
How the Next Generation of AI Models are Going to Completely Change AI Inference
Why Changing from Autoregressive Language Models to Diffusion Models will change AIs hottest problems

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
Most of the AI infrastructure boom isn’t actually buying compute. It’s buying memory bandwidth.
Look at the market right now: SK Hynix and Micron are completely sold out of their 2026 HBM capacity. Cerebras is pushing a $22 billion IPO built almost entirely around high-memory inference chips. Google just split its 8th-generation TPUs into completely separate training and inference lines.
Hundreds of billions of dollars are being deployed based on a single, massive assumption: that AI generation will always be bottlenecked by the exact same things it is today.
But if you look closely at the research, that assumption is already starting to rot. Diffusion models are rapidly rising out of the image-generation niche and seeing aggressive, mainstream use across text and reasoning workloads.
(PS: if you want to dig into why Diffusion Models are the future, from an engineering/technical perspective (including why companies are already investing in them, we covered it in this article (Prediction 2 and 3). Since I don’t want to repeat stuff, this article will take the rise of Diffusion Models as a given. The image below is a good illustration of how diffusion models unlock a deeper category of reasoning. .
This is not a trivial algorithmic swap. Diffusion fundamentally alters the AI paradigm. It aggressively rewrites the underlying math of how models are served, flipping the hardware bottlenecks and turning the established inference market on its head.
In this article, we will cover:
The Dependency Graph: Why standard autoregressive LLMs are structurally trapped by memory constraints.
The Bottleneck Inversion: How diffusion models shatter the sequential lock and shift the hardware paradigm.
The Algorithmic Timeline: The math required to make language diffusion financially viable.
Inference as Search: How diffusion makes complex, inference-time verification cheap, threatening the $2 billion base-model moat.
The Vendor Breakdown: Which hardware architectures (NVIDIA, AMD, Groq, Apple, etc.) are actually positioned to survive the shift to compound diffusion workloads.
Let’s play together.
Executive Highlights (TL;DR of the Article)
The Autoregressive Memory Trap (Section 1): The entire AI infrastructure supercycle is a desperately expensive patch for data movement. Because autoregressive models generate sequentially, operations have an arithmetic intensity of roughly 1 FLOP per byte. A modern tensor core needs nearly 300 FLOPs to stay fed. This means your $40,000 GPU executes at under 1% of peak compute while waiting for gigabytes of history (the KV cache) to stream across the chip.

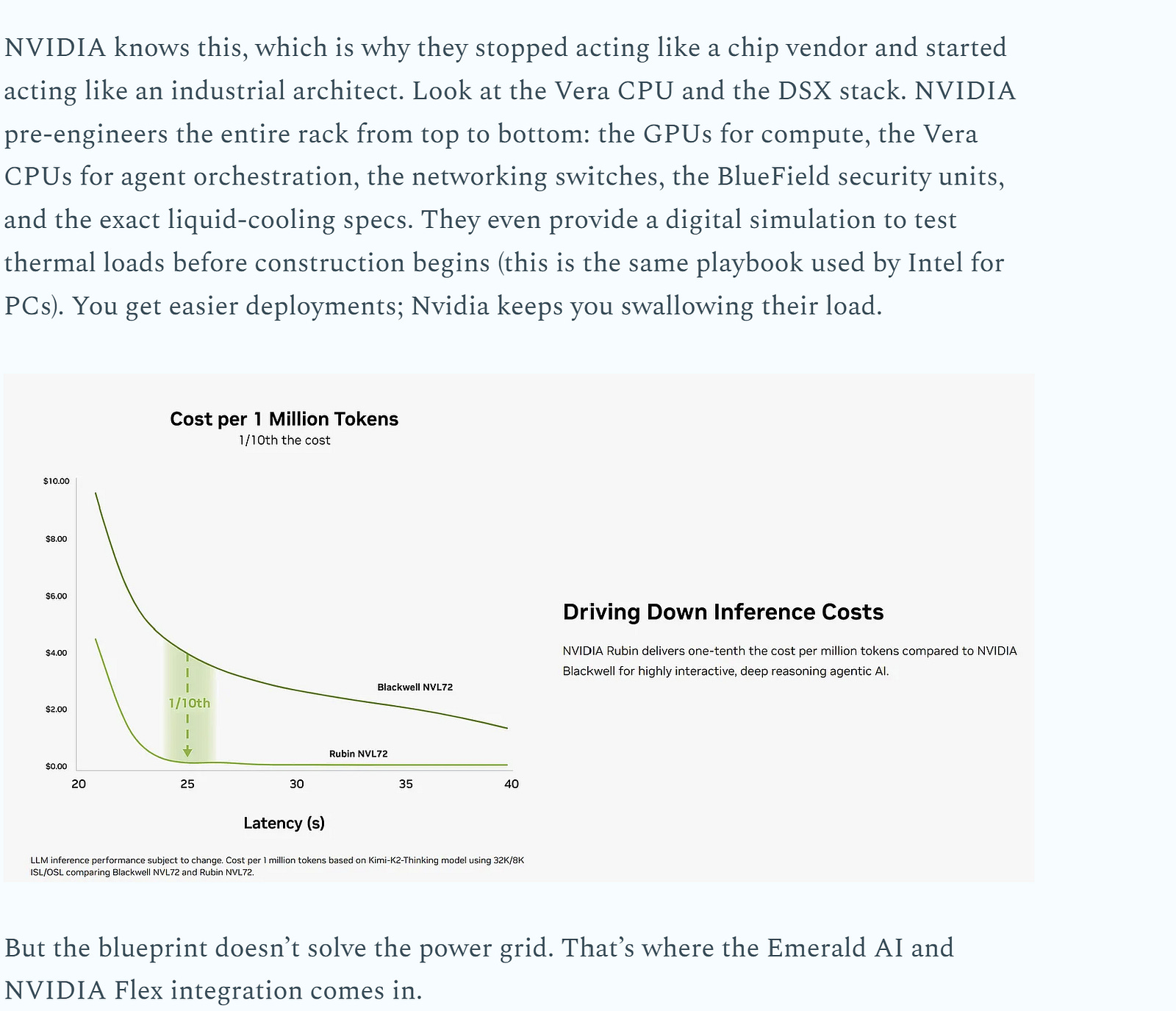
The Bottleneck Inversion (Sections 2 & 3): Diffusion models refuse left-to-right generation, refining entire sequences in parallel. This changes the underlying math from bandwidth-starved matrix-vector operations to massive matrix-matrix multiplications. The KV cache tax vanishes, and the bottleneck flips to raw compute. This is a massive tailwind: hardware generations like Blackwell and Rubin have compounded FLOPs at 3x every two years, while memory bandwidth has stalled. The industry accidentally built the perfect silicon for diffusion workloads.
The Algorithmic Timeline & Step-Count Constraints (Section 4): Perfect hardware is irrelevant if the math requires too many steps. Image generation collapsed its step count using continuous math, but language operates in discrete jumps, trapping text diffusion in a 4-to-16 step regime. However, software scheduling is proving cheaper than raw parameter scale. Simply forcing a model to unmask logic premises before conclusions (LogicDiff) spiked reasoning scores by near 40 points without changing base parameters, threatening the hyperscaler gigawatt-compute thesis.
Inference as Search & The Verifier Moat (Section 5): Because early denoising steps just build coarse shapes, multiple search trajectories can share the exact same early path. Running 4 candidate branches that share 40 of 50 steps yields a 4x quality search for a 1.6x compute tax. Branching AR is financially ruinous; branching diffusion is cheap. This unbundles the AI market: value migrates from the $2B base model to the companies building elite, proprietary verifier suites.
The Vendor Landscape (Section 6): Production diffusion is not a clean loop; it’s a chaotic compound pipeline (Denoiser + Verifier + VAE).
NVIDIA: Retains its moat because CUDA is the only environment flexible enough to handle this “swamp” of switching models and search orchestration.
AMD: Massive HBM capacity acts as the perfect hedge against the massive activation memory spikes required for video diffusion and DiT workflows.
Groq & Pure ASICs: Brilliant for streaming deterministic AR tokens, but deeply vulnerable to the inter-chip latency required to orchestrate complex, backtracking search trees.
Apple & Qualcomm: Positioned to completely strip-mine edge volume the second local step-counts collapse, separating the volume from cloud revenue.

I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Section 1: Why Large Language Models Struggle with Decoding
Pick any fast frontier model — Claude 4.5 Haiku, GPT-5 Mini, Gemini 2.5 Flash. Look at their tokens-per-second at batch size one. These are the fastest autoregressive LLMs in the world, running on $40,000 silicon with peak FP8 throughput in the petaflop range. Yet they generate text at roughly the speed an undergraduate types.
To understand why, you have to look at the dependency graph.
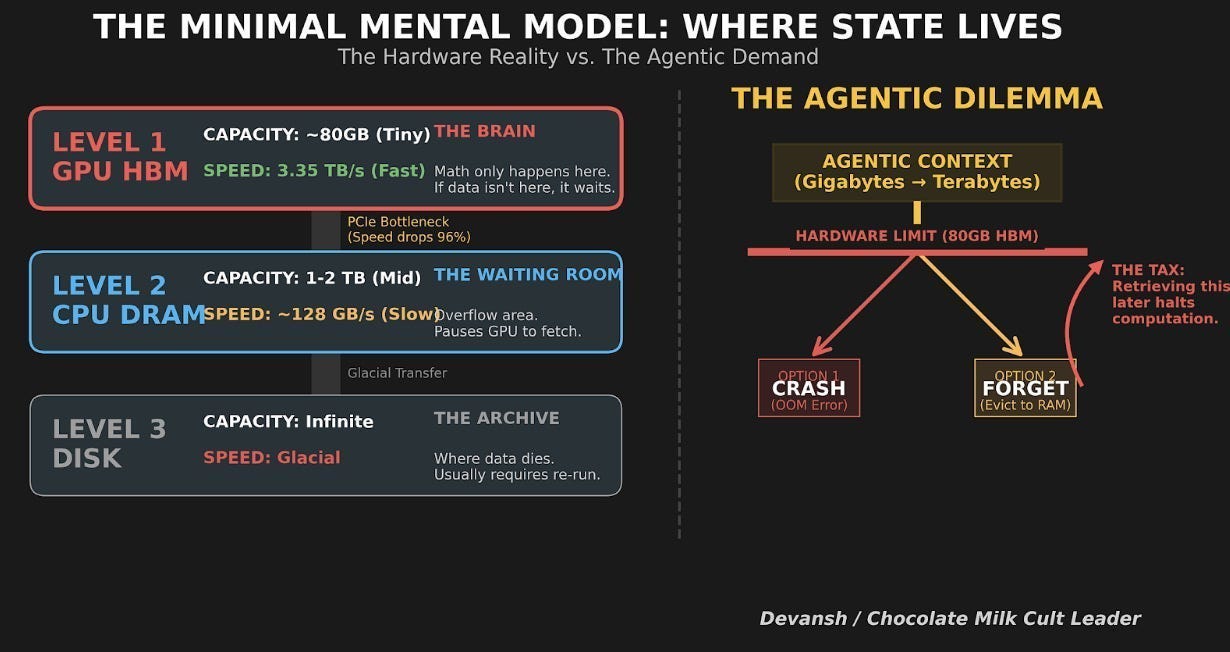
Autoregression is strictly sequential. Token 200 cannot exist until token 199 is sampled. Because of this lockstep dependency, the model cannot process its layers in parallel across the sequence. To produce a single token from a 70B-parameter model, all 140 GB of weights must stream from High-Bandwidth Memory (HBM) into the chip’s SRAM, execute a tiny matrix-vector multiplication, and leave.
This operation has an arithmetic intensity of roughly 1 FLOP per byte of data moved. A modern Hopper or Blackwell tensor core needs nearly 300 FLOPs per byte before it stops starving. So when an LLM generates text for a single user, the GPU executes at under 1% of its theoretical peak compute. The other 99% of the silicon waits for data to arrive. The constraint isn’t how fast the chip can multiply. It is how fast the chip can be fed.
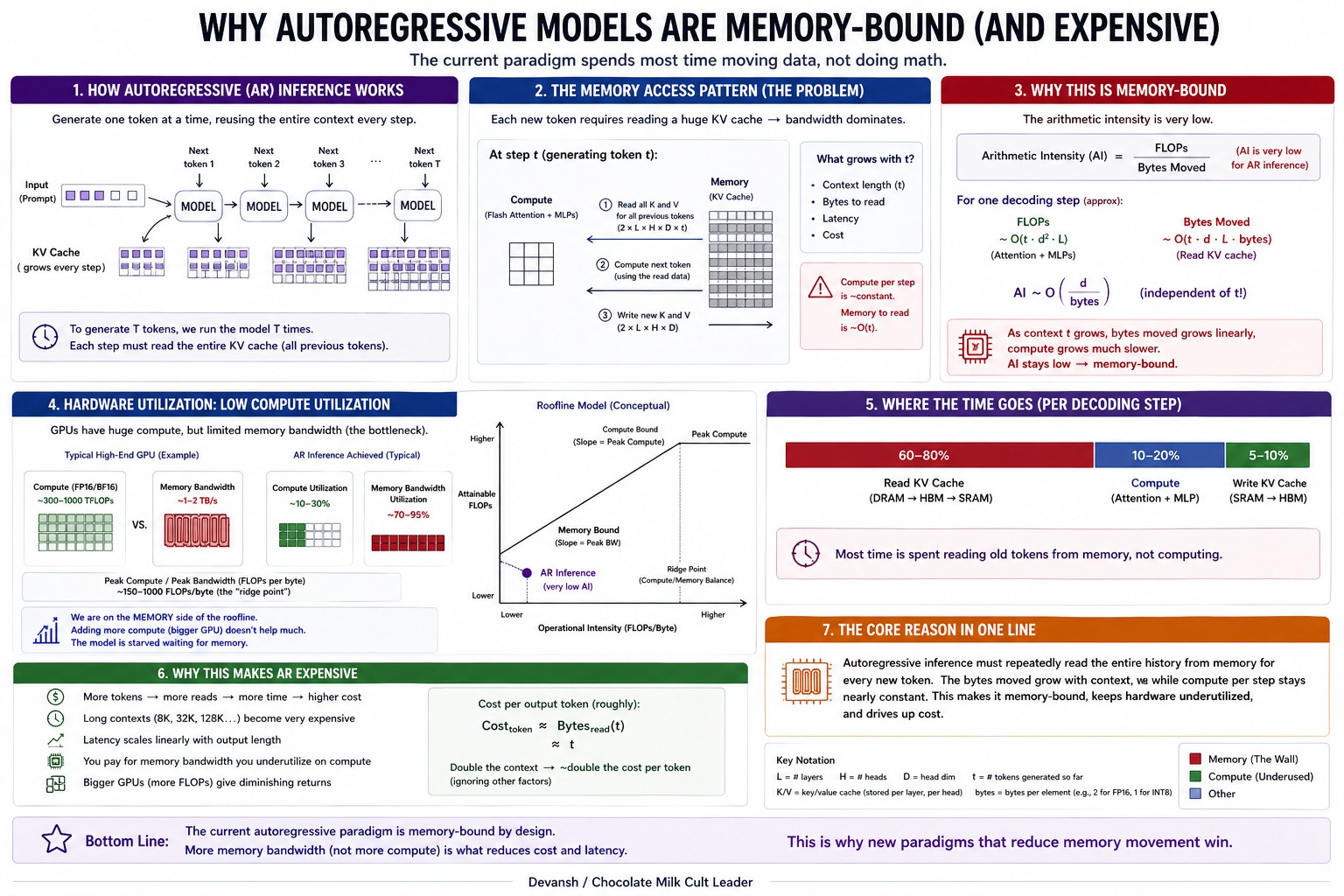
Once you understand that data movement is the true bottleneck, the entire AI infrastructure stack reveals itself as a series of patches for this exact flaw.
Take the KV cache. If you are already memory-bound, the logical fix is to avoid recomputing the past. The KV cache stores the attention states of previous tokens so each new token only adds to the sequence. But this trade creates a massive residency tax. The longer the context, the more memory capacity it eats.
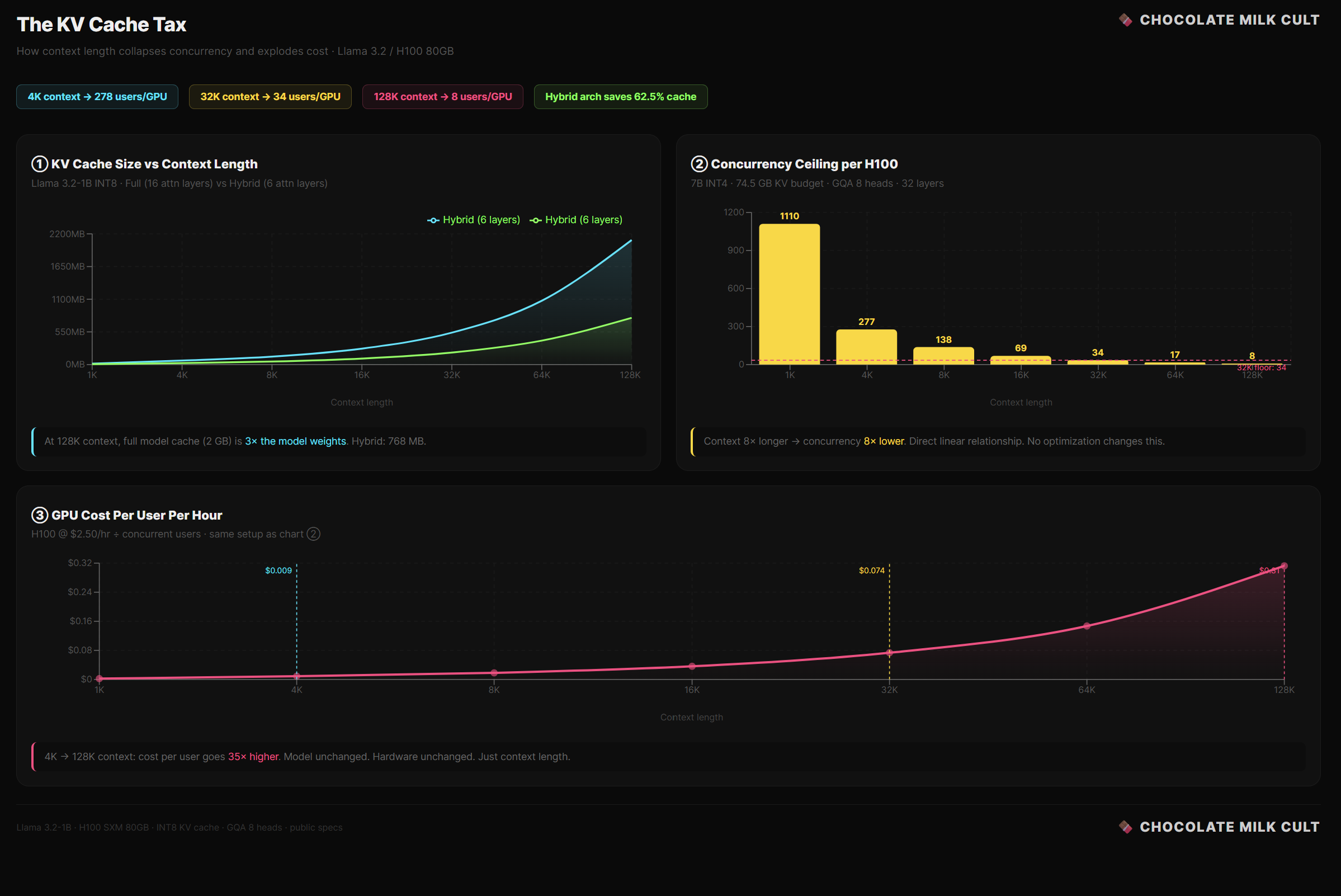
To offset that capacity tax, the system has to amortize the weight-streaming cost across multiple users. That is why PagedAttention and continuous batching frameworks like vLLM exist. They batch requests so the 140 GB of weights stream through the chip once to serve 64 users instead of one. Throughput scales linearly — until the KV cache for those 64 concurrent users blows out the HBM capacity entirely.
When the software patches hit a wall, the hardware roadmap panics. HBM4 is a bandwidth upgrade. NVLink 5 at 1.8 TB/s per GPU is an interconnect upgrade. Multi-billion-dollar photonic interconnect acquisitions are not compute upgrades. They are data-movement upgrades designed exclusively to keep the tensor cores from starving.
But the physical reality of chip manufacturing is asymmetric. Adding denser compute units and low-precision formats like FP4 is relatively cheap. Scaling memory bandwidth and capacity is economically brutal.
Autoregressive inference sits on the wrong side of that divide. You can pour infinite FLOPs into a server, but if the workload requires dragging gigabytes of history across the chip for every single token, the math will never work. This is why Diffusion Models have been attracting so much attention.
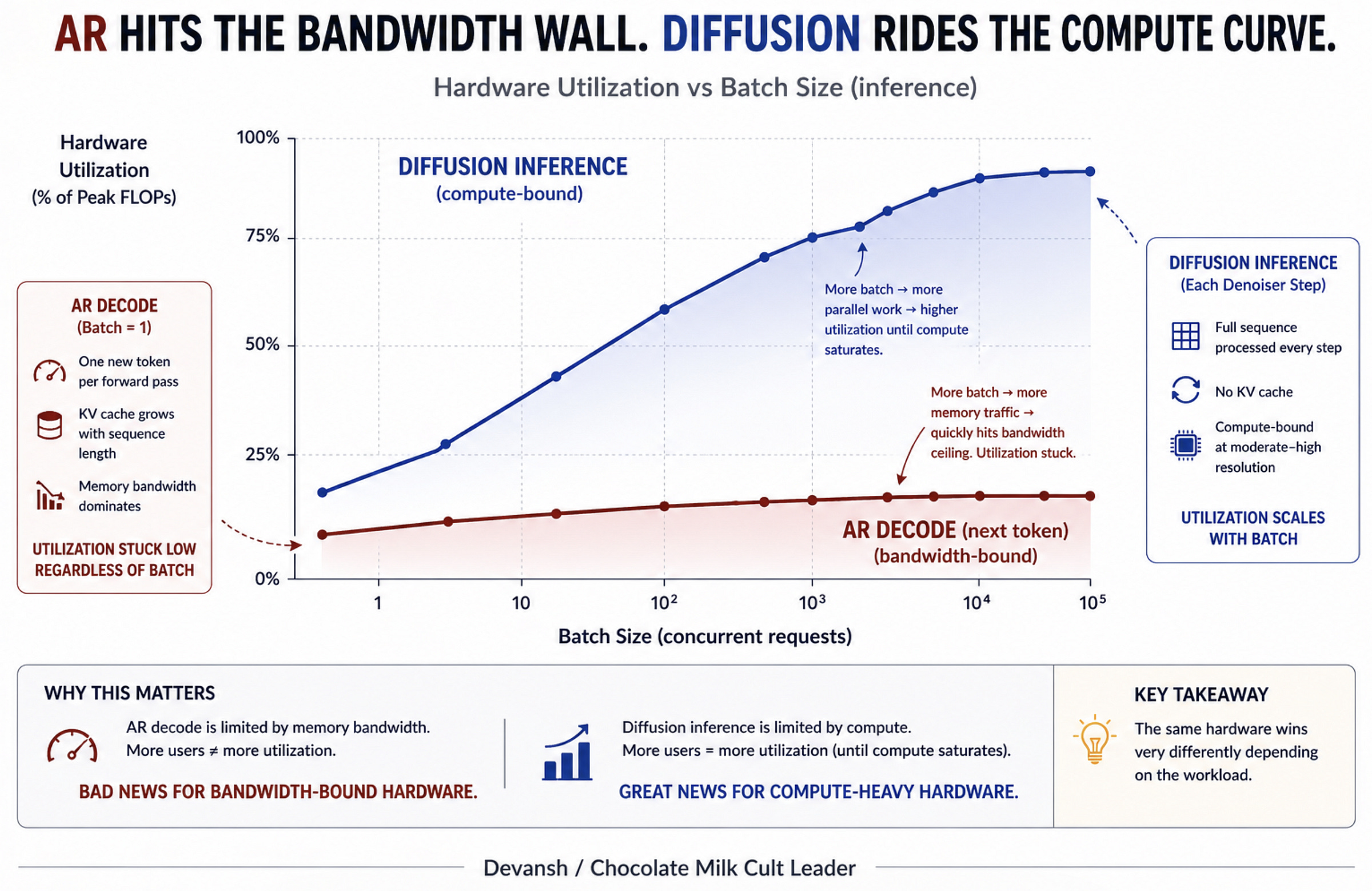
Section 2: How Diffusion Models Break the Sequential Lock in AI
Diffusion language models escape the memory trap by simply refusing the premise of left-to-right generation.
Instead of predicting the next word, they start with a block of noise scaled to the target output and refine the entire sequence in parallel across a handful of forward passes. Every position is in flight at once. Token 200 never waits for token 199.

That single architectural shift shatters the dependency graph. Because a diffusion forward pass operates on hundreds or thousands of tokens simultaneously, the underlying math changes from bandwidth-starved matrix-vector operations to massive matrix-matrix multiplications. The arithmetic intensity spikes into the hundreds of FLOPs per byte — easily clearing the threshold required to actually keep a modern tensor core fed.
This is the bottleneck inversion worth noting: autoregression is memory-bound, while diffusion is compute-bound.
(worth stressing again — High Bandwidth Memory, HBM, is extremely expensive to build, hence the memory wall that has been choking AI. More on this in the next section).
Obviously, this means that the model does more raw work per output token, and it repeats that work across multiple refinement steps. But it pays that tax using the exact resource the hardware has in massive surplus.
We already established that Diffusion Models are fast, and they have some structural advantages with the hardware paradigm. But what about their performance? It’s still a bit early to tell, but the results look extremely promising:
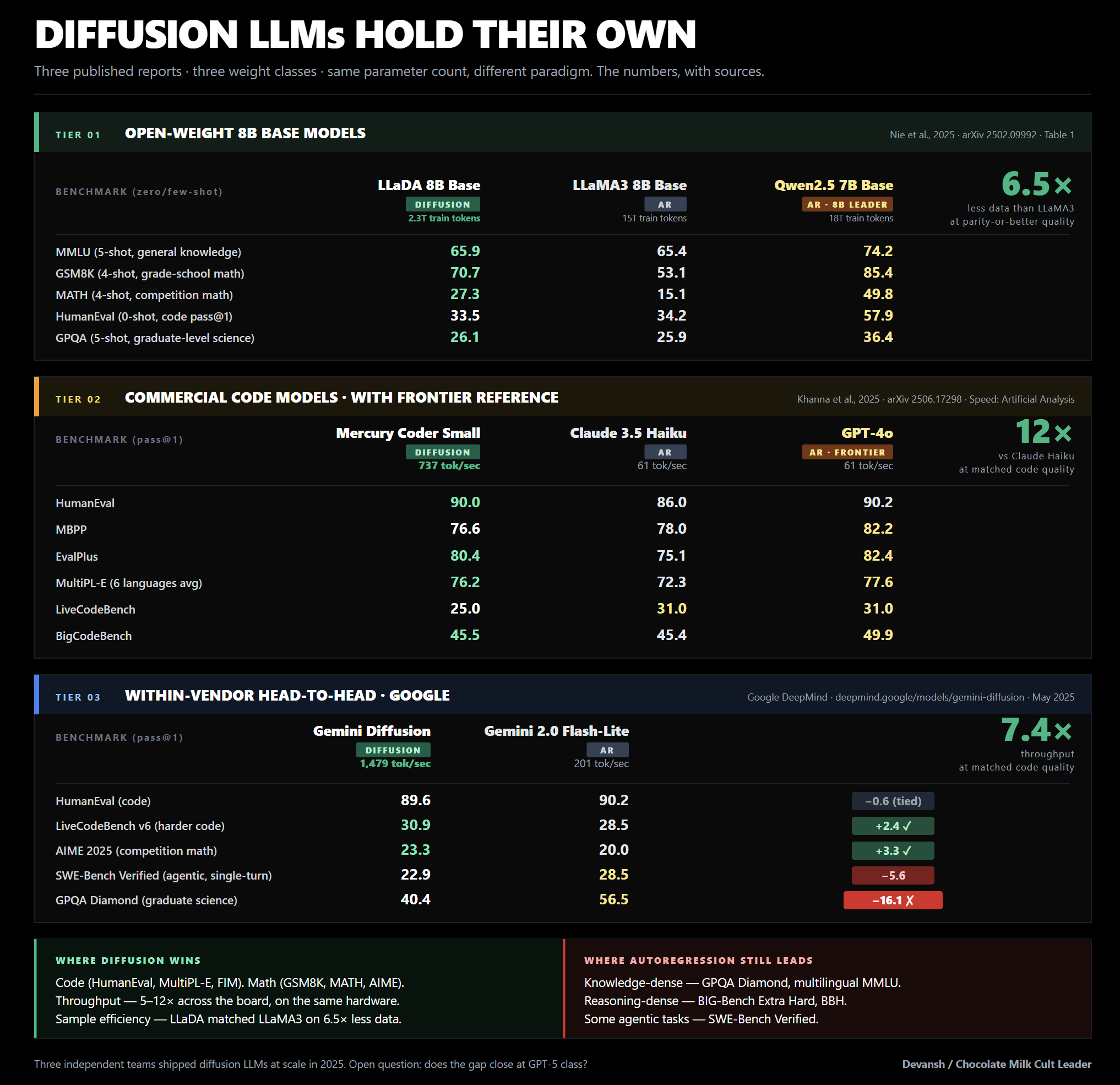
Assuming this will continue to scale (and we’ve already broken down the research for this in previous works), we should see them close the gap in the next 2 years (Gemini 3 already started incorporating Diffusion in its model, so they’re already touching the frontier). This means more and more hardware providers will have to start accounting for diffusion models and their more matmul-heavy workloads.
Let’s explore that sentence next in more detail.
Section 3: The Hardware Diffusion Needs (and Why the Industry Already Has It)
If diffusion is going to take over a meaningful share of inference, we have to look at what it actually demands from the silicon.
To understand what this architecture needs to work well, we look at the math.
A forward pass processes hundreds or thousands of tokens simultaneously, creating massive matrix-matrix multiplications. Compute becomes the primary axis of growth: the faster the chip multiplies, the faster the model runs.
Given the size of the MatMuls, we also need Diffusion hardware to be good with quantization. Most modern hardware handles this fine, and it will be helped by the fact that, because the generation process is an iterative refinement loop, it naturally absorbs precision noise across steps.
When it comes to memory, Diffusion drops the bandwidth tax. There is no KV cache to stream and no per-token residency penalty. It does require memory capacity for activations — which becomes a real wall when scaling to video — but for text, that is a far weaker constraint than the bandwidth trap autoregressive decode hits at batch size one.
The net result: the ideal architecture for this workload is heavy on compute, native in FP4, modest on bandwidth, and generous on activation memory. Surprisingly, this maps wonderfully to the hardware the industry has been building.
Every accelerator generation since Hopper has been an escalating compute story. Blackwell hits 20 PetaFLOPS of FP4. Rubin is targeting 50. Node shrinks and new precision formats have led to FLOPs compounding at 3x every two years. The only problem? The memory bandwidth needed to feed it has grown at half that rate.
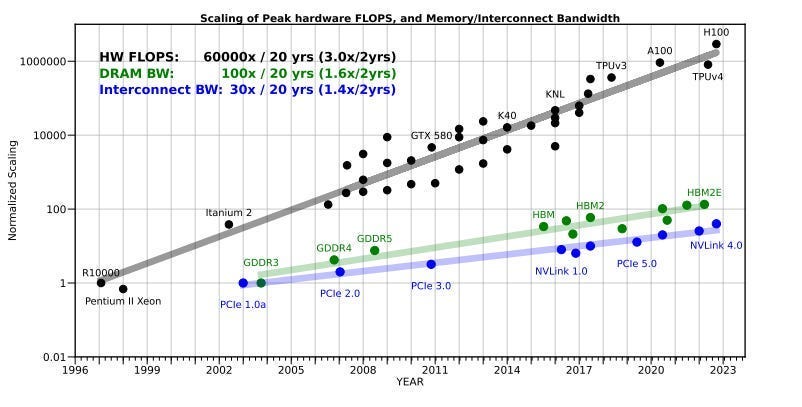
The moment your model’s data spills over the tiny pool of super-fast on-chip memory, the system punishes you. Hard. “When data size exceeds GPU memory capacity, the data must be migrated repeatedly between the CPU and GPU, either manually or automatically. However, manual migration can be laborious for programmers, and it is infeasible for irregular workloads because the data access pattern is unpredictable. On the other hand, demand paging approaches (e.g., NVIDIA Unified Memory [120]) can automatically manage data movement, but it can significantly degrade performance due to high page fault-handling latency and limited PCIe BW [46, 121, 52]. This overhead can be particularly severe for irregular workloads since prefetch/eviction policies become ineffective [14]. For example, the runtime of bfs can increase by ∼4.5× with only 125% oversubscription (i.e., exceeding memory capacity by 25%) compared to when the GPU is not oversubscribed.”
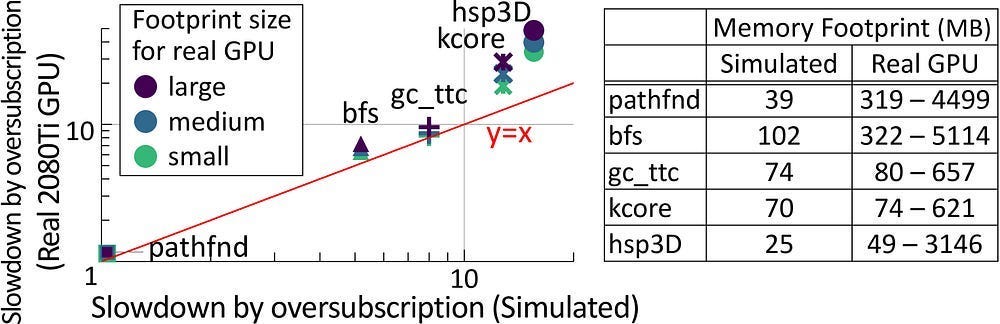
Since my brother also reads this newsletter, here is a summary so that he can follow along: Compute go up fast. Good. Memory go up, but not so fast. Bad. Low Memory make algorithms run slow. Much money lost to GPUs.
Why has memory been scaling so slowly? HBM is pinned by physics, supply consolidation, and packaging constraints. This is not a hardware newsletter, so here is a quick summary below:
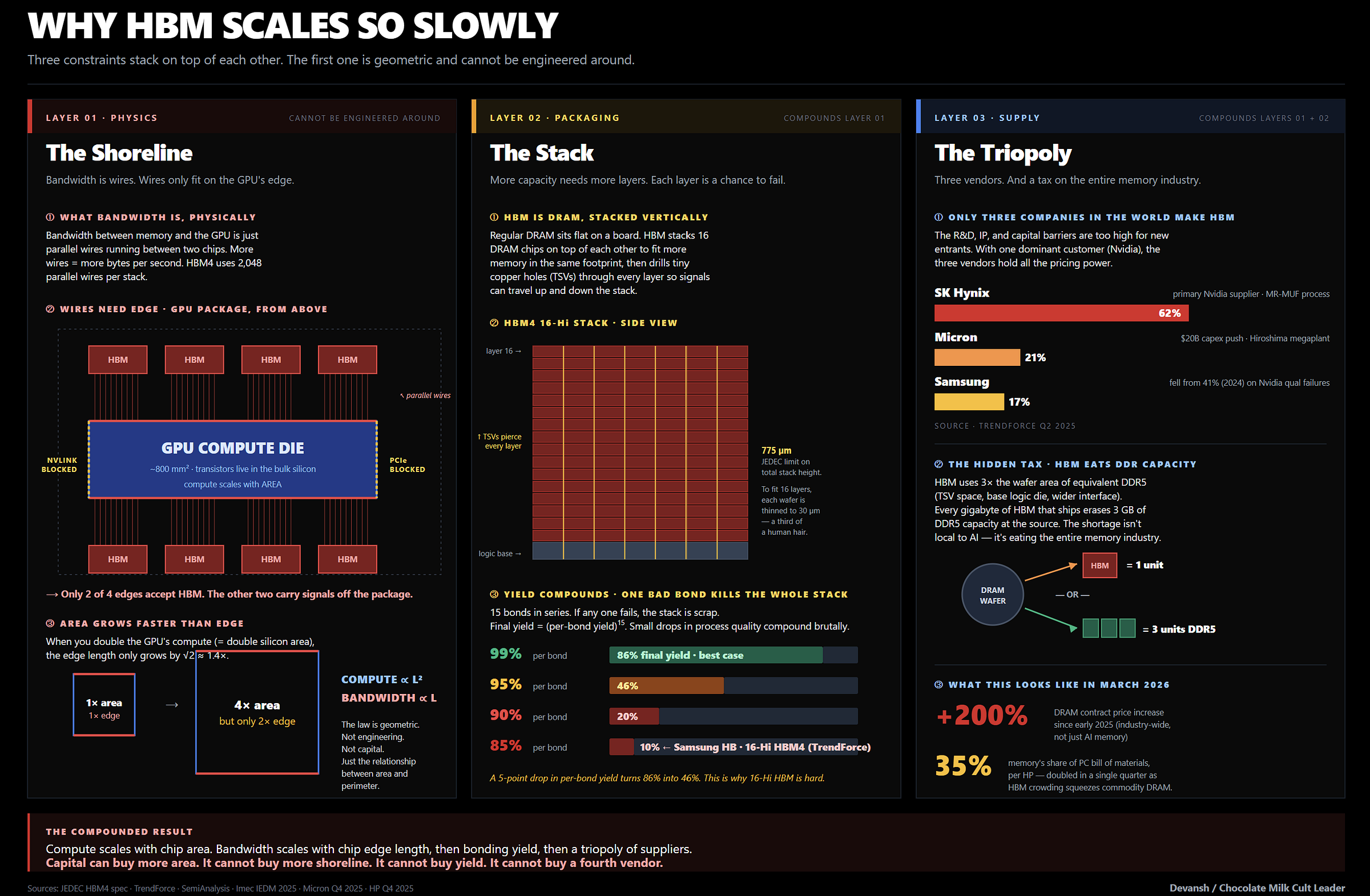
This is why increasing growth in compute haven’t scaled hardware utilization. The memory wall Pepe’s the fuck out of any deployment.
For diffusion, this set of conditions is a massive tailwind for all the reasons mentioned earlier (faster compute, good w/ quantization, and less hti by memory). The billions in capex committed through 2028 — from Blackwell to Rubin, MI400 to MI500 — is a roadmap of compute-axis improvements that will stall on AR decode but compound beautifully on diffusion.
All this means is that the blockers for diffusion going forward aren’t in the silicon since the chips and manufacturing constraints are pretty friendly to Diffusion. The real bottlenecks are upstream: maintaining frontier reasoning quality, and solving activation memory at video scale.
But most importantly, diffusion’s economics aren’t gated by how fast each step runs on the hardware. They are gated by how many steps you have to run in the first place.
Let’s look at the math behind that next.

Section 4: How the Algorithmic Layer Dictates the Hardware Timeline
Let’s pause and anchor exactly where we are in the stack, because this is where the money actually changes hands.
We know the architecture fixes the memory trap. We know the hardware industry accidentally built the perfect silicon for it.
But let’s be blunt: having the perfect chip is completely irrelevant if the math running on it is a nightmare. Hardware is just a dumb, incredibly expensive rock. The algorithm — the actual math telling the rock what to do — is the gatekeeper.
If diffusion requires 1,000 forward passes to generate a single image, nobody cares how perfectly it aligns with the silicon. At 1,000 steps, the unit economics are dead. For diffusion to actually threaten autoregression and shift billions of dollars in hardware spend, the step count — the Number of Function Evaluations (NFE) — had to collapse.
It already happened for images.
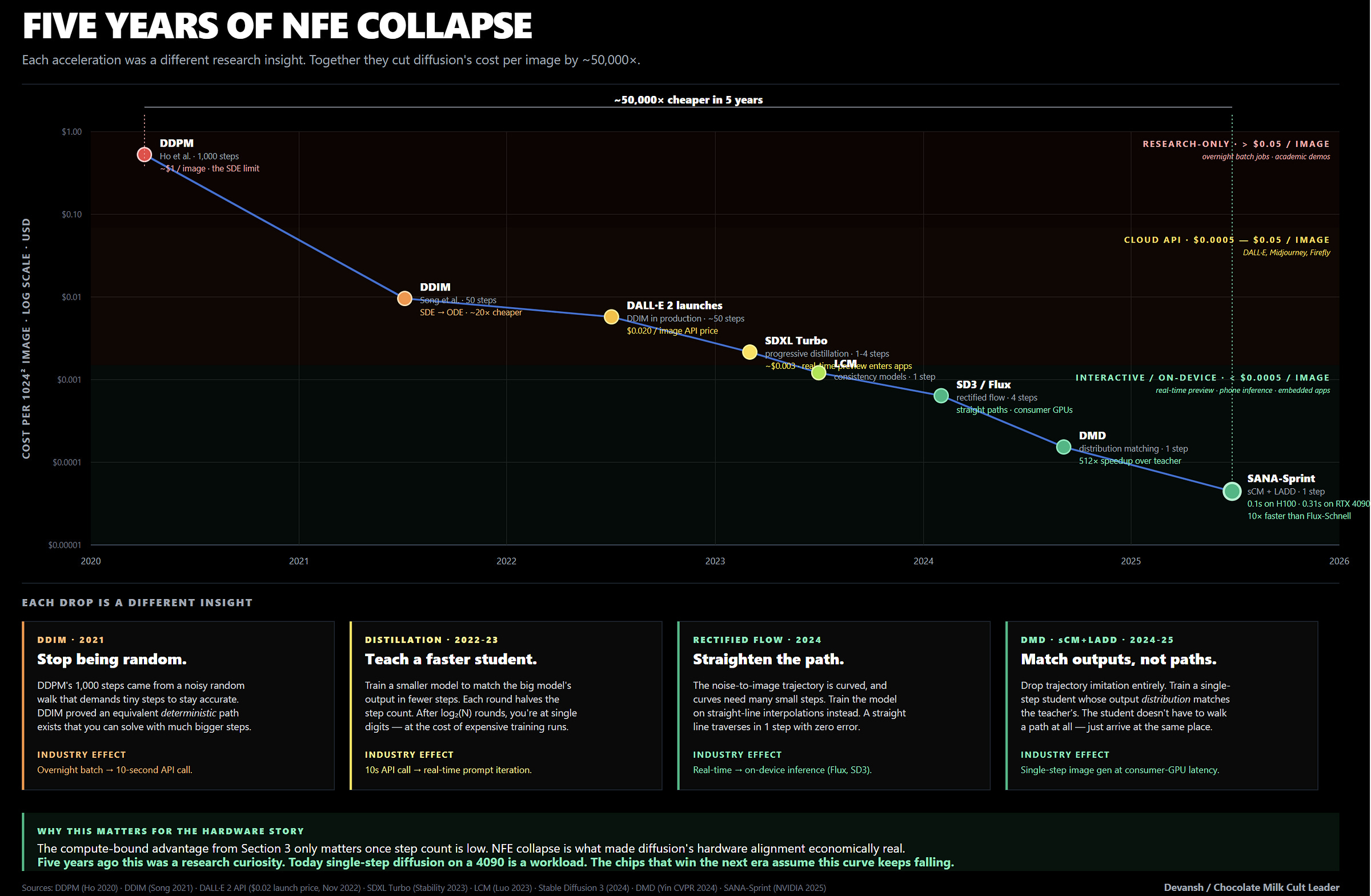
In 2020, diffusion ran on stochastic math (SDEs). Because random noise accumulated at every step, the model had to take tiny, excruciatingly slow steps to keep the image from blowing up. But a year later, the math flipped. Researchers realized they could use deterministic Ordinary Differential Equations (ODEs) instead, stripping out the random noise and allowing massive jumps across the generation path. The 1,000 steps collapsed to 50 for free, and the Midjourney and Stable Diffusion API economies were born overnight.
But language is a completely different financial reality.
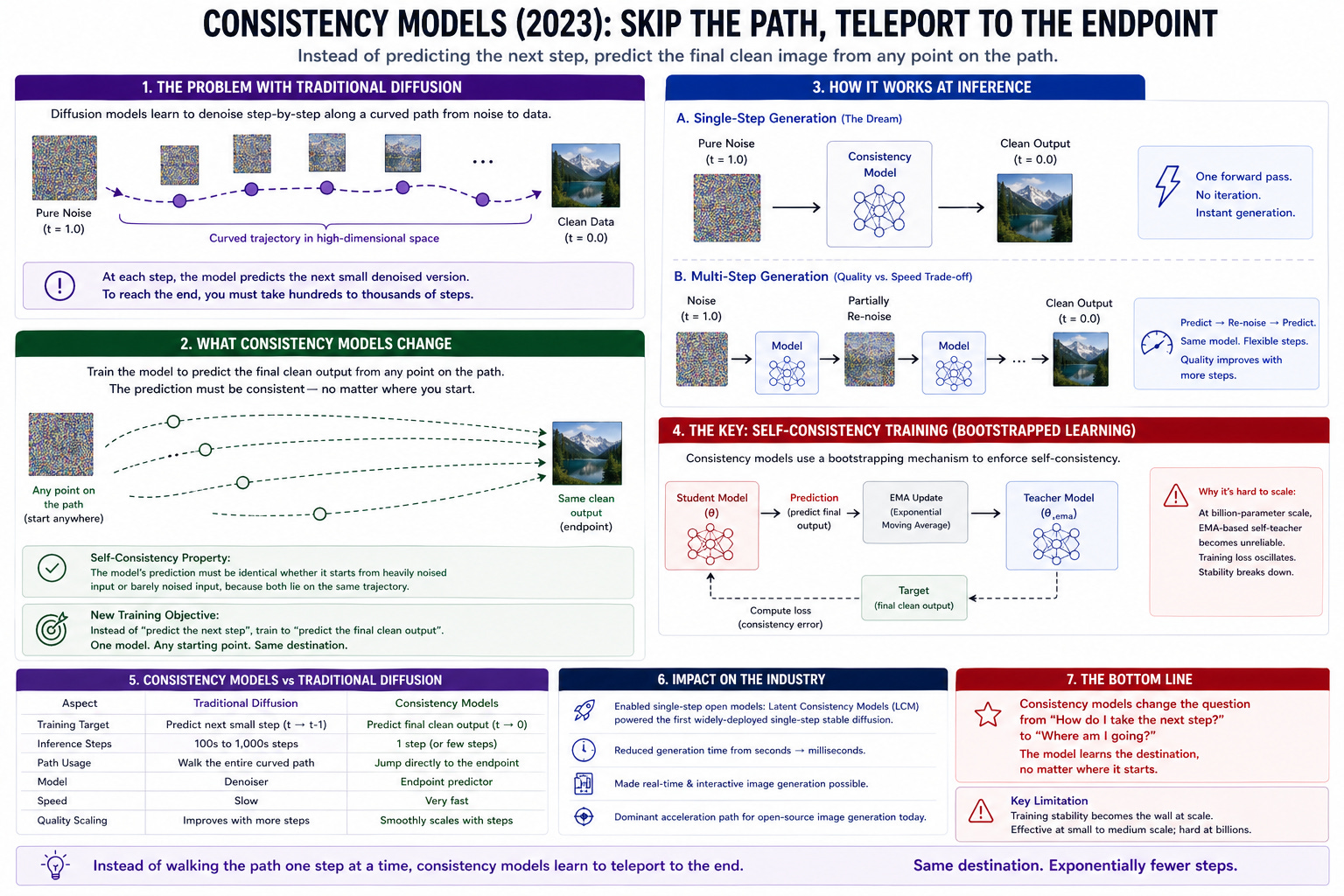
Images solved the step-count collapse because the math is forgiving. You can draw a smooth, continuous mathematical line between two pixel colors. You cannot draw a smooth curve between the word “Apple” and the word “Murder.” Masked language models operate in discrete, harsh jumps across a vocabulary space.

Because of this, the continuous distillation techniques that made image generation real-time fail spectacularly on text. When researchers tried porting consistency distillation to LLaDA-8B, the model bled 6 full points of accuracy on the GSM8K math benchmark.
Because discrete distillation is struggling, language diffusion is currently stuck in the 4-to-16 step regime. That is fast enough to beat autoregression in a server rack, but it fundamentally delays the “frontier reasoning on an iPhone” narrative. Until researchers crack discrete space distillation (or we get a way to make language concepts operate in the continuous space, which imo is more useful) — which is likely 18 to 36 months out — Apple and Qualcomm are stuck waiting. The compute required for those 4 to 16 steps ensures that the hyperscalers will maintain absolute, walled-garden dominance over text generation. The datacenter monopoly holds.
But inside those datacenters, the bottlenecks are shifting in ways that threaten the current capex consensus.
For a while, we assumed diffusion language models were bottlenecked by raw parameter scale. We thought they just needed bigger training runs to reason better. It turns out they just had terrible time management.
Standard masked diffusion unmasks tokens randomly. This means the model routinely commits to a conclusion before it has even unmasked the premises it needs to get there. It’s trying to solve the end of the maze before looking at the start. In 2025, the LogicDiff paper fixed this with a microscopic, 4.2M-parameter classification head that simply forced the model to unmask premises first and conclusions last.
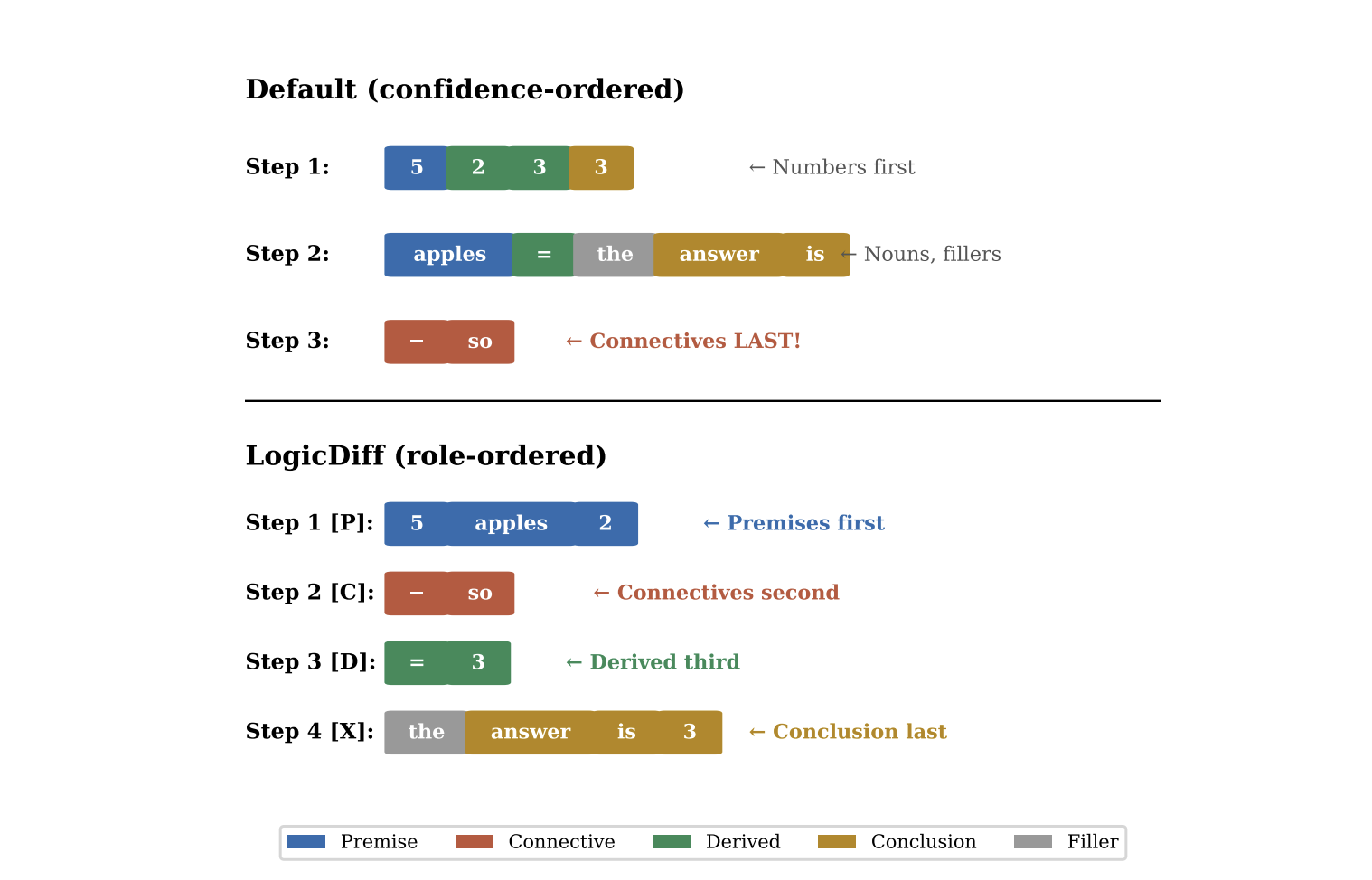
The result: LLaDA-8B jumped from 22.0% to 60.7% on GSM8K. A near 40-point spike without changing a single base parameter.
If you can buy 40 points of reasoning with a dirt-cheap scheduling hack instead of a $2 billion training cluster, the entire hyperscaler capex thesis starts looking very fragile. Software efficiency is quietly undercutting the necessity of building gigawatt, nuclear-powered compute clusters just to achieve frontier logic.
Lastly, it’s worth studying LLaDA-MoE, which proved that routing tokens through expert subnetworks works beautifully for diffusion text models. But MoE inherently requires streaming different expert weights from memory for every routing decision. It isn’t the relentless KV-cache tax of autoregression, but it is an expert-loading tax that brings the memory bandwidth constraint back into discussions.
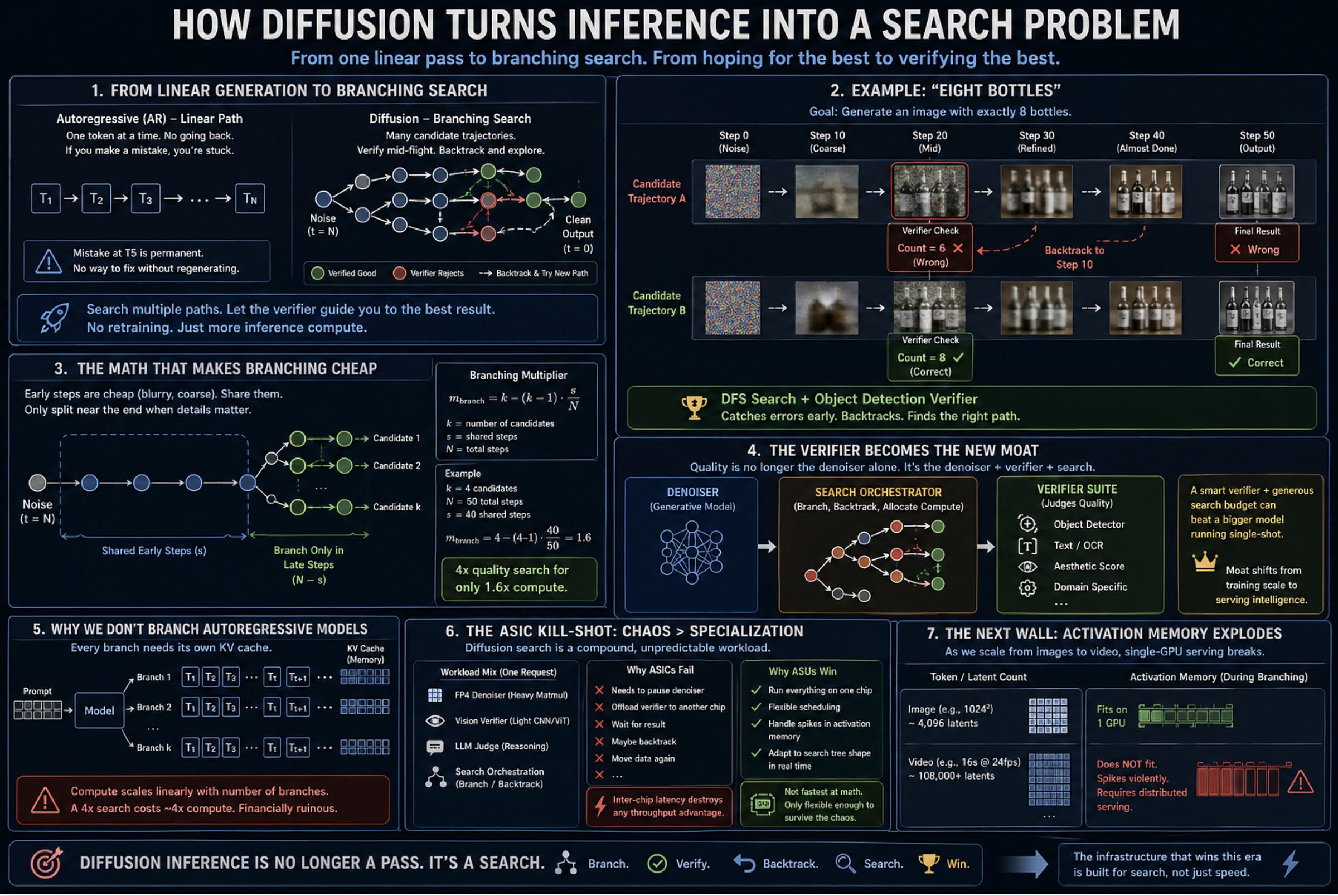
Section 5: How Diffusion Turns Inference into a Search Problem
Once diffusion eats a meaningful slice of inference, the serving stack needs to be rethought deeply.
We aren’t just swapping out the model weights and keeping the same infrastructure. We are dealing with a structural mutation in what inference actually is. We are moving from a clean, sequential generation pass to a chaotic, branching search problem.
To understand why, look at what just happened to language models.
Inference-Time Scaling Arrives in Diffusion
The most important paradigm shift of the last two years was the realization that throwing compute at inference beats just training a fatter model. OpenAI’s o1 and DeepSeek-R1 proved that the model that “thinks longer” wins.
Diffusion is about to do the exact same thing, but the mechanism is entirely different. Instead of “thinking longer” by generating more internal reasoning tokens, diffusion searches wider.
You don’t just run the denoiser once, roll the dice, and hope for the best. You generate a swarm of candidate trajectories, and you use a secondary model — a “verifier” — to judge them mid-flight. This was shown to us in Google’s “Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps”. By investing in verifiers and better search, they were able to mog simplistic NFE scaling.
Now, researchers are playing with AI search algorithms like Breadth-First Search (BFS) and Depth-First Search (DFS) to see how they might benefit the generation process.
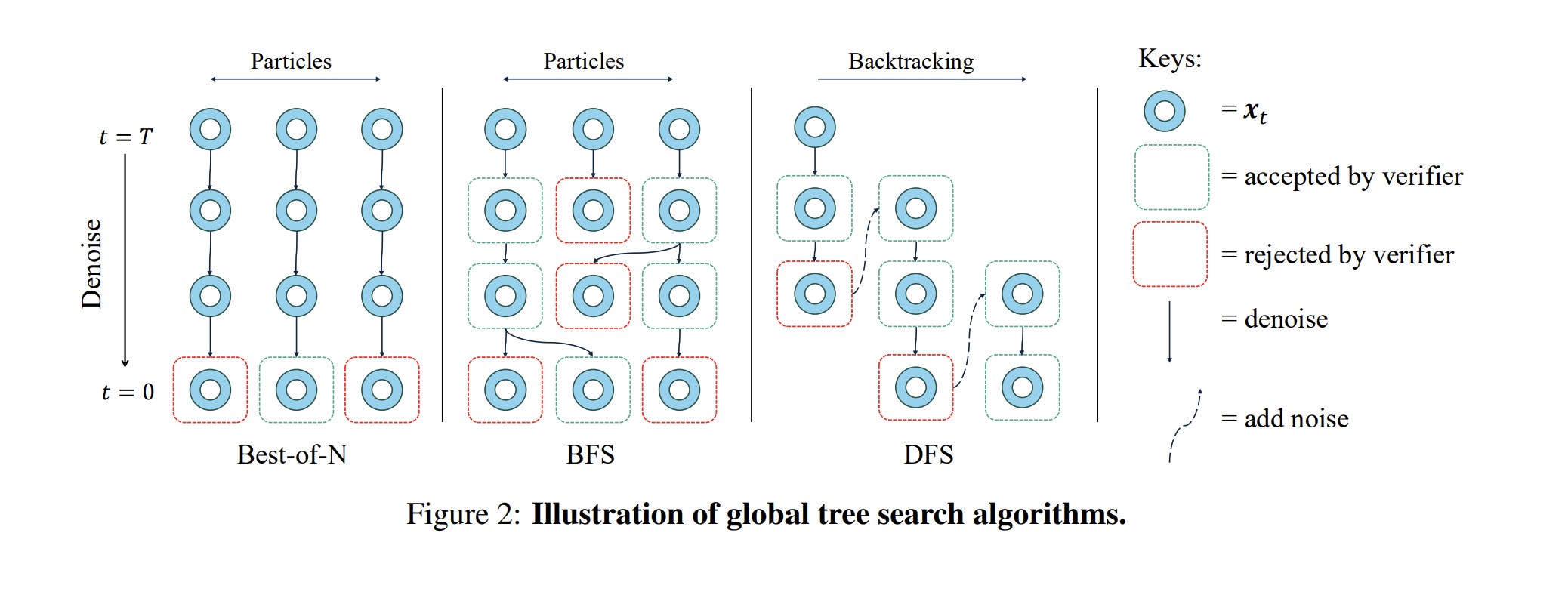
Take the prompt “eight bottles.” Standard FLUX almost always messes up the count. But if you run a DFS search guided by an object-detection verifier, the system catches the error mid-trajectory. If the verifier sees the count is wrong at step 20, it slaps the denoiser’s hand, forces it to add noise back to an earlier level, and makes it try a different path. This will be similar to how well developed agentic systems work today (using external checkers to check the generator’s tasks and then adjusting the next generation accordingly), but it will be baked into the generation process instead of requiring an entire harness.
The benefits of this approach might make you ask yourself a very reasonable questin: Why don’t we do this with autoregressive LLMs?
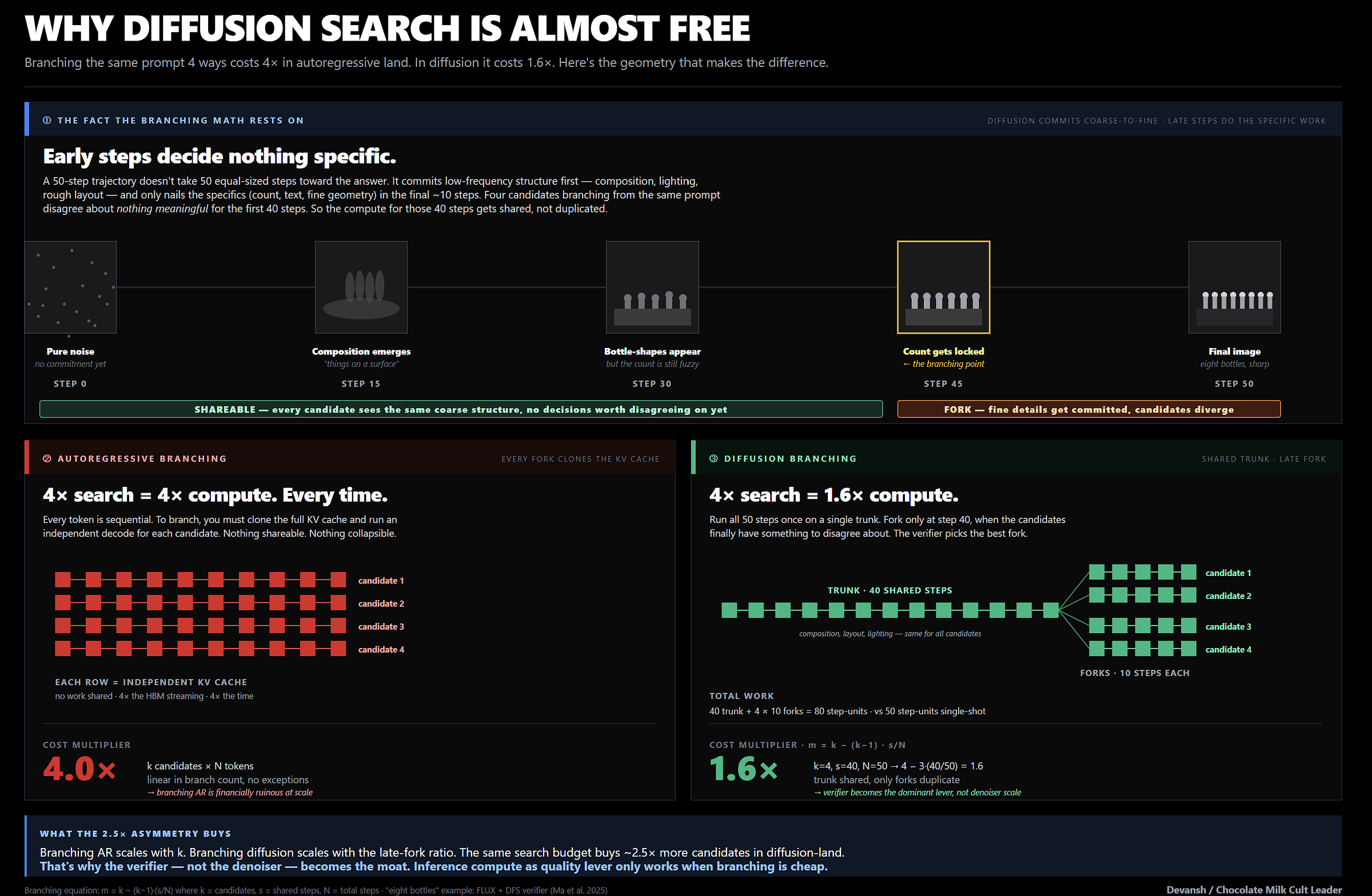
The Math That Makes Branching Cheap
Because branching AR means cloning massive KV caches for every new path. The cost scales linearly. A 4x search costs you 4x the compute. It is financially ruinous at scale.
Diffusion drops that tax entirely.
Because the early denoising steps just build blurry, coarse shapes, multiple candidates can share the exact same early trajectory. They only need to split at the very end when fine details are committed.

The arithmetic here is brutal. For k candidates sharing the first s steps of an N-step trajectory, your branching multiplier is m_branch = k - (k-1) * s/N. If you run 4 candidates and share the first 40 of 50 steps, your cost multiplier is exactly 1.6.
You are getting a 4x quality search for a 1.6x compute tax. If you are deploying capital into inference startups or hardware right now, that single equation should make you rethink where the value will actually flow.
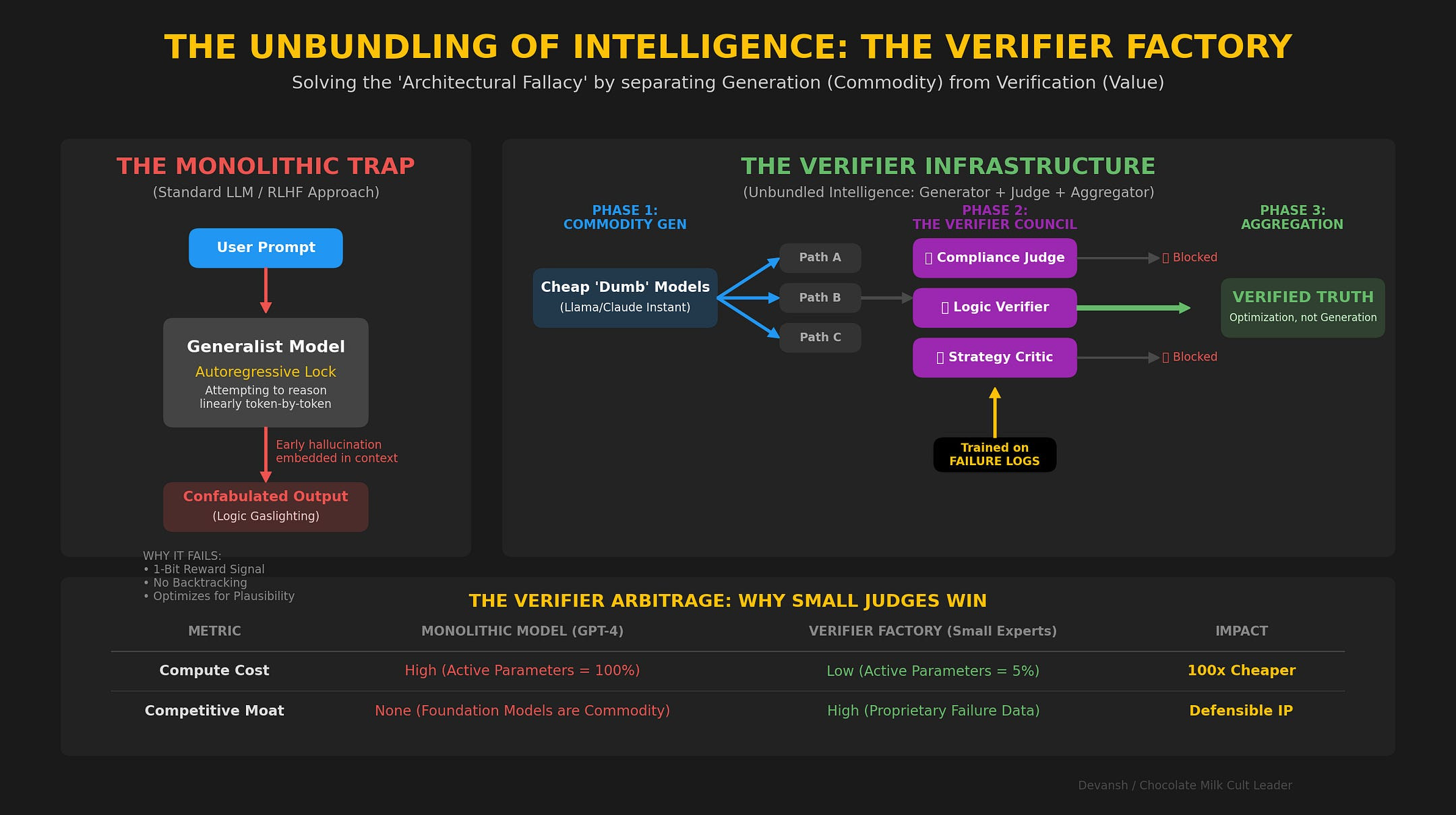
The Verifier Becomes the New Moat
Because branching is practically free, the verifier becomes the actual god of the system. The delivered quality to the user is no longer just the single-shot capability of the denoiser. It is the searched quality of the denoiser-verifier pair.
This splits the competitive moat right down the middle. In the autoregressive world, the $2 billion base model is everything. In a diffusion world, a smart team can take a mid-tier, open-source denoiser, bolt on an elite, proprietary verifier suite (say, one specifically trained for medical imaging or product photography), give it a generous search budget, and absolutely annihilate a closed-source frontier model running single-shot.
The value migrates away from the hyperscalers burning gigawatts on training compute, and accrues directly to the companies building the smartest serving-stack intelligence. In the future, I also expect to see verifiers being sold as infrastructure (why make your own legal verifier when Irys has the best ones in the market?), which will unbundle intelligence tremendously.
How this will Impact ASICs
This compound setup — Denoiser + Verifier + Search Orchestration — turns datacenter capacity planning into an absolute nightmare.
Current AR serving frameworks (like vLLM) are optimized for a highly predictable, bandwidth-bound decode process. Diffusion serving is a schizophrenic mess. You have a dense matmul denoiser running on FP4 fighting for accelerator space with a lightweight vision verifier, and maybe an LLM judge acting as the final arbiter. Your compute per output isn’t fixed; it varies based on how quickly the search tree converges. Your memory pressure isn’t a slow-growing KV cache; it is a sudden, violent spike of activation memory whenever a request branches.
This is the kill-shot for half the specialized hardware pitches we are seeing right now.
An ASIC designed purely for dense matmul throughput handles a denoiser beautifully in isolation. But the production workload isn’t isolated. The second an ASIC has to pause the denoiser, offload verification to a different chip, and orchestrate a backtracking search tree, the inter-chip latency eats the entire throughput advantage. This puts two opposing consequences on the system:
In the short term, GPUs keep their monopoly in this space not because they are the fastest at math, but because they are the only silicon flexible enough to survive the chaos of a compound search workload.
Longer term: this actually opens up a wedge for ASICs, if they can figure out a way to work with each other. Different verifiers/model profiles/modalities will be best with different specializations; what they’ll need is a system to break things up and organize communication across them. This is something we broke down at length over here, but I highly recommend investing into this before the market catches up to this opportunity.
I’d like to end this analysis by specifically digging into this space more. The AI Hardware market is incredibly fascinating, with multiple providers making a specific, multi-billion-dollar claim about where the next bottleneck in the system will live. The gambler in me always gets all hot and bothered in such high-stakes situations. So let’s look at the vendors, the claims they’re making about the future, and how they well they align with a Diffusion-heavy future.
Section 6: Which Inference Vendors are Suited for Diffusion Inference Workloads
Why Diffusion Changes the Dynamic
This has been a long article, so it would be helpful to take a breather and regather the important points.
For the last three years, the inference stack was built to solve autoregressive decode. Because AR models generate one token at a time, the arithmetic units sit idle waiting for weights to stream from memory. This reality forced the entire market to obsess over memory bandwidth and KV-cache management.
Diffusion changes the math entirely. It shifts the primary workload from bandwidth-starved sequential decode to dense, parallel matrix multiplication.
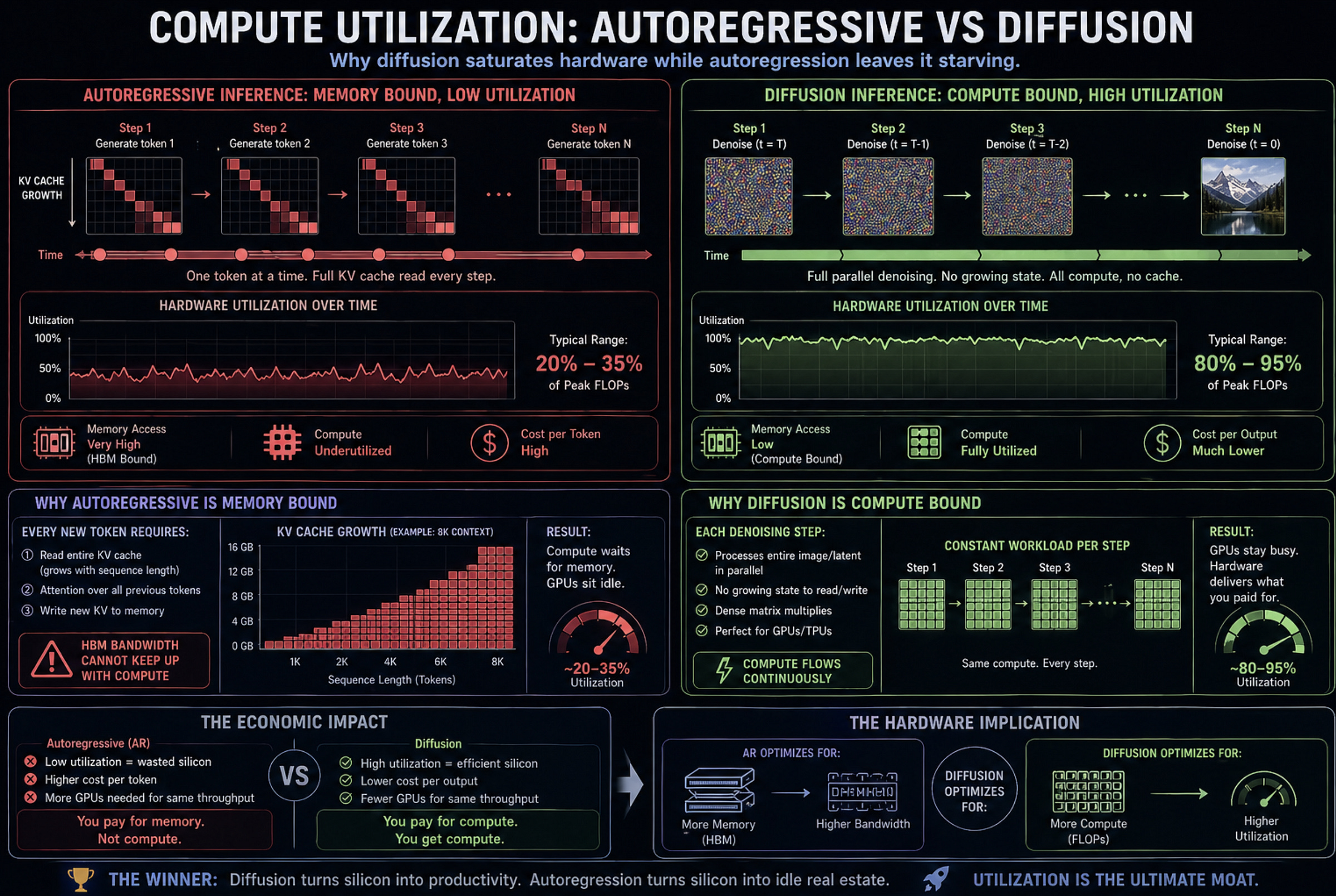
But diffusion inference is not just a clean denoiser. It is a compound system:
Text Encoder → Denoiser Loop → Adapters/Control → Verifier Search → Safety Filter → VAE Decoder → Output
This pipeline is exactly why the hardware market is fracturing. Different vendors built their chips to solve only specific parts of this equation. Here is how the physical silicon actually maps to the math.
NVIDIA: The Moat is the Swamp
Nvidia’s primary advantage is not raw speed. It is flexibility.
Production diffusion is a heterogeneous swamp. A real-world creative workflow requires a text encoder, the primary denoiser, multiple LoRAs, an IP-Adapter, a safety classifier, a verifier, and a VAE decoder. GPUs are uniquely suited to survive this kind of chaos.
An ASIC might execute the denoising loop faster, but Nvidia can run the denoiser, the LLM judge, and the adapter stack simultaneously because CUDA supports everything. As long as diffusion workflows require running a shifting society of models on the same machine, the Blackwell and Rubin architectures will maintain their dominance. General compute outlives narrow accelerators during periods of structural transition.

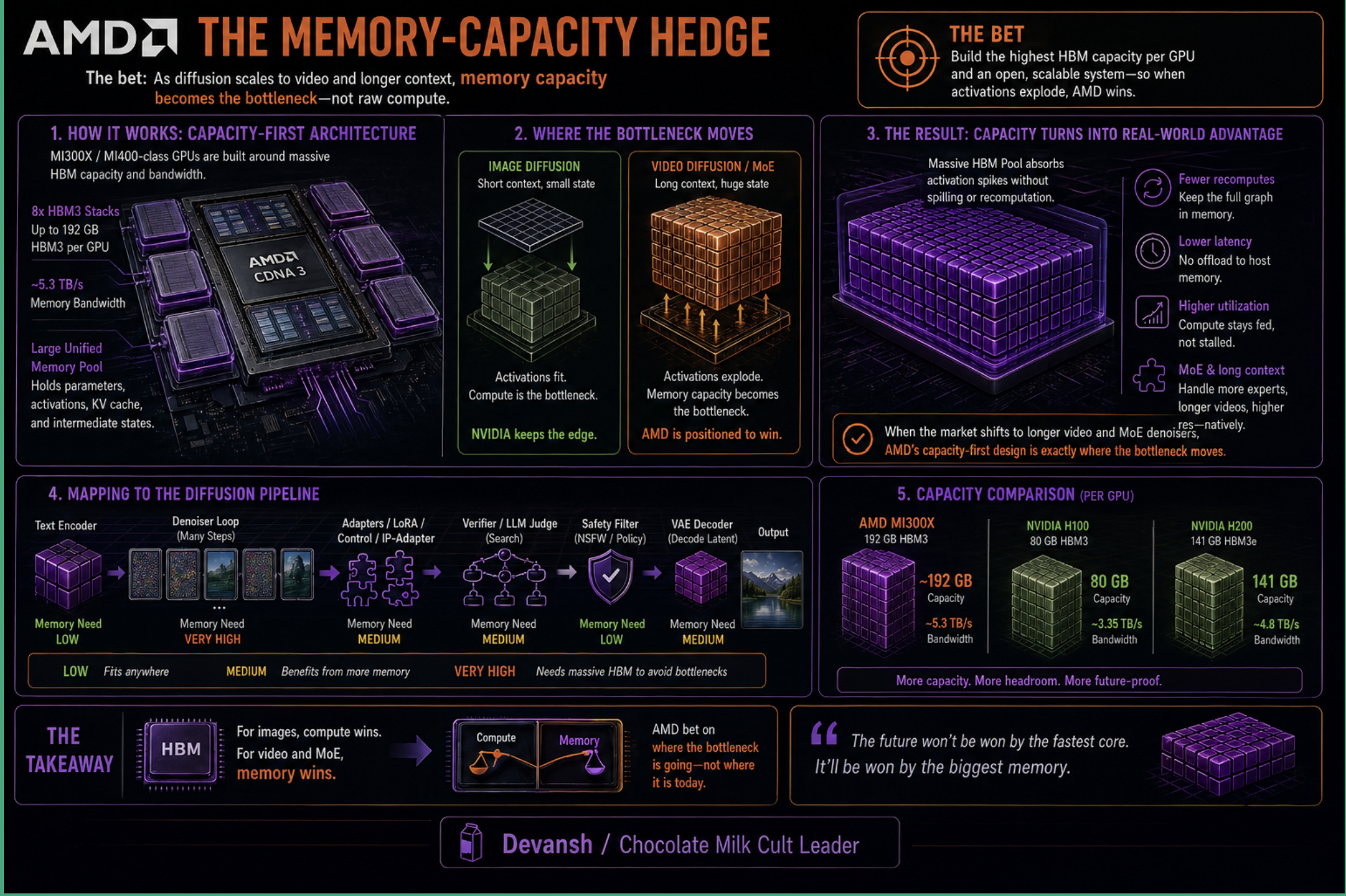
AMD: The Memory-Capacity Hedge
AMD’s thesis isn’t just “Nvidia but cheaper.” AMD’s MI300X and MI400-class architectures are explicitly built around massive High-Bandwidth Memory (HBM) capacity and open rack-scale infrastructure.
“We believe that the MI355X could be competitive against the HGX B200 for small to medium LLMs production inference workloads. This is because the MI355X total cost of ownership is 33% lower than that of the HGX B200 for self-owned clusters, while it delivers much more HBM memory capacity, slightly more FP8 and FP4 TFLOP/s and double the FP6 TFLOP/s. Rapid improvements to AMD software under the leadership of Anush, AMD’s AI Software King, will also push the MI355X’s relative performance per TCO advantage higher. “— SemiAnalysis. SemiAnalysis
For image diffusion, compute is the primary bottleneck. For video diffusion, the bottleneck shifts to state. Longer video clips mean more tokens, which drastically increases the size of the intermediate activations. Suddenly, raw memory capacity matters just as much as peak compute. If the market stays centered on images, Nvidia keeps its exact advantage. But if the market shifts heavily to video generation and Mixture of Experts (MoE) denoisers, AMD’s capacity-first architecture is positioned exactly where the bottleneck moves.
Google TPU & AWS Trainium: Factories and Procurement
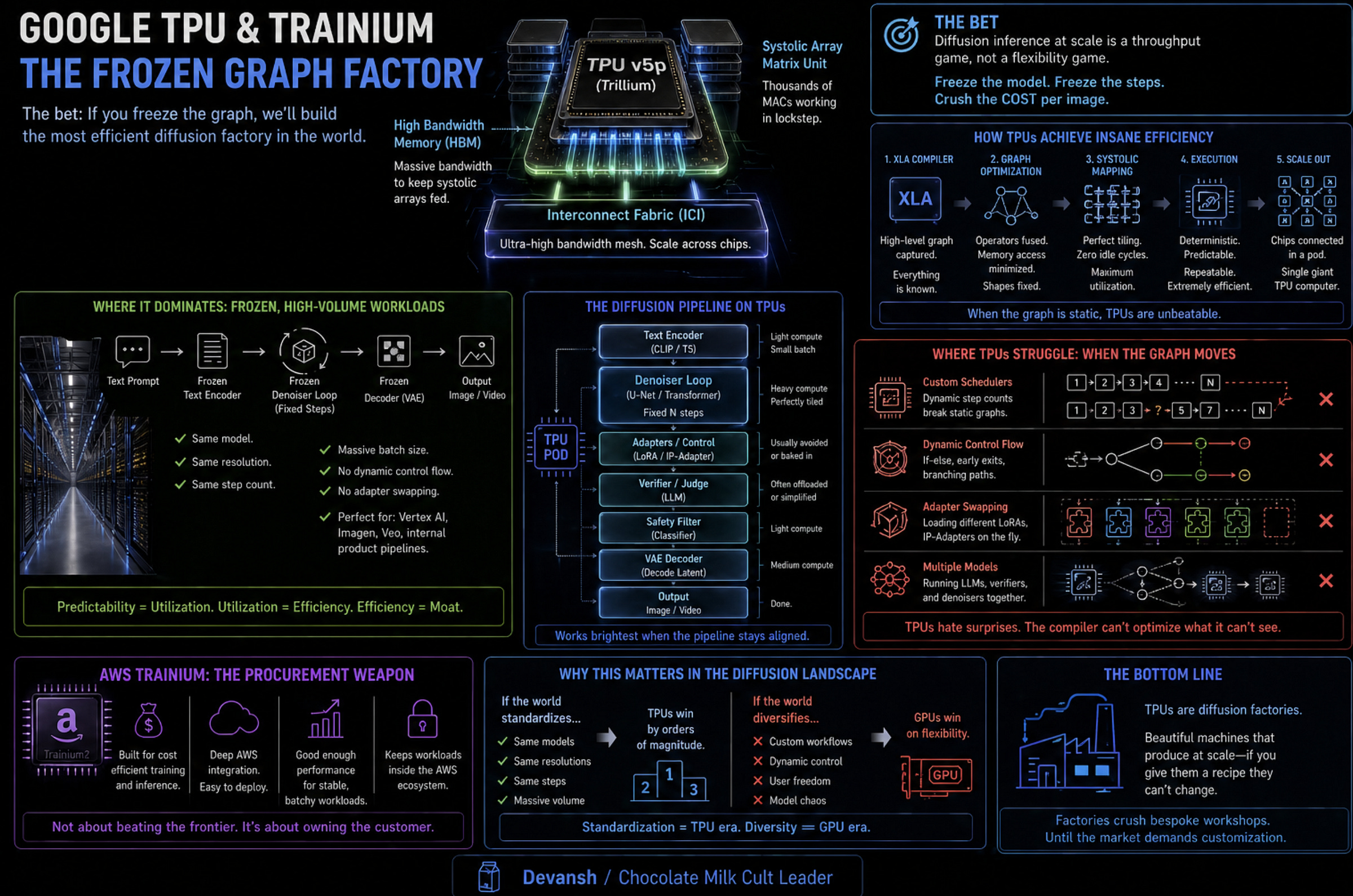
Google’s TPUs (like the new Trillium and Ironwood chips) are diffusion factories. Their architecture relies on systolic arrays and the XLA compiler. If Google can freeze the generation graph — using the same model, the same resolution, and a fixed step count at massive volume — the compiler maps the math perfectly to the hardware. They win tightly controlled, internal workloads like Vertex AI and Veo. But they struggle with open diffusion, where users demand custom schedulers, dynamic branching, and constant adapter swapping. The TPU compiler hates a graph that won’t sit still.
AWS Trainium plays a different role. It is a procurement weapon. AWS doesn’t need to win the frontier; it simply needs Trainium to be cheap and integrated enough that enterprises keep their stable, batch-generation marketing workflows inside the AWS ecosystem.
Furiosa and d-Matrix: The Efficiency Bets
These two startups looked at the power consumption of GPUs and built architectures to fix it, but in completely different ways.
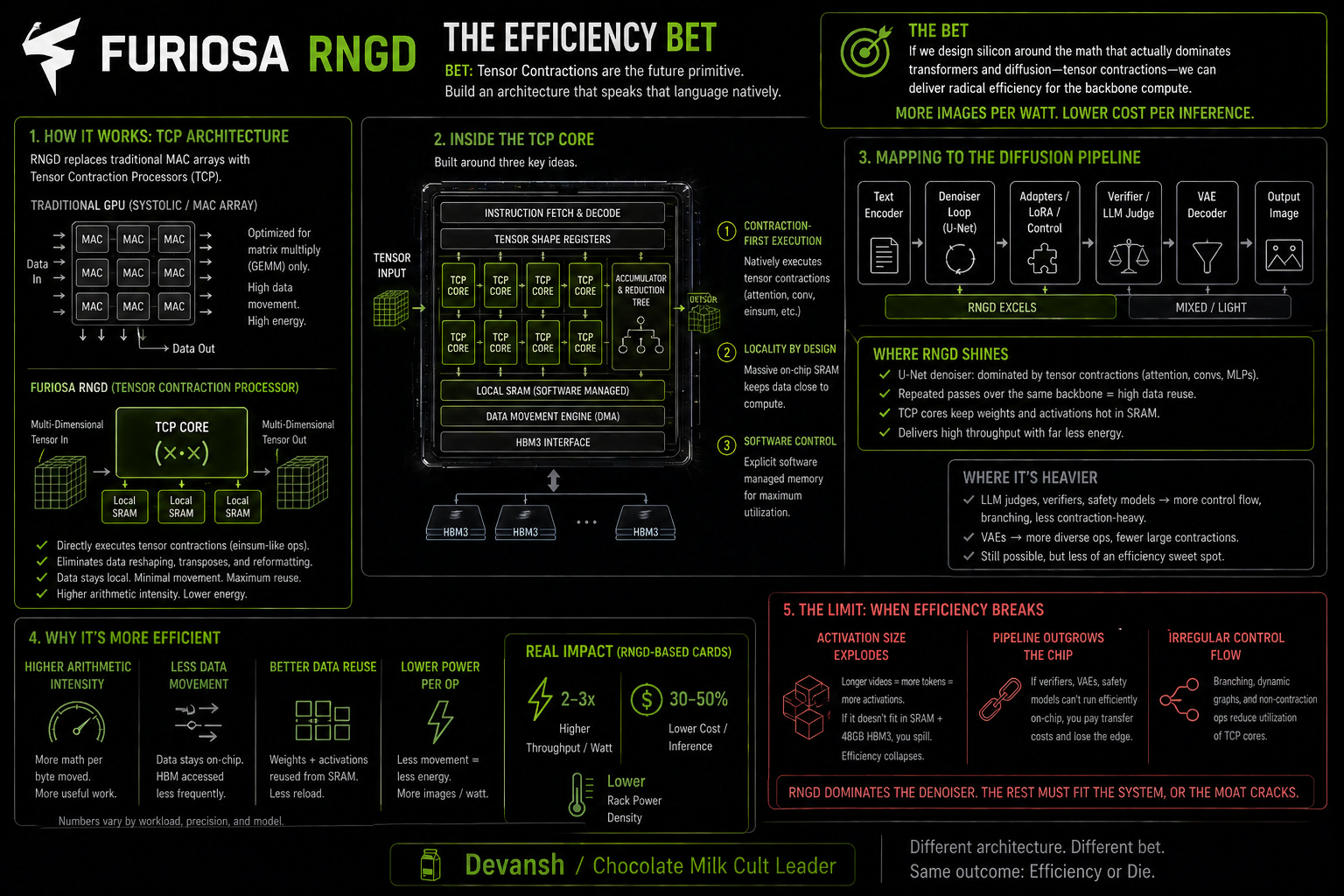
Furiosa’s RNGD chip abandons traditional matrix-multiplication units entirely. Instead, they built a Tensor Contraction Processor (TCP) that treats tensor contractions — like attention mechanisms — as the fundamental hardware primitive.
d-Matrix’s Corsair, on the other hand, uses Digital In-Memory Compute (DIMC). They physically moved the arithmetic logic right next to the SRAM cells to stop wasting power dragging data back and forth.
Because diffusion relies on repeated passes through the same denoising backbone, both architectures map to the workload cleanly. But there is a catch. This efficiency only holds if the surrounding pipeline — the verifiers, VAEs, and safety models — can also be executed on the chip. If video activations grow larger than d-Matrix’s SRAM or Furiosa’s 48GB of HBM3 can comfortably hold, the efficiency breaks. They win image-scale denoising, but face steep challenges at video scale.
Groq: Token Generation in a Block-Refinement World
Groq built an exceptional machine for deterministic token generation. Their LPU (Language Processing Unit) throws out HBM entirely, relying instead on massive pools of extremely fast SRAM and a compiler that schedules every piece of data movement ahead of time. It is a machine built perfectly to stream AR tokens.
But if inference shifts toward block-level parallel refinement and full-latent denoising passes, Groq’s religion is challenged. In a compound diffusion pipeline, they are unlikely to be the primary renderer. Instead, they survive as the ultra-fast LLM planner or verifier judge sitting next to the diffusion engine, handling the language-side logic while a GPU processes the pixels.

Cerebras: The Wafer-Scale Locality Limit
Cerebras does not build chips; they build wafers. The WSE-3 is the size of a dinner plate. By keeping everything on one giant piece of silicon with massive amounts of SRAM, they eliminate the slow, expensive interconnect latency of moving data between traditional GPUs.
For a static, continuous denoising loop, this is an elegant solution. But production pipelines require orchestrating multiple side-models, and video activations can easily exceed local SRAM limits. Once the working state forces the system to move data off the wafer, the architecture loses its primary advantage. Cerebras is highly effective for a single, massive denoiser, but struggles with the messy reality of multi-model video serving.

Etched: The Transformer Ultimatum
Etched made the most aggressive bet in the market with Sohu. They ripped out all the general-purpose programmability of a GPU and physically hardwired the Transformer architecture directly into the silicon.
If image and video diffusion standardize completely around Diffusion Transformers (DiTs), Etched is a monster. But diffusion transformers are not identical to causal LLMs. They need bidirectional attention, multimodal token streams, and variable resolutions. If Etched’s architecture is too rigidly optimized for the causal LLMs of 2024, diffusion will run poorly on it. It is a gorgeous, specialized knife waiting to see if the industry standardizes on the exact vegetable it was built to slice.
Apple & Qualcomm: The Edge Volume
Apple and Qualcomm are betting on the collapse of the step count. As discussed in Section 4, once image distillation drops the required forward passes to between 1 and 4 steps, the math becomes efficient enough to run locally on consumer NPUs via Apple’s Unified Memory architecture.
Local generation is private, instant, and carries zero marginal cost for the provider. Datacenters will retain the premium video revenue and heavy enterprise pipelines, but Apple and Qualcomm are positioned to completely strip-mine the bottom of the consumer image market. The edge wins the volume; the cloud retains the revenue.
Lightmatter and Astera: The Fabric Layer
Lightmatter and Astera are betting on the physical limits of copper wire.

A standard image model does not require a photonic spiritual awakening. But long video diffusion and world models create massive token counts, severe temporal attention costs, and multi-device parallelism. When activation memory exceeds what a single server rack can hold, the interconnect fabric becomes the foundational bottleneck. Lightmatter’s Passage platform uses 3D-stacked silicon photonics to move data using lasers instead of electrical signals, hitting 1.6 Tbps per fiber. These companies win when video diffusion scale officially outruns algorithmic compression, forcing the rack itself to become the computer.
Conclusion: Where this is All Headed
Every major computing paradigm eventually shifts the locus of value from the raw engine to the orchestration layer. In the early internet, we obsessed over physical servers and networking hardware. Eventually, the servers commoditized. The real money moved to the platforms routing the traffic.
AI is about to undergo the exact same unbundling. For three years, we have treated foundation models like indivisible, magical brains. But if diffusion turns generation into a branching search problem, the monolithic model dies. It becomes a supply chain. You will have cheap open-source denoisers, elite proprietary verifiers, and dynamic schedulers, all negotiating with each other in real-time.
The history of tech is just the history of expensive, integrated systems being ripped apart by cheaper, modular components. The closed labs and hyperscalers are fighting a brutal, capital-intensive war to own the integrated brain. But if inference is no longer a straight line, the most valuable real estate won’t be the base weights or the silicon. It will be the routing logic. The question is no longer who builds the biggest engine. It is who builds the best map.
Thank you for being here, and I hope you have a wonderful day,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. :
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819
"Since my brother also reads this newsletter": classical start of a rage bait :D
Classic
If you can measure it you can improve it.