
Why Some Startups Are Easy to Copy While Others Aren’t
What Apple, GitHub Copilot, and legal AI reveal about how incumbents lose paradigm shifts

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
Most people repeat the same line whenever a startup starts getting real traction: if the idea is good, the incumbents will just copy it and kill the company. Sometimes that’s true. A lot of the time, it isn’t.
Incumbents are very good at copying products that fit neatly into their existing logic. They are much worse at responding when the new thing requires them to change how the product works, how success is measured, and how teams inside the company are organized. That is the part people miss. The question is not just whether the startup has a good product. The question is whether the incumbent can adopt that product without breaking the assumptions that made the incumbent successful in the first place.

That is the lens for this article. I want to break down why some startups are easy to crush while others are much harder to absorb; why large companies often lose even when they have obvious structural advantages; and how these dynamics have played out across several important AI markets. We’ll start with the general framework, then work through diverse case studies in assistants, coding tools, and legal AI.
In this article, we will cover:
Why the standard “incumbents will just copy the startup” narrative breaks down so often in practice
How short-term incentives, organizational structure, and internal politics make incumbents worse at crossing into new paradigms
Why some startups are just improved versions of the old workflow, while others change the workflow itself
How to tell the difference between a company that is genuinely shifting the market and one that is just building a wrapper
Why Apple had many of the right assets for on-device AI and still failed to capture the shift
How the battle in AI coding moved from autocomplete, to delegation, to autonomous execution
Why each of those shifts changed what developers were actually valuing and paying for
What those patterns reveal about which kinds of AI companies are structurally positioned to win
Why the current generation of legal AI is built on a limited foundation
What a more defensible and more ambitious legal AI architecture looks like
Executive Highlights (tl;dr of the article)
The standard line — “if a startup has a good idea, incumbents will just copy it” — only works when the startup is improving the existing workflow. Incumbents are strong at copying wrappers, packaging, and incremental upgrades. They are much weaker when the new product changes the workflow itself, because competing then requires product, organizational, and cultural change rather than just feature matching.
That is why incumbents often lose paradigm shifts even when they have more money, talent, distribution, and trust. The problem is usually not intelligence; it is structure. Big companies are bad at crossing the short-term pain required to reach a better long-term system, especially when the new approach initially looks messier, riskier, or less aligned with what made the old system successful.
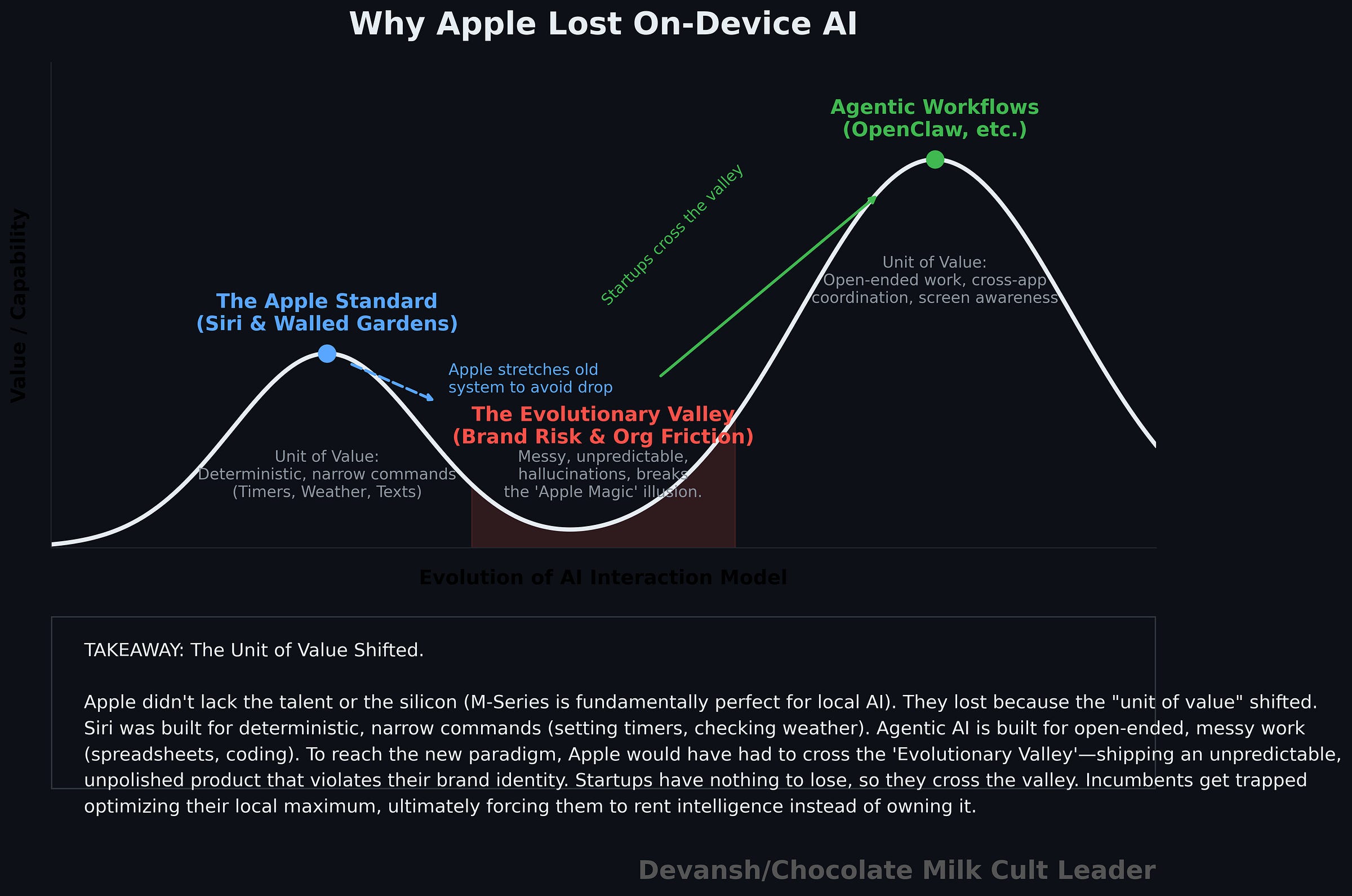
Apple is one example. It had the hardware, distribution, ecosystem, and user trust to dominate on-device AI, but it was built around a narrow assistant model. When the market shifted from command execution to open-ended work, Apple struggled to rebuild around that new logic and ended up leaning on outside model providers instead of defining the category itself.
The coding market shows the same pattern in faster motion. Copilot fit the old workflow and won the first phase. Cursor changed the value from autocomplete to higher-level delegation. Claude Code changed it again from delegation to autonomous execution. Each shift changed what developers were actually paying for, and each made the previous leader’s strengths less decisive.
The same lens applies to legal AI. The first wave won by making legal drudgery faster, but most current systems still rely on a limited stack: flat retrieval plus autoregressive generation. That works well enough for assistance tasks, but it starts to break when the problem requires structured reasoning, competing interpretations, and delayed commitment.
The weakness is straightforward: retrieval surfaces what looks similar, not always what actually governs; generation tends to commit too early to one path; and law lacks the clean external verification loops that make agentic systems work so well in coding. So simply adding more prompting, more fine-tuning, or more agent wrappers does not solve the core issue.
The next generation of legal AI will likely come from systems that change the underlying architecture, not just polish the current stack. That means exploring multiple reasoning paths before committing, and representing legal knowledge in a more structured way instead of flattening everything into one semantic space.
The broader point is simple: the easiest startups to kill are the ones that fit neatly inside the incumbent’s worldview. The dangerous ones are the startups that force a different workflow, a different product logic, and eventually a different company.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
1. Why Incumbents Fail to Outexecute Startups
The standard narrative — incumbents will copy existing good startups and starve the startups out — fails more often than the people quoting it are willing to admit. And when it does, people quote all kinds of reasons for the incumbent’s failure. However, the analysis is often wrong. There are several why the technical, political, and organizational reasons that hold back the incumbents from adopting the paradigm of the new-comer. Studying these gives us insight into three important learnings:
Why incumbents often fail to adapt to new era startups.
Why certain research paradigms become dominant.
What differentiates startups/approaches that truly disrupt the paradigm vs the interchangeable mediocrities that fail and do get packed by the incumbents?
Let’s kick it.
1.1 The Evolutionary Valley: Short-Term Pain Kills Innovation
Ever wondered why humans can’t go super saiyan or Bankai our way to greatness (drop your fav bankai below)? Even though they would objectively make our lives way better? The reason is an interesting biological concept called the Evolutionary Valley.
Any system — biological, technological, organizational — can see a higher peak ahead, but to reach it, it must first get worse. It must pass through a dip in performance, stability, or fitness before climbing to a superior design. In our example, the intermediate designs from base human to Bankai would require traversing human designs that have weaker immunities, require more energy, die earlier etc.
Evolution avoids these valleys because natural selection punishes anything that loses capability, even temporarily. Orgs have a similar tendency, especially in incumbents, where people are often more worried about internal politicking vs the survive or die struggles in startups (for any decision maker, there is more stable upside in maneuvering inside and not failing vs trying a big homerun and failing).
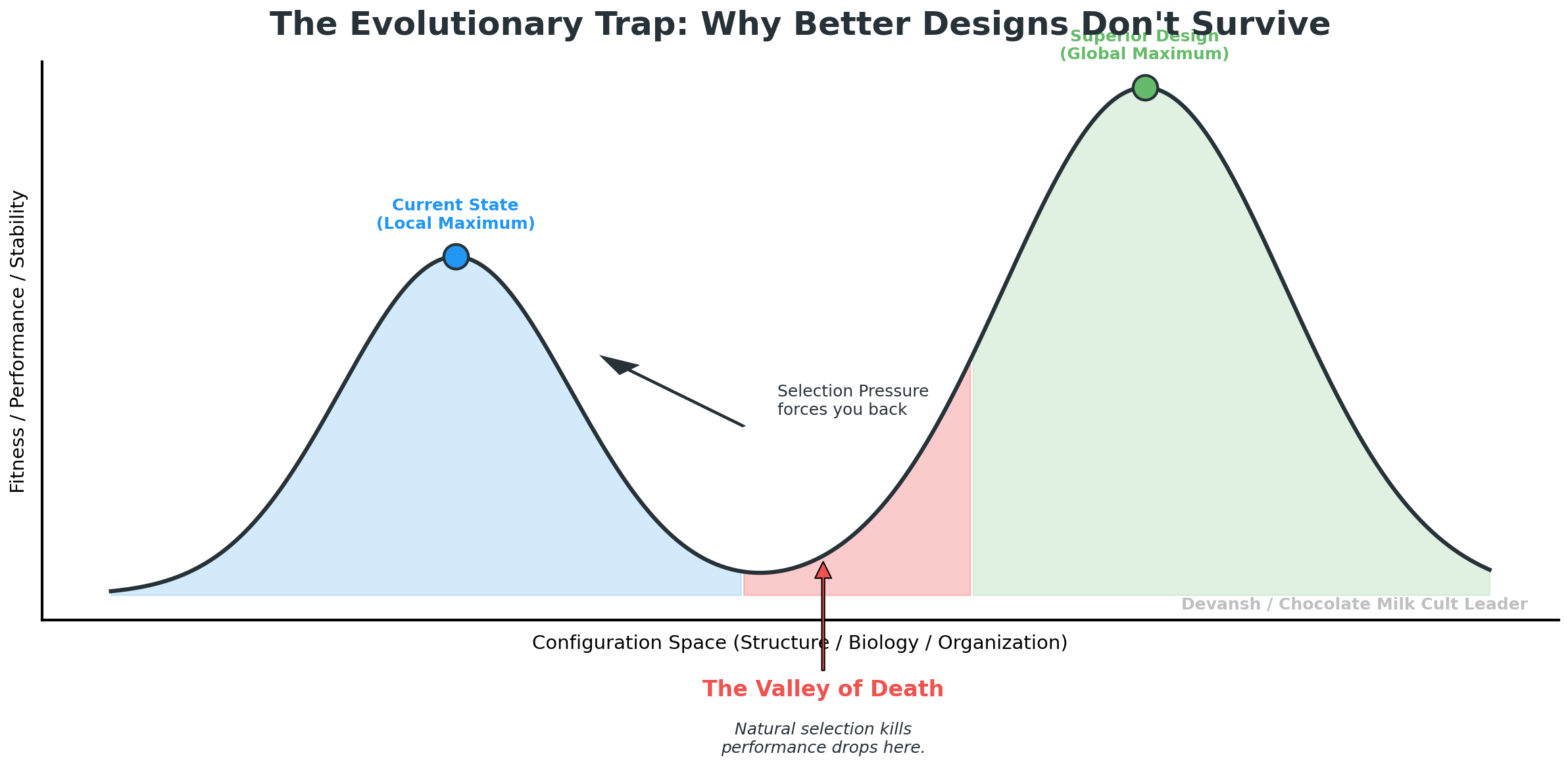
What happens when we scale this out across the org? People will optimize for stability over strategic risk, avoiding the valley. This becomes worse in many established incumbents which tend to implictly punish disruptions through:
Quarterly reviews and PIPs incentivizing a quick win culture
Annual budgets keeping things more stuck
Frequent reorganizations stopping a team from building something meaningful long-term through loss of key silod knowledge.
External departures making above worse.
A bureaucracy that requires so many layers of approval to pick a restaurant for a meal.
This is why so many great engineers/researchers leave these companies to begin with. They think in terms of absolute improvements and the frontiers of performance, not realizing that the path to that frontier is not viable for a group that reduces risk more than it seeks upside. This is also why communication is key for engineers, see our guide here, since it enables them to get buy in for their projects (see our guide here).
In other words icumbents don’t fail from incompetence; they fail because short-term pain outweighs future advantage.
1.2 Old “Units of Value” Lock Systems in Place
Products aren’t just features — they’re built around implicit assumptions (“units of value”). What does the system do? How should the user interact with this system? Every software system implicitly presents its thesis on what work is worth doing, what should be left to the users, and how the user will interact with their tool.
Paradigm shifts, however, aren’t upgrades; they’re resets. Claude Code changed the primary workflow from tab edits (Copilot) and IDE-assistance to making devs sit on the command line. Deeper than that, it changed the nature of code written (small changes to entire functionalities), the work being done (writing specs to hitting auto approve (or as some people like to pretend, reviewing)) and even what was possible (implementations within expertise to complete horizontal aspects where AI puts out slop in the other aspects). In many ways, Claude Code changed the success criteria for AI coding assistants, as we broke down here:

If you want to learn how to use Claude code better, See our guide to Claude Code here

Getting back to the point, disruptions change the units of value and how people interact with the work, forcing incumbents to abandon existing metrics, infrastructure, and team structures. Incumbents rarely commit to such drastic internal disruption. Instead, they stretch outdated systems as much as possible. No matter how much Copilot tries to imitate Agentic Development, they will always be limited there.
1.3 Conway’s Law: Companies Ship Their Org Chart
Conway’s Law states product design mirrors company structure. Existing teams, boundaries, and ownership patterns limit product evolution. New paradigms typically break these structures, forcing internal reorganizations that incumbents resist. The result is a struggle to adapt.
Conway’s Law is iconic so I’m not going to huff on too much about it, but it’s important enough to merit it’s own substructure. Once you learn it, you can’t unsee it anywhere.
1.4 How to Recognize Real Shifts vs “Wrappers”: A Simple Mental Model
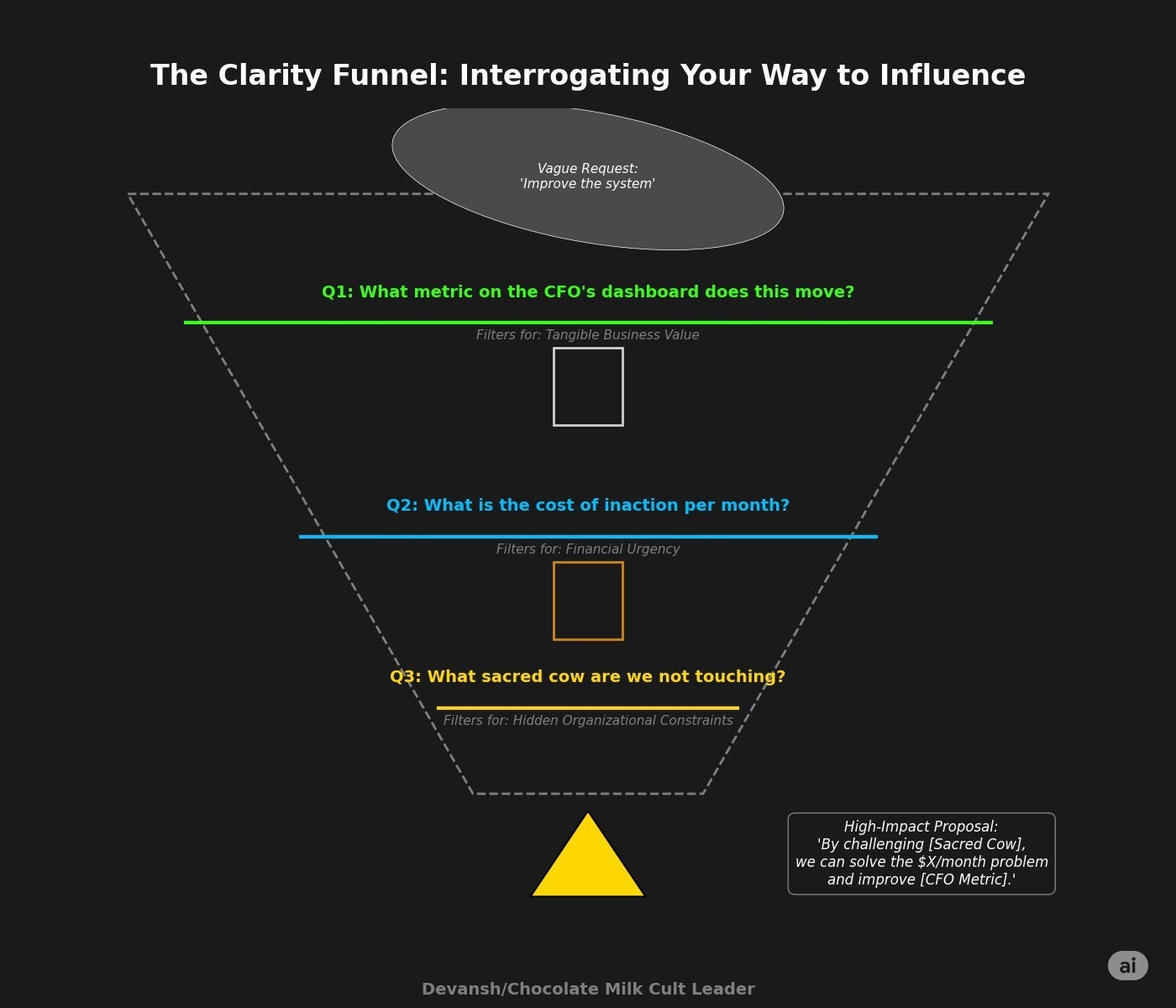
Incumbents copy easily but rarely disrupt themselves willingly. This brings us to the close of this section. Knowing what we do now, how can identify winners vs plays that will be crushed by incumbents? I would ask myself a simple question ( we use startups as an example since they are the clearest example, but it applies to research as well):
If a startup optimizes the existing workflow (a better “wrapper”), incumbents easily copy or acquire it since they have all the native advantages.
If a startup redefines workflow and user expectations (a “native” approach), incumbents resist, hesitate, and pay a premium later. In many cases, the change might be too much to copy effectively.
In reality, this sits on a spectrum. An AI companion startup, for example, might choose to commoditize intelligence rather than compete with incumbents there, and instead differentiate through persistent memory across sessions, context management for long conversations, edge voice deployment, and the surrounding engineering stack. The question isn’t what to build, but where to differentiate versus where to buy. Strong startups decide this from day one — and build accordingly.
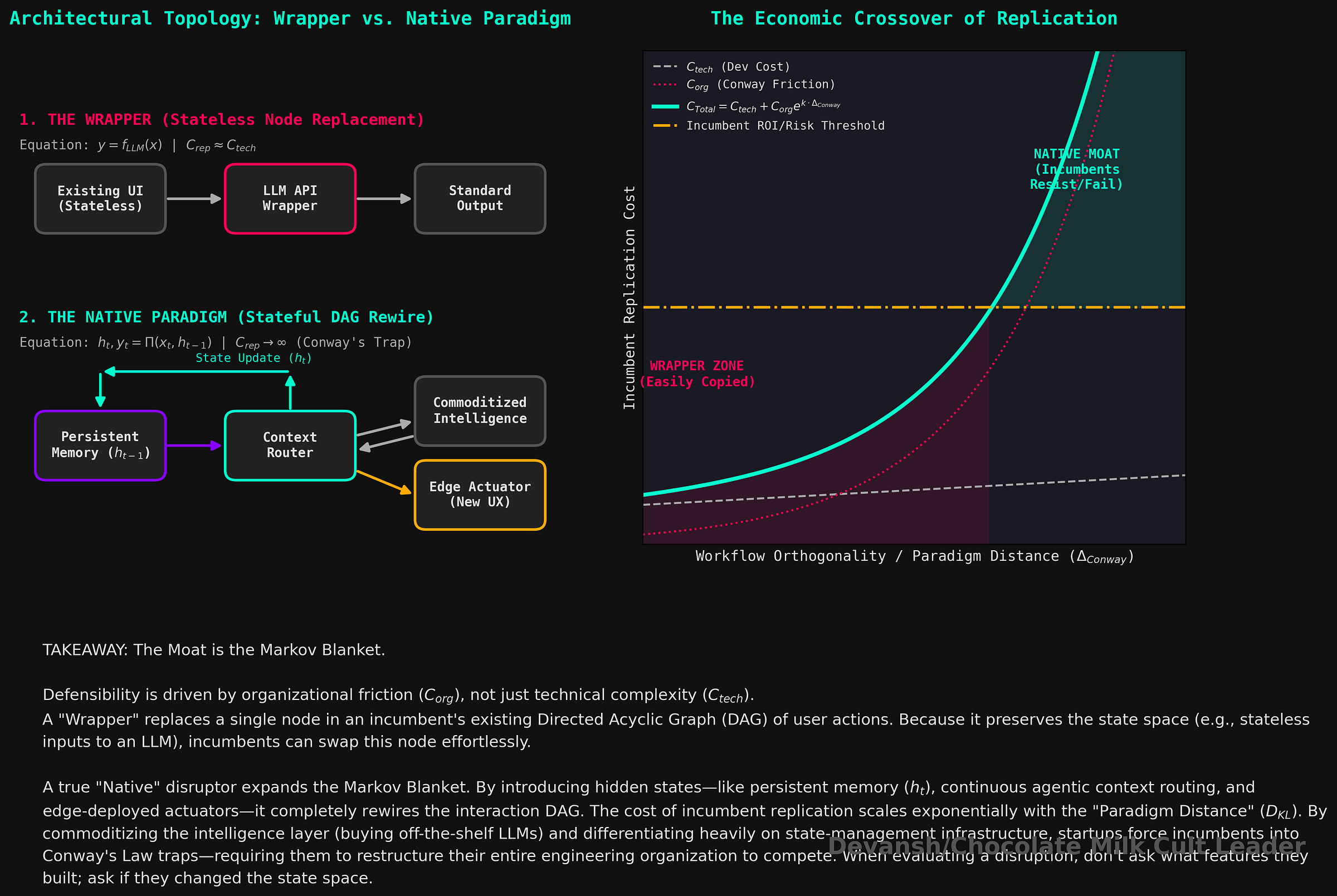
So when you’re looking at one of these, don’t overthink what they’ve built. Just look at how the interaction actually changes — what goes in, what comes out, where it starts to fall apart. That’s usually enough to tell if it’s something genuinely new or just a slightly cleaner version of what already exists. Similarly, if you’re a founder trying to evaluate your idea, ask yourself if you’re questioning a fundamental paradigm/reworking an interaction pattern, or if you’re simply trying to do something that exists better. The closer you are to the latter, the more at risk you will be against incumbents copying you.
Let’s look at how these factors play out through our various case studies.
2. Case Study 1: How Apple Lost On Device AI
2.1 Apple Started With Everything
Go back to the 2010s. When Siri dropped in 2011, Apple defined the baseline for AI-driven computing (it’s not a coincidence that so much scifi post Siri leans on Apple-esque aesthetics to communicate “advanced AI”; that’s how ingrained they became). They had every structural advantage: unmatched distribution, massive consumer trust, and eventually, the undisputed best custom silicon for local inference (M-series and A-series chips are practically begging to run local models). I remember having discussions about how Apple’s complete integration made their hardware much better for ML all the way back in 2017 (incidentally, our patented algorithm that beat Apple took advantage of this exact property; their system could not handle high noise environments when you took it out of the iPhone/perfect lab conditions).
Apple’s entire brand was built around making complicated technology feel natural to normal users. If you were sketching the ideal company to introduce AI-powered computing to the mass market, you would end up drawing Apple.
Now come back to 2026. Look at the booming spaces of personal AI assistants, on-device AI, and computer use systems automating spreadsheets/slides. 3 massively lucrative markets, all directly tied to what Siri was thought to eventually grow into. But look in these markets, and you’ll see that Apple isn’t even competing. In fact, in one of these spaces, they had to open up their infamous walled garden and pay their competitors.
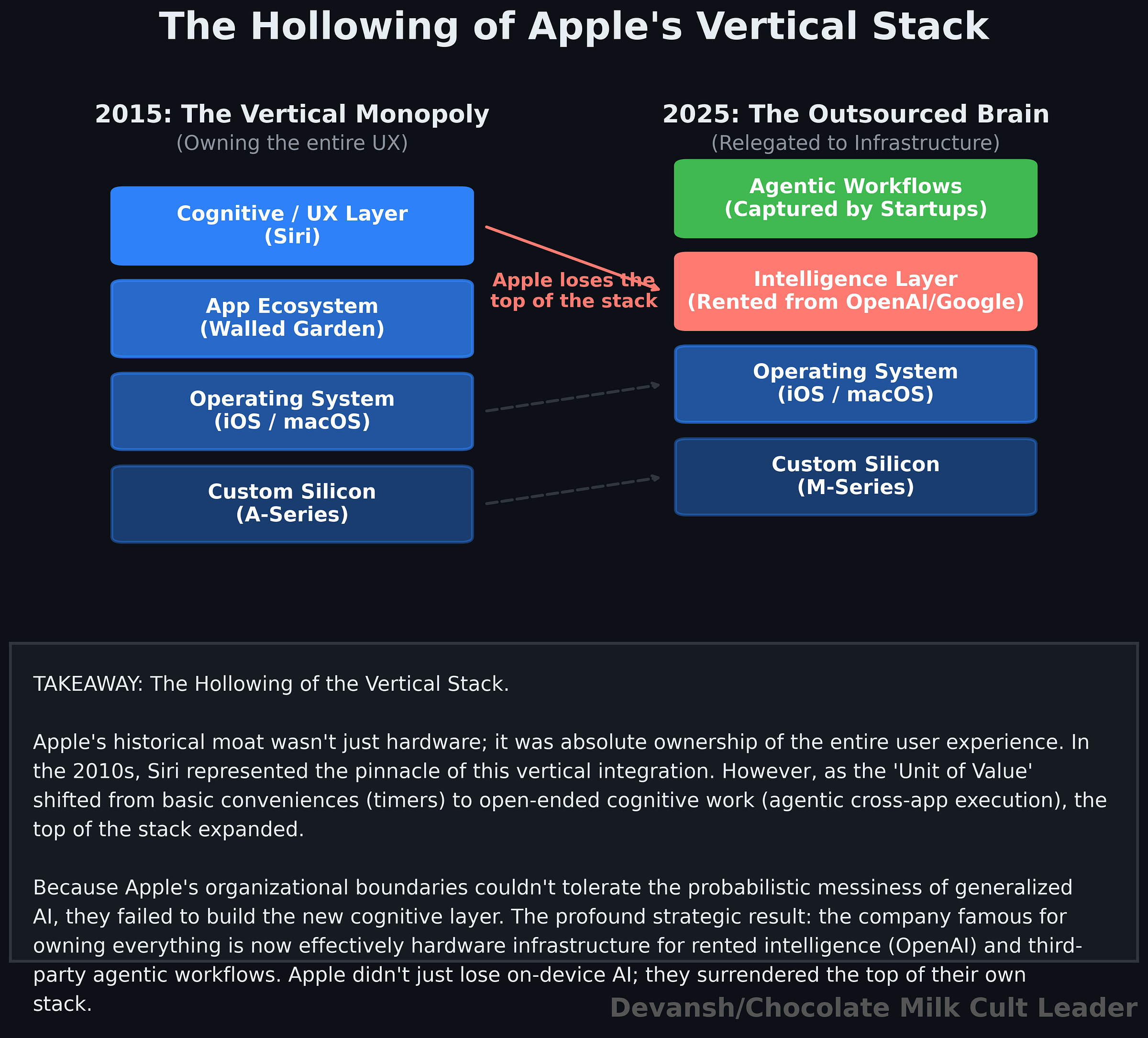
How did this happen?
2.2 What Apple Missed: The Unit of Value Changed
The original assistant model was based on command execution. Set a timer. Send a text. What’s the weather? Play this song. It was useful, but narrow. The system’s value came from mapping a spoken request to a predefined action. That is a very different product from what came next.
General-purpose models changed the unit of value. AI stopped being a convenience layer and started becoming a work layer. The role of the assistant is shifting from completing small tasks to meaningfully participating in valuable work like writing, coding, planning, and creating documents. That is not the old assistant paradigm with a few extra features stapled on. It is a different thesis about what the computer is for and how the user should interact with it.
The result is what you’d expect now that you have our mental model. Apple had world-class hardware for local AI and all the talent + cash to make it happen + the distribution to benefit from it immediately; what they did not have was the right product thesis. And so they felt the ground shifting under their feet.
2.3 Why Apple Couldn’t Move to Capture On-Device AI
Apple’s old assistant stack was built around predictability, bounded behavior, privacy, and tightly controlled user experience. Generalized AI systems are messier than that. They are probabilistic, open-ended, less controllable, often inconsistent, and initially worse in exactly the ways a company like Apple finds culturally offensive. To really make the shift, Apple would have needed to ship something that felt less polished, less deterministic, and less classically “Apple” in the short term so they could learn their way into the new paradigm over time.
That is the valley. And as we talked about, systems abhor that valley.
Then there is the org problem. A true generalized AI layer cuts across hardware, operating systems, developer tooling, apps, cloud services, search, consumer UX, and enterprise workflows. That kind of product does not fit neatly inside the old boxes. It requires cross-boundary coordination and, more importantly, a willingness to let one new paradigm rearrange old internal power structures. Apple, like every large incumbent, is still subject to Conway’s Law whether people on tech Twitter want to write poems about them or not. Companies ship their org charts. If the org is optimized around stable boundaries, the product will inherit those boundaries.
So Apple did what incumbents usually do. They stretched the old system. They kept improving Siri inside the logic Siri was born with rather than rebuilding around the new logic that was taking over. At every time step t, it probably made sense internally (at any given time it was likely costly to switch w/ lower short term returns). Strategically, it was a disaster.
2.4 Apple’s Real Concession: Renting the Intelligence Layer
When Apple integrated ChatGPT into Siri (and later Gemini and Claude), the significance was not just that they had added a partner. Plenty of companies partner. What made it interesting is that this is Apple partnering with an external company on a core aspect of their experience. This is the company whose identity has long been built around owning the critical layers of the experience. For a company whose entire religion is absolute proprietary control over the ecosystem, farming out their core cognitive layer to external providers is a massive concession.
Here, you might push back against me. “Devansh, is Apple’s loss that bad? All they pay is a little bit of money to external LLM providers; they would’ve had to risk much more if they were building their model. Isn’t this the right move for the business?”
And that is a good point. However, it misunderstands something:
Apple not trying to build its own foundation model can be viewed as smart.
BUT, they didn’t have to compete in the LLM provider race in order create extremely powerful workflow assistants that would lock people into their ecosystem. Most famous agentic assistants/computer use systems today are quite model agnostic; OpenClaw being the most recent viral example. Building one of these could have unlocked a massive revenue stream and a strong differentiator for their ecosystem.
Apple had the device, the trust, the silicon, the installed base, and the ecosystem, and yet they’re sitting on the sidelines as newcomers unlock absurd growth. In this context, there is some irony that MacOS due to it’s inherent advantages, is now the first place where many of the next-generation agentic tools are released.
Even a company with absurd advantages can miss the future when the new system requires them to temporarily become worse at being the old version of themselves. Apple had almost everything needed to lead this shift. But they could not give up the assumptions that made the old system work.
Apple still exists. They will continue to overcharge for their devices and tap their cohort of brain-dead, status-obsessed morons that will buy the most recent iPhone to be ahead. But our next fall from grace is much higher. They had a deeper entrenchment, extreme advantages, and still got their assess kicked by 2 different waves of disruption that completely changed the way software was written. The most ironic part: this is the one group that you would’ve expected to be on top of innovation.
Case Study 2: How Github Copilot Lost to Cursor, which is being now being beaten by Claude Code.
3.1 Copilot Won the First Battlefield
If you looked at the market when Copilot arrived, the story seemed pretty straightforward. Copilot was a crown jewel in the Microsoft portfolio, consolidating several structural advantages:
MS had GitHub, giving them access to where data and dev interaction patterns.
MS had VSCode, the go-to IDE for devs.
MS had enterprise trust, which is huge because no one ever gets fired for buying IBM.
They had the deal with OpenAI, spinning out the frontier models powering CoPilot.
Copilot fit neatly into the world. It sat in the editor, gave you small completions, helped at the line and function level, and let the developer remain firmly in control. That last part mattered more than people admit.
It kept the developer as the primary author and bottleneck. It didn’t change how devs worked or what they really did; it made existing work faster. Microsoft and GitHub loved this. It also drove massive enterprise adoption because it didn’t break any existing engineering management structures. It was safe.
So, how did it start to lose traction to Lovable and Cursor? Products created not by established AI teams or big-name founders, but relative no-names. Both Lovable and Cursor changed the battlefield, completely reworking the developer experience.
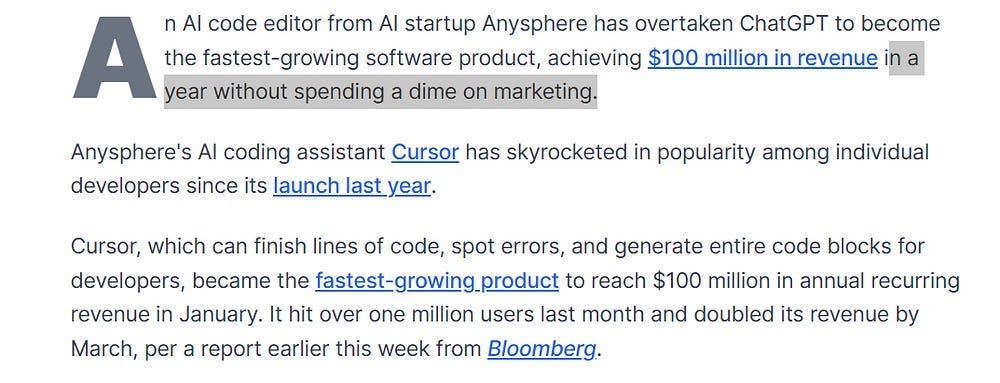
3.2 How Cursor Changed What Developers Were Actually Buying
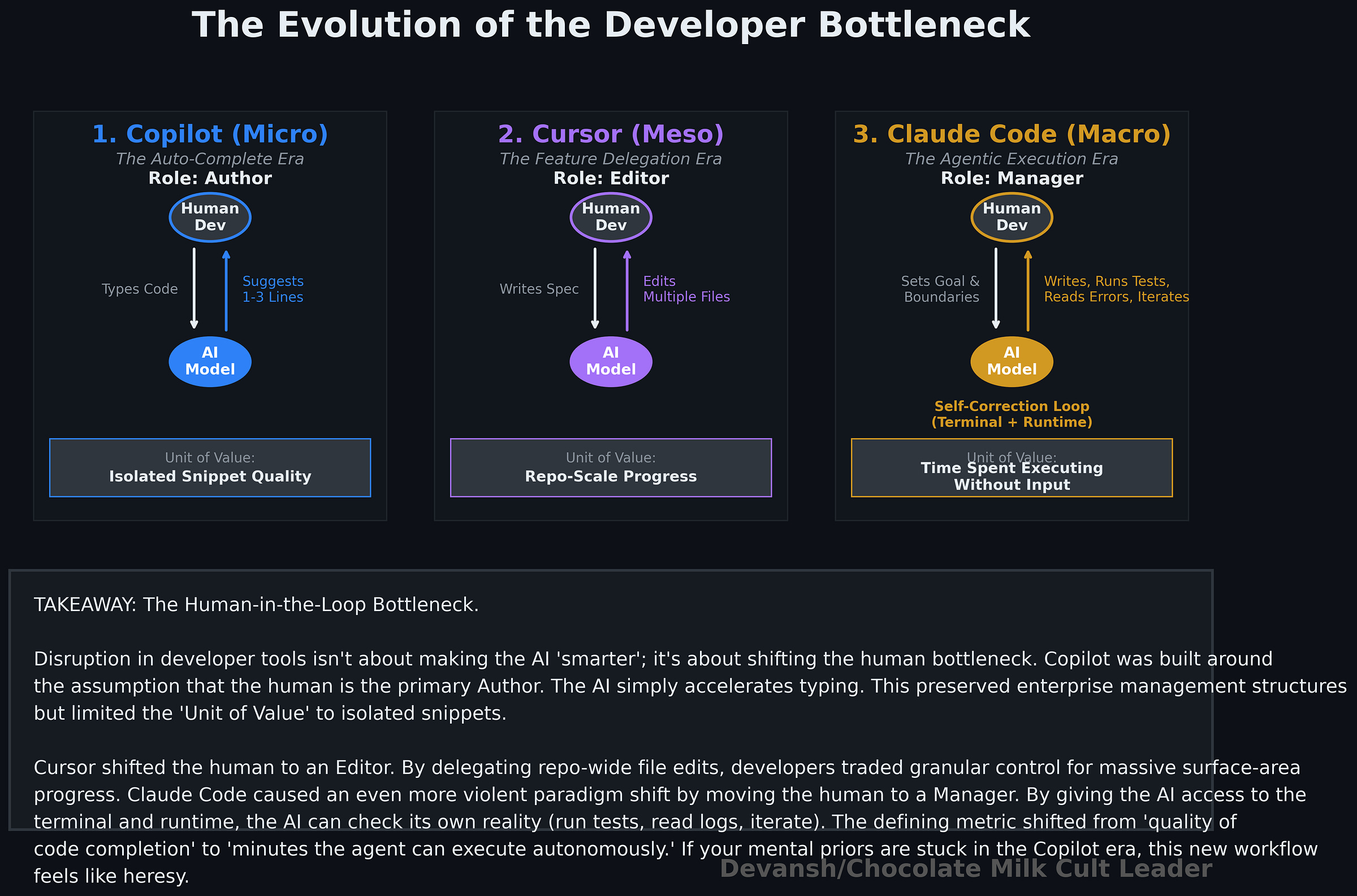
When it arrived, Cursor changed the unit of value. The point was no longer to help you finish the next line; the point was to move a meaningful chunk of the codebase from a higher-level instruction. That sounds like an extension, but the switch changed the dev-AI interaction pattern.
With Cursor, the center of gravity moved from local code completion to repo-scale progress. You gave it a spec, some context, and let it fan out across multiple files. The trade became obvious very quickly: you gave up control and polish in exchange for much more surface area moved per interaction. Security issues that would have ruined Copilot became the norm with Cursor since Cursor changed the unit of value from “quality of suggestion in isolated snippet” to “quality of execution across a longer context”.
This is where the framing of Cursor as a more ambitious Copilot was wrong. Cursor was not trying to win the old game (better tab autocomplete) by a wider margin. It was changing the game from “help me write this function” to “help me implement this feature.”
Instead, we should understand Cursor by understanding the shift in the unit of value: Cursor shifted the gold standard from perfectly elegant function completions to delegation. Cursor started naturally reworking their IDE-experience around this. Microsoft tried to shoehorn this functionality into Copilot Chat, but they were slowed since they had to do this in VS-Code, their golden child. Majorly reworking it was held back by the factors we’ve discussed in Section 1.
Cursor’s success led to a lot of imitators, but since they were all optimizing around the Cursor workflow next, they all shared the same structural advantages and disadvantages. That’s why we didn’t see any major disruptions in the marketplace until a competitor came to change the battlefield once again.
3.3 How Claude Code “Replaced Software Engineers”
Cursor had already pushed the unit of value toward higher-level delegation; Claude Code pushed it toward delegated execution. Claude Code didn’t steal customers from Cursor because it could write bigger chunks of code (or write better chunks of code). It took category ownership by doing different things: inspecting the repo, using tools, running commands, executing tests, noticing failures, revising its approach, and constantly working. That is a different category of behavior.
Just as Cursor brought “vibe-coding” to the forefront of discussions, Claude Code was the first system where people started talking “time the agent executing w/o any input” as a defining quality improvement (“Claude spent 2 hours non-stop”, later “Codex did 8”…). Anytime people bring in a new metric for evaluating a system, we can be reasonably confident that we’re starting to deal with a paradigm shift. Let’s look at how this played out in practice.
Once the model can touch the terminal, check reality, and iterate against feedback, the workflow changes again. The developer is no longer just a coder with better autocomplete, not even just a spec writer for larger edits. They start becoming a reviewer, coordinator, and boundary-setter for an agent that can actually go try things. It’s not a coincidence that Claude Code only really gained its mainstream virality after Claude updated Opus 4.6 around December to explicitly become much better with computer use and working on agentic executions. That was when the system could truly excel in this new category of delegated execution.
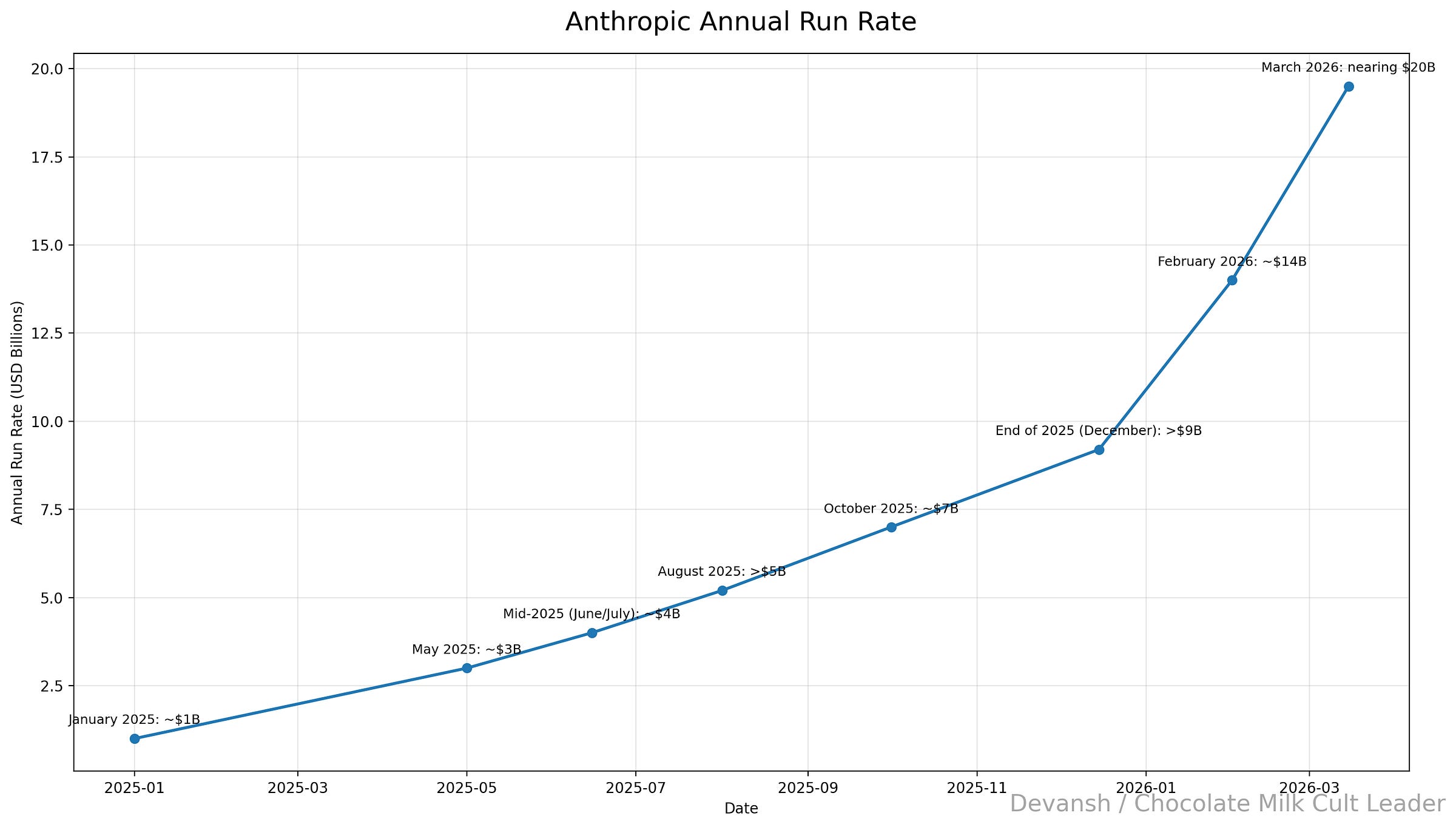
This was a larger paradigm shift from Cursor than Cursor was from Copilot, and thus its impact was more explosive. Anthropic’s run rate was 1B in January 2025, 4B in Mid-2025 (June/July): ~ 7B in October 2025: ~ $7B and by the end of 2025 it was estimated > $9B. What happens after Opus takes becomes fully aligned for agentic tool use? Their growth explodes — between 1.5x to 2x every month (14B Feb; 20B March). When we visualize this, the trend becomes very clear.
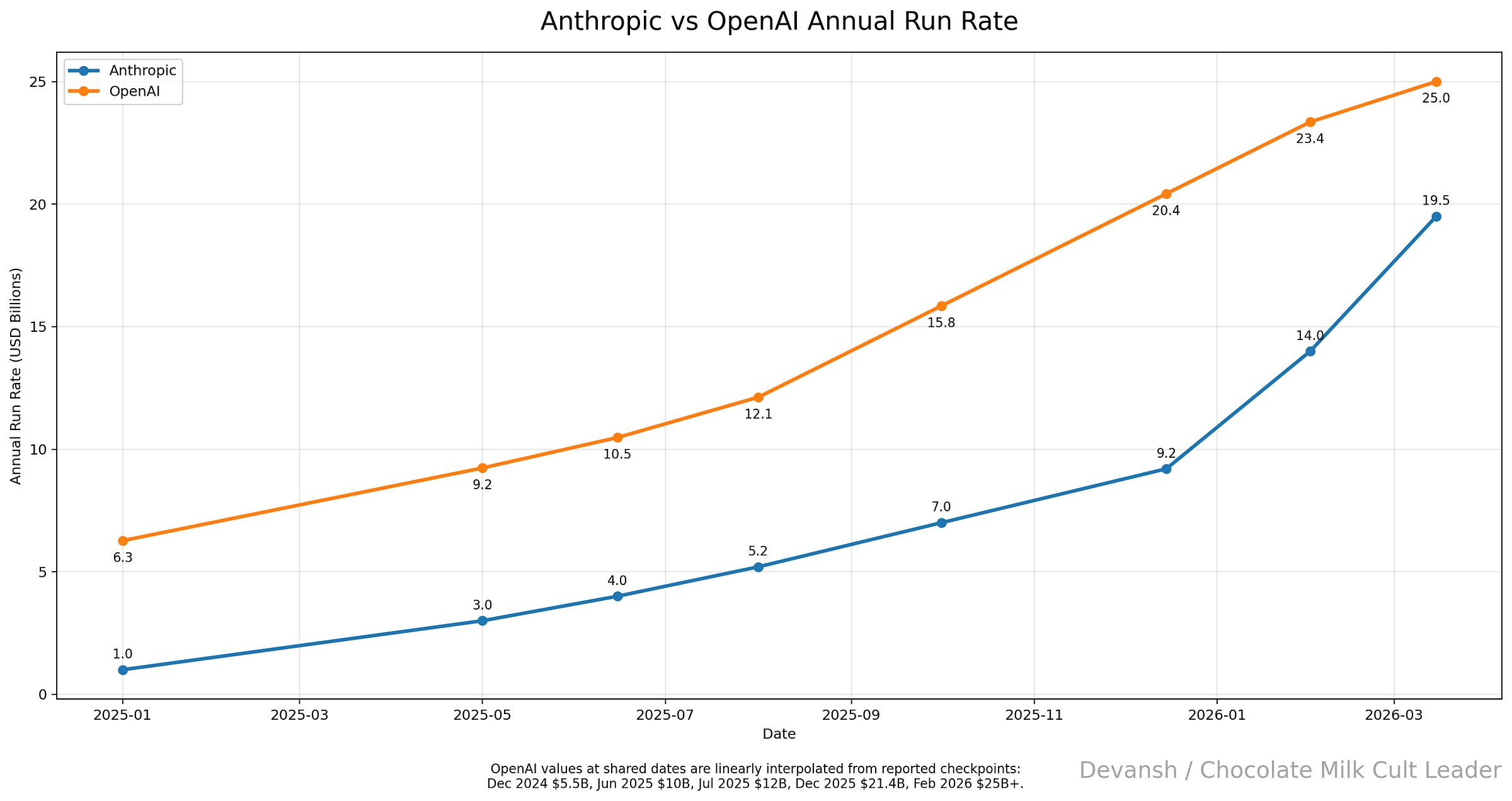
To really contextualize this, however, we should look at the macro trends across the space. After all, could this growth be explained by a general increase in LLMs (after all, even Google boasted about an insane increase in Gemini token consumption late last year). Comparing Anthropic vs OpenAI, we see something interesting: both grew similarly well (w/ OpenAI even doing better mid last year when Deep Research and Memory were purring for them). However, when Anthropic doubled down on the paradigm shift and changed its battle to focus on agentic execution, it’s slope suddenly skyrocketed.
Beyond the financials, this paradigm shift even rippled into the fundamental ways we build and analyze LLMs. Agentic Tool Use has increasingly both become a fundamental part of training and benchmarks. Even the way LLMs now prioritize context within their established context windows has changed. Modern LLMs are increasingly shifting the focus away from human conversations. Instead, context is evolving into infrastructure for processing agent logs, tool call histories, memory state, and multi-step execution traces. These can be seen through several experiments, which we will publish soon as we compare the stability of various LLMs. You can also read more about it here.
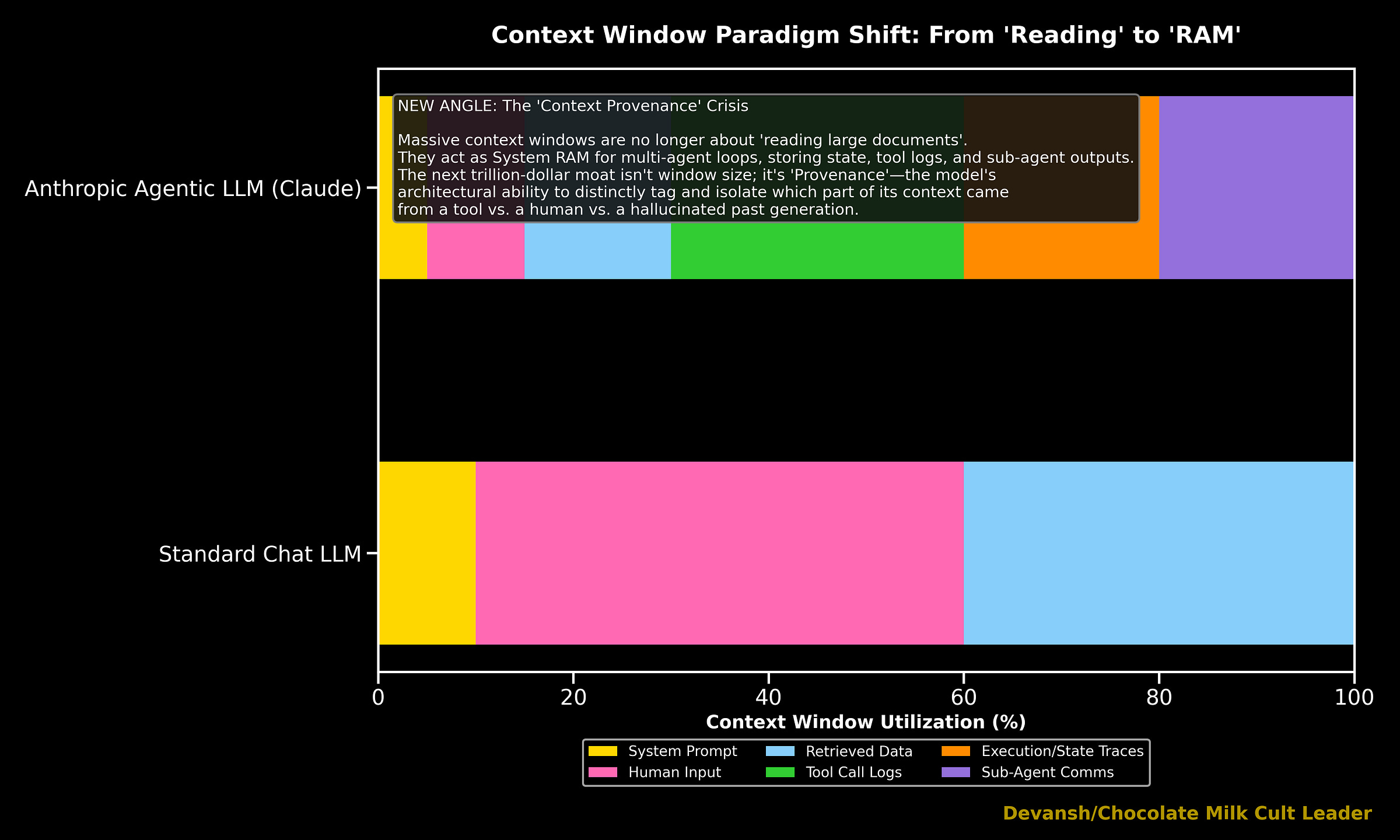
I use many words and perspectives to communicate one point: Claude Code didn’t steal Cursor’s thunder by producing meaningfully better one shot output, it stole it by building an interative system that changed the very definition of one shot (from what the system output when first given the prompt to what did the system output when the system finally gave the developer the output). This was a major paradigm shift, and thus it was appropriately rewarded by the market through much better rewards and a durable moat.
3.4 Why the Previous Leaders Keep Struggling to Catch Up
At this stage, all 3 of our players have the same set of offerings: an IDE chatbot, an agentic mode for execution, and a CLI tool. The difference here isn’t in their raw features but in their priors. To someone who built their mental model around building Copilot, Cursor’s new IDE paradigm is very uncomfortable. An ADE system like CCC would be heresy. Likewise, for Cursor (hence their struggle to deliver a comparable CLI experience). So CC keeps pulling ahead as the old guard struggles to disrupt themselves.
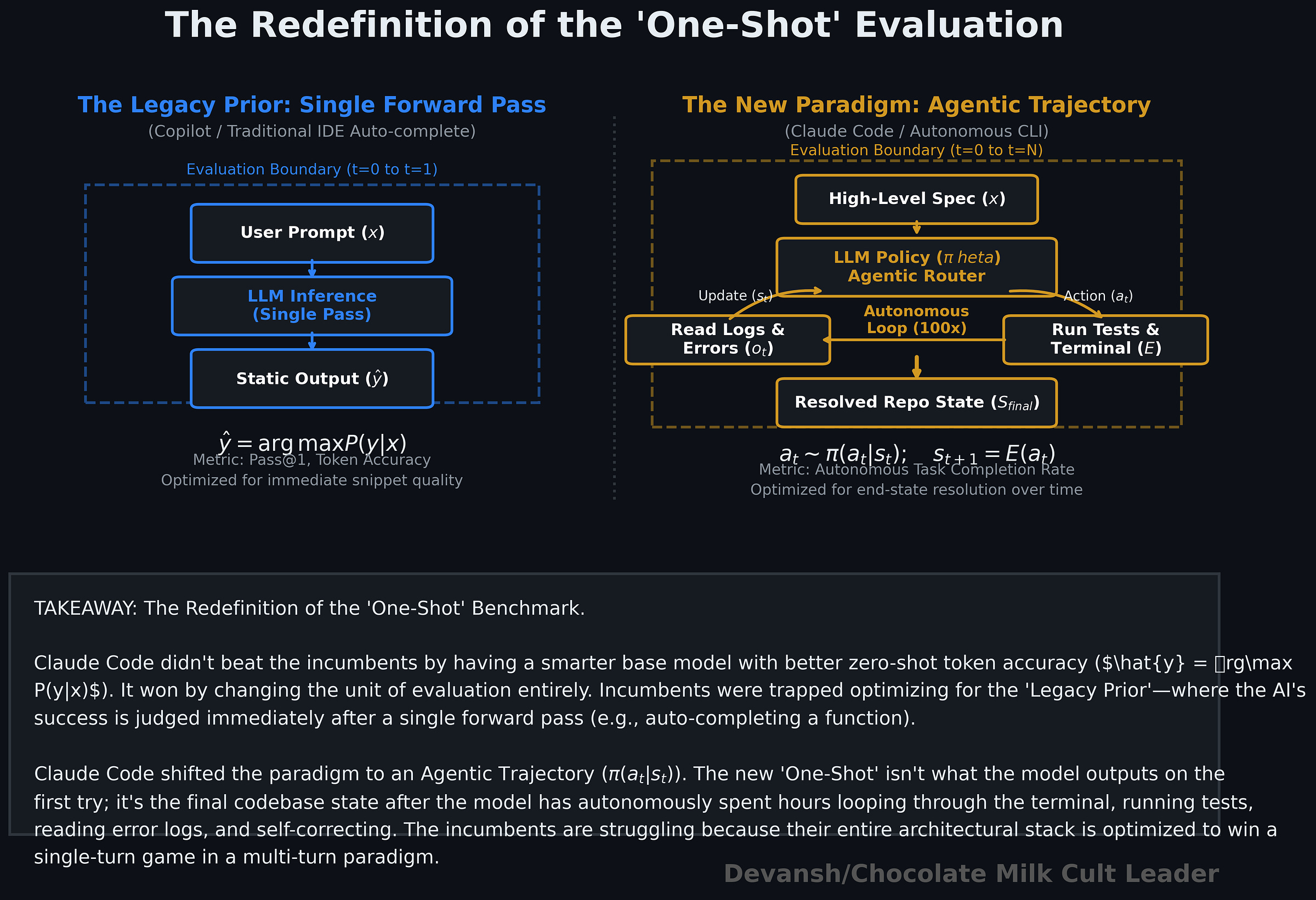
This leads us to an interesting observation wrt to paradigm shifts: they often come from people outside the old system. Old-age experts come with a lot of baggage that makes them very good at optimizing what exists vs rethinking priors. Looking at this case study for instance:
Cursor was created by a bunch of kids.
Boris Cherny (creator of Claude Code) did not build his foundation working on a system like Copilot prior to Anthropic.
Even outside this case, this pattern is worth studying. Contextual AI was founded on a lot of hype around solving context for LLMs by some pioneers in the space. Truthfully, they’ve done fuck-all. The most revolutionary change in context management for LLMs (Recursive Language Models) came from a bunch of college kids.
That isn’t to say domain expertise isn’t useful: it definitely helps more than it hurts. However, this analysis leads us to refine our framing when evaluating founders: if the founder is experienced in the current generation of the systems it’s worth pressing them as to why they are creating a startup. What are they unhappy about? The more fundamental their points of contention/proposed solutions, the more likely they are to build something category-defining as opposed to building something that is incremental and will be replicated by incumbents. The same mental model applies to builders deciding what problem to work on.
We’ve sunk a lot of words into exploring the ecosystem and its pressures. All to come to an understanding of what differentiates startups and when it’s hard for incumbents to disrupt them. Now let’s apply this lens to one of the most hotly contested spaces in AI right now. Let’s predict the future of Legal AI.
Just as Cursor disrupted the market with Quasi-Agentic development, only to be replaced by truly agentic systems like Claude Code, I predict that the first wave of legal AI tools will be disrupted by systems that reimagine intelligence ground up.
Case Study 3: Why Irys will Beat Harvey and Dominate Legal AI.
Perhaps the best way I can do justice to this wonderful mental model I’ve built is to put my skin in the game. So let me tell you why I’m working on a legal AI startup, when I could making a lot more money for doing a lot less work by working at an Nvidia or DeepMind.
4.1 Current Legal AI Optimized Grunt Work
The first wave of Legal AI (at least the first wave of the current generation) got paid because it made legal drudgery less painful through faster summaries, faster clause comparison, faster first drafts, faster search, and faster first-pass issue spotting. That is useful. Firms will absolutely pay for that.
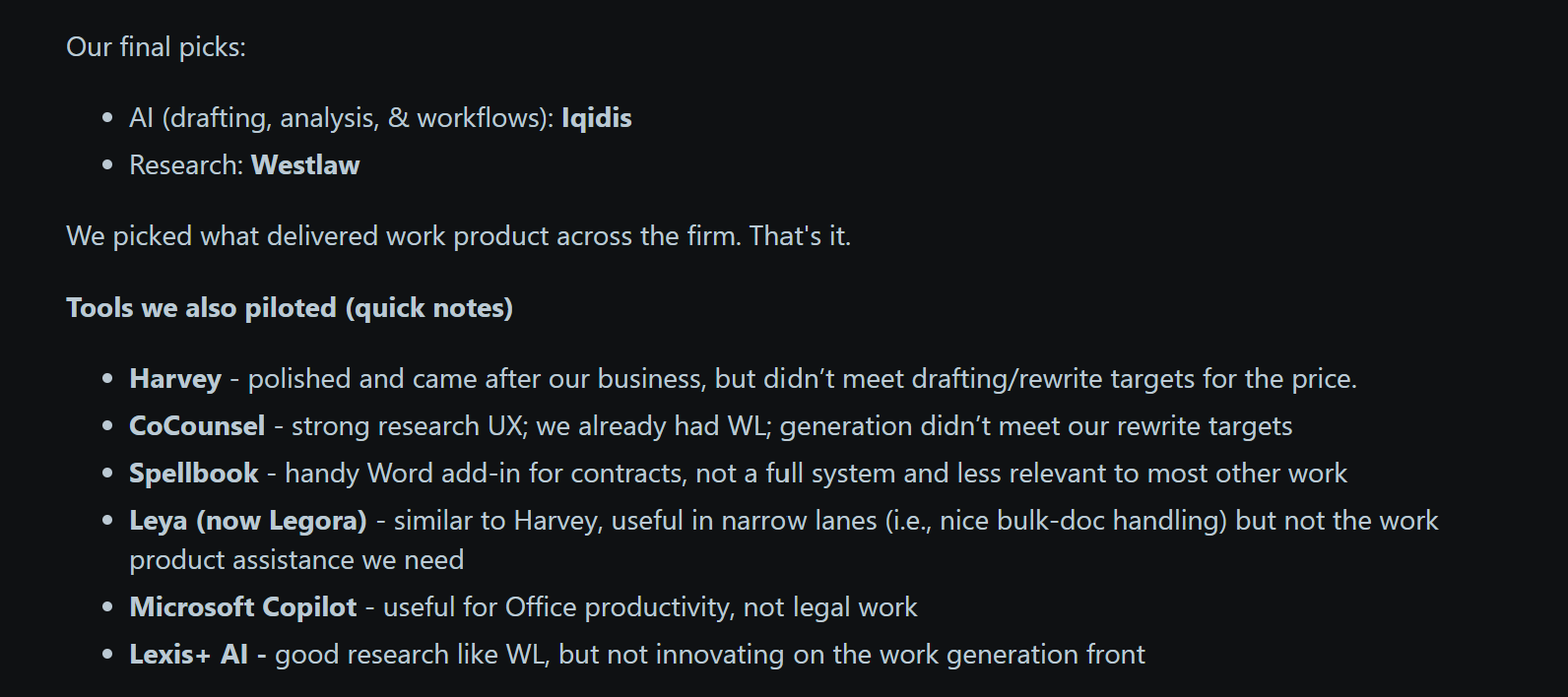
However, this early win + a misunderstanding of AI fundamentals locked the major competitors into a fundamentally limited stack: Vector Search + Fine-Tuned Models (largely abandoned now, but was a huge marketing point at one point). They built their infra investments and teams around scaling these systems. And now people are starting to realize the limitations of these systems , they’re going to struggle to maintain their position at the top.
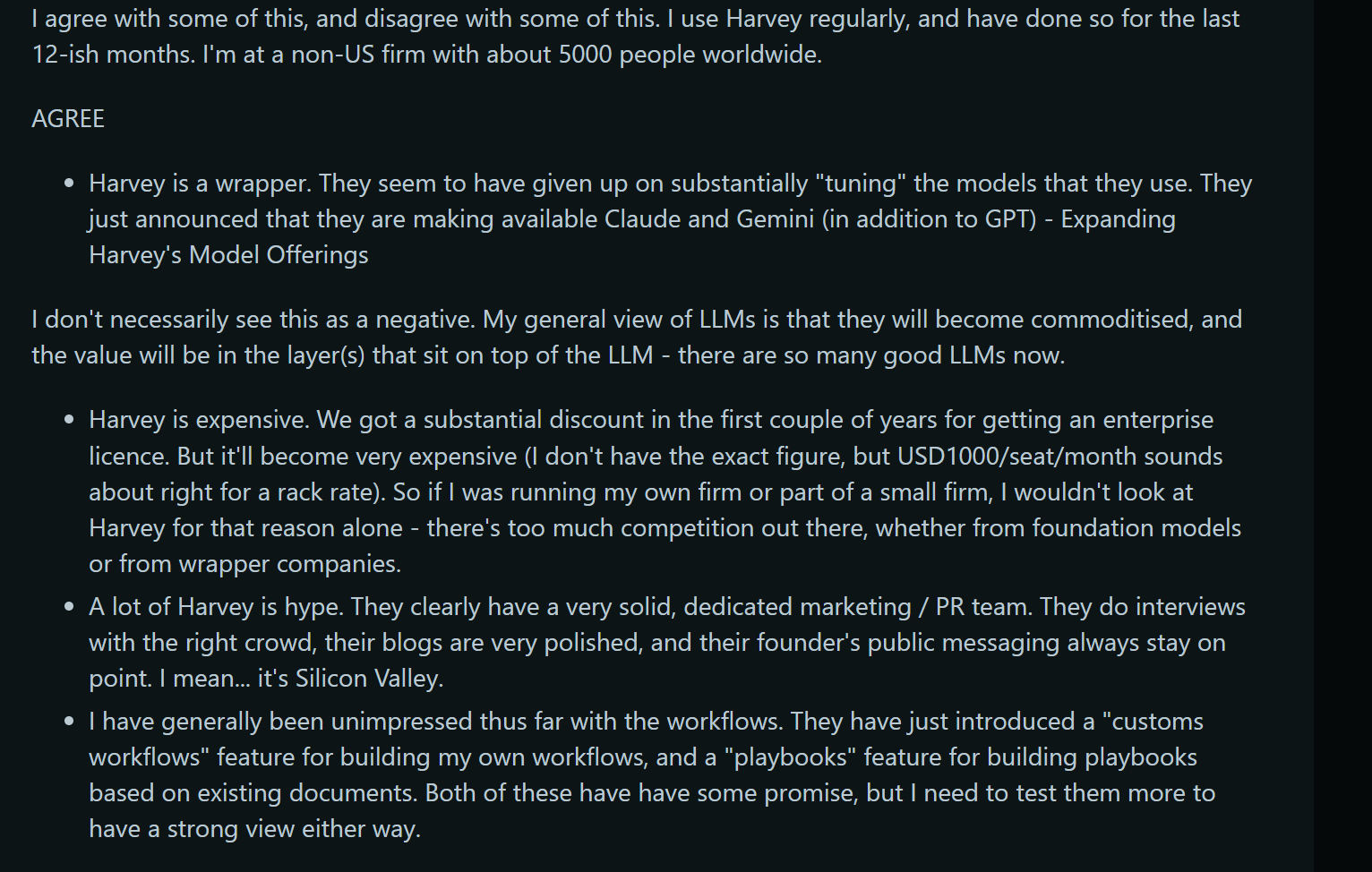
In a recent Reddit post, the OP was scathing toward Harvey. Even people that defend Harvey call it hype and a wrapper and were unimpressed by the workflows feature (their attempt at so called Agentic AI) —
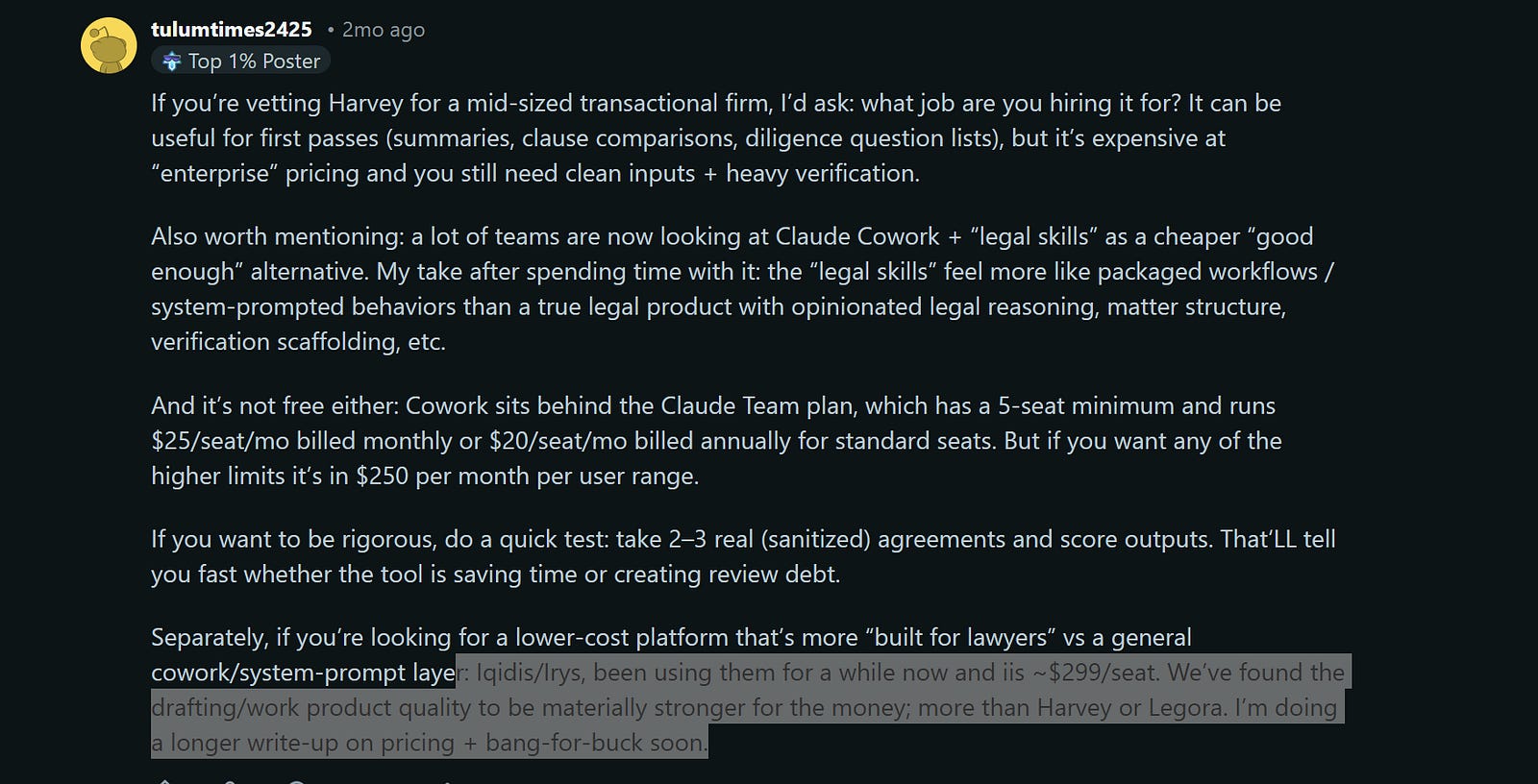
Compare that to the following comment talking about us in the same post (saying that we’re materially better)
Let me tell you why Gen 1 will fall behind (using facts and logic) by exploring why their approach has a mathematical upper limit that they won’t be able to solve for. Then I will tell you how we’re solving for these problems with Irys, our Legal AI platform at Iqidis to build the best Legal AI on the planet.
(Since we have many prominent Legal AI teams read this newsletter, here is an open invite: if you can either disprove my analysis of the failure modes of the current failure modes of Legal AI or want to prove that your system is an actual paradigm shift that addresses these fundamental issues, you’re welcome to come on my newsletter for a livestream conversation/demo. No strings attached, this is basically free marketing for you).
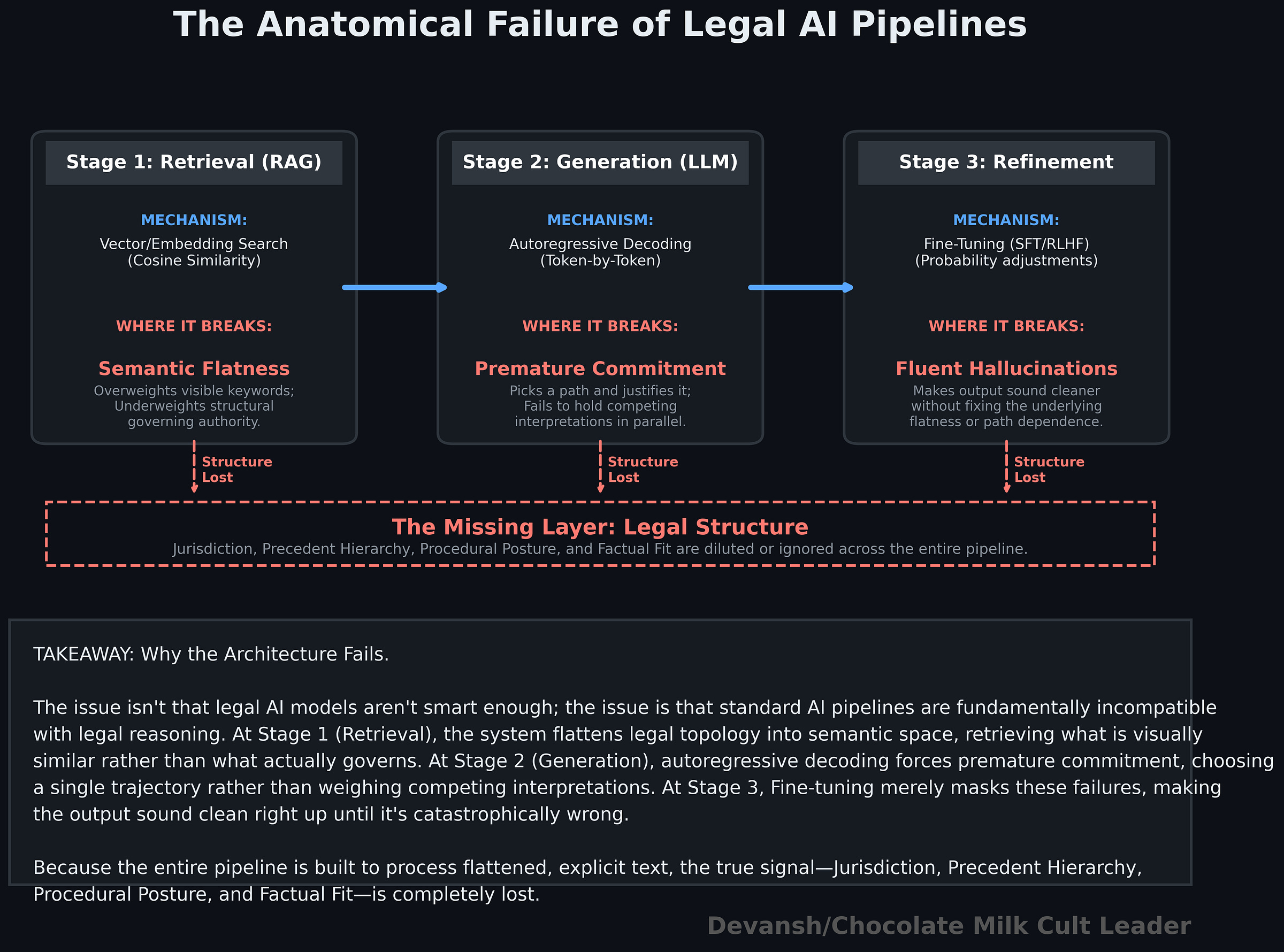
4.2 Why the Current Generation of Legal AI will Fail
Most legal AI systems today rest on two assumptions. First, that the right legal knowledge can be retrieved from a flat semantic space using embedding search or RAG. Second, that once retrieved, an autoregressive model can compress that information into a correct answer. Let’s understand these in more detail, and see why Fine-tuning doesn’t fix anything.
The problem starts with how vector retrieval works. Semantic search maps text into a vector space and retrieves neighbors based on similarity — usually cosine similarity or some equivalent distance metric. In practice, this means the system is optimizing for geometric closeness in embedding space.
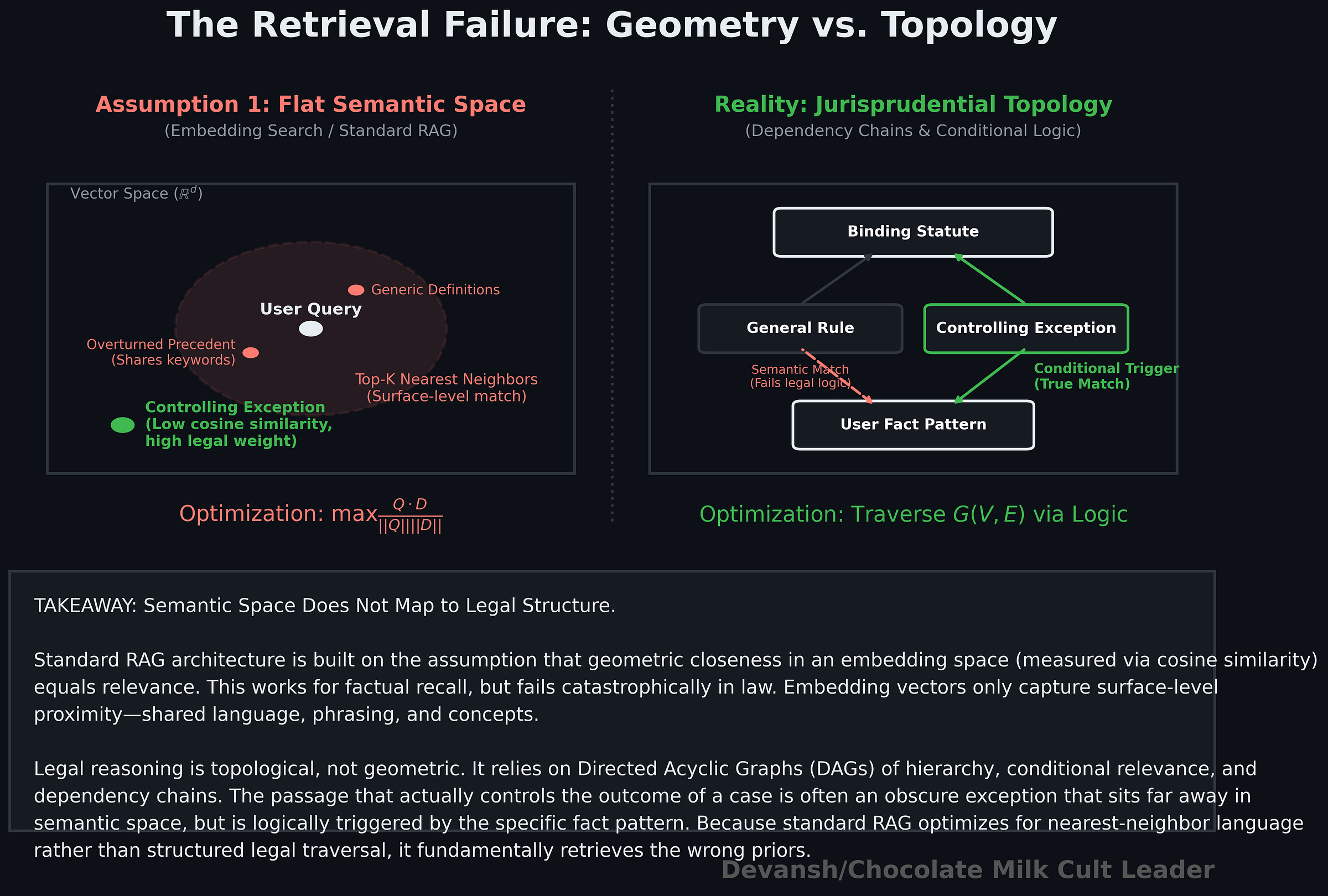
Since not all of you are technical, let’s understand what that geometry actually represents.
Embedding similarity captures surface-level semantic proximity — shared language, shared concepts, shared phrasing. It does not encode legal structure. It does not know hierarchy (binding vs persuasive authority), conditional relevance (“this applies only if X is true”), or dependency chains across doctrines. Two passages can be close in embedding space and completely different in legal weight. Worse, the passages that actually control the outcome are often not the most semantically obvious ones; they sit off to the side, triggered only after certain conditions are met.
So retrieval becomes biased toward what is easy to see, not what actually governs the case. It is a nearest-neighbor search over language, not a structured search over legal reasoning.
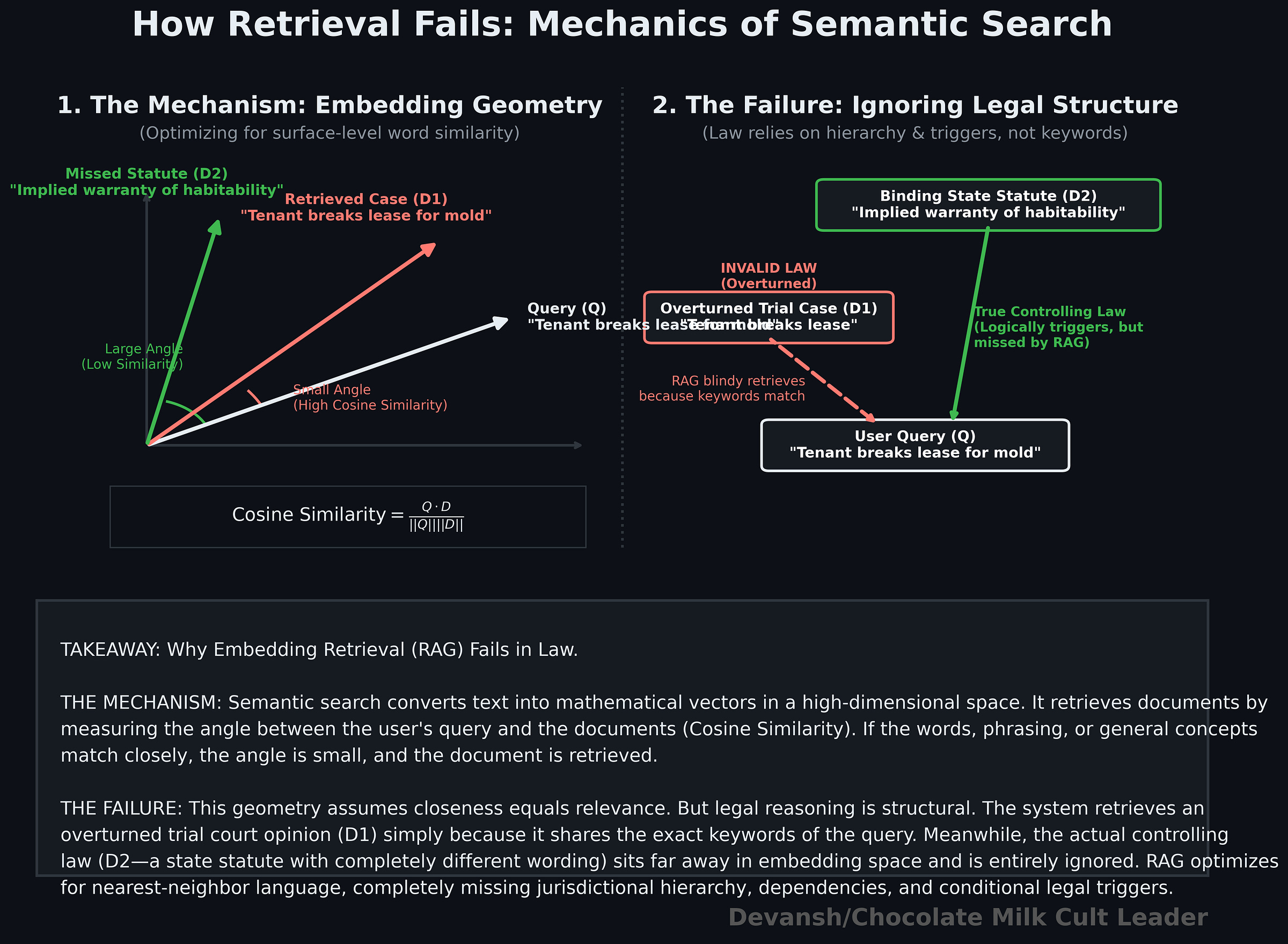
For the sake of argument, let’s say you somehow retrieve the right material. The second assumption breaks things further.
Autoregressive models generate text one token at a time by sampling from a conditional probability distribution. At each step, the model picks the most likely next token given what it has already produced. This creates a form of path dependence: once the model starts moving in one direction, each new token reinforces that direction.
Formally, the model is approximating a sequence of conditional probabilities P(token_t | tokens_<t). But decoding forces a single trajectory through that space. It does not keep multiple competing interpretations alive; it commits locally at every step.
That is fine for tasks where one answer is enough. It is a poor fit for the law.
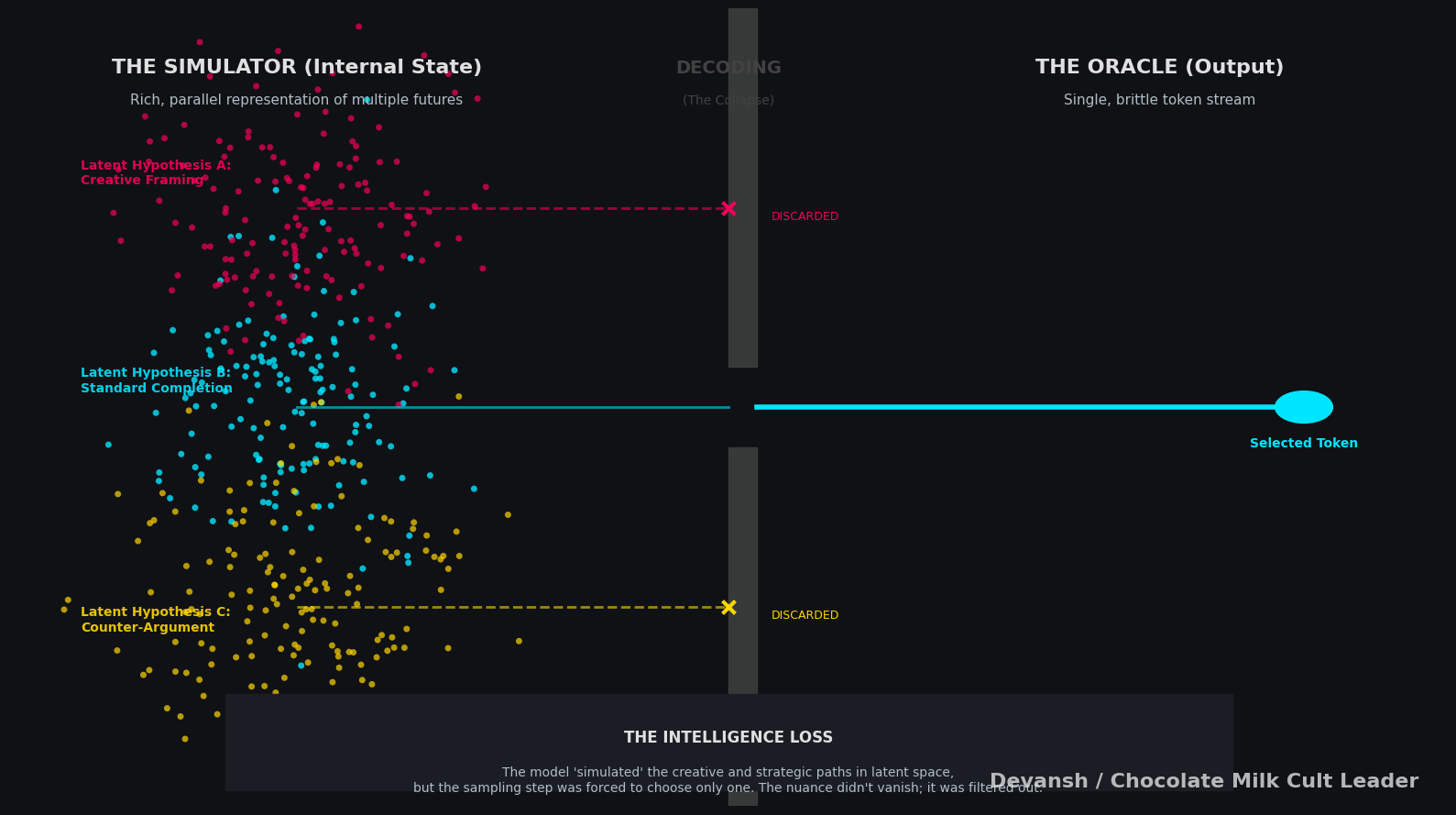
Legal reasoning often requires holding multiple candidate interpretations in parallel — different readings of a statute, competing precedents, alternative fact patterns — before resolving which one dominates (often you will blend multiple). The hard part is not generating a fluent answer; it is managing uncertainty across paths before collapsing to one.
Autoregressive decoding collapses too early, killing this thing. You’re stuck praying that your system will surface the reasoning that will work in this context. If it doesn’t you really have no way to control it, no way to diagnose where it goes wrong, and no way to build your systems to account for it (remember that b/c of how LLMs work, identical inputs can produce different outputs, especially in fuzzy fields like law. This means you don’t even know if your model will be consistently incorrect!!).
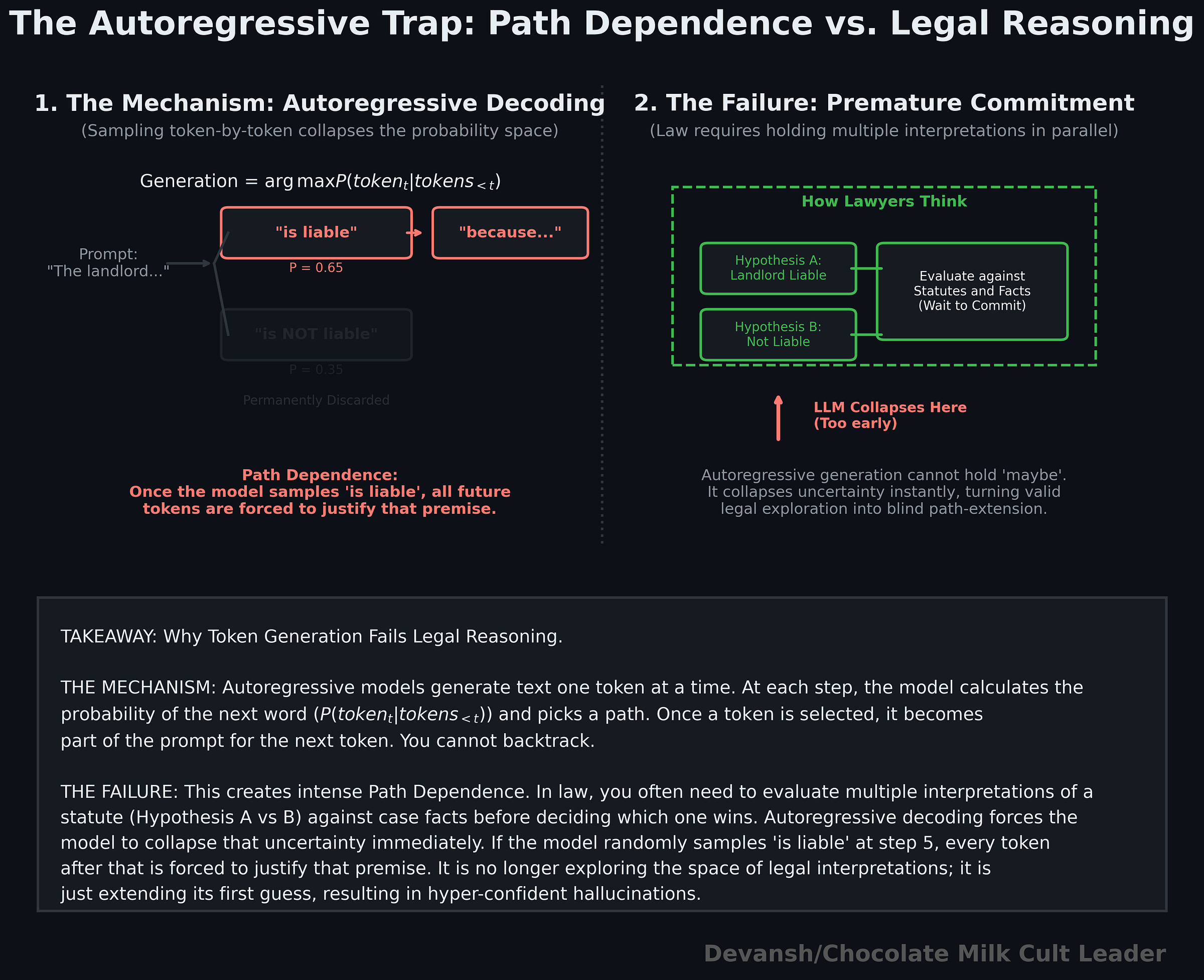
The typical pipeline makes this worse since it retrieves a few chunks and feeds them into the model for generations. The first coherent frame that appears becomes the answer, and everything after that is just elaboration. The system is no longer exploring the space of possible legal interpretations; it is extending the first one that looked plausible.
This isn’t unique to law, since the same problem exists everywhere. But this is where law takes a very different turn from modern agent systems that are modeled on coding assistants like Claude Code. As we discussed earlier, they rely on powerful — plan, generate code, run it, test it, and fix it — loop The system improves because it can verify its own output against an external ground truth. If the code fails, the test suite gives you signal into where and why.
Legal reasoning does not have that property.
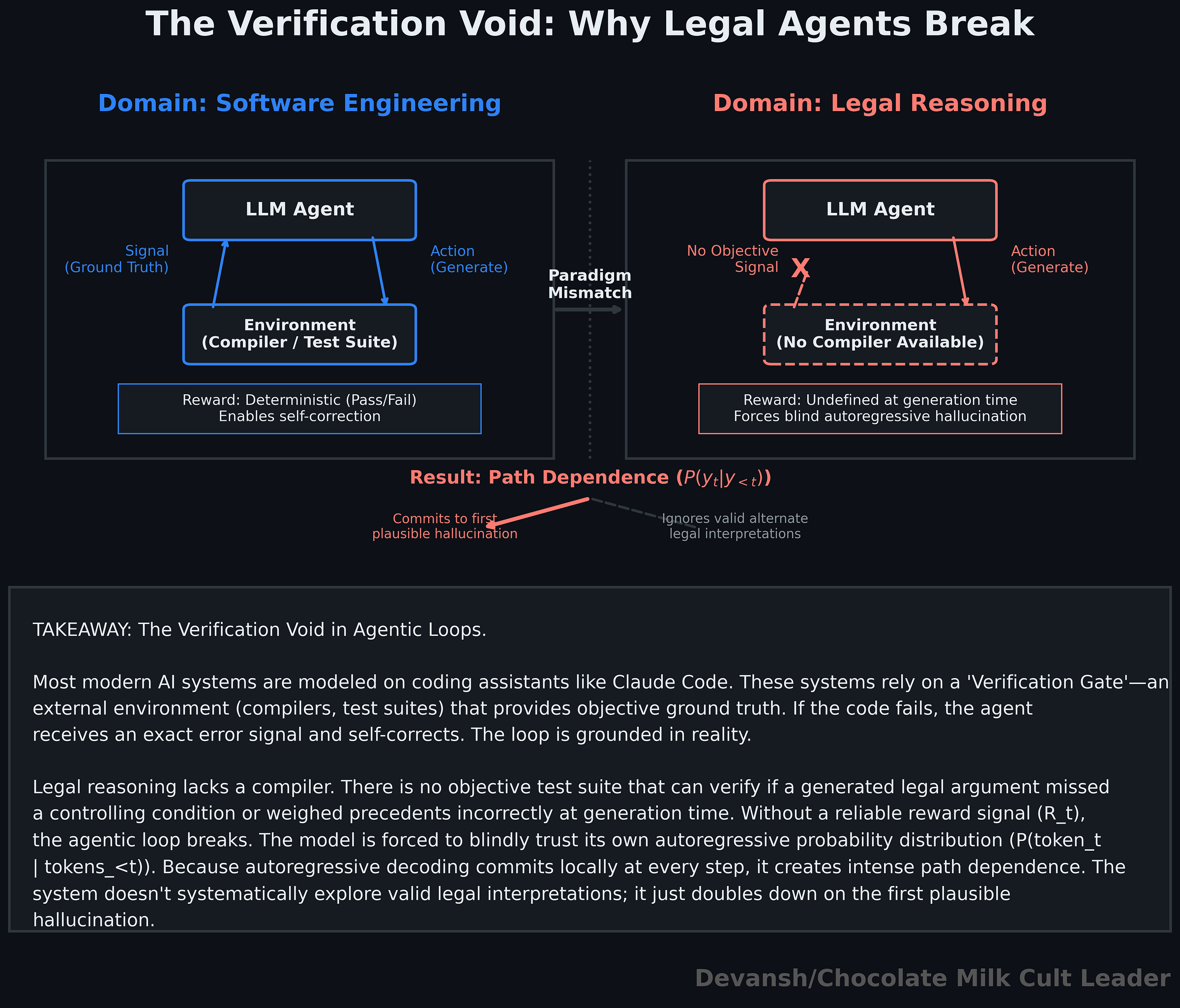
There is no equivalent of a compiler or a test suite that can reliably tell you whether you explored the right interpretations, weighed the correct authorities, or missed a controlling condition. You can only verify against outcomes you already know, which defeats the purpose. For novel questions — the ones your users will give to the system while using it — there is no ground truth available at generation time.
That breaks the entire agent loop.
This is why techniques that work well in code — tool use, execution loops, verification gates — degrade in legal settings. They assume a world where correctness can be checked after each step. Law is not that world.
Fine-tuning does not fix any of this. It adjusts the model’s local probabilities — style, phrasing, some domain priors — but the underlying mechanics remain unchanged. The system is still searching in a flattened semantic space and still committing to a single trajectory during generation. You get more confident answers, not more reliable ones. And as multiple pieces of research has shown, training the model in one set of capacities degrades it elsewhere, unpredictably, meaning you’re still stuck with all kinds of performance issues.
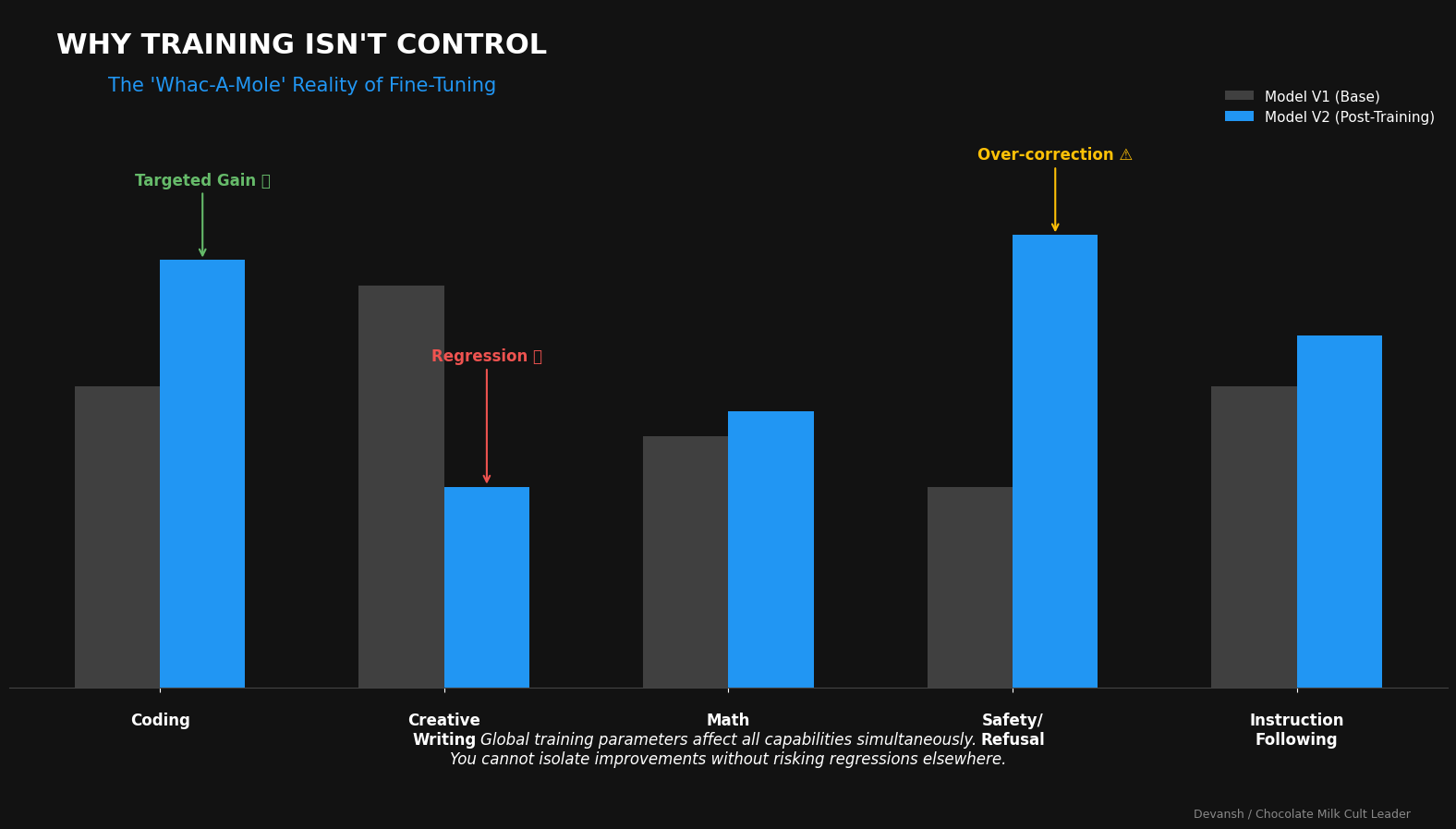
These systems are built to retrieve what looks similar and then commit early to a single explanation. Legal reasoning, on the other hand, depends on finding what actually governs and delaying commitment until competing paths have been properly evaluated. The gap between those two is where things break.
4.3 How We Built Irys Differently
There are major claims made here. The good news, you don’t have to take my word on this. Here are the libraries mentioned here, fully open sourced so you can verify my claims yourself:
Fractal Embeddings applied to Biology (this was done by an external researcher, no affiliation to us. Their positive results prove that our research is truly foundational, not just a coat of paint).
If the current stack fails because it commits too early and flattens too much, then the answer isn’t better prompting. It’s to remove those constraints.
The first constraint is premature commitment. Standard decoding forces the model into a single visible path almost immediately. What you want instead is the ability to explore multiple reasoning trajectories before collapsing to an answer.
This is where Latent Space Reasoning (LSR) comes in (read about it here). Instead of treating generation as a single forward pass, it treats reasoning as a search problem over latent trajectories. Small changes in latent states can produce entirely different lines of reasoning without changing the model weights. The model already contains multiple possible interpretations; standard decoding just locks you into one too early.

You can see this directly in the results. Simple latent perturbations pushed a Qwen3–4B model’s arithmetic accuracy from 32.0 percent to 51.6 percent — without any training or fine-tuning. On planning tasks, baseline decoding can collapse into degenerate outputs — sometimes as short as 14 words — while the same model, under perturbed trajectories, produces full 650+ word solutions.
But the more important result is qualitative, not quantitative.
Evolved latent trajectories don’t just produce better answers — they produce different ones. Entire reasoning paths appear that never show up under standard decoding: different strategies, different abstractions, different conceptual frames. This isn’t stylistic variation. It’s accessing parts of the model’s internal knowledge that the default decoding path never reaches.

In legal reasoning, that matters. Ambiguity isn’t something to suppress — it’s something to explore before deciding. If the system collapses too early, entire interpretations never get surfaced at all. Our paradigm gives us the ability to tackle that.
The second constraint is flattened representation. Legal knowledge isn’t a single semantic space; it’s structured — jurisdiction, issue, doctrine, authority, factual fit. Treating all of that as one embedding space forces the system to relearn structure implicitly every time.

A better approach is to encode that structure directly. Hierarchical representations break the problem into levels, so the system doesn’t have to solve the entire space at once. Instead of asking “what’s the right answer?” in one step, the system resolves a sequence — where does this apply, which doctrine governs, how does it map to the facts.
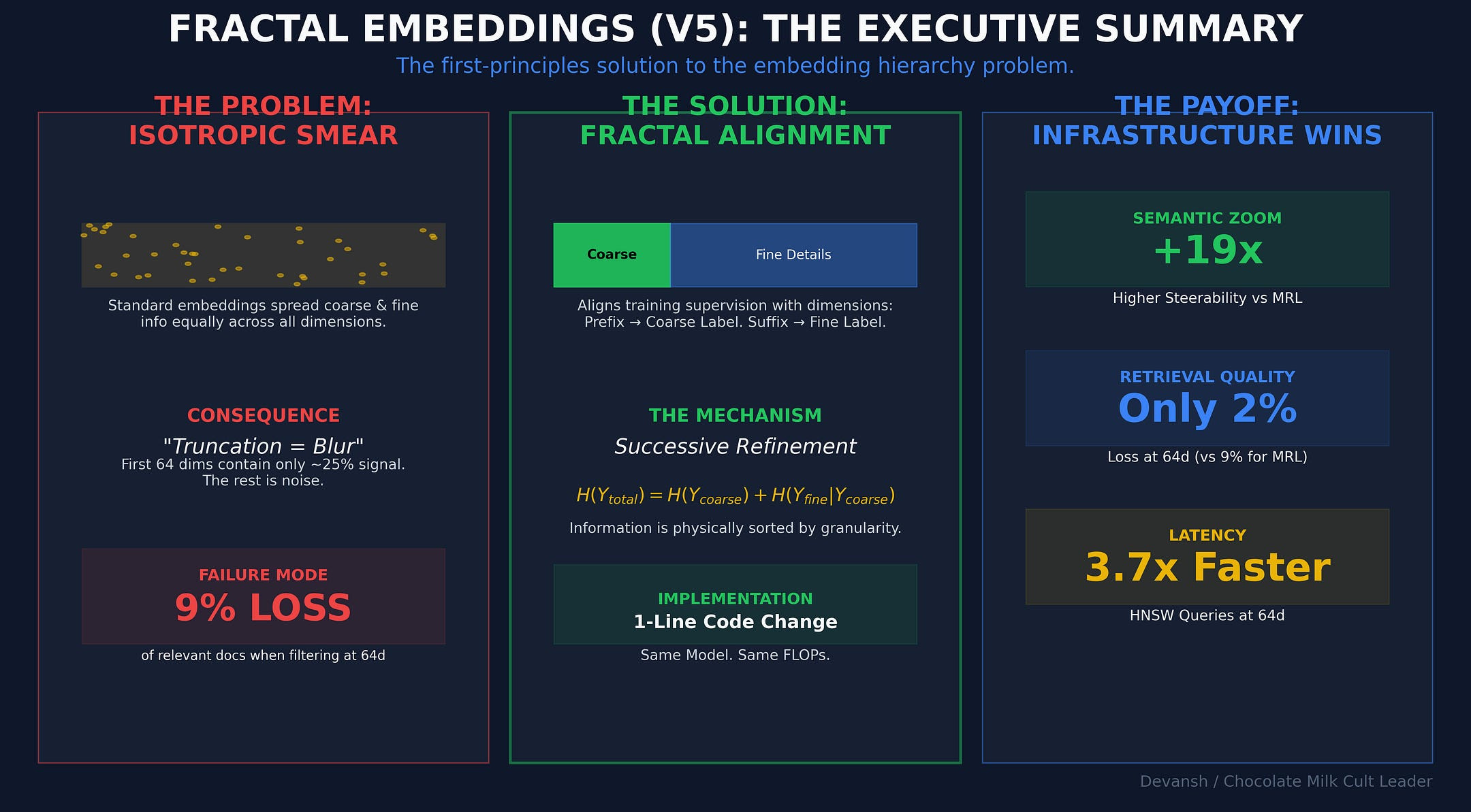
In the frac-bio-embed work (which I feel compelled to stress again, was not done by us, it was an independent researcher taking applying our work in a new space we didn’t even design for) the same hierarchical approach was applied to single-cell biology — 7.9 million cells across 203 types — and consistently improved performance over flat embeddings, with the largest gains at fine-grained distinctions. This proves that our diagnosis scratches at a failure mode: when structure matters, flattening loses it.

Both of these changes point to the same idea.
The problem isn’t that models aren’t capable. It’s that the current stack restricts how they search and how they represent the problem. Change those, and you don’t just get better answers — you unlock reasoning paths that weren’t accessible before.
4.5 What This Means for the Future of Legal AI
The first wave of Legal AI got paid because it solved drudgery. Good. But Conway’s Law, Sunk Cost Fallacy, and all the other issues we’ve elaborated on at length will keep that generation stuck in this framework and have difficulty pivoting to the new architectures that will define the next generation of legal work.
To repeat our prediction: Just as Cursor disrupted the market with Quasi-Agentic development, only to be replaced by truly agentic systems like Claude Code, I predict that the first wave of legal AI tools will be disrupted by systems that reimagine intelligence ground up. And as this happens, these incumbents will fail to rebuild effectively.
We’re already seeing the early signals of this:
If you go to lawyertalk and other legal subreddits, we’re the most positively talked about Legal AI tool out there, by quite a mile. And people often talk about how different our answers feel as opposed to Harvey etc, which feel like wrappers (deep research this if you don’t believe me).

We’ve also beaten the other names to land several big names like Blockchain.com. But more importantly then landing is retention. Our enterprise retention rate is 100% (we’ve never lost an enterprise client, ever). This is despite the fact that we don’t have any lock-ins or anything that forces people on the platform.
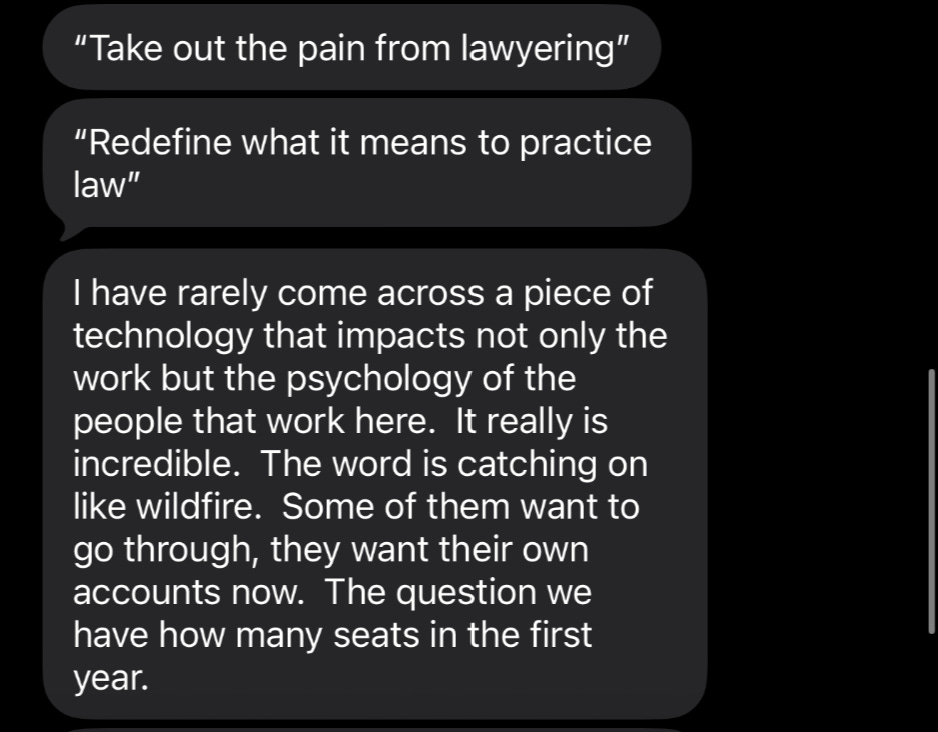
Going back to our earlier discussions about how disruptive startups change the interaction paradigm/usage patterns of their users, we’ve got messages from several users that they love “sparring” with our platform, and our sophisticated reasoning system allows them to have a lot more fun discussing law with our platform (one person said that he was staying up till 2AM playing with the platform). These are the kinds of use-cases that can’t be replicated easily, and we’re on the verge of some major releases to lock these in further.
This has been a long article, so I’ll end it here. As mentioned, if you’re a legal AI startup that disagrees with any of my analysis, or you want to stress how different you truly are, you’re more than welcome to come state your piece on this newsletter. I welcome all challengers.
Thank you for being here, and I hope you have a wonderful day,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. :
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819
Thank you. Great insights, as usual, and one or two really strong nuggets I'll repost.
One minor note on Conway's Law - the system ends up mirroring the *communication* structure in an organization, not necessarily the organizational structure. And I've seen this in practice - take an existing org structure and add additional structured communications between two siloed teams, and all of a sudden you'll start to see more and better communication between those parts of the system as well, without a reorg.
So, an org structure that perfectly maps the desired system architecture will still produce something else (like system patches to route around the org friction) if the right kinds of communications don't happen between the teams that represent the communication points in the system. And an incumbent willing to invest the resources and disruption to improve communications between siloed teams may be able to change their architecture some without a reorg.
This means, for example, that if your org has communication policies or habits that add friction to communications (default to use email over DMs, hard limits on meeting length or quantity, default private Slack groups, etc.), even a full reorg may change very little in the underlying architecture without upending the communication practices as well.
All that said, though, in many cases there's not much practical difference for incumbents. Because often, the sclerosis of the communication structures is one of the main things that prevents the incumbent from re-organizing in the first place. So, in a real world sense, the importance of communications over org structure may make it even harder for incumbents to compete.
And communication friction increases with org size (Price's Law may contribute here). So, the larger the org, the harder it will be for them to compete, even if they pay the tax to reorg for the new architecture required.