
Stateful Swarms make AI 100x More Intelligent per Dollar
How Irys beat Harvey AI on the Legal Agent Benchmark (1.7x performance with 39x lower cost)

Agentic AI systems consistently fail at managing persistent memory and structured understanding. Most existing setups reread entire documents repeatedly, lose critical details through summarization, and incur significant computational costs due to inefficient context management. Current solutions, like larger models or expanding context windows, offer superficial improvements without addressing the core architectural limitations.
Stateful Swarms tackle this directly. Instead of relying on volatile inference windows or endless reprocessing loops, this framework coordinates multiple specialized agents through a persistent blackboard state. Each agent performs a targeted task and updates a structured, auditable memory. This persistent state accumulation means expensive processing is done once, after which systems can cheaply update, query, and reason over the structured knowledge indefinitely.
We validated this by running Stateful Swarms against the complete 1,251-task Harvey Legal Agent Benchmark, achieving an 83.74% pooled criteria pass rate, a 17.75% strict all-pass rate, at $1.30 per task. Critically, these results came from structural coordination improvements rather than raw model scaling or specialized engineering (all details, including code and experiment details, published here).

In this deep dive we will cover:
Why long-context inference is fundamentally limited
How standard agentic systems repeatedly waste resources
What are Stateful Swarms and their structural advantages for agentic reasoning tasks
Detailed results from our evaluation against Harvey LAB
The essential role of auditability in production-grade systems
Why persistent state is critical for scalable knowledge work
Given our commitement to open source and open science, the entire repository, benchmarks, and reasoning traces are open-sourced under an MIT license. We invite you to examine, validate, and extend our work directly (including using it commercially). Additionally, we are actively seeking engineering collaborators interested in enhancing the framework and building the next generation of agentic tooling.
This is a foundational step towards intelligent systems that truly remember.
(PS: If you want to use our Swarm Infrastructure, sign up for our API here: https://www.irys.ai/irys-api)
Executive Highlights (tl;dr of the article)
Long-context inference is architecturally broken. Attention scales quadratically, memory bandwidth is physically capped, and model performance collapses as input grows (Liu et al., Chroma 2025).
Expanding the context window doesn’t work. Training bigger models doesn’t fix positional encoding bias — a fact on page 3 gets treated differently than the same fact on page 97.
Current agentic systems fail through statelessness. Decomposing tasks avoids context limits, but agents end up rereading processed documents and losing critical findings when context compacts.
Conversational handoffs degrade signal. Passing information through natural language summaries causes single agents to outperform multi-agent systems under equal token budgets (Tran & Kiela, Stanford 2026).
Stateful Swarms use a persistent blackboard. Specialized agents write provenance-tracked entries to an append-only, typed knowledge base instead of passing volatile context to each other.
Read once, query forever. The blackboard accumulates structured understanding so you only pay the token cost to read a document set once.
Costs drop by 39x. On the 1,251-task Harvey Legal Agent Benchmark, this architecture hit 17.75% strict all-pass at $1.30 per task, beating Harvey’s published 7.1% at $50.90 per task (w/ Opus hitting 10,7%, no costs mentioned, can assume same cost as 4.7 b/c the models have identical pricing). Doing the math, Swarms are between 66-98x more efficient than the best performers.
Structure drives performance. Frozen Gemini models that scored 0% in standard agentic setups produced these results purely through structural coordination.
Auditability is built in. Every blackboard entry tracks its type, source document, creating worker, iteration, confidence score, and support links.
Failures are fixable. You can trace exactly where extraction succeeded but synthesis failed, which is a strict requirement for production in regulated domains.
State is unavoidable. Recompute is waste, and prompt-as-memory is not a real solution for the economics of knowledge work.
Why Generative AI Currently Fails at Complex Queries?
The original promise of AI solving long-context knowledge work was AGI — a model that would solve whatever problem you threw at it in one shot. Just prompt and forget.
We’ve moved on from this fantasy, but some people still ride for a meeker version of this idea: eventually context windows will get big enough to where we don’t need any great engineering. However, when you dig into the details of how LLMs work, this fantasy face-plants real quick.
How Self-Attention becomes very Expensive in Long Context Inference
Attention computes a score between every pair of tokens. As context grows, compute scales quadratically. This means as your context length increases, the cost of computing Self-Attention grows very, very quickly. And this is something you have to recompute with every new message: meaning that you’ll spend a LOT of money recomputing mostly irrelevant tokens to answer even basic questions (keep in mind as your input context grows, you’ll most of your input tokens will likely be irrelevant or distracting to your actual query).
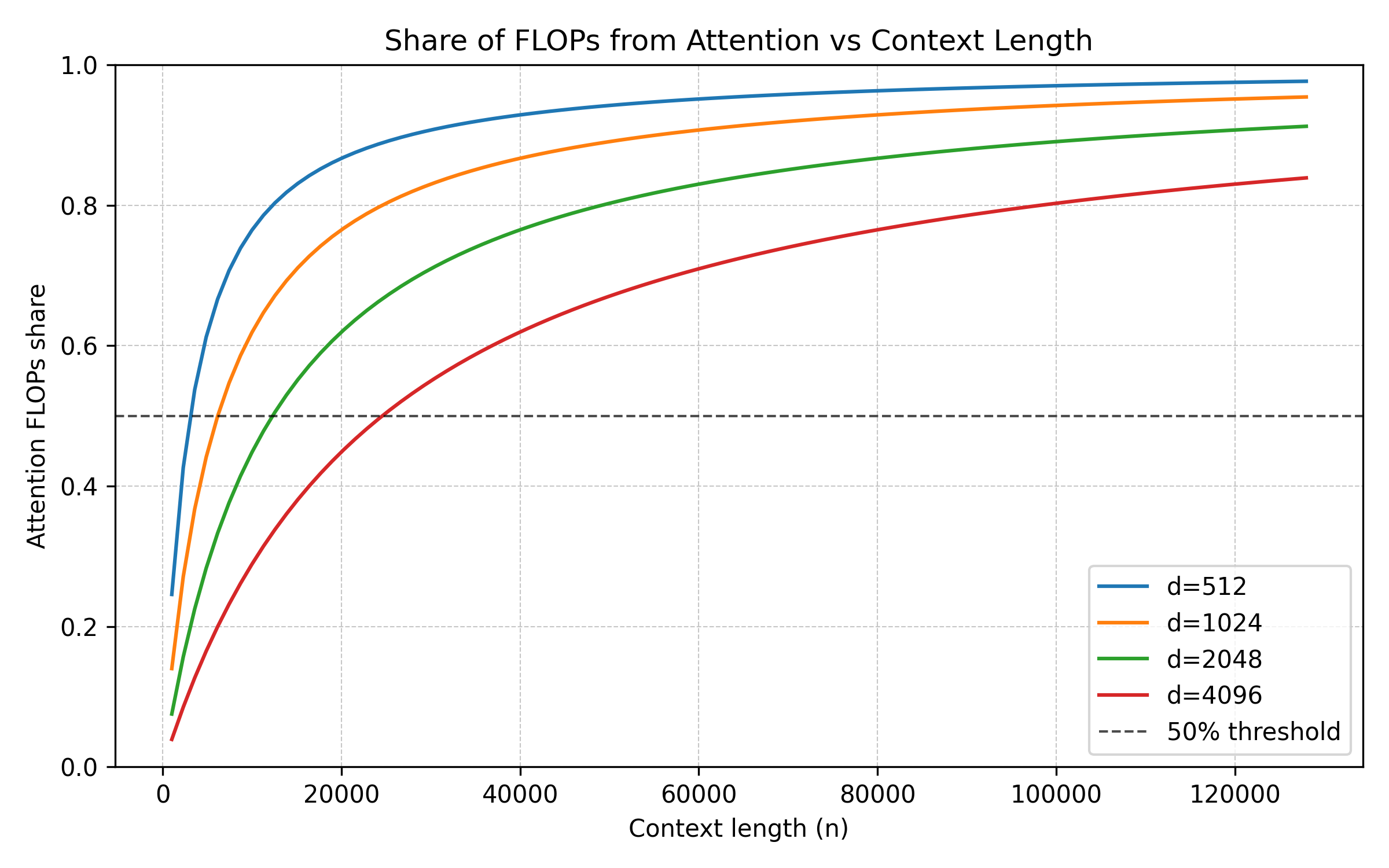
FYI, we still don’t know how to counter this issue. The most efficient edge models have kicked the can down the road by layering in their expensive full self-attention layers between stacks of cheaper variants. By not computing the cost of full MHA every layer, you can drive down costs of your network, but we still have to pay the piper eventually.
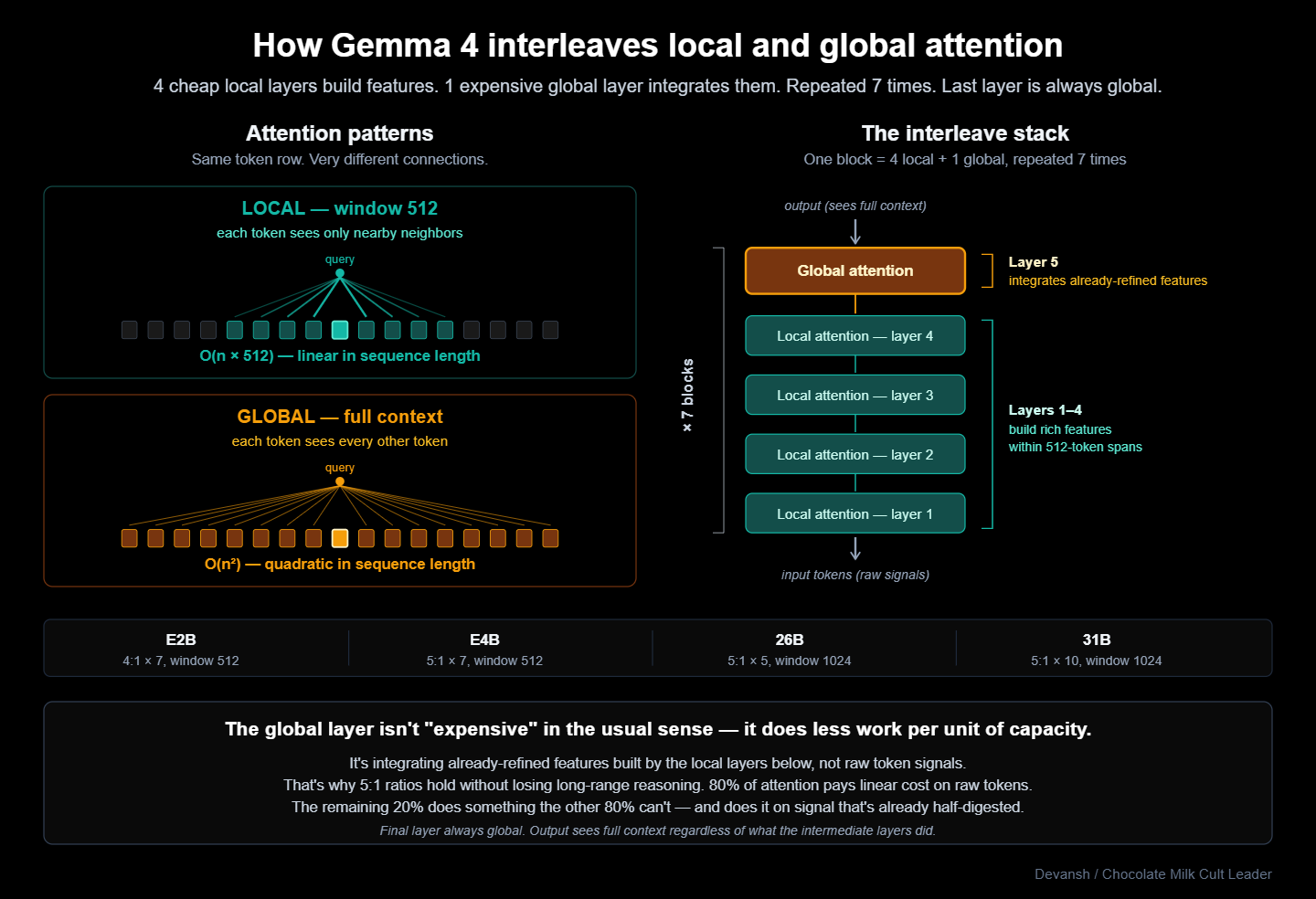
But lets say you bite the bullet on this because you’re determined to send all your tokens to one model. Your worries don’t end here. The most expensive aspect of long context work is in the hardware.
How HBM Makes Serving Long Context Expensive
To serve those tokens, the GPU must constantly move the KV cache in and out of High Bandwidth Memory (HBM). HBM is the most expensive component on the chip, and its bandwidth is physically capped.
Dao et al. formalized this as the IO-awareness problem in FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (NeurIPS 2022) when they found that the bottleneck in long-context serving is not the FLOP count of attention but the number of reads and writes between GPU SRAM and HBM. FlashAttention reduces memory accesses but does not eliminate the quadratic scaling of the mechanism itself.
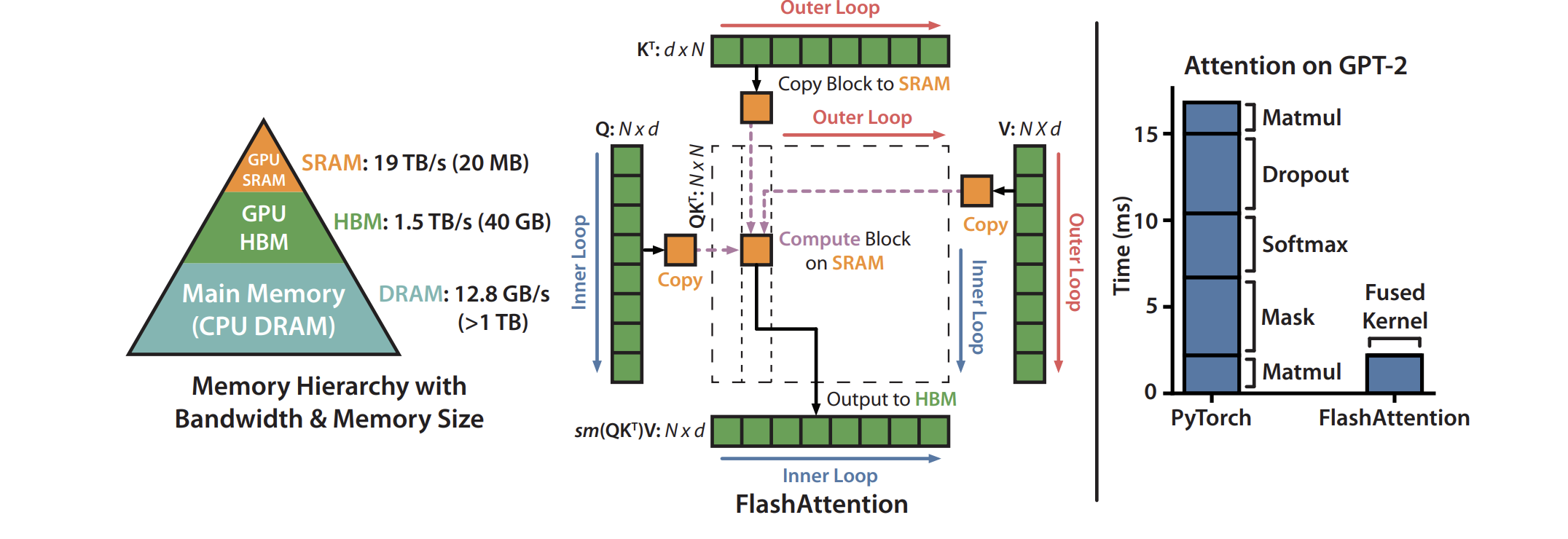
Tldr: you want big memory chip for big context; you give Micron big money.
But let’s say you have a lot of money, and no actual AI expertise to solve problems (all too common in legal tech). So we go ahead with trying to build long context models, no matter the context. This is where you hit the next set of problems.
Training Models is Unreliable (especially over Long Contexts)
With all that money floating, couldn’t you eventually train a super long context model to solve all your problems? Not really.
The scaling curve for knowledge injection is not linear. Forcing a single model to hold all knowledge creates interference. Optimizing weights to improve reasoning in one domain often degrades performance in another. You can push a model to ace a benchmark, but you cannot reliably bake deterministic facts into its weights for production use. This is why LLMs are still hit with all kinds of random and unpredictable hallucinations, even for things that should be in their cutoff dates.
What about in-context learning (stuffing all the important context in memory)? Assuming your users are willing to go through the effort of sharing their entire strategy, relevant context, and jurisdictions in the context window, you hit attention degradation. A fact on page 3 receives different attention than the exact same fact on page 97. Liu et al. demonstrated this directly in Lost in the Middle: How Language Models Use Long Contexts: on multi-document QA, model performance dropped over 30% when the answer document was positioned in the middle of the context versus the beginning or end. As long as LLMs use Rotary Position Embedding (RoPE), which introduces a decay that biases attention toward sequence boundaries, we will continue to have to deal with this.
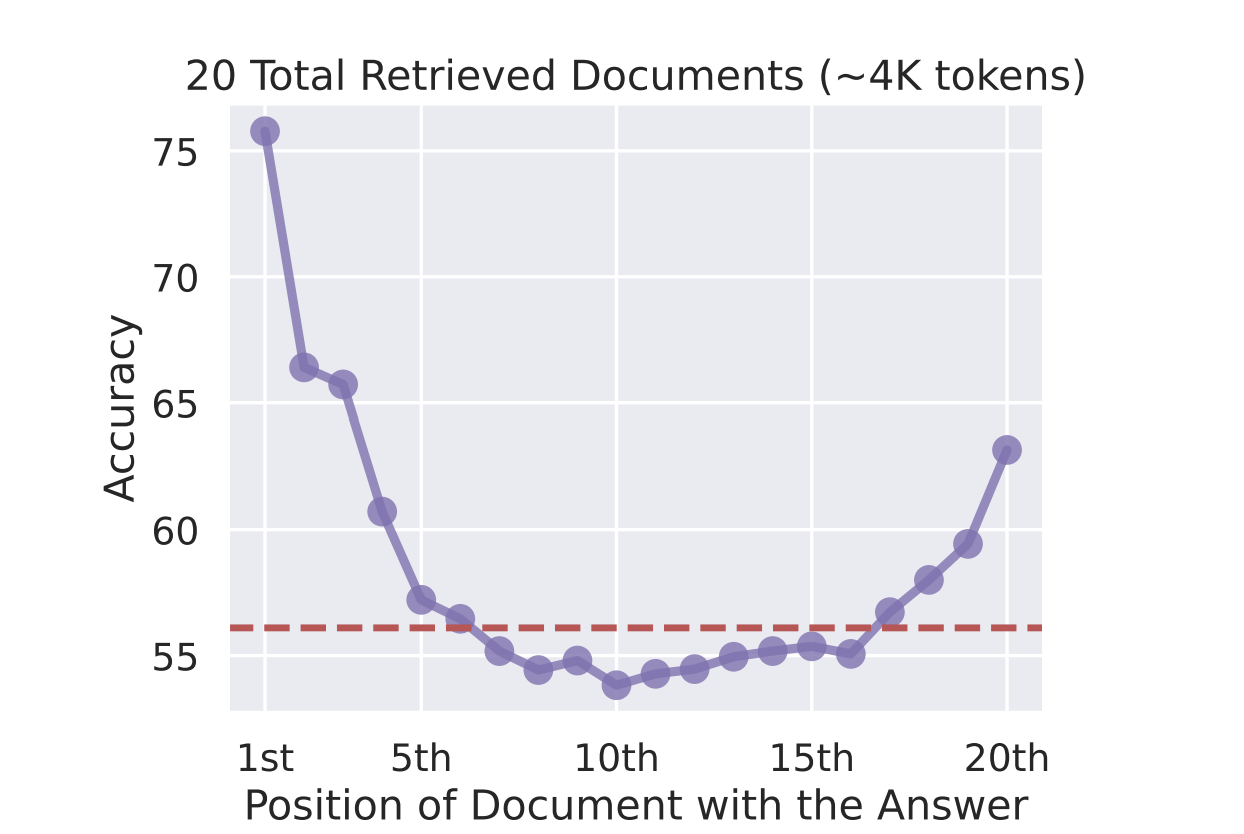
Chroma’s 2025 Context Rot: How Increasing Input Tokens Impacts LLM Performance study extended this finding across 18 frontier models and found that every model exhibited performance degradation as input length increased. The degradation is nonlinear and unpredictable: models can hold near-perfect accuracy to a threshold, then collapse.
So even if you really want to set your money on fire by training larger models for more context, you’re not guaranteed the returns you want. And when your model eventually fails, you’ll have no clue what steps to take to fix it (you can retrain, but that’s costly and doesn’t guarantee behavior).
This bitter pill is what has shifted LLM training priorities over the last 1.5 years. Open any modern LLM training recipe, and you see that the models are trained on tool use. This is because the labs have explicitly shifted their priorities away from single-shot capability to agentic systems — instead of hoping one call does everything, call a model a bunch of times, often including tools like calculators, code runners, web search etc. This way we can cover the gaps of each individual model call/method through a variety of techniques.
(when engineers use variety to make their lives better, they’re celebrated; when I want variety in my life, people say I have commitment issues. smh these double standards).
The added benefit of agents (imo the main advantage) is the traceability. If something fails, you can isolate it very quickly by tracing the tool calls and their I/O. You can finally see if your “DO NOT HALLUCINATE” instruction fired off as it should’ve.

Agentic Systems are amazing, and very useful. It’s no coincidence that the mainstream adoption of Claude and GPT in knowledge work came from their agentic systems CoWork/Anthropic and Codex, respectively. However, they have a few issues:
They’re very expensive to run, and they waste a lot of tokens relearning things (rereading docs they’ve already studied, rereading their agent trails etc) or redoing things because they lost instructions somewhere.
Remember the problems with building long context models? Still an issue. So they deal with long contexts by compacting their windows, which makes the above worse since a lot of important things are lost when we compact.
These agents can be hard to extend beyond their baseline
The pace of LLMs makes agentic systems very hard to trace and stop mid-run since they spew out an overwhelming amount of text very quick. This makes their outputs very unmaintainable and increases the amount of rework required. This is why many people report negative ROI from these agents (since they build systems/do work that they don’t understand and thus end up having to redo).

These were some of the issues that we’ve been trying to address at Irys when building meaningful long context agents for knowledge work. We’ve realized that the solution to this is not to incrementally improve a limited paradigm, but to rebuild stronger foundations.
Why Stateful Swarms Are All You Need for Knowledge Work
To understand why this architecture works, you have to break down the two terms individually:
Swarm: The system replaces the single-model monolith with a fleet of coordinated AI agents. Instead of expecting one generic prompt to parse an entire matter, the architecture delegates tasks to specialized worker agents that handle distinct execution phases.
Stateful: The system maintains a persistent, append-only, typed knowledge base that accumulates data over multiple iterations. The intermediate state survives across sessions, meaning the system doesn’t lose its mind when a user opens a new window.
We solve the coordination problem through the Blackboard Pattern. The blackboard is a structured shared state that functions as the primary asset of the system. Agents never pass context blocks directly to one another. Instead, a worker reads the blackboard, performs a tightly bounded piece of cognitive labor, and writes its findings back as a typed entry with explicit source provenance.

The system executes this process across ordered phases. A seed planning agent first maps the document landscape to define key extraction criteria, specific questions, and target schemas. Parallel extraction workers then populate the blackboard with observations, tracking metrics like source quotes and confidence scores. Higher-tier analytical reviewers step in next to synthesize these extractions, resolve conflicting data, and trace explicit evidence chains. Finally, a supervisor runs a deterministic convergence check: if knowledge gaps remain, it dispatches targeted follow-up workers to parse specific document sections rather than re-reading the entire corpus.
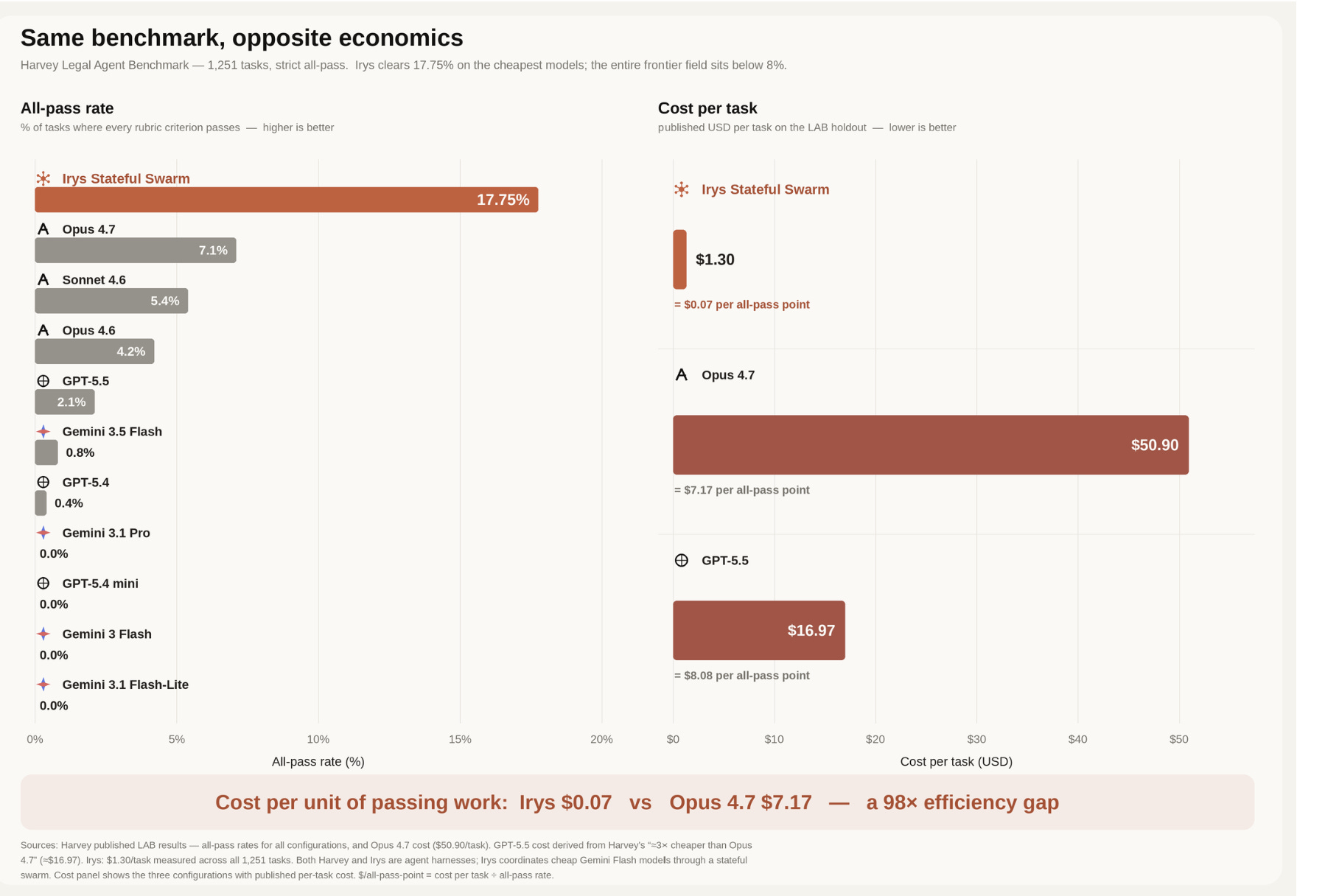
To prove the validity of this architecture, we ran it against the full 1,251-task Harvey Legal Agent Benchmark (LAB). The data proves that structural coordination matters far more than raw model scale.
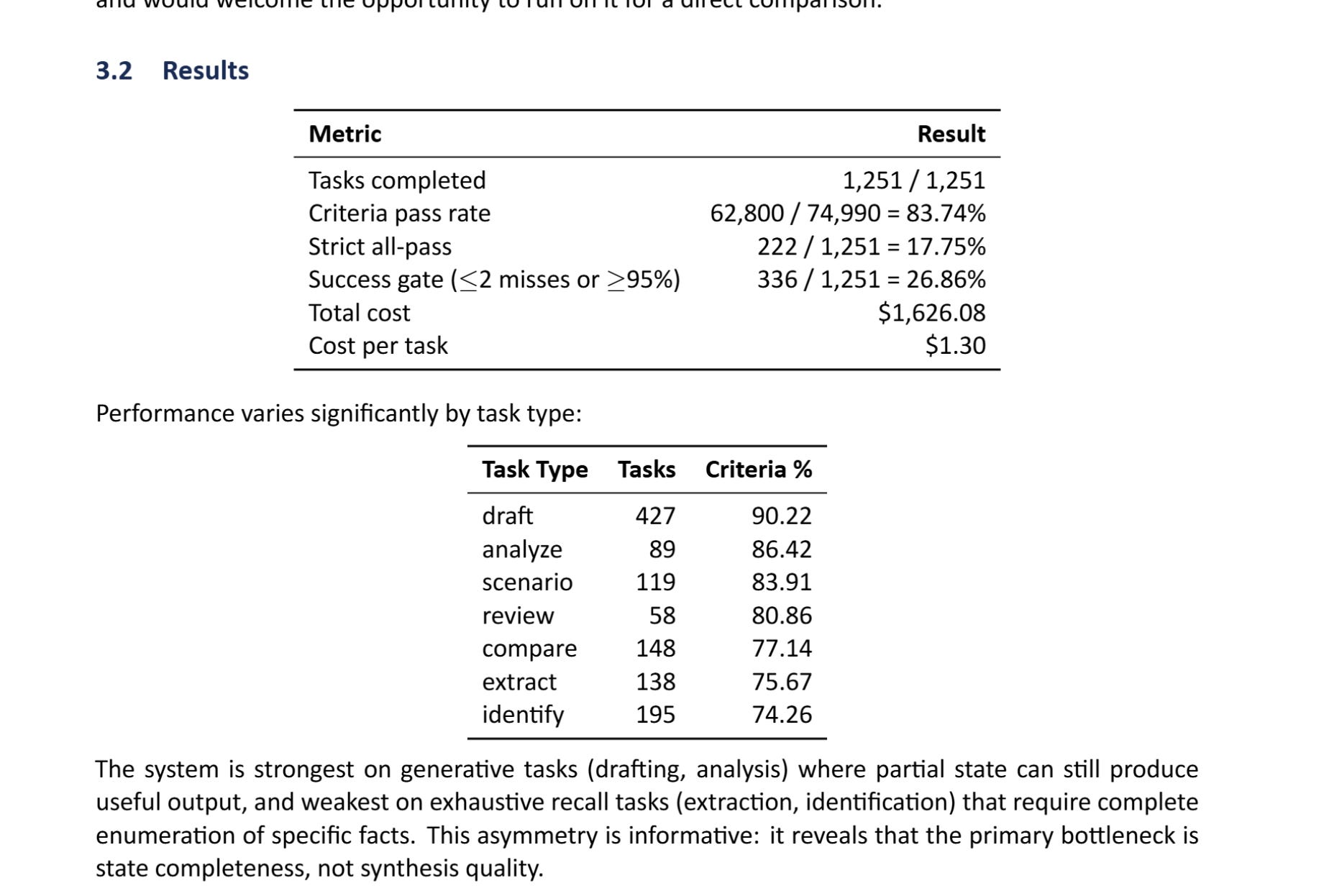
The system achieved an 83.74% pooled criteria pass rate and a 17.75% strict all-pass rate across 24 practice areas. It did this at a total compute cost of $1,626.08, which averages out to $1.30 per task. Harvey’s published baseline on their twin holdout distribution reports a 10.4% strict all-pass rate at an average cost of $50.90 per task. The stateful swarm delivers a 39x structural cost reduction while significantly outperforming their best system.
(If you compute the cost per passing point, this jumps up to 98x the efficiency, but we’re not stressing that too much since performance is the biggest driver right now and we don’t have the private hold-out set).
This economic shift is driven by precise model routing over cheap, commodity infrastructure. The system routes high-volume parallel extraction tasks to Gemini 3.1 Flash Lite at $0.25 per million input tokens and $1.50 per million output tokens. We reserve the mid-tier Gemini 3.5 Flash strictly for reasoning-heavy steps like planning, cross-document analysis, and final synthesis, at $1.50 per million input tokens and $9.00 per million output tokens.
In Harvey’s baseline evaluations, these exact same Gemini models achieved a 0% strict all-pass rate when deployed inside standard agentic setups. We specifically picked these models to prove a point: by changing how the models interact — moving from stateless tool-calling pipelines to a stateful, iterative blackboard — the same frozen weights jump from absolute failure to 17.75% perfect execution. This is proof of our larger thesis that structural improvements can unlock capabilities not present in relying purely on the model layer.
Our system design allows us to tackle one of the biggest blockers in multi-agent systems. Tran & Kiela (Stanford, 2026) argued in Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets that every inter-agent handoff loses information — grounded in the Data Processing Inequality, which predicts that coordination can only degrade performance.
We show that their finding holds for conversation-based multi-agent systems where agents pass context through natural language summaries (which creates a loss of information and an ability to enforce constraints). It does not hold for blackboard architectures where agents write typed, provenance-tracked entries to structured shared state. Our blackboard doesn’t lose information at handoffs. That is why the same Gemini models that achieve nothing individually produce 17.75% strict all-pass when coordinated through one.
So far, we’ve discussed how Irys’s Stateful Swarms paradigm solves 3 of the main issues plaguing current agentic systems:
The shared blackboard means we can accumulate knowledge over time, reducing the tokens from re-learning.
Blackboard allows prevents loss of information on compaction and other issues.
Our use of self-defining swarms (analyst writes custom prompts for whatever problem needs it) also ensures that it can handle a wide amount of flexibility in the problems we can solve (I’d encourage you to try the GitHub CLI on your own problems; part of the reason we’re open sourcing it is to get your insights into what you’d prefer differently).
We haven’t talked much more about the audibilty and transparency. That was because our new blackboard allows us to pull off one of of the best feats of auditability yet.
Why Auditability Matters More Than the Benchmark Score
No matter how good, a system is bound to fail. But a wrong answer can still be a useful answer, if we understand where it went wrong and how to avoid that.
Let’s see how the blackboard enables that. In our Stateful Swarms, every task produces a complete, structured record of how the system arrived at its conclusions. Each blackboard entry carries its type, source document and section, the specific worker that created it, the iteration it was created during, its confidence score, and which other entries it supports or contradicts.

You can literally study the blackboards as they progress over iterations and use them to see how the system evolved it’s understanding and how it learned things over time. In an upcoming UI update to Irys, we’re going to expose this learning evolution to our users so they can stop/redirect things mid-investigation as our system finds interesting learnings.
The main advantage of the blackboard for transparency is that it’s much clearer to read and it centralizes all important information to one place (instead of scattering the learning fragments all over like Sukuna’s fingers). This allows us to study both the success and failure to improve the outcomes. Let’s understand how.
When the system succeeds, the trace demonstrates why. On a credit agreement comparison that scored 40/40, the blackboard evolved from 7 seed entries to 2,400 grounded findings over 12 iterations: 2,044 source-grounded observations, 87 cross-document calculations, 135 identified gaps, and 113 analysis entries identifying specific deviations. Each analysis entry carries a supports field linking back to the evidence it synthesizes. A reviewer follows the chain from conclusion to evidence to source document.

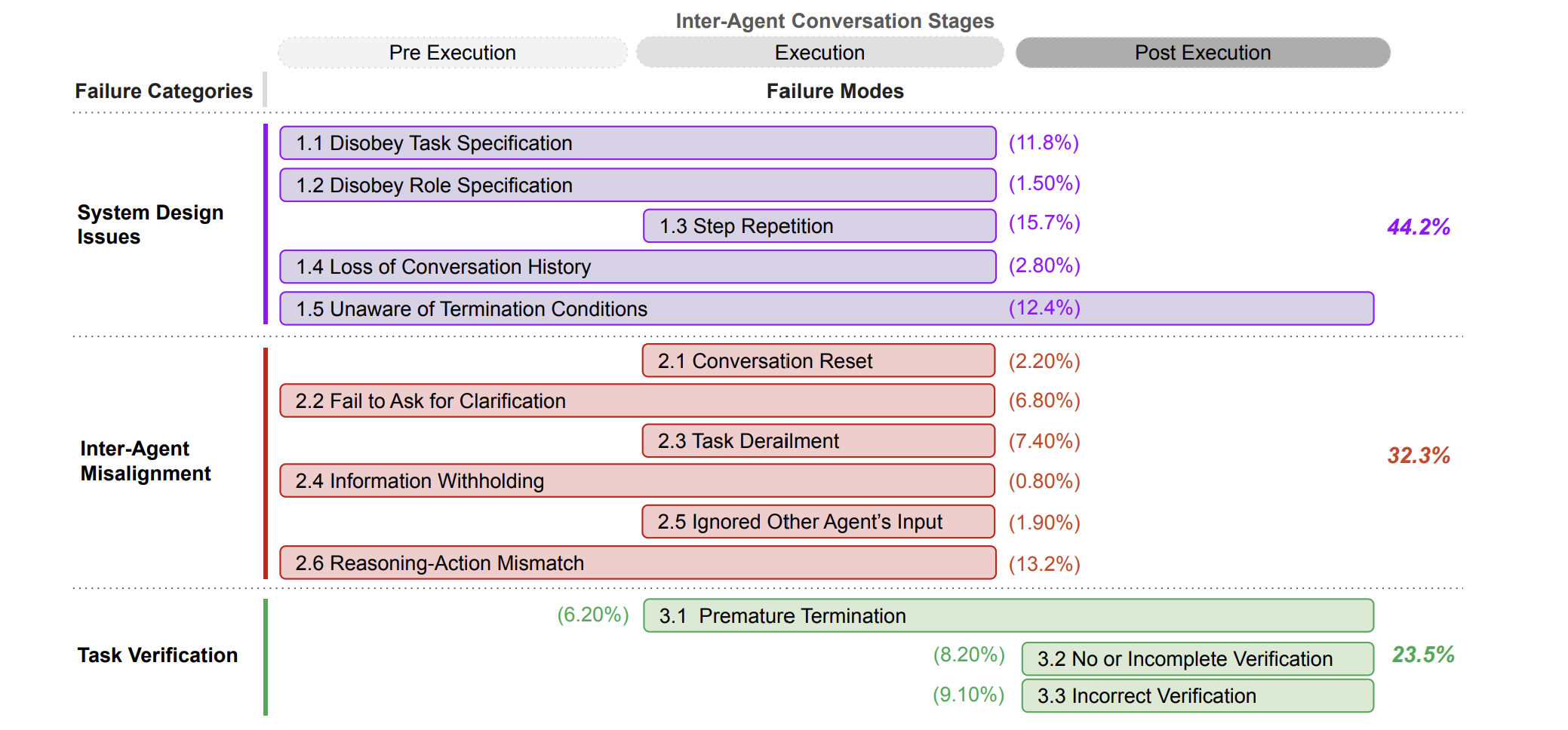
When the system fails, the trace reveals why — and whether the failure is fundamental or fixable. On a sanctions entity extraction task that scored 80/85, the five missed criteria shared a diagnostic pattern. The blackboard contained entries with two name variants — “Zenith Petrochem Industries LLC” from one document and “Zenith Petrochemical Industries LLC” from another. Both were correctly extracted. Both existed in the state. What the system failed to do was cross-reference these entries and flag the discrepancy. In a separate miss, the system identified that a 49% ownership stake sat 1% below the OFAC 50% threshold and even mentioned that aggregate ownership by blocked persons could trigger a violation — but didn’t elaborate the aggregation principle with sufficient specificity.
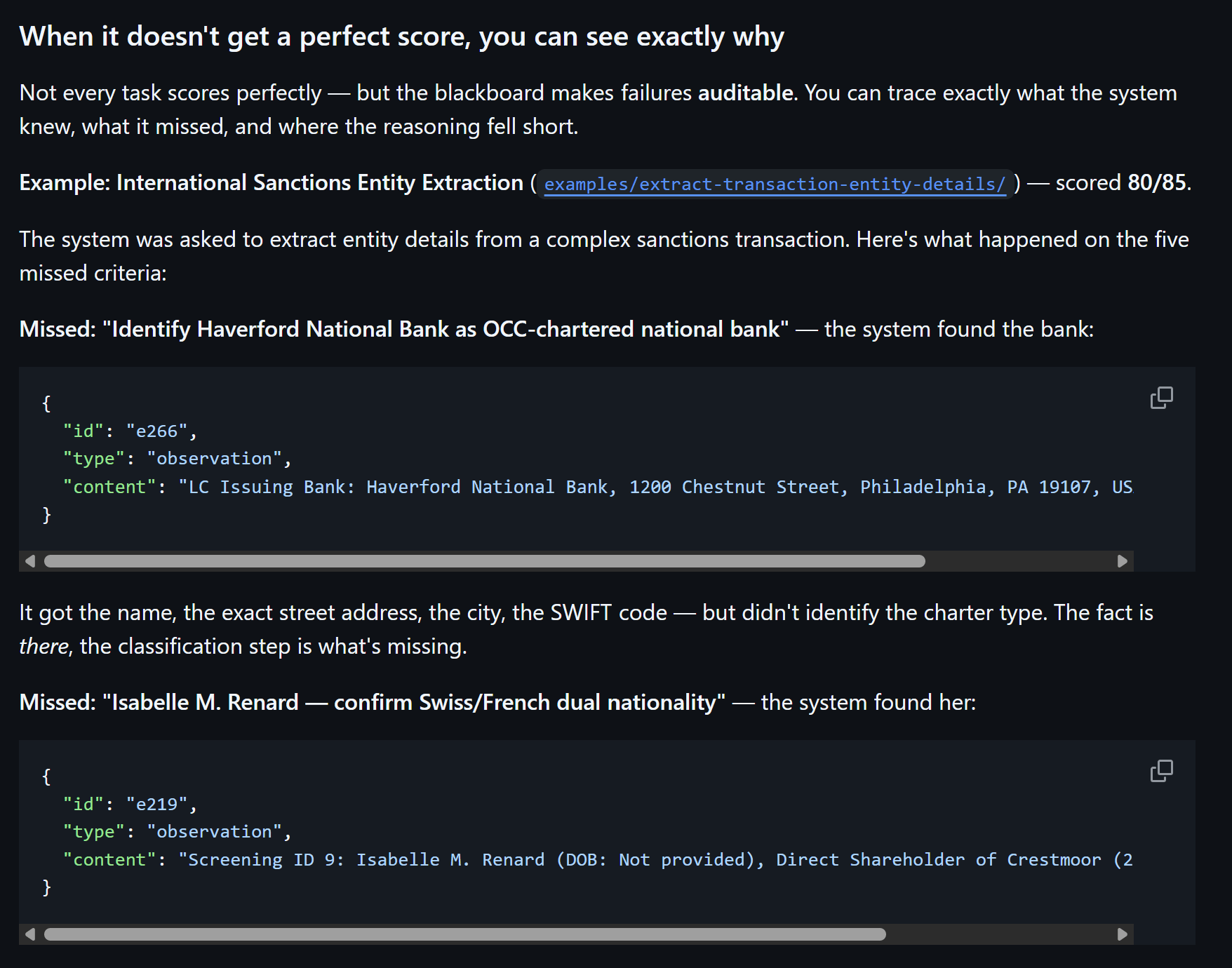
The pattern — correct extraction, incomplete cross-referencing — is qualitatively different from a system that never found the information. It tells you the failure is in state processing, not in extraction capability. These are fixable failures, and the blackboard is the mechanism that makes them identifiable. A monolithic system that missed the same criteria would give you nothing: did it not read the document? Read it but not extract the entity? Extract the entity but not notice the variant? No way to know.
For legal work specifically, this is not optional. Attorneys are professionally responsible for the accuracy of their work product. A system that produces correct answers 83% of the time is useful only if the remaining 17% can be identified and corrected.
(From a product perspective, this also means that we know why our system fails and we can improve our product much faster and w/o guesswork/relying on the luck of training a new model, since our improvements are structural).
What This Means in Production
Furthermore, this performance profile generalizes beyond legal analysis. The machinery of state tracking, multi-iteration convergence, and typed provenance requires no domain-specific training or weight adjustment. We are releasing the system as an open-source CLI that accepts any document set and task instruction. We’ve validated the architecture across internal repositories spanning multiple domains, and we are actively running benchmarks on non-legal verticals that we’ll be publishing in the coming months. The coordination logic is identical — the benchmark adapter is the only domain-specific component.
We checked this on 7 Datadog 10-K annual filings (FY2019 through FY2025). We asked a non-legal question — “Analyze how Datadog’s strategic priorities have shifted over the last 5–7 years using their annual 10-K filings (2020–2026). Produce a comprehensive investment memo covering product strategy evolution, go-to-market shifts, risk factor changes, competitive positioning, and financial trajectory.”
What happened (shared here):
irys-stateful-swarms completed in 800 seconds. 12 iterations, 2,115 blackboard entries, 218 signals, 2.7M tokens. Produced a 12,657-word investment memo covering product strategy evolution (2012–2024 timeline), GTM transformation (10,500 → 29,200+ customers), competitive positioning shifts, financial trajectory ($362.8M → $2.68B revenue), and risk factor evolution.
Claude Opus sub-agent failed after 415 seconds. Hit “autocompact thrashing” — context window filled up after 2–3
filings, compacted, refilled, compacted again, gave up. Produced nothing.
In production environments, this stateful foundation unlocks a massive cost advantage over multi-turn interactions. Our enterprise platform, Irys, pairs swarm coordination with hierarchical embeddings and persistent indexes, and knowledge graphs to cut multi-turn inference costs by up to 100x compared to stateless re-computation on user defined matters (it’s also why we can ingest as many Gigabytes of documents, which none of our competitors can do).
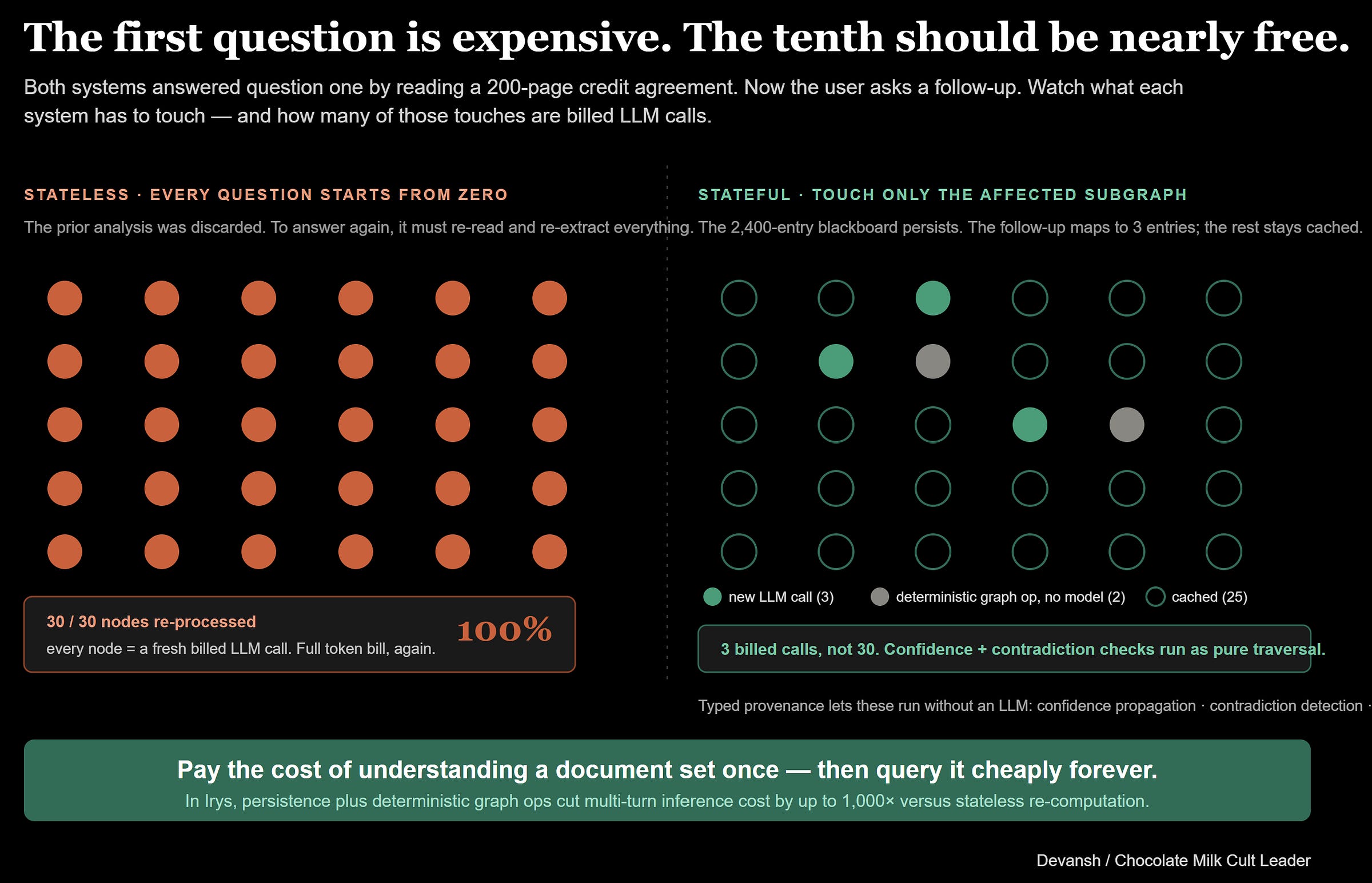
Because the blackboard entries are structurally typed and tracked by worker provenance, the system can run deterministic algorithms directly on the state graph without calling an LLM at all. Operations like updating confidence scores across linked nodes, tracking fulfilled obligations, and flagging internal contradictions are handled via pure graph traversals and mathematical updates. When a user asks a follow-up question or introduces a new document amendment, the system targets and updates only the affected subgraph. You pay the steep token cost to read and extract a document set exactly once, then query against the accumulated understanding cheaply forever.
Conclusion: The Future is Stateful Swarms
Our open-source code uses standard API calls to baseline frozen language models — no latent space reasoning, custom embeddings, or proprietary retrieval engines. This minimalist approach ensured alignment towards benchmarks (which tend to be very atomic in what they allow) and also let us show what raw coordination logic can do on its own. But standard API loops, while fine for controlled benchmarks, crumble under real-world engineering realities and production costs.
The industry is obsessed with brute-force scale with massive models and sprawling context windows. The assumption is that stuffing infinite memory into a prompt is sustainable. It isn’t. As we detailed, relying entirely on the context window leads to attention decay, information loss, and spikes your hardware costs. Constantly reprocessing the same 3 2000-page document to answer a basic follow-up question is fundamentally broken. You end up paying full price to read the same text over and over again (yes yes prompt caching, but that’s a bandaid, not a fix).
Stateful swarms change this by moving memory out of volatile inference and into structured reasoning. This is the structured, auditable state the system refines and preserves. You invest in understanding a document set exactly once, then query it cheaply forever.
I’ll leave you with an observation. Recompute is waste. Pinning is waste. Session loss is waste. Someone will solve these problems, because the economics demand it. The future belongs to stateful systems that retain and refine memory persistently. This means that whether or not you are fully sold on stateful swarms, you can’t deny that state is one of the core problems for agentic systems to solve. And taking that as a given, it’s also impossible deny that the current “prompt as memory/state” solutions are woefully lacking.
So whether you agree with stateful swarms or you have an alternative idea, I’d say that there’s no denying that it makes sense to explore this part of the world together, as fellow believers in Statefulness. I’ll look forward to hearing from you.
Repository: github.com/dl1683/irys-stateful-swarms
Contact: devansh@iqidis.ai
Thank you for being here, and I hope you have a wonderful day,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. :
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819
Reminded me of the blackboards in university lecture rooms where professors unfold them to address the memory issue of students. Our face looked exactly like the above meme when we first encountered those put in use. Sounds like to be a promising workflow also by reducing a handover loss. This is the way.