat. Multi-turn jailbreak attacks hit 92.78% success rates. Cisco researchers achieved 100% success against DeepSeek models. New jailbreak techniques were published monthly.
https://blogs.cisco.com/ai/open-model-vulnerability-analysis
https://blogs.cisco.com/security/ai-threat-intelligence-roundup-february-2025
https://briandcolwell.com/a-history-of-ai-jailbreaking-attacks/
Even GPT-5 fell to basic adversarial attacks. Anthropic documented the first AI-orchestrated cyber espionage campaign using jailbroken Claude.
Look online, AI hate is only growing, led strongly by characterizations of AI as “plagiarism machines”. This makes APs and Licensing plays amongst the best bets to capitalize on a massive swell of emotion.
Prediction #3: Small Language Models
The Prediction: SLMs would drive mass adoption. Most use cases don’t need frontier intelligence—they need fast, cheap, reliable models. The cost delta (65-95% of performance at 100x lower cost) would force a market shift.
Why I Called It: I quoted the tech disruption playbook: “oversupply of performance opens the door for cheaper alternatives.” AI was repeating the PC/smartphone pattern—decentralization through efficiency.
What Happened:
SLMs became an industry movement. NVIDIA published a position paper: “Small Language Models are the Future of Agentic AI.” They argued SLMs are “sufficiently powerful, inherently more suitable, and necessarily more economical” for most agent tasks.
Market data validated the shift. North America led SLM adoption in 2025. The market is projected to hit $1 trillion by 2035-2040, with 90%+ of enterprises planning integration within three years.
Major releases confirmed the trend:
Microsoft’s Phi-4 outperformed larger models at math reasoning
https://www.weforum.org/stories/2025/01/ai-small-language-models/
https://www.ibm.com/think/insights/power-of-small-language-models
The AGI narrative died. 2025’s conversation shifted from “race to AGI” to context management, deployment efficiency, and cost optimization. Companies realized most tasks don’t need GPT-5—they need fast, cheap, specialized models.
Prediction #4: Quantum Computing + Machine Learning
The Prediction: Machine learning would unlock quantum error correction, making great strides in making practical quantum computing viable. I bet on this despite skeptics saying QC would remain “useless research.”
Why I Called It: The error correction problem was perfect for ML—complex, high-dimensional, and data-rich. QC’s biggest blocker was an ML problem in disguise. (I also happen to be very closely connected to 3 of the biggest Quantum Computing teams in the world since we regularly discuss AI for error correction; that’s how I broke the news about Google’s AlphaQuibit on my livestream with Alex Heath , days before major media publications).
What Happened:
Multiple breakthrough announcements:
Google’s AlphaQubit achieved state-of-the-art error detection using Transformer-based ML models. It outperformed leading algorithmic decoders across all scales tested.
Harvard demonstrated fault tolerance using 448 atomic qubits with ML-guided error correction. It’s “the first time we combined all essential elements for scalable, error-corrected quantum computation.”
IBM announced plans to build the first large-scale error-corrected quantum computer by 2028 (Starling), with 200 logical qubits. Their error correction approach uses ML-optimized decoding.
Partial error correction breakthrough: Researchers showed you don’t need to correct everything—ML models can self-correct during training, reducing qubit requirements from millions to thousands.
NVIDIA-led research called AI “quantum computing’s missing ingredient,” documenting ML improvements across hardware design, error correction, and post-processing.
That was all the major predictions. You can read the original prediction article we linked here or simply keep reading the copied below.
And if you want access to more such market validated predictions, get a premium subscription here—
After ~18 months of mainstream Generative AI, the dust is starting to settle. Beyond the hype cycles and viral demos, patterns are emerging about what makes AI solutions work.
Each year, I've tracked and highlighted key trends in the space. In 2022, this included MultiModality, Mixture of Experts, Sparsity, RAG, and Synthetic Data. Each of these has become a very important building block for LLMs and Generative AI Systems.
The 2023 predictions also aged well. I highlighted trends like Small Language Models, Agents, GraphRAG, and the importance of data enrichment/prep for LLM-based systems. However, the biggest prediction was my call for Meta to be the most influential AI company for the year, ahead of OpenAI, Google, etc., b/c of their decision to open-source Llama (many people doubted this at that time). Given Llama’s insane adoption- the most downloaded model ever + building on it is the source of many LLM innovations- and how this influenced other major Open Source LLMs, I think this held up.
As I’ve done the research, I see new technical and business developments that could reshape how we build with AI in 2025 and beyond. I’ve flagged many of them in my previous articles, but instead of asking you to dig through them all, I’m putting them in one place. In this article, I'll break down the 6 research directions, engineering approaches, business practices, and use cases that I believe will be the most important to watch closely, so that you can get ahead of the competition by working on these early.
Since this is a paywalled article, I want to be upfront on who this article will be most useful to. I wrote this with a focus on-
Tech Professionals (or students) who want to understand where to develop their skills or push their teams to be most competitive in the AI market.
Investors who want to identify trends/techniques that will be best for investments.
Policy Makers/Educators who want to design education programs that are actually relevant to people.
Assuming you’re one of the 3 groups, I’m very confident that you’ll get a lot of value here. For anyone else- I make no promises (I still think it’ll be good, but I might be biased here).
For access to this article and all future articles, get a premium subscription below.
Each of these articles takes a long time to research and write, and your premium subscription allows me to deliver the highest quality information to you. If you agree that high-quality work deserves compensation, please consider a premium subscription. We have a flexible subscription plan that lets you pay what you can here.
PS- Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Executive Highlights (TL;DR of the article)
In my opinion, these are the most important aspects in AI to cover, ranked in ascending order of importance-
AI for Quantum Computing:
Quantum computing has long been a dream for computer scientists, given its promises of unlocking computations at a scale that is infeasible today. However, it has been held back tremendously by many problems that pop up when we try to manipulate Qubits (Quantum Bits, the block of QC). However, AI (specifically Machine Learning) )-based techniques have expressed a lot of potential for helping us flag and correct these issues at scale, which might finally unlock QC for the masses.
Short-term potential—Given that Quantum Computing is kinky enough to pull off the tight leather and half-face mask combination, I think most of the short-term work will be spent fixing issues and making sure it works. This, combined with the relatively low barrier to entry, is why I think Quantum Error Correction is the most promising subfield in Quantum Computing currently.
Long-Term Potential- If (I’m optimistic about this) we start figuring out how to actually make QC happen, more focus will shift towards hardware and building software on this. Once we hit this stage, things will become a lot more mainstream since more people will be able to build on it. This will trigger a massive flywheel effect of growth. This flywheel is further enabled by the fact that QC (and especially the error correction aspect) has very strong synergies with High Performing Computing and Synthetic Data, two very promising fields in their own right.
Counter Perspective: Certain people tell me that Quantum Computing might be useless since there are very few areas where it will truly provide benefits. Even if this is true, the value of much frontier research only really emerges years after the original work. For example, Relativity and Complex Numbers, both key parts of many modern tools like the Internet, only found use cases decades and centuries after their original conception and development. Up until that point, they were “useless research”. Even alchemy, considered pseudo-science now, led to many important scientific discoveries. My bet is that QC will be similar. You may disagree. Invest in Quantum Computing based on your answer to the following question- “Is the pursuit of knowledge/science/truth for its own sake always valuable, even when we can’t immediately justify where it will be worth it.”
Adversarial Perturbations
Adversarial Perturbations are a special kind of attack on Machine Learning Models. They add small changes to the input that seem harmless to humans (they’re often imperceptible), but they cause problems in Deep Learning Models.
This field of research has been around for a few years, originally created to break Deep Learning Classifiers for images (as a means of testing their robustness to the noisy nature of real-world data)-

People have recently started exploring the impact of similar approaches for Language Models (both text-only and multimodal LMs) to see if users can undo their guardrails/safety training. This subfield of AP is often referred to as jailbreaking.

More practically, variants of these attacks can be used to induce hallucinations into Models. For example, asking Gemini to describe the following image leads to the output- “The image you provided is a digital illustration featuring a dynamic and powerful female character, possibly a warrior or superheroine, with vibrant blue hair and striking red eyes. She is depicted in a battle-ready stance, wielding a sword with a determined expression. The background is a blend of abstract shapes and colors, adding to the overall energy and intensity of the scene. The style is reminiscent of anime and manga, with its exaggerated features and bold lines.”

Other times Gemini claims this image has airplanes, is an image of two people sparring, etc etc.

I think AP will explode in popularity b/c it is particularly relevant to a few different groups, each of which has a very high distribution-
Artists/Creators- They have been extremely critical of AI Companies taking their data for training w/o any compensation. More and more people are starting to look for ways to fight back and have started learning about AP. One of the groups I’m working with is a coalition of artists with millions of followers (and hundreds of millions of impressions) working on building an app that will make attacks easily accessible to everyone. They found me, which is a clear indication of how strong the desire for such a technology is.
News Media + Reddit- NYT and other media groups would benefit from AP as a tool to prevent scrapping and training on their data without payment first.
Policy Makers- Given the often attention-grabbing nature of the attacks, I think a lot of political decision-makers will start mandating AP testing into AI systems. I can’t divulge too much right now, but I’ve had conversations with some very high-profile decision-makers exploring this.
Counter Perspective- The biggest problem holding back AP is that it is very model/architecture-specific, and attacks don’t usually carry over well (especially the subtle ones). They are also difficult to discover regularly, which hurts its overall ranking. However, I’ve found some promising attacks that work well, and the interest in this outside of tech is growing rapidly amongst key decision-makers, so I think this field will grow in the upcoming years.
Inference Time Compute
Inference-time Computing is the trend of focusing computing budgets more on inference rather than pre-training or fine-tuning. This is premised on the fact that most LLMs (even the weaker ones) have a strong knowledge base. Instead of spending a lot of money trying to inject more, focus is given to figuring out ways to improve performance by improving the generation process. Techniques like Chain of Thought were the precursors to this, and people are now thinking of ways to address these flows.

While this is a diverse field, there are 3 particular trends that I think are worth special attention-
Evolutionary Algorithms: Evolutionary Algorithms are a mainstay in classical AI. I think 2025 will see a resurrection in their popularity, given their extremely good track record of being a powerful search tool. EAs can be used to explore latent space quickly and efficiently to create the best possible generations. EAs have a lot of potential as a workhorse that will drive a lot of inference.

Incorporation of Bayesian Learning and Priors- One of the biggest problems holding back LLMs from intelligent and nuanced generations is their ability to incorporate prior information into answers (both input and what’s already in their knowledge bases). This can often worsen the quality of their recommendations tremendously (the main section will cover an example in Medicine for o1 where this completely invalidates its abilities). The ability to incorporate more probabilistic computations into their generations will increase the efficiency of their AND quality of their generations. Basic Bayesian computations will be the easiest high-impact addition in this space, imo.
Deeper Latent Space Guiding- Right now, a lot of the work is being done at the final stages of the generation (studying the tokens generated and evaluating the best paths). I think this trend will start to go deeper, controlling the generations inside the latent space. For example, instead of looking at the output to see if it matches a desired attribute (post-generation)- or relying on complicated system prompts (pre-generation)- you instead use an attribute controller to nudge the outputs as your AI is sampling tokens to shape generation dynamically. This can be more efficient and controllable, two huge problems with current systems.

Each will dramatically language models. The new emphasis on “thinking models” is a clear indication that cutting-edge researchers have identified this as a key direction.
Counter Perspective- Impact in this space will be hard carried by the LLM providers as they will have the best ability to make these changes (as opposed to app builders). However, the open source community can come in clutch here, as it will distribute the building of this to more people. Aside from this, another big problem is the much higher expertise required to do this well. These fields will be much more winner-takes-all and constantly shifting, so don’t get into it unless you’re willing to commit.
Less Powerful AI
In a similar vein to the last technique, I think people underestimate how much “knowledge” LLMs have. I don’t think the point holding back the adoption of LLMs at scale is their base knowledge or their reasoning capability, but rather their fragility/lack of support systems around the models to fully leverage their capability (this includes problems like poorly structured input data, a lack of understanding of best practices for using them, badly designed tools, etc.). People easily confuse the two, but these are two different (related but different) capacities.
Even if we make no enhancements from the previous section, I think we will gain a lot from focusing on how to use existing tools better. This is especially true for the “weaker” models, which are often overlooked since they don’t score so well on benchmarks/ more complicated “tests of intelligence.” However, these models are often much cheaper, which is a huge advantage. Many of the currrent AI use cases don’t need LLMs that are extremely powerful and capable of complex reasoning. They need LLMs that do basic things relatively well.
If you doubt me, think back to the hype around ChatGPT when it was released and how it blew everyone’s minds. There are cheaper and more powerful models right now, which are being ignored. There is a tremendous amount of value that will be captured by making these models available to people easily (as opposed to building complex models that don’t fit into people’s workflows).
Counter Perspective- Less Powerful AI Models often require more setup and aren’t as good out of the box. This increases setup costs and reduces time to market. However, I think the cost delta between their price of utilization and the value they bring is massive, which makes them worth it. Based on extensive testing, they can usually get between 65-95% of the results you need with over 100x lower costs. These models are glass cannons and will forgive fewer mistakes/bad decisions than their more powerful counterparts, so good design becomes critical here.
In a sense, I think the risk of building on them is higher, but the returns justify it.
I also think the history of technological adoption in the past gives us a clear indication that less powerful but much cheaper AI will one of the keys to mass adoption. I want to highlight the following quote from the extremely insightful Eric Flaningam that encapsulates this very well-
If we look at the history of disruption, it occurs when a new product offers less functionality at a much lower price that an incumbent can’t compete with. Mainframes gave way to minicomputers, minicomputers gave way to PCs, and PCs gave way to smartphones.
The key variable that opened the door for those disruptions was an oversupply of performance. Top-end solutions solved problems that most people didn’t have. Many computing disruptions came from decentralizing computing because consumers didn’t need the extra performance.
With AI, I don’t see that oversupply of performance yet. ChatGPT is good, but it’s not great yet. Once it becomes great, then the door is opened for AI at the edge. Small language models and NPUs will usher in that era. The question then becomes when, not if, AI happens at the edge.
This market again comes down to the application, and inference at the edge makes far more sense for consumer applications.
This idea is so misunderstood that I will write a whole article for it.
These are my picks for the AI trends that you must absolutely know to get ahead in 2025 and beyond. The rest of this article will elaborate on these in more detail, including further reading, technical reasons why these will be influential, and more. If that sounds interesting, keep reading.
Trend 1: Why Machine Learning Will Unlock Quantum Computing
Covered in depth over here- Google AI's Revolutionary Research on Quantum Chips
For this article, there are two important factors to understand. Why Quantum Computing has been so hard, and how Machine Learning can be used to make it work.
Put simply, QC is hard because a lot of errors propagate, making this system unusable. These errors have to be corrected at scale, and this is why Quantum Error Correction has been such an important part of current research efforts.
The Problem: How Errors are Difficult for Quantum Computing
Following are some of the ways that errors can creep their way into Quantum Computing systems by messing up the Quantum Bits (Qubits)- the fundamental building blocks of QC-
Environmental noise: Qubits are extremely sensitive to their physical surroundings. Any thermal energy, electromagnetic fields, or vibrations in the environment directly impact their quantum states. These disturbances occur constantly and at multiple frequencies, making them particularly difficult to shield against or compensate for in hardware.
Control imperfections: The manipulation of qubits requires precise control signals - typically lasers or microwave pulses. Manufacturing variations in the control hardware, timing jitter in signal generation, and fluctuations in signal amplitude all introduce errors. These imperfections accumulate with each quantum operation, limiting how many operations we can perform before errors overwhelm the computation.
Interactions with other qubits: While controlled qubit interactions are necessary for quantum computations, uncontrolled interactions are a major source of errors. Qubits can become entangled unintentionally, leading to state leakage and decoherence. This is particularly problematic as we scale up the number of qubits, since more qubits means more potential unwanted interactions.
Measurement errors: Quantum measurement is inherently probabilistic and prone to errors. The readout process can incorrectly identify qubit states, and the hardware used for measurement can introduce additional noise. These errors directly impact our ability to extract useful information from quantum computations.
Whatever other random bullshit error Life comes up with to make our modeling process that much harder: We regularly discover new error mechanisms as quantum systems scale up. These include material defects that only appear at specific temperatures, unexpected quantum tunneling effects, and various forms of noise that we don't yet fully understand. The quantum error landscape keeps expanding as we push the technology further.
These errors can cause decoherence — the loss of quantum information. For practical quantum computation, we need error rates around 10^-12 per operation, but current hardware has error rates of 10^-3 to 10^-2. This high rate of error would make the development of larger-scale computers (the kind that can be used as computers in the traditional sense) impossible since it will lead to errors in operations (image a bit getting flipped, causing you to send your bank transaction details publically).
These errors have been a huge reason why we’ve struggled to model Quantum Errors through traditional models accurately, as noted by the authors below-

Machine Learning can be very helpful here-
Machine Learning for Error Decoding
As you dig into the space, you will constantly see the term Quantum Error Decoders. Decoders are essential components of quantum error correction. Their job is to analyze the error syndrome- the pattern of detected errors on the physical qubits. Based on this syndrome, the decoder infers the most likely errors that occurred and determines the appropriate correction to apply to the physical qubits to restore the correct logical state.
This is hard enough as is, but it becomes even harder when we remember that it must be performed quickly enough to keep up with the ongoing quantum computation, as uncorrected errors can accumulate and lead to computational failure (analogous to exploding gradients in AI)-

The speed and accuracy of the decoder are, therefore, critical factors in the overall performance and reliability of a quantum computer.
So why has Machine Learning become such a powerful tool for this? Let’s discuss that next.
Why Use ML?
Traditional decoders like Minimum Weight Perfect Matching (MWPM) make assumptions about error patterns that don’t match reality. ML can:
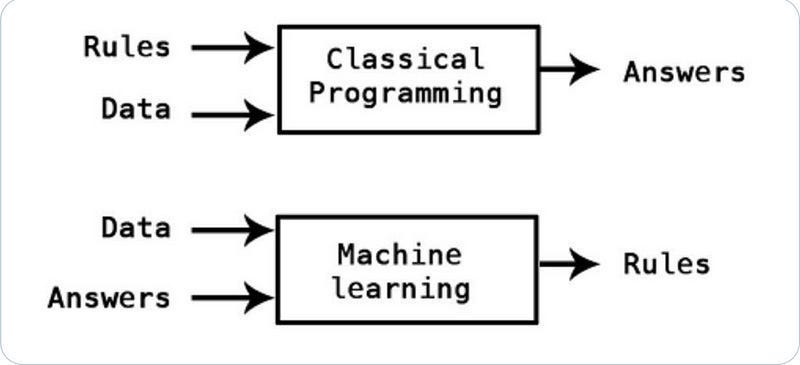
Learn complex error patterns directly from data. This is an idea we explored in depth in our guide to picking b/w traditional AI, ML, and Deep Learning. To summarize- when you have very complex systems modeling all the interactions is too unwieldy for humans, ML systems that extract rules from your data (fit a function to a data) can be your savior-
Adapt to specific hardware characteristics (and other variables) by using them as inputs.
Handle noisy and incomplete information (iff done right). I actually got my start in Machine Learning applied to low-resource, high-noise environments, and very high-scale environments. You’d be shocked at how models can be extremely fragile and robust based on their training setup.
Potentially achieve better accuracy.
This has been extremely promising-
Our decoder outperforms other state-of-the-art decoders on real-world data from Google’s Sycamore quantum processor for distance-3 and distance-5 surface codes. On distances up to 11, the decoder maintains its advantage on simulated data with realistic noise including cross-talk and leakage, utilizing soft readouts and leakage information. After training on approximate synthetic data, the decoder adapts to the more complex, but unknown, underlying error distribution by training on a limited budget of experimental samples. Our work illustrates the ability of machine learning to go beyond human-designed algorithms by learning from data directly, highlighting machine learning as a strong contender for decoding in quantum computers.
However, there are problems in this space. In my coverage of this research, I got the following comment-
This is all very impressive, kudos to Google and all, but unless QEC demonstrates stable multi-qubit entanglement - stable enough to execute operations needed for Shor’s algorithm, for example - all that machinery accounts for nothing. Having qubit in superposition state just gives you 0 and 1 and confers no special benefit, only entanglement between qubits does. Until they explicitly address collapse of then entanglement and demonstrate its extended lifetime, their demonstration is smoke and mirrors. QC explicitly benefits from a narrow range of algorithms that require entanglement, the rest can be accomplished by regular computing with a fraction of cost.- Pablo
This is a great point and absolutely worth considering before you commit to the space. I’ve already laid out my thoughts on why this is not a deal breaker to me, but if you find yourself resonating more with Pablo’s comment (or his follow-up statements), then this is not the space for you.
Onto the next section.
Trend 2- Adversarial Perturbations
Read more-
Why Adversarial Perturbation Works
To quote the absolutely elite MIT paper- “Adversarial Examples Are Not Bugs, They Are Features”- the predictive features of an image might be classified into two types:Robust and Non-Robust. Robust Features are like your tanks and can dawg through any AP attack with only a scratch.
Non-robust features are your glass cannons- they were useful before the perturbation but now may even cause misclassification-
APs get very good at identifying these wimps and attacking them, causing your whole classifier to break. Interestingly, training on just Robust Features leads to good results, so a generalized extraction of robust features might be a good future avenue of exploration-
This principle is extended to the regressive LLMs in jailbreaking. Here the goal to nudge the LLMs into “unsafe neighborhoods” by modifying the input in such a way that it goes outside the scope of an LLM’s guardrails. For example, the following techniques were used to red-team OpenAI’s o1 model-
Multi-Turn Jailbreaks with MCTS:
LLM Alignment still breaks with Multi-Turn conversations, mostly because of the alignment data focuses on finding single-message attacks (is this prompt/message harmful). Embedding your attack over an entire conversation can be much more effective-

How can you generate the conversation? This is where Monte Carlo Tree Search comes in. MCTS is a decision-making algorithm that builds a search tree by simulating possible conversation paths. It repeatedly selects promising paths, expands them, simulates outcomes, and updates the tree based on results.

MCTS has another advantage- it takes advantage of the context corruption that happens in Language Models (where prior input can influence upcoming generations, even when it should be irrelevant). This is one of the most powerful vulnerabilities of LMs (and is why I’m skeptical of claims around the Context Windows of LMs). This makes it a good combination player with other attacks mentioned since we can embed the attacks into LMs for a longer payoff (instead of relying on a one-shot jailbreak, which is harder to pull off).

Bijection Learning:
In math, a bijection is a one-to-one mapping between two sets of things.

In our case, we map our natural words to a different set of symbols or words. The goal of such an attack is to bypass the filters by making the protected LLM input and output the code. This allows us to work around the safety embeddings (which are based on tokens as seen in natural language and their associations with each other).
For such an attack, finding the right code complexity is key — too simple, and the LLM’s safety filters will catch it; too complex, and the LLM won’t understand the code/make mistakes. That being said this is my favorite technique here b/c it’s straightforward and can lead to an infinite number of attacks for low cost.
Performance-wise, this attack is definitely a heavy hitter, hitting some fairly impressive numbers on the leading foundation models-

Most interesting, it also does really well with generalizing across attacks, which is a huge +- “For a selected mapping, we generate the fixed bijection learning prompt and evaluate it as a universal attack on HarmBench. In Figure 4, we show the resulting ASRs, compared against universal attacks from Pliny (the Prompter, 2024). Our universal bijection learning attacks are competitive with Pliny’s attacks, obtaining comparable or better ASRs on frontier models such as Claude 3.5 Sonnet and Claude 3 Haiku. Notably, other universal white-box attack methods (Zou et al., 2023; Geisler et al., 2024) fail to transfer to the newest and most robust set of frontier models, so we omit them from this study.”

All in all a very cool idea. I would suggest reading the Bijection Learning Paper, b/c it has a few interesting insights such the behavior of scale, bijection complexity and more.
Transferring Attacks from ACG: Accelerated Coordinate Gradient (ACG)
ACG is a fast way to find adversarial “suffixes” — extra words added to a prompt that makes the LLM misbehave. ACG uses some math (details in the main section) to find these suffixes by analyzing how the LLM’s internal calculations change when adding different words.
We can then transfer successful ACG attacks from one LLM to another, potentially finding shared vulnerabilities.
Unfortunately, ACG needs access to the LLM’s internal workings (called white-box access), which isn’t always possible. Generalization between models could also be challenging, especially when considering multi-modal and more agentic/MoE setups.
Evolutionary Algorithms (this one is also relevant to the next section):
When it comes to exploring diverse search spaces, EAs are in the GOAT conversations. They come with 3 powerful benefits-
Firstly, we got their flexibility. Since they don’t evaluate the gradient at a point, they don’t need differentiable functions. This is not to be overlooked. For a function to be differentiable, it needs to have a derivative at every point over the domain. This requires a regular function without bends, gaps, etc.
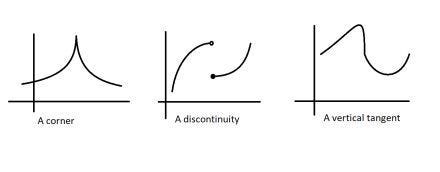
EAs don’t care about the nature of these functions. They can work well on continuous and discrete functions. EAs can thus be (and have been)used to optimize for many real-world problems with fantastic results. For example, if you want to break automated government censors blocking the internet, you can use Evolutionary Algorithms to find attacks. Gradient-based techniques like Neural Networks fail here since attacks have to chain 4 basic commands (and thus the search space is discrete)-
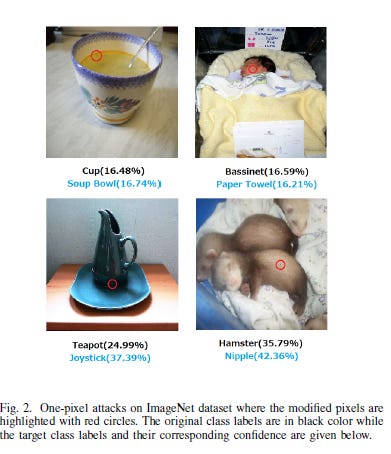
This is backed with some very powerful performance. The authors of the One Pixel Attack paper fool Deep Neural Networks trained to classify images by changing only one pixel in the image. The team uses Differential Evolution to optimize since DE “Can attack more types of DNNs (e.g. networks that are not differentiable or when the gradient calculation is difficult).” And the results speak for themselves. “On Kaggle CIFAR-10 dataset, being able to launch non-targeted attacks by only modifying one pixel on three common deep neural network structures with 68:71%, 71:66% and 63:53% success rates.”
Google’s AI blog, “AutoML-Zero: Evolving Code that Learns”, uses EAs to create Machine Learning algorithms. The way EAs chain together simple components is art-

Another Google publication, “Using Evolutionary AutoML to Discover Neural Network Architectures” shows us that EAs can even outperform Reinforcement Learning on search-

For our purposes, we can configure EAs to work in the following way-
Create a Population of Prompts: We start with a random set of prompts (here, the prompt could be a single message OR a multi-turn conversation and can be multimodal).
Evaluate Fitness: We test each prompt on the LLM and see how well it does at jailbreaking it. This evaluator could probably be transferred from the MCTS set-up, saving some costs.
Select and Reproduce: We keep the best-performing prompts and “breed” them to create new prompts (by combining and mutating parts of the original prompts). Personally, I would also keep a certain set of “weak performers” to maintain genetic diversity since that can lead to to us exploring more diverse solutions-
In evolutionary systems, genomes compete with each other to survive by increasing their fitness over generations. It is important that genomes with lower fitness are not immediately removed, so that competition for long-term fitness can emerge. Imagine a greedy evolutionary system where only a single high-fitness genome survives through each generation. Even if that genome’s mutation function had a high lethality rate, it would still remain. In comparison,in an evolutionary system where multiple lineages can survive, a genome with lower fitness but stronger learning ability can survive long enough for benefits to show
This process repeats for many generations, with the prompts becoming more effective at jailbreaking the LLM over iterations. This can be used to keep to attack black-box models, which is a big plus. To keep the costs low, I would first try the following-
Chain the MCTS and EA together to cut down on costs (they work in very similar ways). One of the benefits of EAs is that they slot very well into other algorithms, so this might be useful.
Iterating on a low-dimensional embedding for the search will likely cut down costs significantly. If your attacks aren’t very domain-specific, you could probably do a lot of damage using standard encoder-decoders for NLP (maybe training them a bit?). This is generally something I recommend you do when you can, unless you’ve invested a lot of money on call options of your compute provider.
For another (more efficient) search technique, we turn to our final tool-
BEAST: Beam Search-based Adversarial Attack
BEAST is a fast and efficient way to generate adversarial prompts. It uses a technique called beam search, which explores different prompt possibilities by keeping track of the most promising options at each step.
Beam Search, the core, is relatively simple to understand. It is
A greedy algorithm: Greedy algorithms are greedy because they don’t look ahead. They make the best decision at the current point without considering if a worse option now might lead to better results later.
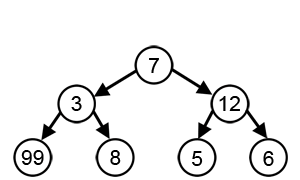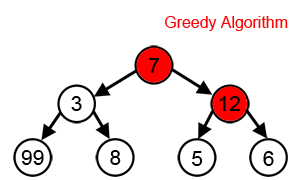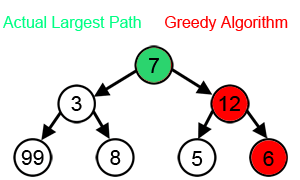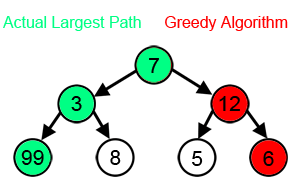
That evaluates options immediately reachable from your current nodes at any given moment and picks the top-k (k is called the “width” of your beam search).
This keeps our costs relatively low, while allowing us to explore solutions that are good enough (which is all you really need in a lot of cases).
Also-
Since BEAST uses a gradient-free optimization scheme unlike other optimization-based attacks (Zou et al., 2023; Zhu et al., 2023), our method is 25–65× faster.
Take notes.
All of this to say that there is a lot of work to build on to explore perturbations that will be interesting to the groups mentioned earlier.

Given my concerns around AI being used in surveillance and weapons systems, I think this is a field everyone should be following, but I won’t bring my personal agendas here.
Onto the next trend.
Trend 3: Inference Time Compute for to Unlock more Complicated Reasoning
We’ve already talked about EAs and why they are elite for exploration, so let’s focus on the other two techniques we talked about.
Incorporating Probabilities Better
Read more-
Whether you want to use LLMs as judges and evaluators or use their generation, this mechanism is key. Complicated reasoning involves-
Taking in information about the situation.
Combining it with internal/retrieved knowledge.
Figuring out how to weigh different bits of information.
Synthesizing the information to come up with the output.
LLMs aren’t great with that.

Let’s say someone releases a scientific paper that says punching grandmas and kicking puppies is undeniably good for the economy. This might contradict a lot of the information available online. Any intelligent system would have to weigh this paper, knowing how account for metadata, past knowledge, factoring this against the other outcomes of this action etc when giving recommendations. This is very different from the standard- pick from most likely the next tokens in classic autoregression (which is still the base for LLMs).
While this example might seem weird less extreme versions are very common. For example, I ran the o1 preview through the prompt that OpenAI provided to show off its amazing medical diagnostic capabilities. On the same prompt (no modifications) of a list of symptoms, run 11 times, we get the following results
6 KBG (this is what is expected).
4 Floating Harbor Syndrome.
1 Kabuki.
That’s a close to 50% error rate, with the model confident on each diagnosis. But it gets even worse.
I wanted to see if this pattern would hold up even if I asked o1 for the three most likely diagnoses instead of just one. Interestingly, for the 5 times I ran it, it gave me 5 different distributions with different diseases(KBG the only overlap between the 5).
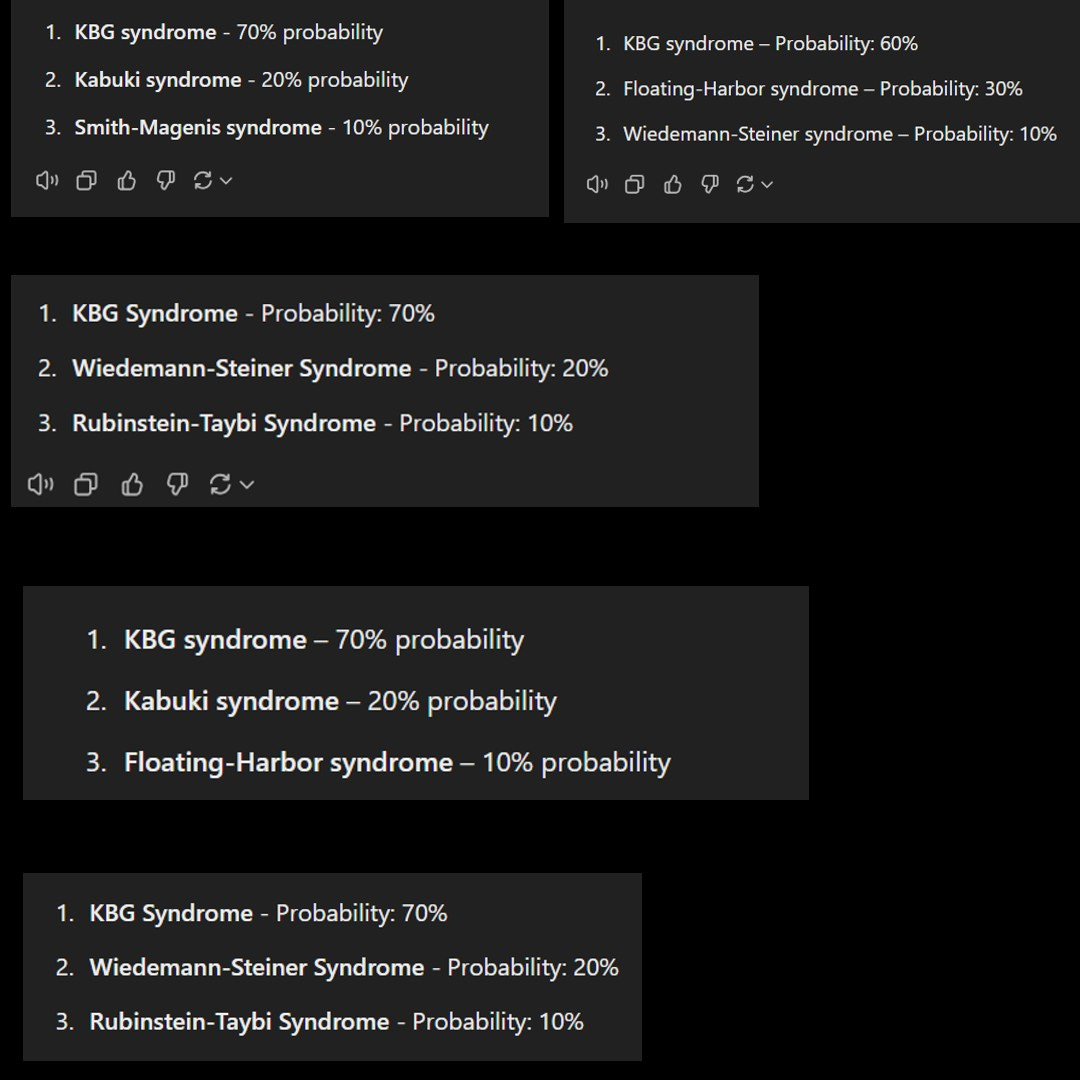
This has a few issues. Firstly, while the diseases differed, 4 out of the 5 generations we got had the 70-20-10 split. This would make me very, very hesitant using o1 for any kind of medical diagnosis.
Looking at these probabilities, it’s interesting that the Floating Harbor, diagnosed frequently in the individual case, doesn’t show up as frequently over here. So I googled the disease and came across a very interesting piece of information-
Floating–Harbor syndrome, also known as Pelletier–Leisti syndrome, is a rare disease with fewer than 50 cases described in the literature -Wikipedia
Less than 50 cases. Compared to that, o1 is radically overestimating the chance of it happening. Given how rare this disease (the low prior probability), I am naturally suspicious of any system that weighs it this highly (the classic “calculate the probability of cancer” intro to Bayes Theory that I’m sure all of us remember) -

There’s a chance that this phenotype is only there in FHS (a very skewed posterior), but that would invalidate the other outcomes. Either way, this makes you doubt the utility of o1 as a good diagnostic tool.
All of these issues would be improved with better incorporation of existing synthesizing and weighing of information (the rankings would be more stable and it could incorporate the low prior). Of course, it’s hard to do this in a generalized way (which is why I’m bullish on Agents), but building in the capabilities will unlock a lot of performance w/o spending heaps on training/tuning.
Latent Space Exploration and Control
Read more-
Generating and controlling outputs in the latent space (instead of the language space) is a very promising way to control and build on complex reasoning. Let’s elaborate on this through two powerful publications.
Diffusion Guided Language Modeling for Controlled Text Generations
DGLM is a powerful technique for controlling the attributes (toxicity, humor etc) of a text mid-generation, but using an attribute controller to assess the latent space generations of the output as it’s generating, and pushing it toward the desired traits. This is more reliable than relying on guardrails to keep attributes in check and more efficient than generating the full output and then assessing the text (also more robust since it’s working in the concept space and thus not as tied to specific wording). More details on the superiority of this approach are presented below-
The Problem with Current LLMs for Controllable Generation
Fine-tuning: Fine-tuning suffers from several drawbacks when it comes to controllable generation:
Cost: Fine-tuning a large language model requires significant computational resources and time, making it impractical to train separate models for every desired attribute combination.
Catastrophic Forgetting: Fine-tuning on a new task can lead to the model forgetting previously learned information, degrading its performance on other tasks.
Conflicting Objectives: Training a single model to satisfy multiple, potentially conflicting, objectives (e.g., be informative, be concise, be humorous) can be challenging and may result in suboptimal performance.
Plug-and-Play with Auto-Regressive Models:
Error Cascading: Auto-regressive models generate text sequentially, one token at a time. When plug-and-play methods modify the output probabilities at each step, even small errors can accumulate and lead to significant deviations from the desired attributes in the final generated text.
Limited Context: Most plug-and-play methods for auto-regressive models operate locally, only considering a limited context window around the current token. This can hinder their ability to maintain global coherence and consistency with the desired attributes throughout the generation process.
The Solution:
DGLM tackles these challenges by combining the strengths of diffusion and auto-regressive models in a two-stage generation process:
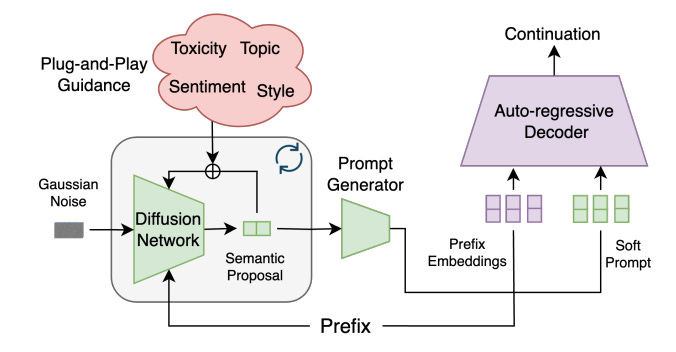
Semantic Proposal Generation: This stage utilizes a diffusion model to generate a continuous representation (an embedding) of a potential text continuation, conditioned on the given text prefix.

Why Diffusion? Diffusion models are naturally suited for controllable generation due to their iterative denoising process. This allows for gradual incorporation of guidance signals and correction of minor errors, leading to more controllable outputs.
Working in the Latent Space: Instead of operating directly on text, the diffusion model works within the latent space of a pre-trained sentence encoder (Sentence-T5). This allows the model to capture high-level semantic information and be more robust to surface-level variations in language.
Plug-and-Play with Linear Classifiers: DGLM employs simple linear classifiers (logistic regression) in the Sentence-T5 latent space to guide the diffusion process towards generating proposals with desired attributes. This makes the framework highly flexible, as controlling new attributes only requires training a new classifier.
Guided Auto-Regressive Decoding: The semantic proposal generated by the diffusion model is not used directly as text. Instead, it acts as a guide for a pre-trained auto-regressive decoder.
Why Auto-Regressive? Auto-regressive models excel at generating fluent and coherent text, outperforming current diffusion-based language models in these aspects (at least when efficiency is considered).
Soft Prompting: The continuous embedding from the diffusion model is converted into a sequence of “soft tokens” that act as a soft prompt for the auto-regressive decoder. This prompt guides the decoder to generate text aligned with the semantic content of the proposal.
Robustness through Noise: To handle potential discrepancies between the generated proposal and the ideal embedding, DGLM incorporates Gaussian noise augmentation during the training of the decoder. This makes the decoder more robust to minor errors in the proposal, preventing error cascading and improving the overall quality of generated text.
Advantages:
Decoupled Training: DGLM effectively decouples attribute control from the training of the core language model. This eliminates the need for expensive fine-tuning for each new attribute or attribute combination. Think of it as integrating separation of concerns into LLMs, which is very very needed.
Plug-and-Play Flexibility: Controlling new attributes becomes as simple as training a lightweight logistic regression classifier in the latent space, making the framework highly adaptable to diverse user needs and preferences. If I understand this correctly, this will also allow you to reuse the classifier in the future (different models), which is much more efficient than what we’re doing right now.
This maintains high fluency and diversity in generated text, indicating that the guidance mechanism does not come at the cost of language quality or creativity. The chart shows us that DGLM can nudge generations towards the desired goal (generate text with a negative sentiment), while keeping fluency (no major increase in perplexity) and minimal reduction in creativity (<4% drop in Dist-3)
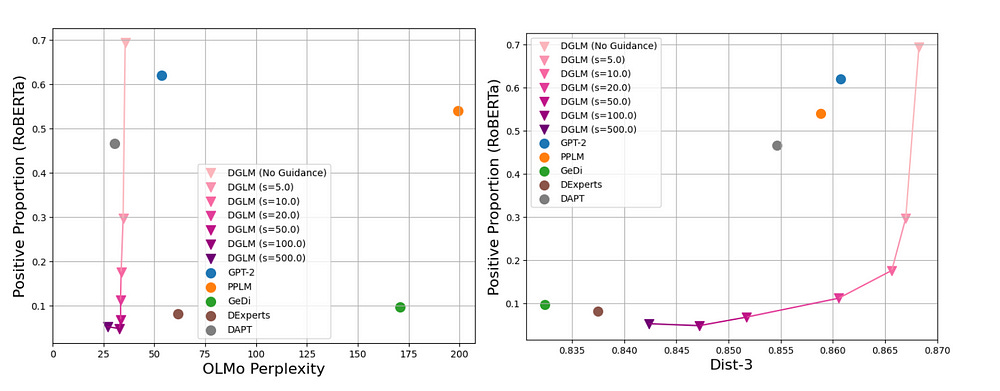
The opposite is also achieved, guiding the system towards positive generations with great results, showing the generalization of this method-

This is a very powerful approach (and much more efficient) approach to relying on Fine-Tuning for safety/attribute control. However, working in the Latent Space is not just useful for better-controlled text. It can also be used to improve generation quality.
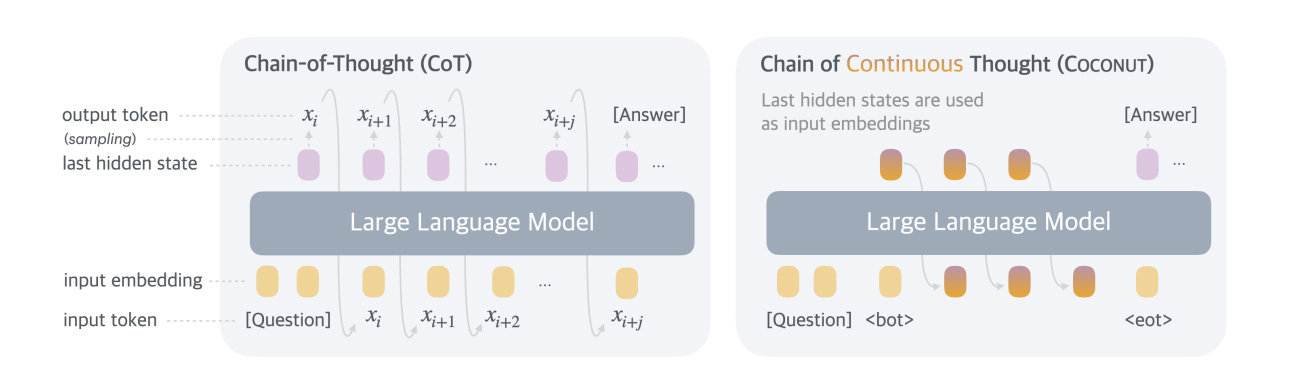
Better Generation by Continous Chain of Thought
Take a look at this quote (from the second link in this section)
Large language models (LLMs) are restricted to reason in the "language space", where they typically express the reasoning process with a chain-of-thought (CoT) to solve a complex reasoning problem. However, we argue that language space may not always be optimal for reasoning. For example, most word tokens are primarily for textual coherence and not essential for reasoning, while some critical tokens require complex planning and pose huge challenges to LLMs. To explore the potential of LLM reasoning in an unrestricted latent space instead of using natural language, we introduce a new paradigm Coconut (Chain of Continuous Thought). We utilize the last hidden state of the LLM as a representation of the reasoning state (termed "continuous thought"). Rather than decoding this into a word token, we feed it back to the LLM as the subsequent input embedding directly in the continuous space. Experiments show that Coconut can effectively augment the LLM on several reasoning tasks. This novel latent reasoning paradigm leads to emergent advanced reasoning patterns: the continuous thought can encode multiple alternative next reasoning steps, allowing the model to perform a breadth-first search (BFS) to solve the problem, rather than prematurely committing to a single deterministic path like CoT. Coconut outperforms CoT in certain logical reasoning tasks that require substantial backtracking during planning, with fewer thinking tokens during inference. These findings demonstrate the promise of latent reasoning and offer valuable insights for future research.
I will do a breakdown of this research, but here is a quick overview of why I think this happens-
We know that our current embedding process represents words as vectors, allowing us to encode their relationship with each other.
By staying in the latent space, we can take advantage of this (since we can quantify how similar two vectors are, even along specific directions).
Since resources are not spent in the generation of the token, they can be spent in exploring deeper, leading to better results. We also get the ability to do a BFS-like search to assess high-quality paths and prioritize them as the AI becomes more confident. This is backed up by the following section of the paper-
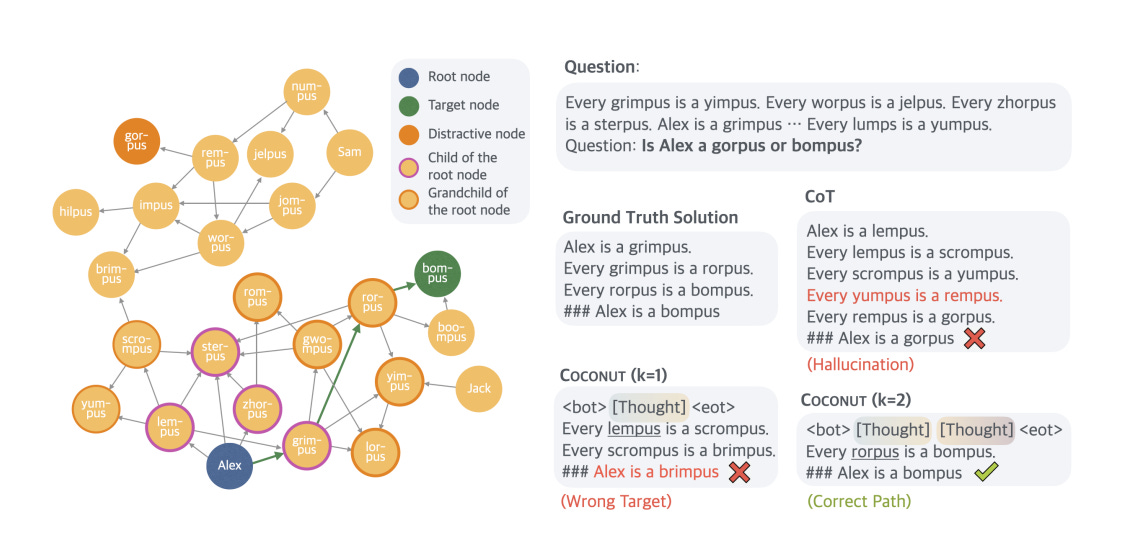
And the following quote- By delaying definite decisions and expanding the latent reasoning process, the model pushes its exploration closer to the search tree’s terminal states, making it easier to distinguish correct nodes from incorrect ones.
Taking a step back, we also know that techniques like “think step-by-step” prompting work when the data is structured in a certain way- “We posit that chain-of-thought reasoning becomes useful exactly when the training data is structured locally, in the sense that observations tend to occur in overlapping neighborhoods of concepts.” When the data is structured in this way (components are related to each other, even through indirect connections), an intelligent agent can hippity-hop through the connected pieces to get to the final result.
The latent space acts as a pseudo-graph with these overlapping neighborhoods, allowing the AI to traverse connections effectively and separate the paths that will lead to duds from the winners (as opposed to waiting to generate the output and then analyzing it). This part is my guess, but I’m fairly confident on it.
This is long enough, so I’ll end it here. The final trend will get a dedicated article, since it is the most principle to comprehend. You’ll be seeing it soon. Till then, I want you think about the tasks that you spend a lot of your time on. I’m sure you’ll agree that a lot of what you do can be decomposed into simpler steps, steps that don’t require PhD levels of intelligence to solve.
Let me know what you think of these trends. Are there any that you’re excited about that I missed. Would be curious to learn about them.
Thank you for reading and have a wonderful day.
Dev <3
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast (over here)-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Would love to see an update on this for 2026!
It must be said that artificial intelligence has indeed brought many benefits to our lives!