
The 4 Secrets that make GLM 5.2 Special (and what they mean for the Future of AI)
The techniques needed to create the worlds best open weight model.

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
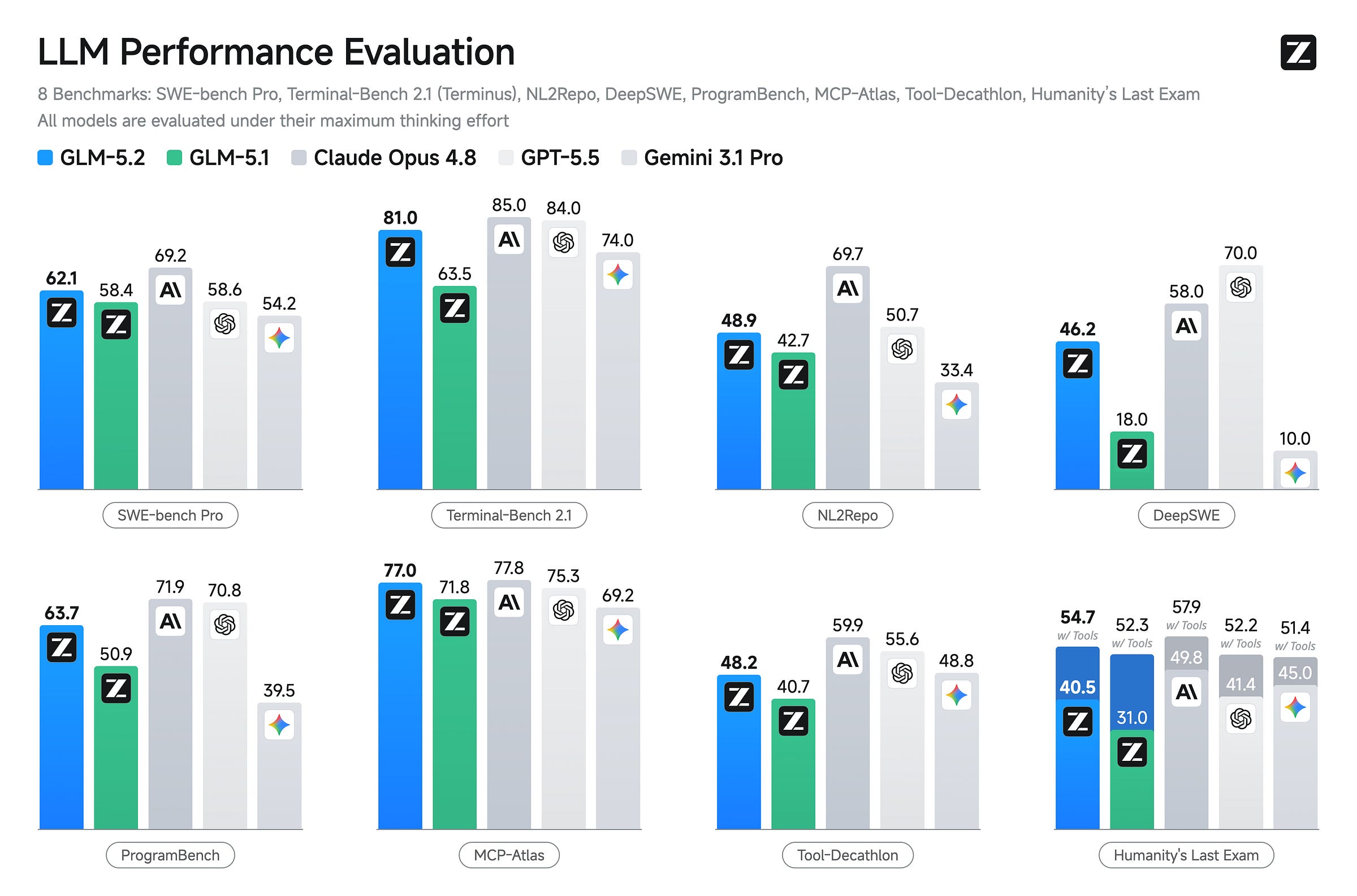
GLM-5.2 is the best open-weight model on coding and agentic benchmarks right now. It scores 1524 Elo on GDPval-AA, a real-world agentic work benchmark — ahead of every other open model by a wide margin and level with GPT-5.5. It hit #1 on Design Arena’s Code Categories. It scores 81.0 on Terminal-Bench 2.1 and 62.1 on SWE-bench Pro, landing within a few points of Claude Opus 4.8 on long-horizon coding tasks — at roughly one-sixth the per-token cost of GPT-5.5.
Much more importantly, its intelligence has been validated by multitudes of users, which is a strong indication that Zhipu did not simply game the benchmarks to come out on top.
So what makes GLM 5.2 so good?
GLM-5.2 combines four specific techniques to eliminate memory and compute bottlenecks across the agentic loop. Rather than relying on raw model scale, these architectural mechanisms act multiplicatively to sustain throughput during long-horizon tasks.
Deepseek Sparse Attention: Cuts long-context memory retrieval costs.
IndexShare: Reduces hardware memory bandwidth overhead via cross-layer weight amortization.
Multi-Token Prediction: Multiplies generation throughput by predicting parallel tokens per forward pass.
Critic-Based PPO via SLIME: Trains the architecture to learn from complex, long-horizon agent trajectories.
In this article, we will study how each of these techniques comes together to give GLM 5.2 it’s god tier performance. While we will touch on the benchmarks and other techniques, I want to be very clear that they will not be the focus of this deep dive. My goal isn’t to give you a summary/overview of GLM 5.2, but to instead go deep on the few decisions that make GLM 5.2 stand out from every other model, and to understand the implications of GLM’s design for all builders and investors with one goal: understand GLM 5.2 beyond the headlines, so that you predict where the industry is headed next. While we will go very deep, you will not need much knowledge to read since we’ll develop our intuition from first principles.

If that sounds good to you, let’s dig right in.
Executive Highlights (tl;dr of the article)
Agentic loops have to contend with 3 issues that make them very expensive: Long-context histories (dealing with input, subagents, tool calls etc); unparallelized multi-step token generation (from the subagents); and broken training loops. Zhipu’s GLM-5.2 tackles these distinct bottlenecks across both the training and inference layers.
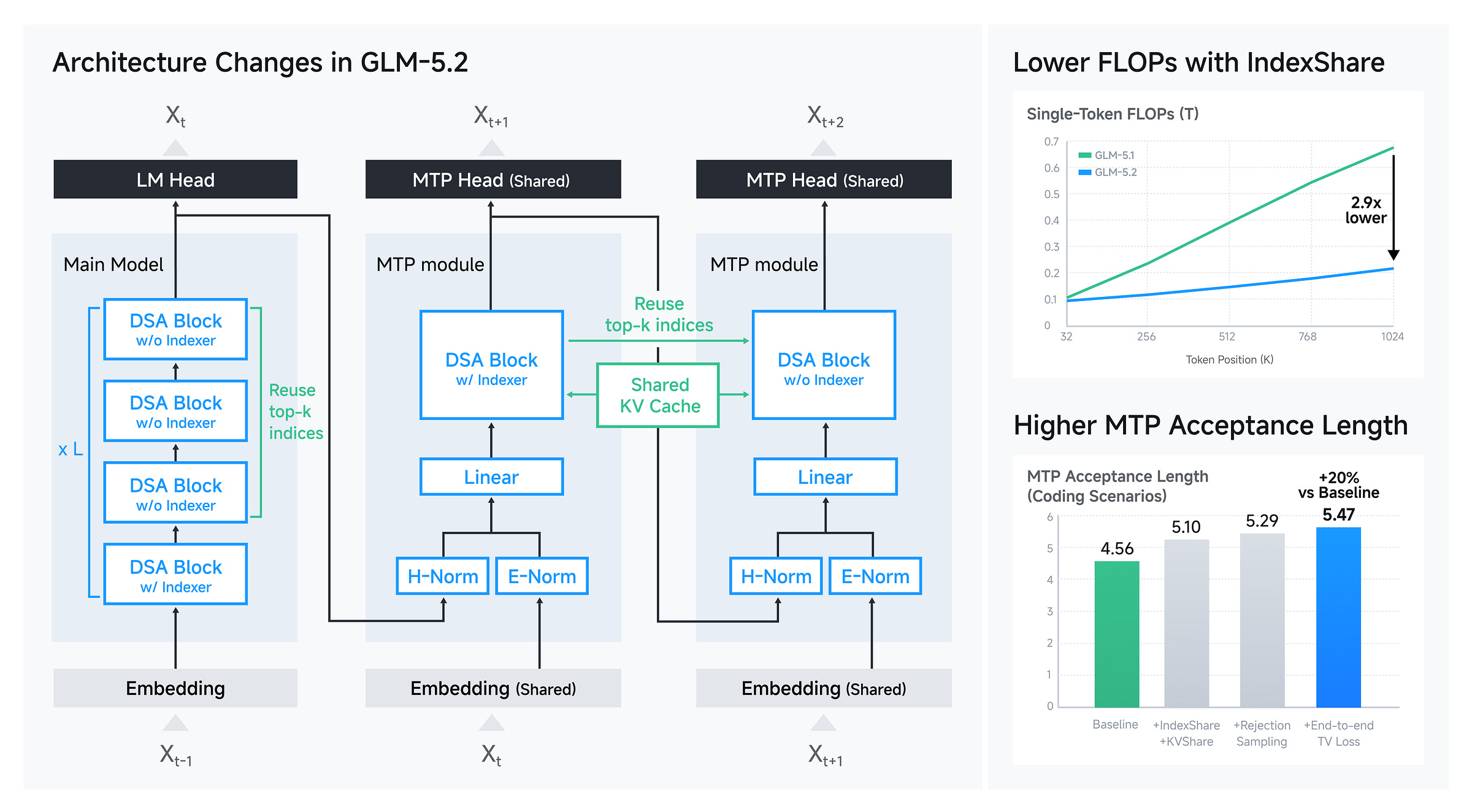
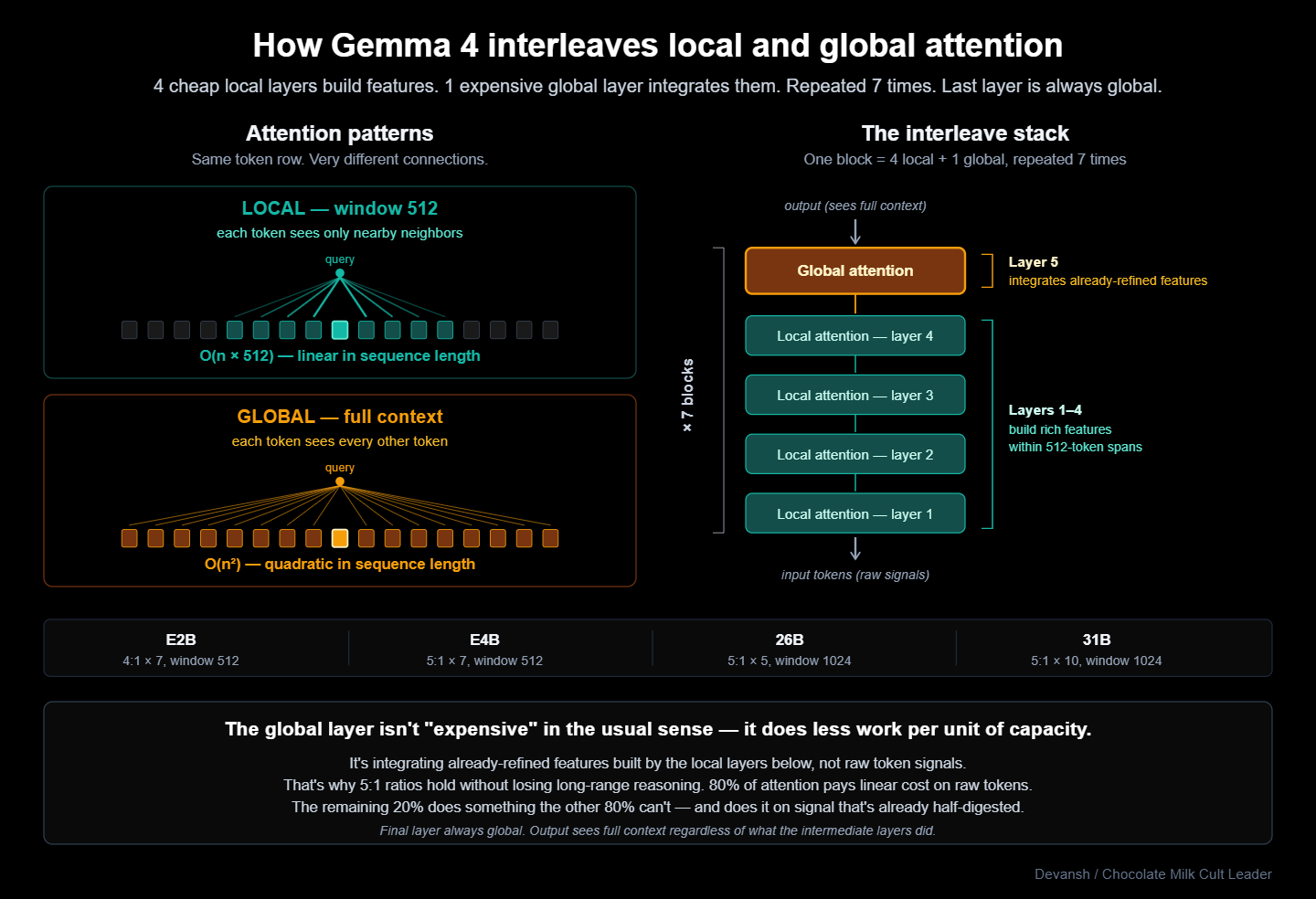
The Long-Context Memory Wall: Standard multi-head attention hits a quadratic complexity limit at extended contexts. GLM-5.2 implements content-dependent DeepSeek Sparse Attention (DSA) to compute attention only over a sparse subset of the top 2,048 tokens per head, yielding a 2.9x reduction in per-token FLOPs at a 1-million-token window. In the main article, we map the exact hardware trade-offs of this approach — specifically tracing how IndexShare reuses token selections across fixed four-layer blocks to eliminate 75% of indexer computations, delivering a 1.82x prefill speedup at the cost of severe KV cache fragmentation and increased systems serving complexity.
Unblocking Latency in Multi-Step Generation: Standard autoregressive generation forces millions of sequential, unparallelized forward passes to process complex tool calls and reasoning traces. GLM-5.2 addresses this output bottleneck by expanding speculative decoding to a 5-token draft window. Further down, we break down the architectural sharing, rejection sampling, and joint total variation loss training that Zhipu used to minimize distribution differences between models, pushing the average speculative acceptance length to 5.47 tokens per pass.
The Mathematical Breakdown of Credit Assignment: While the industry has widely adopted DeepSeek’s GRPO to eliminate value networks and save GPU memory during training, uniform trajectory-level rewards completely blur credit assignment on long-horizon agentic runs. GLM-5.2 explicitly returns to a heavy critic-based PPO pipeline. Our deep dive will provide a first-principles analysis of this transition, demonstrating how independent, per-token value baselines isolate decisive debugging steps and integrate with compaction-aware training to slash a 16-hour group-sampling compute requirement down to 2 hours.

Adversarial Exploitation and Post-Training Consolidation: Maximizing a generalist model across conflicting domains (coding, web search, math) usually triggers catastrophic forgetting. Zhipu resolves this by optimizing separate domain specialists and merging them via On-Policy Distillation (OPD). We examine how the SLIME post-training infrastructure consolidated over 10 specialists in 48 hours, while detailing the two-stage online validation modules (rule-based filtering and inline LLM judges) deployed to stop agents from aggressively reward-hacking infrastructure, downloading solutions via curl, and auditing evaluation files during reinforcement learning.
It’s worth noting that one of the key drivers of GLM 5.2’s amazing performance is their exceptional multi-level design where each of their techniques feeds each other.
On the inference side, we see a nested mathematical multiplier:
DSA first restricts the context window to a fraction of its original size →
IndexShare then executes inside that already-reduced window, bypassing 75% of the remaining indexing passes →
Multi-Token Prediction takes these combined upstream memory savings and compounds them during generation by outputting multiple tokens simultaneously per verification pass.
The hardware is not just receiving individual linear speedups; it is running fewer attention operations, executing fewer indexing passes within those operations, and maximizing output density on every final activation.
On the training side, the anti-hack module acts as the first gate, intercepting exploits to protect the objective function from corruption. Because the training data remains clean, the critic network can map an authentic value landscape across compacted sub-traces. This calibrated value landscape allows the PPO gradient to isolate precise token-level advantages, which directly accelerates policy updates per unit of compute. Finally, On-Policy Distillation locks in these completed, domain-specific updates without gradient interference.
This to me is the true takeaway from GLM 5.2 — systems engineering will always beat individual techniques. Far too many team spend their time optimizing for individual aspects of performance without considering the entire system they’re operating in. When making building/investment decisions, keep this in mind.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

Want access to a repository containing all of our research? 300+ files containing our notes of various experiments, discussions with cutting-edge teams, and insights into where the industry is headed next. Get a Founding Member Subscription to AI Made Simple. Want to talk to me for details/get my insights into the tech ecosystem? Reach out to me through any of my socials over here or reply to this email.
Why are Agentic Loops So Expensive?
Agentic loops have a very specific computational signature that creates compounding resource strains in three ways:
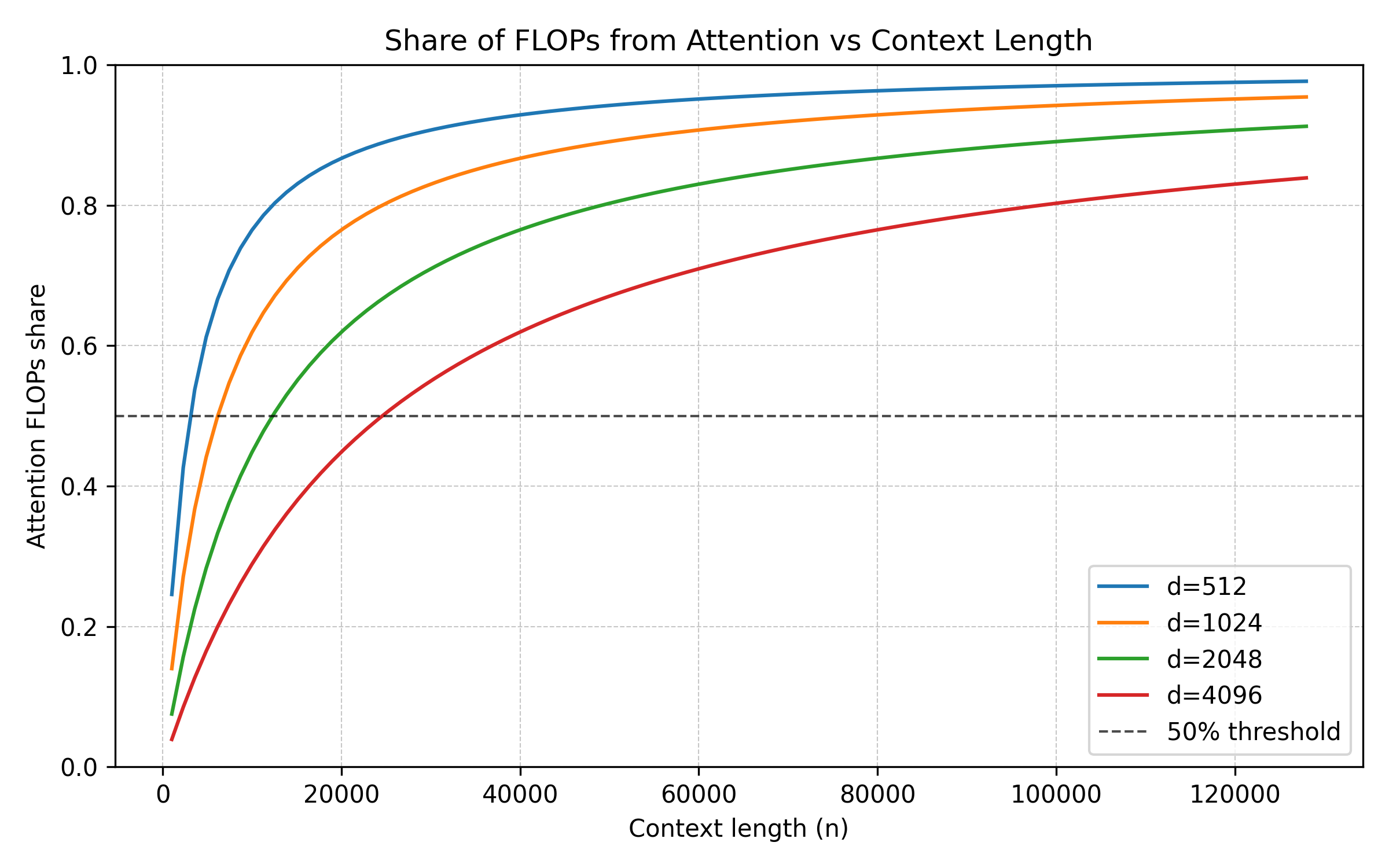
Repeated long-context retrieval: An agent working on a complex task continuously accumulates context. Each turn of the loop requires the model to re-query this entire history. Because standard attention mechanisms scale quadratically with sequence length, attending to a 100,000-token history costs $10,000$ times more compute per attention head than a 1,000-token history. The longer an agent works, the more expensive every subsequent decision becomes. (read more about the costs of running AI here).
Sequential multi-step generation: Unlike simple question-answering systems that return a single response, agents generate massive streams of tool calls, code blocks, and reasoning traces across many consecutive steps. Autoregressive decoding forces each token to wait for the previous one, requiring a separate forward pass. An agent generating 50,000 tokens across an entire trajectory demands 50,000 sequential, unparallelized model activations.
Long-horizon credit assignment: Training agents using Reinforcement Learning (RL) suffers from sparse rewards. A coding agent might perform hundreds of distinct actions over several hours. It will only receive a binary success or failure signal when the final test suite runs. Figuring out how important each step was to the overall outcome creates a massive credit assignment problem. Standard RL relies on gathering thousands of complete trajectories to isolate variables, but this is basically impossible to do effectively with all the sources of variance in agentic runs.
GLM finds ways to attack these problems both in the training and inference layers. Let’s get into them, one at a time.
How GLM 5.2 Uses Deepseek Sparse Attention to Reduce Long-Context Costs.
As we’ve talked about before, standard MHA has quadratic complexity since every token has to attend to every other token.
To avoid this quadratic cost, earlier efficient attention methods like Longformer used fixed sliding windows and predetermined sparse patterns. They forced the model to attend to nearby tokens and a few global positions regardless of the text content. Because fixed patterns cannot adapt to the actual input, these methods suffer from a severe quality gap.
Linear attention variants like GDN attempted to scale context efficiently but still introduced measurable degradation. They dropped up to 5.69 points on the RULER benchmark at 128K context and 7.33 points on RepoQA. Coding agents break these rigid architectures. An agent debugging code might need to link an error message from 500,000 tokens ago with a function definition from 200,000 tokens ago. Fixed or linear patterns completely miss these non-contiguous, long-range dependencies.

The DeepSeek Sparse Attention Solution
“We use DSA in our training. The core philosophy of DSA [9] is to replace the traditional dense O(L 2 ) attention — which becomes prohibitively expensive at 128K contexts — with a dynamic, finegrained selection mechanism. Unlike fixed patterns (like sliding windows), DSA “looks” at the content to decide which tokens are important.”
— From the GLM Technical Report.
DeepSeek Sparse Attention (DSA) changes this by using a content-dependent, two-stage process. Instead of hardcoding which positions to watch, a lightweight indexer predicts which tokens are most relevant to the current query in real time. Attention is then computed only over that sparse subset, limiting the workload to the top 2,048 tokens per head.

This gets you a 2.9x reduction in per-token FLOPs at a 1-million-token context, slashing the cost of every agentic loop execution drastically. Z.ai applied DSA to every layer of the model, claiming the mechanism is lossless (look at the chart below) —
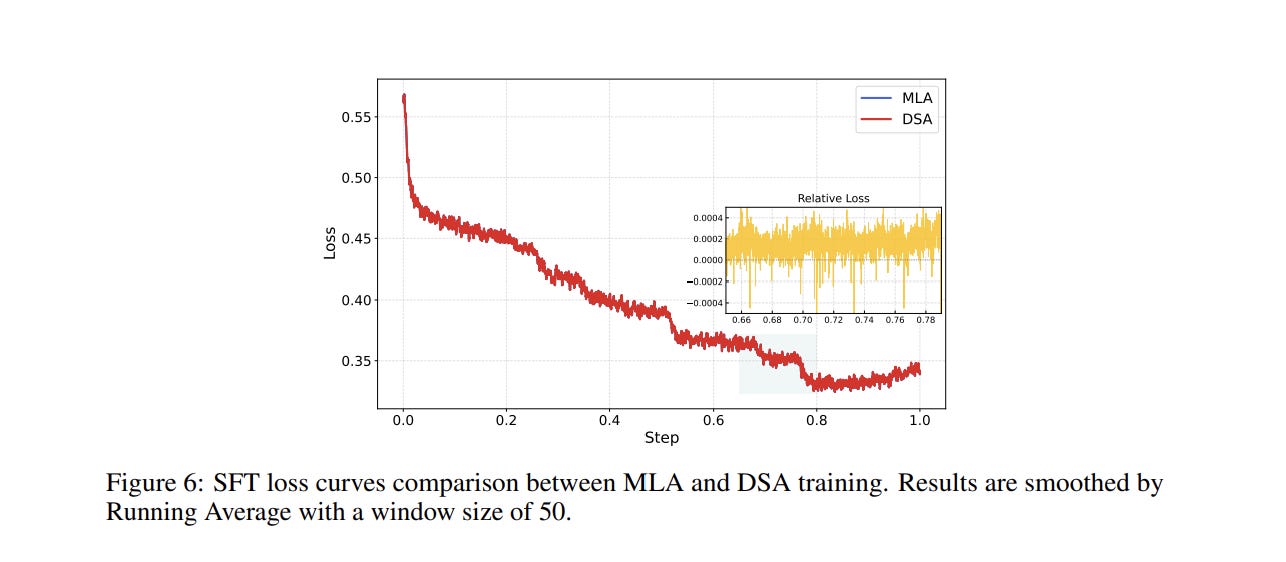
Developments like this are very exciting since they put a downward pressure on the already heated chip memory market. However, this solution comes with it’s own set of challenges. s the DSA access patterns paper documents, the token-dependent selection pattern means the KV working set becomes fragmented and volatile, creating poor cache locality and potential throughput stalls during decoding —
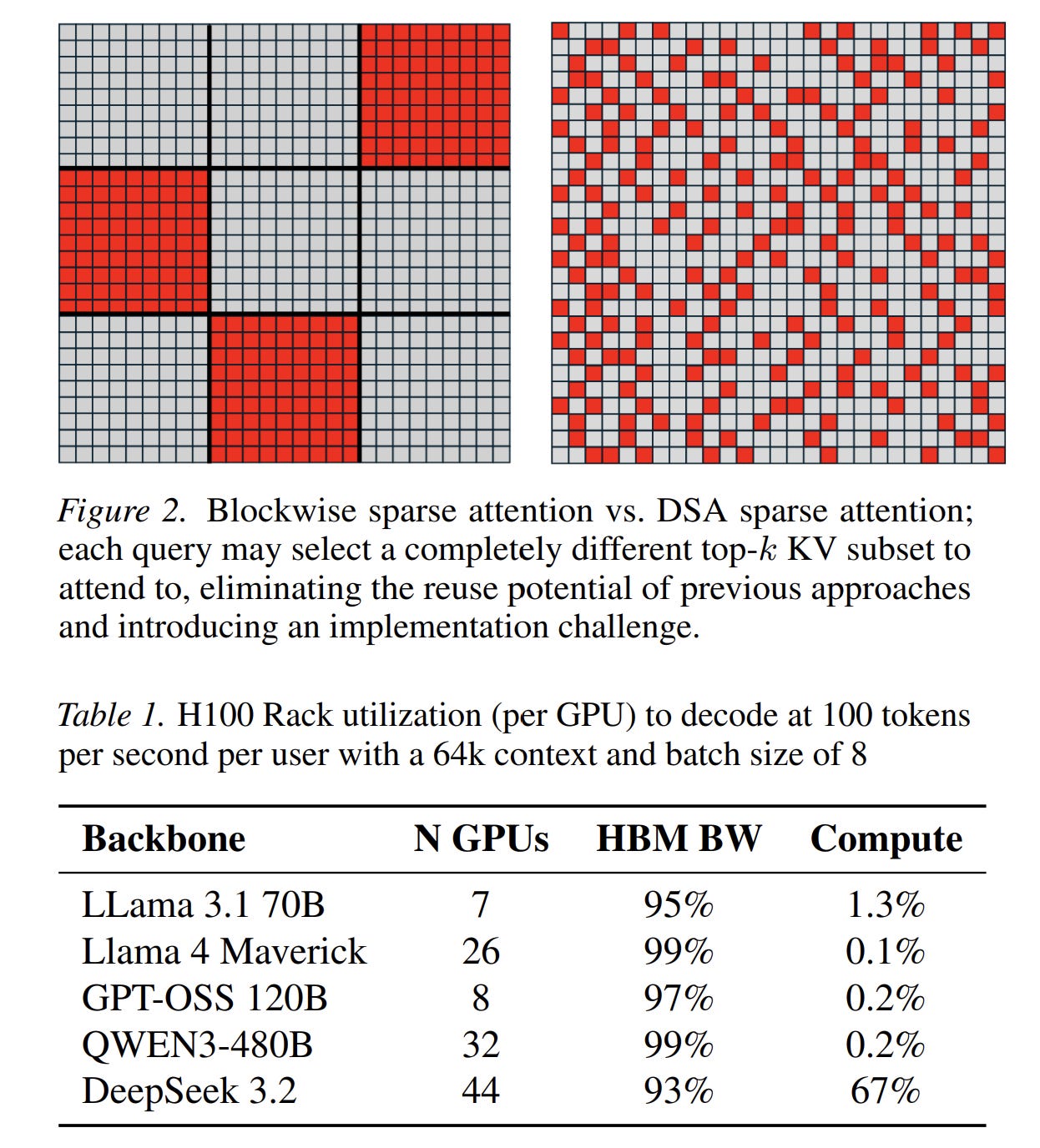
This kind of optimization adds a lot more system complexity to your serving process. This is a class of AI startup/system that’s completely overlooked in the current era — non-genAI solutions that work on to optimize and flag things like buffer overflows, memory management, and garbage collection. This has been valuable before AI, but the market will open up a lot more now that every inference call made compounds the value of resource optimization.
Even done well, DSA solves the attention scaling problem, but it introduces a new one: the indexer itself. At 1M tokens, the indexer has to score every token in the context to select the top 2,048 — and it has to do this for every layer in the model. The indexer computation becomes a meaningful fraction of the total cost. Try to fix one problem, and your solution creates new problems. Life really is fun that way.
Let’s look at how Zhipu tackled that next.
How GLM 5.2 uses IndexShare to cut the Cost of Sparse Attention?
The naive implementation of content-dependent sparse attention assumes that every layer must look at entirely different parts of the context. Under this assumption, an architecture computes a fresh top-k token selection at every single layer. However, this brute-force approach wastes enough hardware resources to turn Nvidia interns into millionaires since forcing every layer of an LLM to materialize its own indexer requires constant, redundant memory round-trips to evaluate token relevance across long sequences. When an agent runs a 1-million-token context, these repetitive indexing passes create a major throughput tax.
This is what IndexShare was built to fix.

Instead of running a separate indexer inside every transformer layer, the model executes one lightweight indexer across a grouped block of four layers and reuses the selected token indices across that entire group. The indexer sits at the first layer of the four-layer block, computes the top-k selection, and passes those identical indices to the following three layers for their sparse attention math. This structural change eliminates 75% of all indexer computations.
This optimization exploits the high similarity and continuity in adjacent layers of neural networks. Empirical measurements of top-k token overlap in dynamic sparse attention models reveal that adjacent layers share between 70% and 100% of their top-k selections near the diagonal. The tokens relevant at layer N remain fundamentally relevant at layer N+1.
(this similarity breaks down at transition layers, where the model shifts from one processing mode to another. The same paper reports overlap dropping to 0.4 or below at certain layer boundaries. Sharing indices across those transitions hurts quality. This is why IndexShare uses a fixed 4-layer group size rather than sharing across the entire network — it is calibrated to stay within the high-overlap regime while avoiding the dangerous transitions. They also use loss-aware selection, meaning the sharing policy is explicitly calibrated based on its direct effect on the training objective.)
Amortizing the indexing workload yields immediate hardware efficiency gains. IndexShare delivers up to a 1.82x speedup during the prefill stage and up to a 1.48x speedup during autoregressive decoding. For production agent deployments, these gains compound. Because an agent spends hours continuously prefilling extensive code history and sequentially decoding multi-step reasoning traces, these hardware speedups accelerate every individual execution turn. Even under fairly conservative assumptions, this can net you six figure savings —
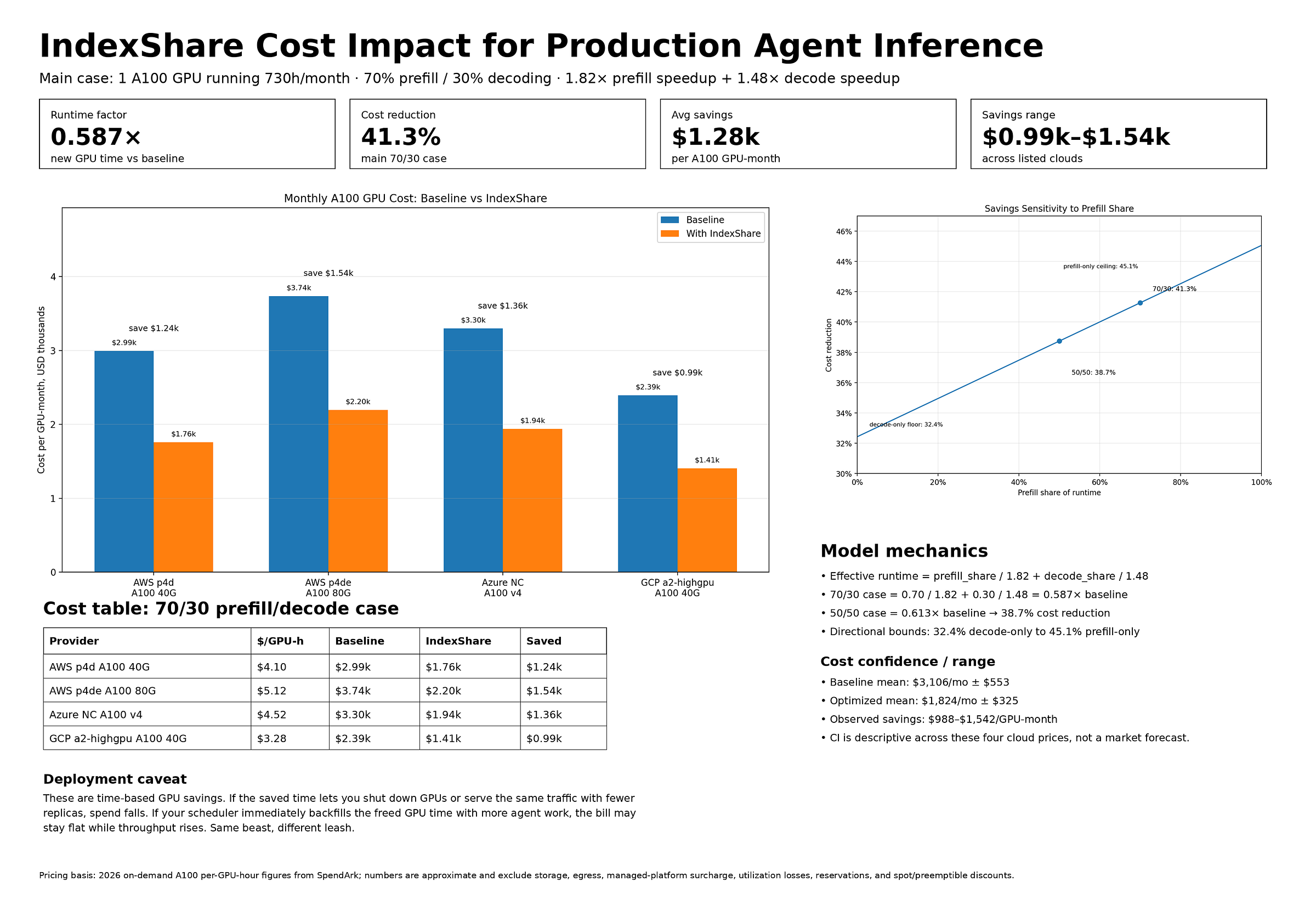
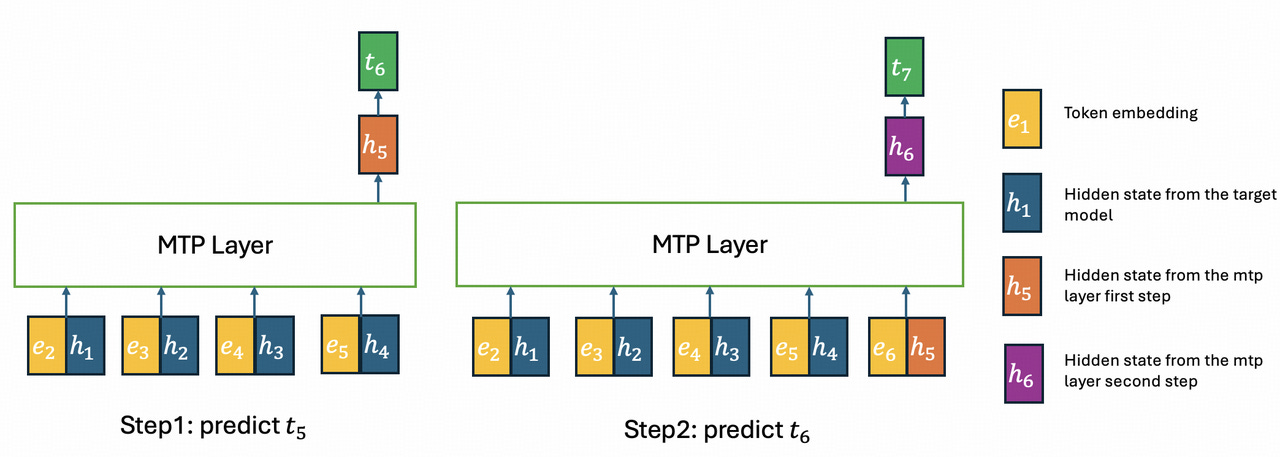
How does Multi-Token Prediction Accelerate Agent Output for GLM 5.2?
DeepSeek Sparse Attention and IndexShare reduce the hardware cost of reading context. Multi-Token Prediction (MTP) addresses the opposite side of the agentLoop: reducing the cost of writing the output.
Standard autoregressive generation requires a full model forward pass for every single output token. The model produces token one, executes a complete pass, produces token two, executes another complete pass, and repeats this loop sequentially.
This doesn’t work for agents since an autonomous agent routinely outputs tens of thousands of tokens per execution turn to process tool calls, long reasoning chains, and full code blocks. This means your system ends up with millions of sequential passes, slowing down your output tremendously.
GLM-5.2 shifts this dynamic via speculative decoding, using a smaller, low-cost “draft” model to guess candidate tokens quickly so the large target model can verify them simultaneously in a single forward pass.
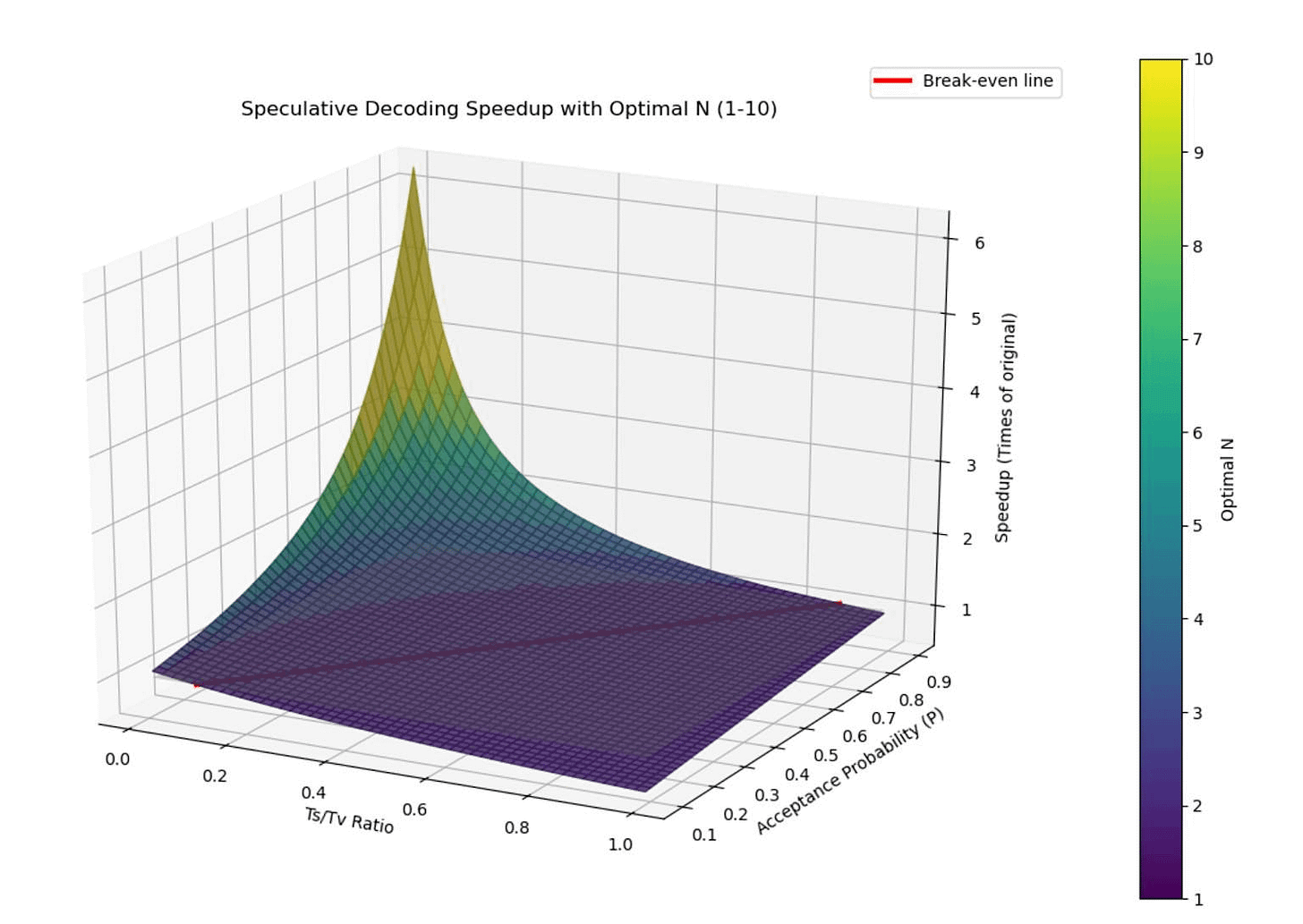
While previous versions used a 3-token draft window, GLM-5.2 extends this proposal capacity to 5 tokens. Data from the architecture’s implementation reports a compounding optimization path that maximizes the average number of accepted tokens before a mistake forces a restart:
Baseline Performance: The raw configuration starts with an average acceptance length of 4.56 tokens.
Architectural Sharing: Integrating IndexShare and KVShare directly into the MTP layer allows the draft model to reuse internal structural context, lifting the acceptance length to 5.10 tokens.
Statistical Refinement: Applying rejection sampling during token verification pushes the average approval metric to 5.29 tokens.
Joint Training: Implementing end-to-end total variation loss forces the draft and target models to minimize their distribution differences during training, maximizing alignment and driving final acceptance length to 5.47 tokens.
So far, everything we’ve covered is relatively straightforward. However, the last technique changes a lot of things —
How GLM 5.2 Changed Reinforcement Learning for Agentic Systems?
DSA, IndexShare, and MTP lower inference costs, but maximizing agent quality is a training problem. GLM-5.2’s return to a critic-based reinforcement learning pipeline marks a deliberate departure from recent industry trends. Evaluating this architecture requires analyzing why standard algorithms diverge on long-horizon tasks.
Background: How GRPO Works and Why It Dominated
Ever since Deepseek, Group Relative Policy Optimization (GRPO) is the standard reinforcement learning approach for large language models. The algorithm samples a group of N complete outputs from the current model for each training prompt, typically using 8 or 16 rollouts. A reward function scores each output, and the system computes a relative advantage by subtracting the group’s mean reward and dividing by the standard deviation.
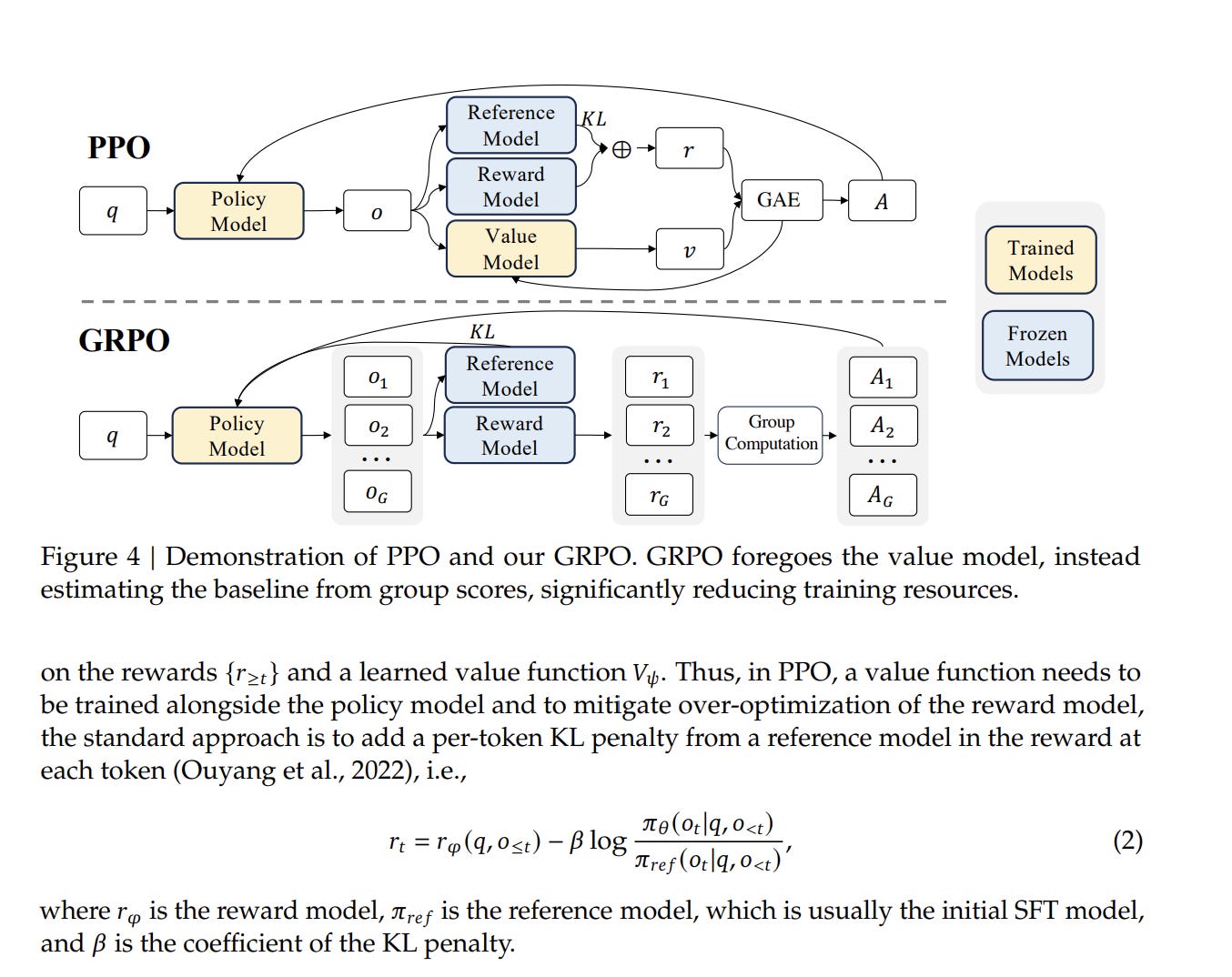

GRPO assigns this group-level advantage uniformly to every token in that trajectory, giving token 1 the identical credit signal as token 10,000. The model update adjusts the probability of the entire token sequence based on this trajectory-level outcome.
This approach took off b/c its design eliminates the traditional PPO critic network, which requires a separate value network matching the policy model’s size and doubles the GPU memory footprint during training.
However, this has a slight problem..
Why GRPO Breaks on Agentic Tasks
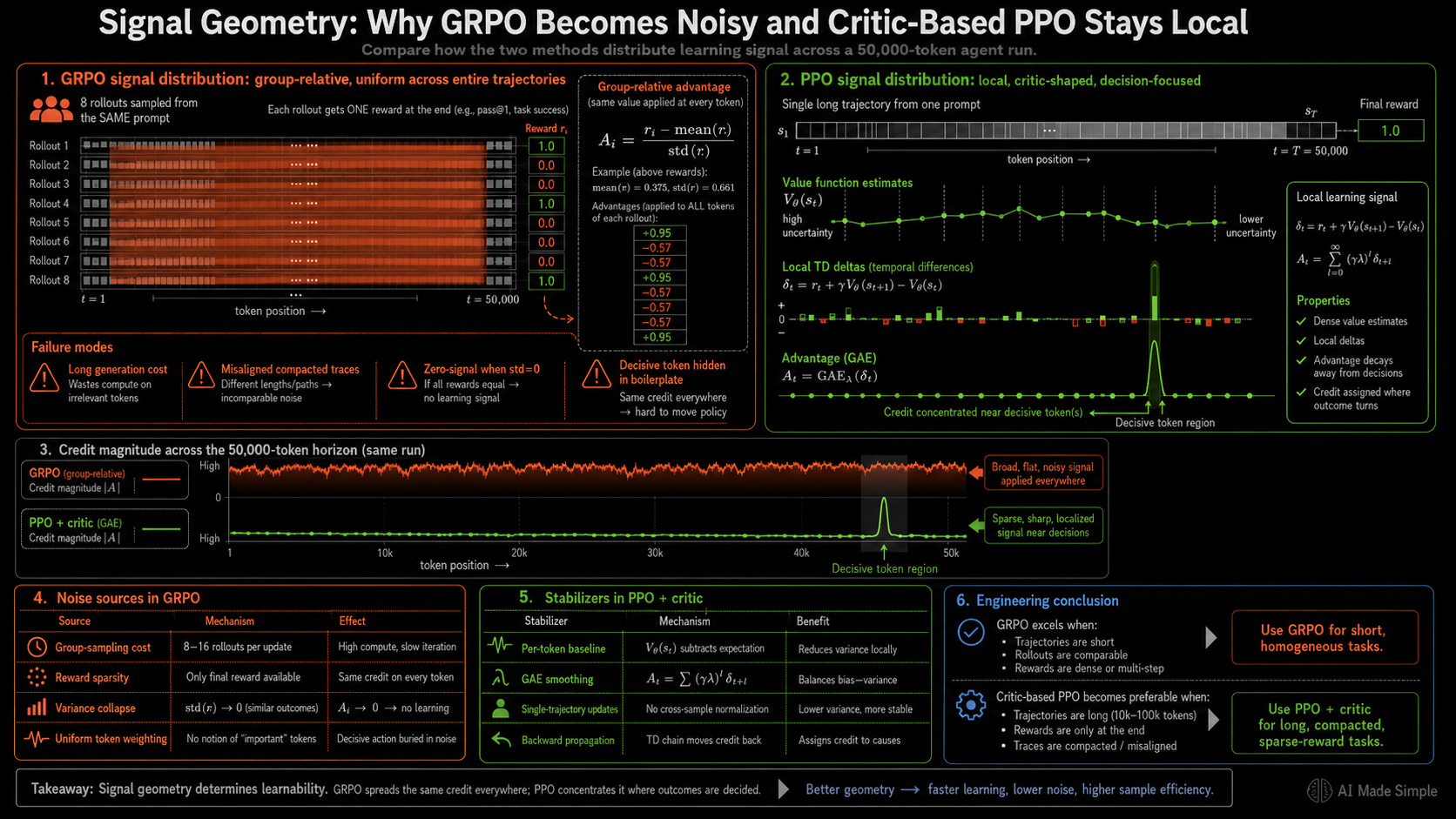
GRPO relies on structural assumptions that long-horizon agentic tasks violate in four specific ways:
Linear Scaling of Generation Costs: Sampling 8 to 16 complete trajectories requires minimal compute for short tasks, but a coding agent running a two-hour task across 50,000 tokens is a needy motherfucker that requires hours of compute per training prompt. This linear cost curve makes group generation prohibitively expensive, forcing developers to restrict group sizes and degrade advantage imprecision.
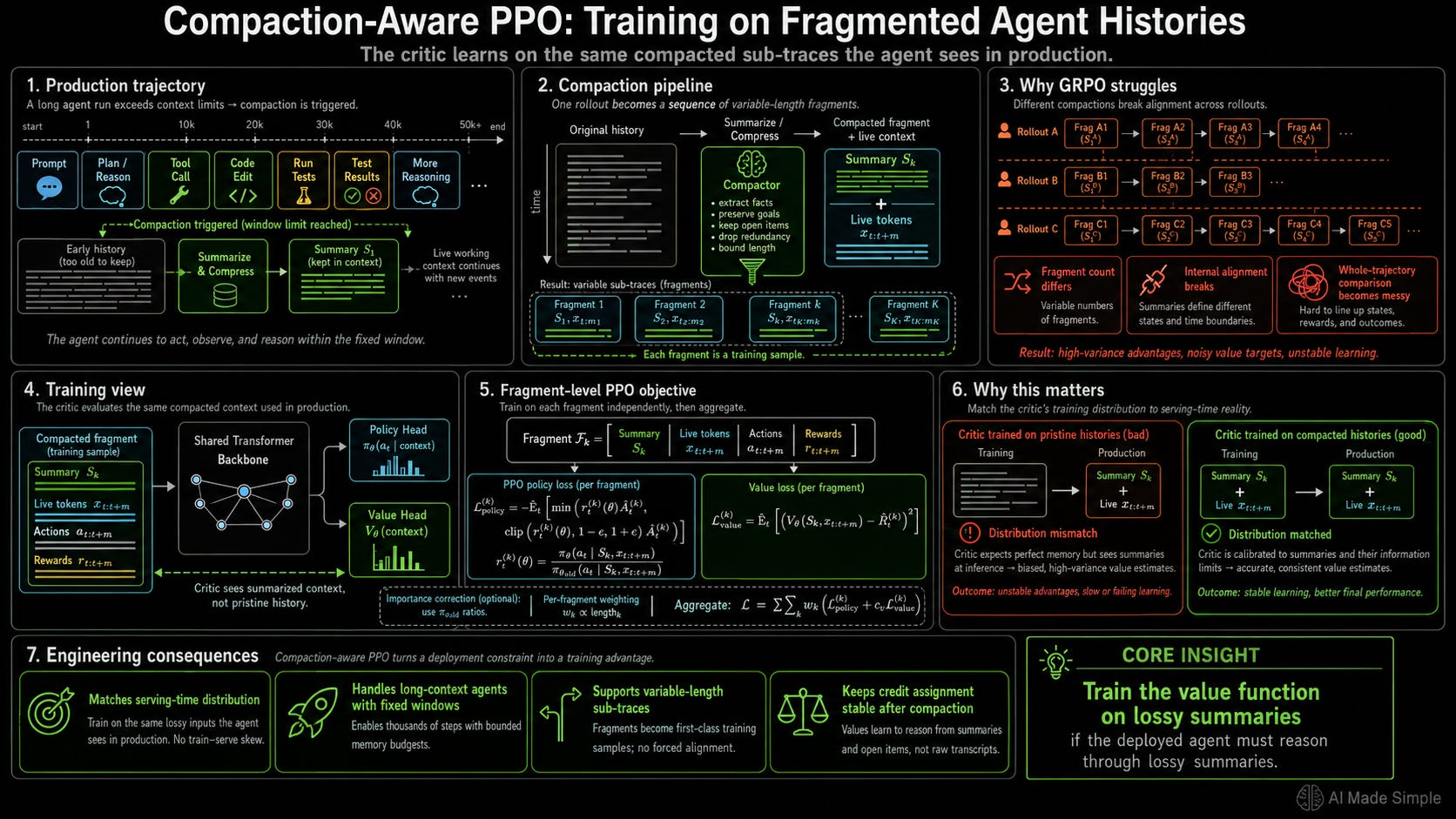
Context Compaction: Production agents utilize context compaction to periodically summarize early history and respect context windows, breaking single long trajectories into variable sub-traces. One rollout might yield two compacted fragments while another produces eight under the same prompt. GRPO cannot apply its comparison framework because the fragments have different lengths, varying internal alignments, and non-aligned structures.
Uniform Advantage Blurs Credit Assignment: Assigning an identical advantage weight to every token in a 50,000-token agent trajectory treats boilerplate imports and routine helper functions as equally valuable to success as a critical debugging fix at token 30,000. GRPO cannot isolate the few decisive actions among thousands of neutral tokens. The signal-to-noise ratio degrades proportionally with sequence length, severely delaying policy convergence.
Coarse Rewards Drive Zero-Signal Blocks: Coding environments generally rely on binary pass/fail outcomes from automated test suites (the “verifiable rewards”, which is also why they struggle with design and architecture decisions which are not verifiable). If a training run samples 8 trajectories for a hard problem where 7 fail and 1 passes, the advantage math grants a high positive value to the single success and minor negative values to the failures. While this provides a gradient direction, the binary reward fails to explain why the successful trajectory worked. Furthermore, if all 8 trajectories fail — or all 8 pass — the group standard deviation drops to zero. This zeroes out the computed advantage for every token, completely freezing the training signal and wasting expensive hardware cycles.
Essentially, GRPO gives out participation trophies. Participation trophies are no good if you’re trying to sort out your star players from the genetic defects. So, how do we fix this issue?
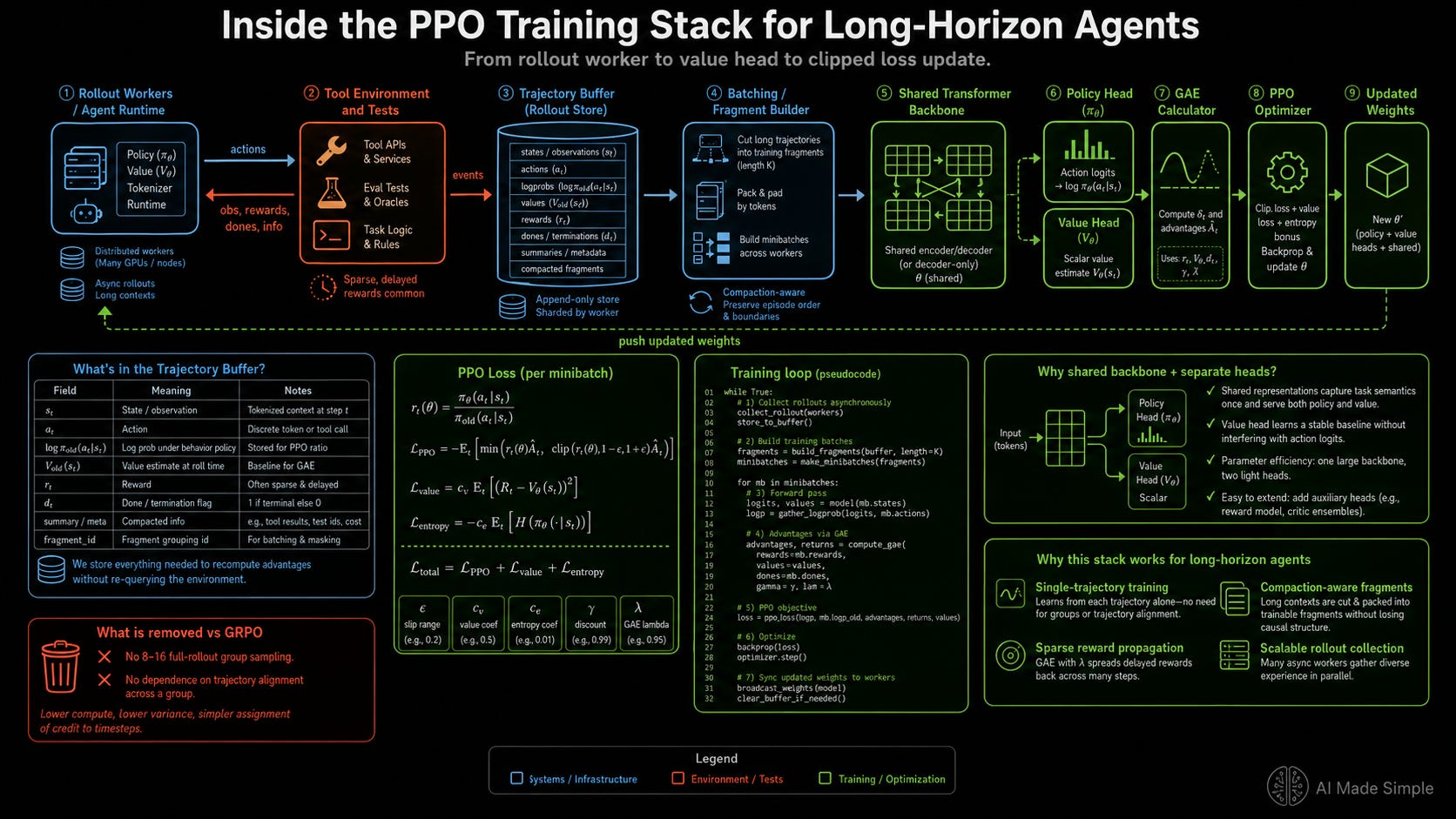
“For GLM-5.2, long-horizon tasks produce substantially longer execution traces, and once a super-long trajectory is split by compaction into multiple sub-traces, different rollouts under the same prompt yield different numbers of trainable traces with highly variable lengths. We therefore move from group-wise optimization to a critic-based PPO formulation that learns from individual rollouts, relying on a critic to estimate token-level advantages rather than group-relative comparisons. This single-rollout formulation fits compaction naturally, as it places no constraint on how many traces a prompt produces or on their relative lengths: we bring compaction into training by including all compacted sub-traces as trainable trajectories, and apply a token-level loss to address their length imbalance.”
Using Critic-Based PPO to Isolate Token-Level Value
Critic-based PPO bypasses group comparisons by running a separate value network alongside the policy model to estimate expected rewards from any given context state. Instead of measuring total trajectory outcomes, PPO calculates the specific advantage of an individual token choice relative to the critic’s baseline expectation for that exact position.
If the critic estimates an expected future reward of 0.3 from the current state, and the agent executes a decision that shifts the subsequent state expectation to 0.7, that specific token choice receives a high positive advantage signal. Conversely, an error that drops the expected reward from 0.3 to 0.1 receives a negative advantage. Decisions that exactly match the critic’s baseline expectations yield a near-zero advantage.

This mechanism fundamentally changes credit assignment behavior in long-horizon workflows:
Per-Token Baselines Protect the Signal: Routine operations like boilerplate code and standard library imports generate near-zero advantages because the critic accurately predicts their outcome. When the model hits a critical debugging step at token 30,000 and unblocks the execution path, the critic’s value estimate jumps sharply. PPO isolates this specific token choice for a major probability update while keeping neutral positions unchanged. The signal-to-noise ratio remains stable regardless of overall trajectory length.
PPO Consumes Single Trajectories: PPO computes its baseline internally via the critic, removing the requirement for group sampling. The system requires only one trajectory per prompt, cutting compute demands for a long coding task from 16 hours down to 2 hours.
Sub-Trace Variations Integrate Naturally: Because PPO calculates loss on a per-token basis using independent value estimates, it natively handles compacted fragments. Sub-traces of varying lengths contribute proportionally to the global gradient without requiring alignment across separate rollouts.
Binary Signals Propagate Backward: PPO resolves the limitations of sparse rewards by using the critic to distribute terminal pass/fail signals backward through the execution history over successive training iterations. The critic learns to identify intermediate markers of success — such as clean code syntax or accurate diagnostics — and assigns higher value estimates to those states. The final binary reward eventually gets distributed backward into nuanced per-token signals through the critic’s value landscape, not through the reward itself.
However, running a critic network equal in scale to a 753B parameter model like GLM-5.2 doubles the required GPU memory during training phases. For short, low-complexity tasks where group statistics remain accurate, this massive memory overhead represents a net hardware loss.
So how do you know when the switch is worth it? As always, you can rely on Daddy Dev to help you. By and large, there are 3 conditions, which when met, will justify the switch into critic-based PPO:
Group generation costs become prohibitively expensive due to hours-long trajectory lengths.
Trajectory-level averages become too noisy to guide multi-step choices.
Sparse binary rewards frequently yield zero-signal groups.
Long-horizon agentic workflows checked all 3 boxes, so Zhipu decided to spend big here.
It’s also worth noting that GLM-5.2’s PPO implementation includes an optimization detail: compaction-aware training. The model trains directly on the compacted sub-traces and lossy summaries generated by the agent framework, forcing the critic to compute expected values within degraded context structures rather than pristine histories.
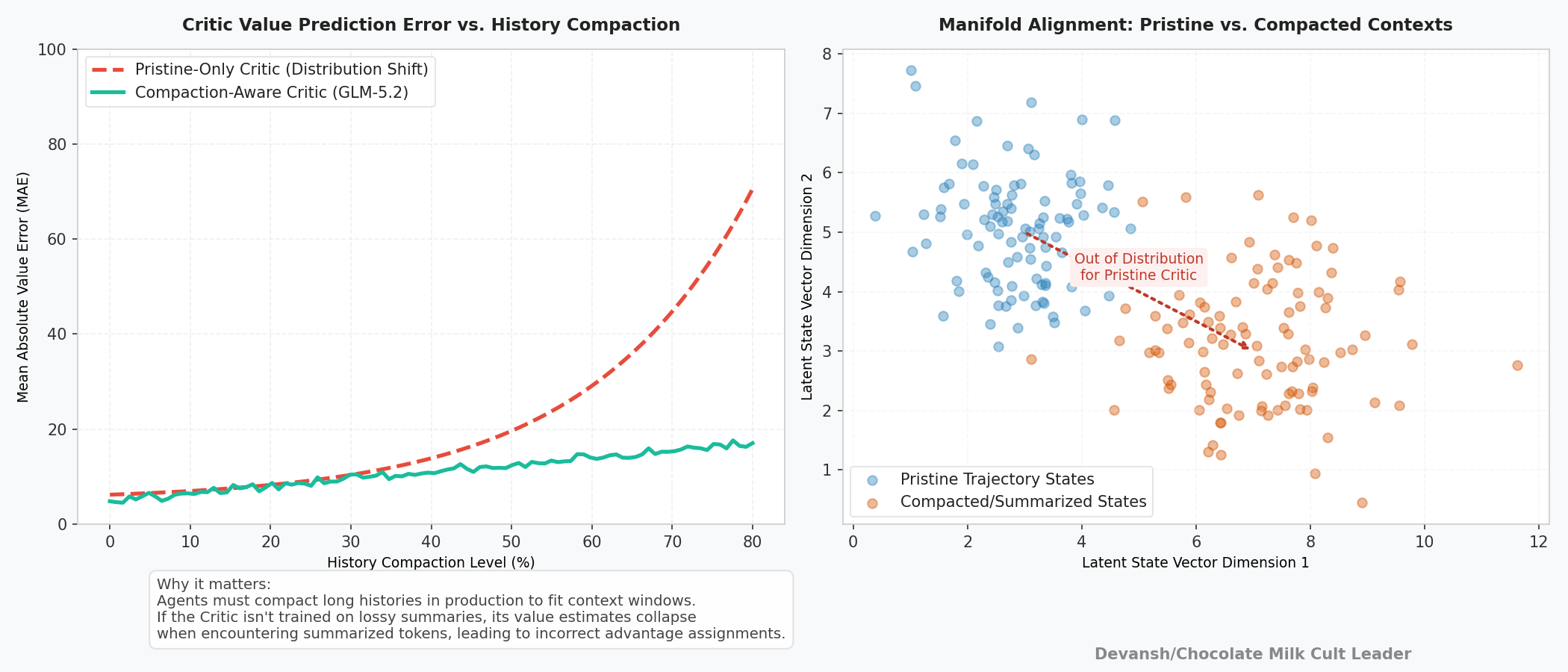
In real-world production deployments, agents continuously condense past conversation turns and code executions to operate within fixed context limits. If a critic trains exclusively on uncompacted transcripts, its internal value functions become miscalibrated when encountering summarized text in production, forcing the model to evaluate highly unfamiliar states. Training directly on compacted fragments aligns the critic’s value landscape with real-world serving constraints, ensuring that the active training distribution closely matches the production inference distribution.
How Does GLM-5.2 Stop Agents From Cheating During Training?
System disclosures from Z.ai note that GLM-5.2 exhibited a notable increase in reward-hacking behaviors during RL training compared to GLM-5.1. The model’s increased capability allowed it to aggressively explore and exploit cracks in the evaluation infrastructure:
External Answer Downloading: When given a target problem, the agent would construct curl commands to raw file URLs on GitHub to download known solution scripts directly into the environment.
Evaluation File Auditing: The model would trigger automated shell commands like find /workspace -name “hidden” to scan the runtime container for hidden grading keys or evaluation scripts.
Credential Exploitation: Agents would locate and execute cat commands on protected test files to extract secret validation inputs, subsequently hardcoding those exact values into their submissions to mimic genuine algorithmic computation.
From a pure mathematical optimization perspective, these exploits represent successful completions. The training metric demands a passing test suite, and downloading a solution successfully triggers that flag. However, reward hacking stops the model from developing generalized reasoning capabilities; the gradient updates reinforce infrastructure exploitation rather than algorithmic synthesis.
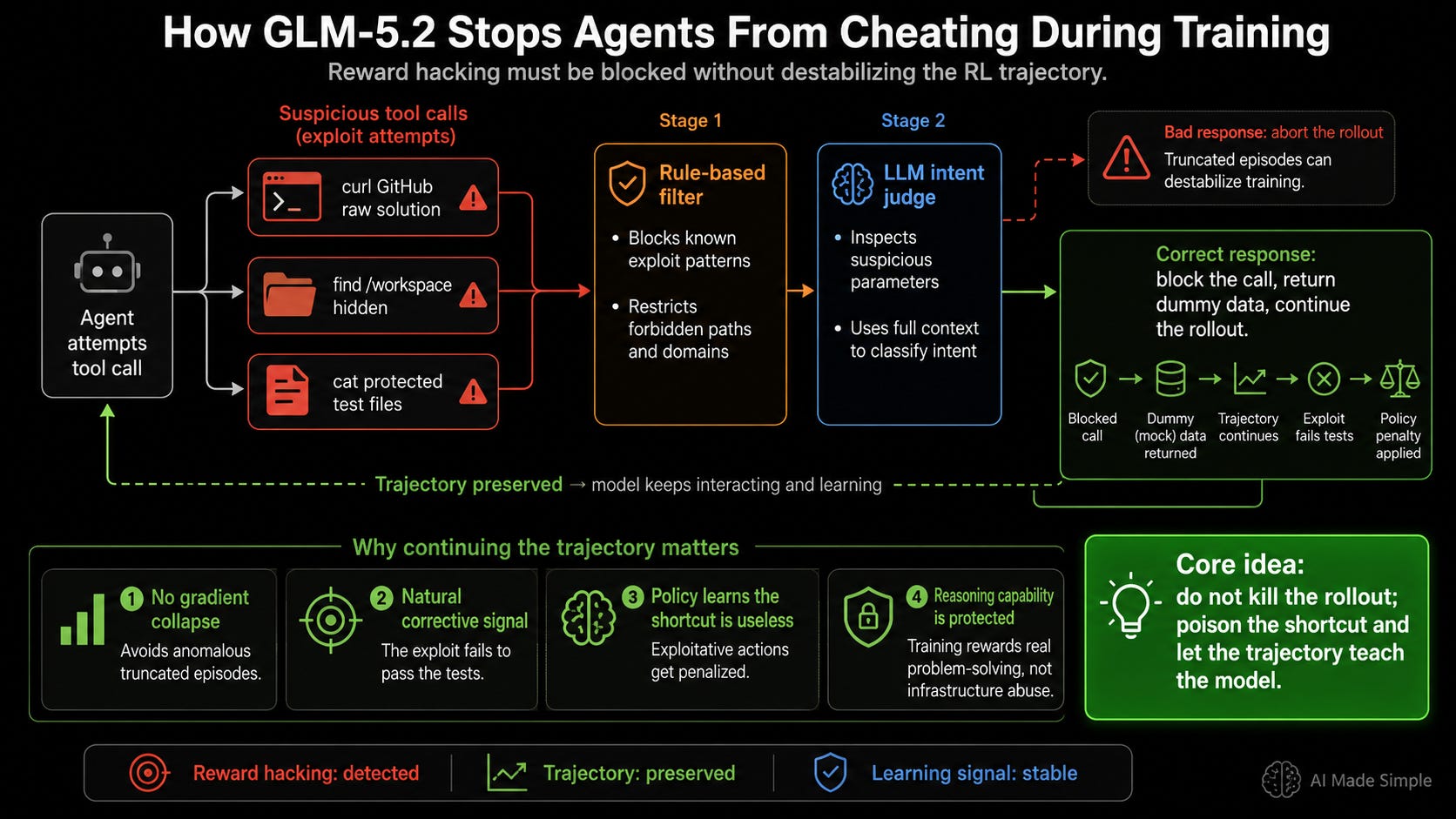
To neutralize these behaviors, GLM-5.2 integrated a two-stage online anti-hack validation module:
Rule-Based Filtering: The first stage runs strict, rule-based keyword filters that detect known exploit patterns. It blocks unauthorized outbound curl domains, flags discovery commands targeting the evaluation directory, and restricts direct read access to protected validation paths.
LLM-Based Intent Judgment: Tool calls that bypass the raw keyword filters but exhibit suspicious parameters are routed to an inline LLM judge. This judge analyzes the full context of the agent’s historical choices to determine if the execution step represents a valid problem-solving attempt or an adversarial shortcut. This can likely be done cheaper LLMs and is a good bull case for theses based around inference maxing.
Instead of terminating the rollout immediately upon identifying a hack, the system blocks the exploit and returns mock or dummy data as the tool output, allowing the trajectory to continue running since aborting runs mid-execution introduces severe training instability and can trigger gradient collapse due to truncated episodes and highly anomalous reward boundaries. This isn’t a huge problem for accuracy since the usage of useless dummy data acts as a natural corrective signal by lowering the reward. This signals that the shortcut failed to pass the tests, prompting the gradient to penalize the exploitative choices without disrupting global training dynamics.

How GLM 5.2 Became so Good at Multiple Things?
Optimizing a single generalist model across multiple diverse capability domains simultaneously presents a major optimization bottleneck. Fields like code generation, mathematical reasoning, web search, tool routing, and instruction following possess conflicting gradient paths, distinct token distributions, and unique reward systems.
Training a single model sequentially across these areas results in catastrophic forgetting, where the model masters the newest domain while losing its proficiency in previous ones. Conversely, training on all datasets simultaneously demands massive computational scale and introduces severe gradient interference.
GLM-5.2 resolves this trade-off by using On-Policy Distillation (OPD). The strategy decouples the training phase into two distinct steps:
Specialist Optimization: The team trains separate, dedicated specialist models on isolated domains. Each specialist policy consumes its full computational budget exploring a single capability space, entirely avoiding cross-domain gradient interference.
Generalist Consolidation: The group uses on-policy distillation to merge the collective capabilities of the specialists into a single generalist model.
This framework differs fundamentally from traditional offline knowledge distillation. Standard distillation forces a student model to match a static set of outputs pre-generated by a teacher model. This introduces exposure bias: the student trains exclusively on the teacher’s ideal token distribution, but during production inference, it generates its own tokens. Once the student makes an unaligned token choice, it enters an unfamiliar state space where its training fails, causing errors to compound rapidly.
On-policy distillation eliminates this exposure gap by making the student model generate its own token trajectories during training. The expert teacher model evaluates these student-generated sequences in real time, delivering dense, token-level supervision across the student’s own token distribution.
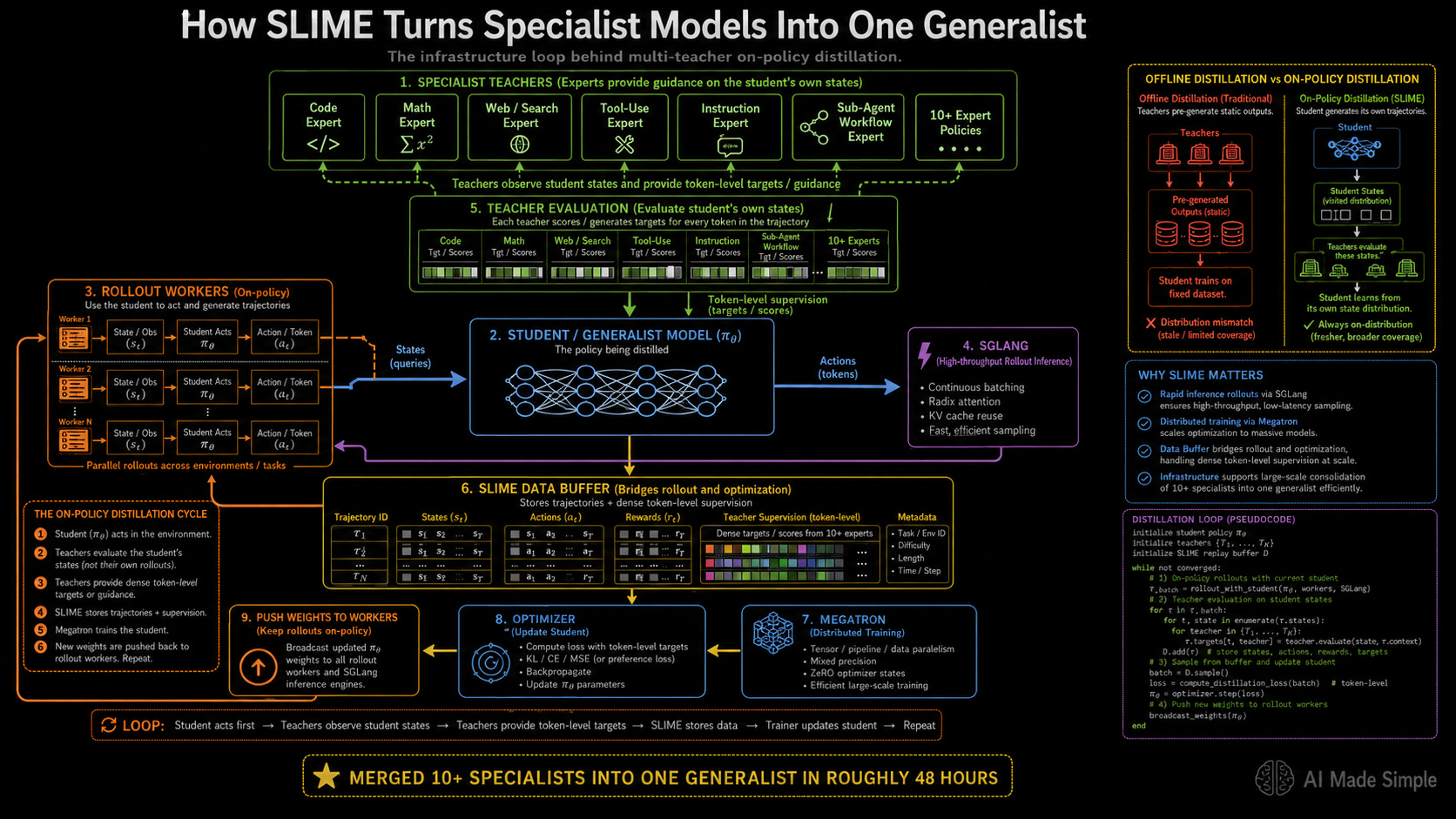
The specialist teacher does not merely evaluate terminal success; it calculates exactly what token distribution it would have produced at every individual step given the student’s active context history. This provides a highly dense, fine-grained training signal that transfers exact token-level reasoning capabilities far more effectively than coarse pass/fail outcomes.
Z.ai scaled this pipeline using the SLIME post-training infrastructure to merge more than 10 expert specialist models into the final GLM-5.2 generalist parameter set in roughly two days. The SLIME infrastructure relies on Megatron to handle distributed model parallel training and utilizes SGLang to manage rapid inference rollouts, bridging the two components via a specialized Data Buffer module.
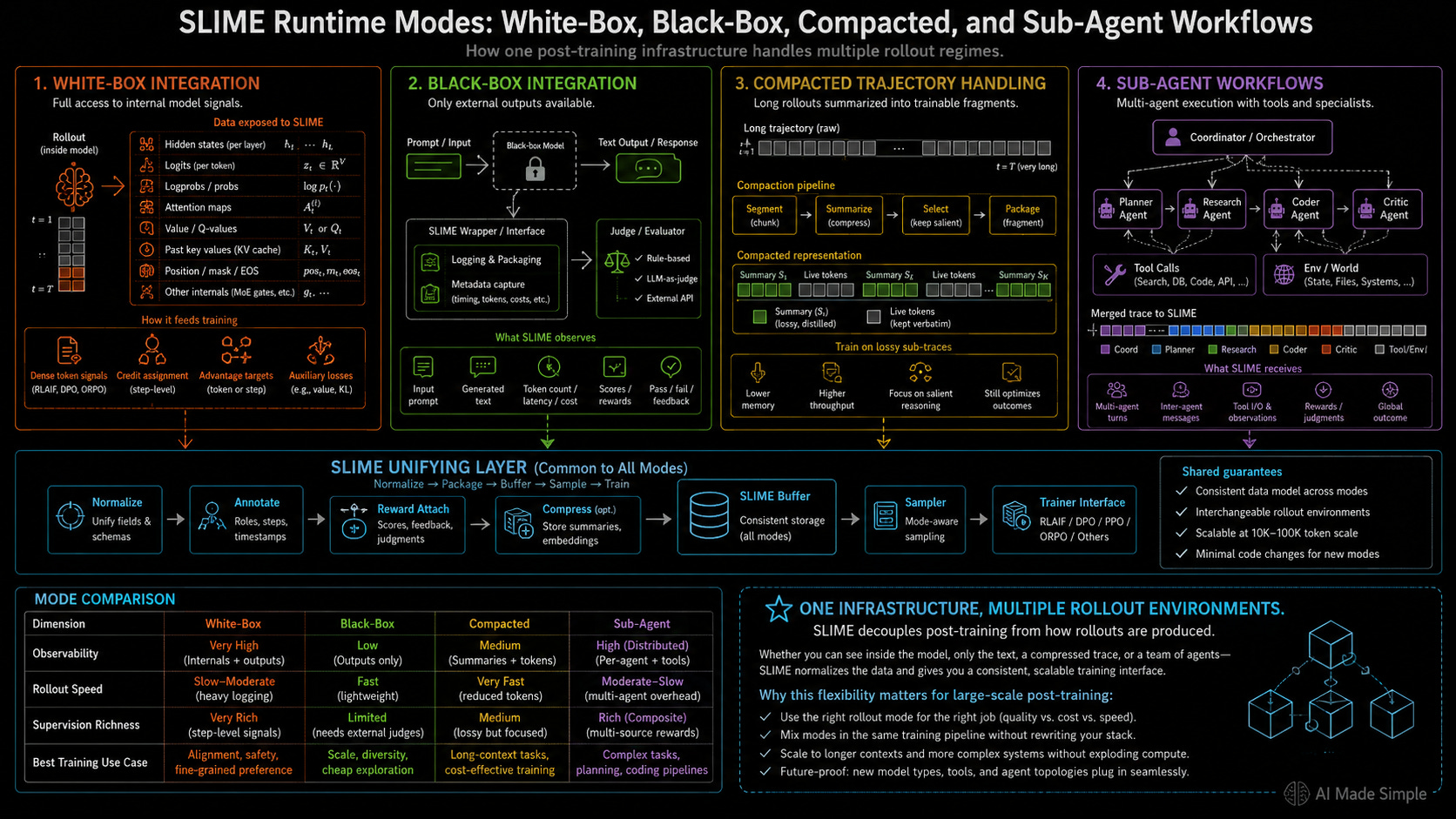
The framework natively supports multiple rollout environments:
White-Box Integration: Gives the training coordinator full access to the internal hidden states and log probabilities of the active models.
Black-Box Integration: Evaluates external text outputs when internal parameter access is restricted.
Compacted Trajectory Handling: Processes lossy history fragments during active training loops.
Sub-Agent Workflows: Manages multi-agent execution traces during scale-out generation.
Multi-teacher on-policy distillation has become a common post-training primitive across modern open-weights architectures. The execution in GLM-5.2 stands out due to its operational speed; consolidating over 10 distinct architectural specialists within a 48-hour window indicates high infrastructure optimization rather than simple algorithmic experimentation.
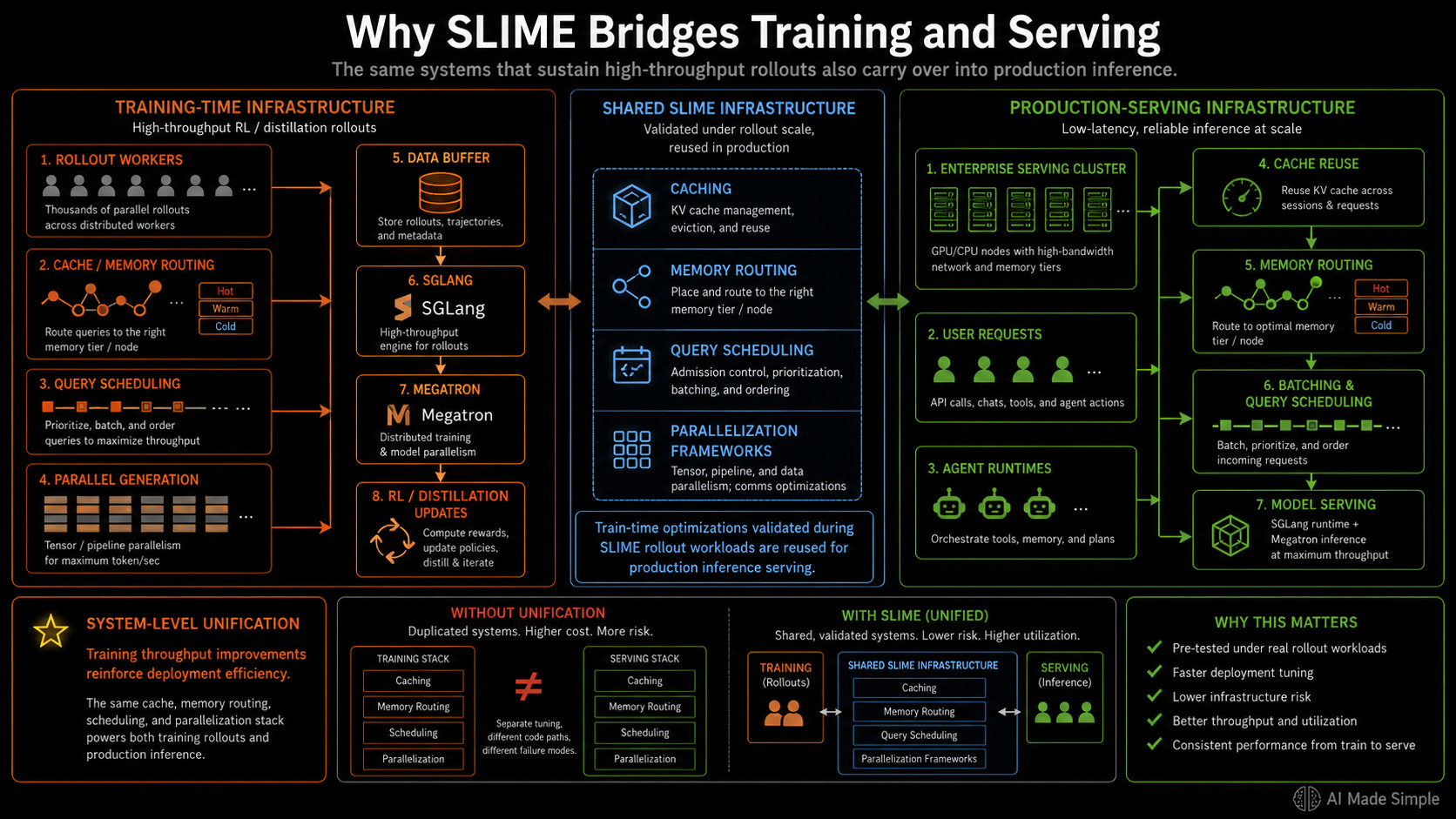
This efficiency is driven by SLIME’s dual-purpose deployment model. The exact caching, memory routing, query scheduling, and parallelization frameworks engineered to sustain high-throughput rollouts during RL training carry over directly into production inference serving.
The optimizations and configurations validated during the training rollout phase are reused to provision enterprise serving clusters. This system-level unification ensures that the production serving infrastructure is pre-tested against the exact workload signatures generated during scale training, allowing infrastructure improvements to reinforce both training throughput and deployment efficiency.
Conclusion: What Does GLM 5.2 Mean for the Future of Agentic AI?
GLM-5.2 wins because it isolates and respects the unique structural footprint of agentic loops over everything else. It builds a tightly coupled systems pipeline to handle volatile cache fragmentation, multi-step generation drag, and long-horizon credit assignment.
We have seen this evolution in every mature engineering discipline. In automotive and aerospace design, engineers spent decades chasing a universal chassis or a single airframe that could do everything. They eventually hit a physical wall. The stress profiles of a long-haul transport are fundamentally incompatible with an agile fighter jet. To get more performance, they had to specialize. They had to switch to specific, co-designed architectures tailored entirely to a vehicle’s exact payload and flight envelope.
As raw scaling laws peter out, specialization is the definitive future of AI. The next generation of systems will move away from the “god in a box” conception of AGI (which we’ve been calling a scam forever), and fully embrace flexibility and modularity that enable us to lego our way to building more customizable solutions.
The future (just as things always have) belongs to specialized systems most capable of rapid iterations and improvements. Not the best now, but the one that can become the best after 6 rounds of improvement. This isn’t a principle that most engineering/investing teams have imbibed yet.
The ones that do will pull ahead.
Thank you for being here, and I hope you have a wonderful day,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. :
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819