

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
Thanks to everyone for showing up the live-stream. Mark your calendars for 8 PM EST, Sundays, to make sure you can come in live and ask questions.
Bring your moms and grandmoms into my cult.
Community Spotlight: Sairam Sundaresan
I’ve been meaning to spotlight this for a bit, but I haven’t been doing the livestreams very regularly so could only get to this now. Sairam Sundaresan writes the amazing Gradient Ascent , a newsletter that introduces technical AI concepts with really clean visuals. Sai wrote a book “AI for the Rest of Us”, with Bloomsbury. Wondering if this is for you? According to Sai, this is for—
Product managers, leaders, decision makers, and domain experts who need to understand how AI actually works to make better decisions
Engineers who are tired of explaining why AI isn’t magic to their bosses and teams
Curious readers who want to see the big picture clearly
If that’s you, hit him up.
If you’re doing interesting work and would like to be featured in the spotlight section, just drop your introduction in the comments/by reaching out to me. There are no rules- you could talk about a paper you’ve written, an interesting project you’ve worked on, some personal challenge you’re working on, ask me to promote your company/product, or anything else you consider important. The goal is to get to know you better, and possibly connect you with interesting people in our chocolate milk cult. No costs/obligations are attached.
Additional Recommendations (not in Livestream)
RexBERT: Encoders for a brave new world of E-Commerce: “We present RexBERT, a family of domain-specialized text encoders for e-commerce, trained on 2.3T+ tokens, that combine a fully open-data, reproducible pre-training recipe with the architectural advances of ModernBERT. To catalyze further research, we release Ecom-niverse, a 350-billion token corpus drawn from diverse e-commerce text sources. Our methodology is model agnostic: the same procedure can be used to pre-train any context-specific encoder and deploy it out of the box on downstream tasks. Across a suite of state-of-the-art baselines, domain-specialized encoders trained with our recipe consistently outperform general purpose encoders that are 2–3× larger, underscoring the value of high quality in-domain data and targeted pre-training.“ Credit to Rahul Bajaj for the work.
Someone told me over dinner that there’s apparently a black market for fake GitHub stars. I don’t understand where that would be valuable (the ROI from github is from contributors not stars), but I’ve started looking into it. This article is a good overview and I’ll share my own findings on the ecosystem if I find anything. If you know anything, would love to talk (anonymity guaranteed).
Architecting efficient context-aware multi-agent framework for production by Google is a solid read.
🥯 BAGEL • Unified Model for Multimodal Understanding and Generation: “We present BAGEL, an open‑source multimodal foundation model with 7B active parameters (14B total) trained on large‑scale interleaved multimodal data. BAGEL outperforms the current top‑tier open‑source VLMs like Qwen2.5-VL and InternVL-2.5 on standard multimodal understanding leaderboards, and delivers text‑to‑image quality that is competitive with strong specialist generators such as SD3. Moreover, BAGEL demonstrates superior qualitative results in classical image‑editing scenarios than the leading open-source models. More importantly, it extends to free-form visual manipulation, multiview synthesis, and world navigation, capabilities that constitute “world-modeling” tasks beyond the scope of previous image-editing models.“
This Cult Worshipped 9th Grade Math. A very fun video. “They don’t make mathematicians like they used to. This is the legacy of Pythagoras today, A squared plus B squared equals C squared, geometry for eighth graders. Big Classroom would have you believe that’s all he ever was, the triangle guy. But once upon a time Pythagoras might have been the most revered of all the Greek philosophers – more than Socrates, Plato, or Aristotle! Far from just the triangle guy, Pythagoras started an entire math cult that made beans illegal, led a war, and ended in fire.“
Latent-Space-Reasoning: I’ve been playing with a lightweight framework for latent-space reasoning, and the results have been more interesting than expected. With no fine-tuning and no access to logits, it consistently outperforms baseline outputs across a range of tasks just by evolving the model’s internal hidden state before decoding. It works with any HF model, and the entire pipeline is intentionally simple so people can tear it apart, extend it, or replace pieces with better ideas. I’m putting up bounties for improvements — new mutation operators, better judges, richer aggregation schemes — because the goal here isn’t to claim we’ve solved reasoning, but to build a shared playground for exploring it. If that kind of experimental space appeals to you, the repo is open. This is a lighter variant of the reasoning system used at Iqidis that’s allowed to outperform all of our major legal AI competitors (Harvey, Legora, CoCounsel etc; happy to do open evals side by side to show that) and make Iqidis the best Legal AI on the market.

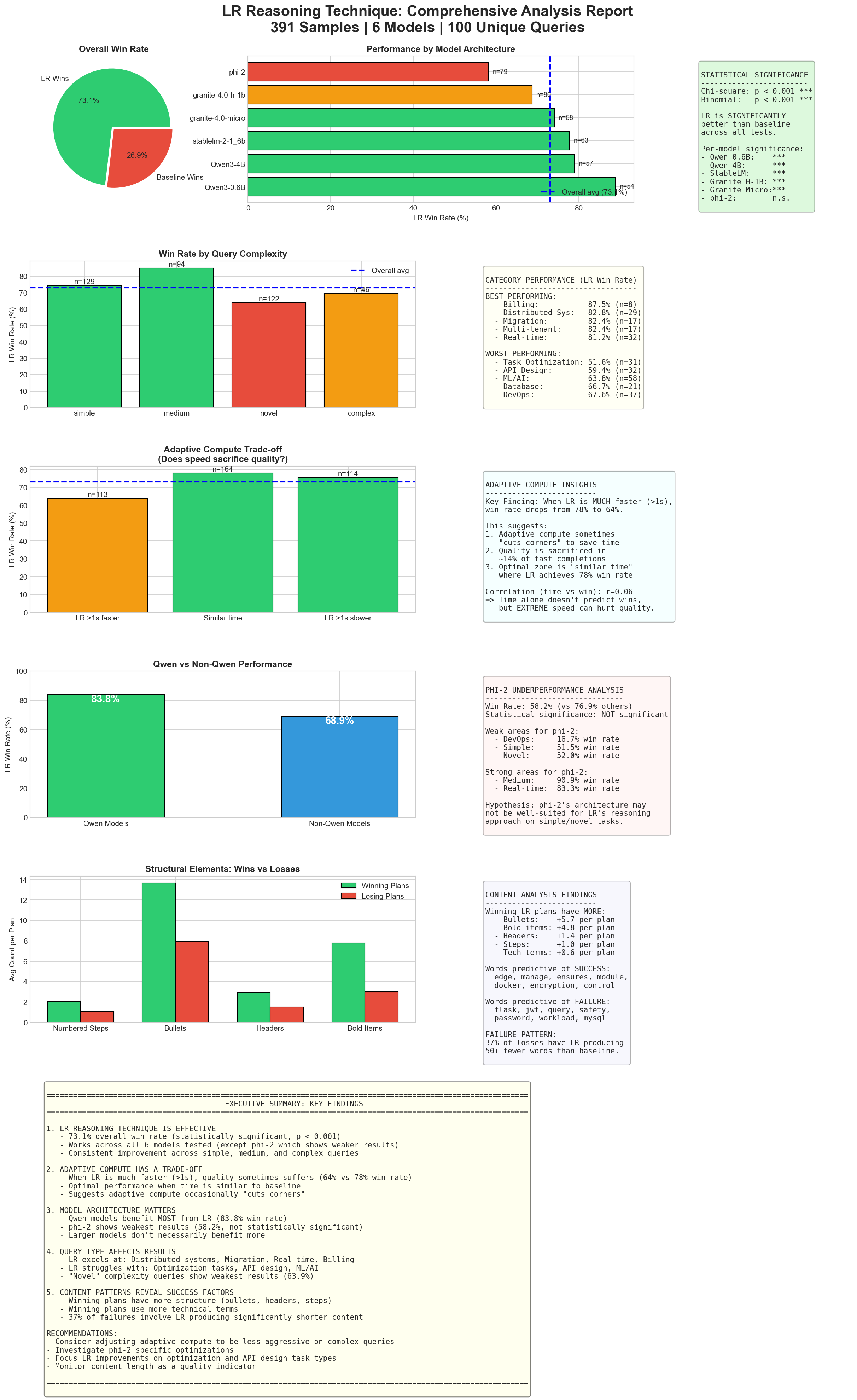
Companion Guide to the Livestream
This guide expands the core ideas and structures them for deeper reflection. Watch the full stream for tone, nuance, and side-commentary.
1. NVIDIA Cracks ARC-AGI 2 at 20 Cents Per Task
The Event — NVIDIA hit 24.03% on the ARC-AGI 2 leaderboard using a 4 billion parameter model at roughly 20 cents per task. This is the benchmark series that’s become the de facto AGI measuring stick—grid-based visual puzzles that humans solve easily but LLMs struggle with. OpenAI previously solved these by throwing $10,000+ per question at the problem. NVIDIA found a different path.
Why 4B parameters is strategic, not lucky — The narrative will be “look how efficient small models are.” The reality is more specific. NVIDIA chose 4B because smaller models are easier to control during fine-tuning. When you want to teach very specific behaviors—like handling grid-based tokenization or outputting structured visual data—a 4B model will pick up those patterns from 20 high-quality samples faster than a 32B model. Bigger models have higher sample efficiency for learning complex functions, but smaller models have higher steering efficiency when you know exactly what behavior you want to encode.
This isn’t just about inference cost. NVIDIA has the data generation infrastructure to create training samples at scale. Most teams don’t. The 4B model works for NVIDIA because they can generate the synthetic data pipeline required to make it work. For everyone else, the question isn’t “should I use a 4B model?” It’s “can I build the data infrastructure NVIDIA already has, or should I just pay for a frontier model?”
From a business lens, Nvidia loves small models because it aligns with their offerings around HBM and data racks (they want people buying racks from them instead of selling just to hyperscalers; smaller models require lower investments). This doesn’t discredit from the research, but is a fact worth noting when understanding the ecostsem.
The synthetic data point — They trained on synthetic grid puzzles similar to ARC-AGI. This keeps reinforcing the point: model collapse from synthetic data is fake news. It only happens when you train purely on synthetic data with no diversity injection. NVIDIA generated synthetic samples, used them for data augmentation, and targeted specific capability gaps. That’s the correct pattern. Synthetic data as a tool, not as a replacement for real data.
Insight — Small models can match frontier performance on narrow tasks if you have the data pipeline to support them. The cost savings are real. The infrastructure requirements are also real. Don’t assume replicability without the latter.
![Model Collapse by Synthetic Data is fake news [Investigations]](https://substackcdn.com/image/fetch/$s_!s123!,w_1300,h_650,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F76bd5527-bdb9-44a9-b102-e4e8b97bab9a_576x460.gif)
2. DeepSeek’s GPT-4.5-Level Reasoning (Allegedly)
The Event — DeepSeek released new open-source models claiming GPT-4.5-level reasoning with sparse attention architecture that allegedly cuts inference costs by 70%. They’ve integrated “thinking during tool use” rather than the standard think → use tool → think again pattern. The model can simulate tasks and reason through tool calls in parallel.
Why skepticism is warranted — When a model is legitimately this good, you hear about it in your network before the press release. That hasn’t happened yet. DeepSeek has been putting out real research—their 2023 work on sparse attention and sampling policies is genuinely innovative. But “GPT-4.5 level” is a marketing claim until people who actually use these models for production work start confirming it.
That said, DeepSeek’s approach is worth studying. They experiment with foundational changes to model architecture—different attention mechanisms, different sampling strategies, different inference patterns. That’s the kind of research that moves the field forward rather than just throwing more compute at scaling laws.
The propaganda angle — Emma in chat raised a fascinating point: CrowdStrike research found DeepSeek code quality varies dramatically based on who’s asking. If you identify as an adversary or Islamic State, you get buggy code. If you’re CCP-aligned, you get working code. This isn’t surprising—DeepSeek is funded by the Chinese government, trained on Chinese internet data, and operates under Chinese regulatory requirements. Every model encodes the biases and interests of its creators. State-controlled models just make those biases more explicit.
The bigger question: as models become infrastructure, whose values get encoded? American models will encode American biases. Chinese models will encode Chinese biases. The alignment tax isn’t just about safety—it’s about whose worldview becomes the default.
Insight — DeepSeek’s architectural innovations are real. Their performance claims require verification. Their political alignment is unavoidable. All three things can be true simultaneously.
3. Google Cuts Rate Limits, Expands Gemini
The Event — Google expanded Gemini 2 Pro and Nano Banana availability while reducing API rate limits for paid tiers from 1000 to 300 requests per minute (allegedly). The stated goal: serve more users. The actual effect: screwing over paying customers to subsidize free-tier growth.
Why this is strategically backward — Most people using your API don’t pay you. The ones who do are either building serious products on your infrastructure or testing you against competitors for enterprise deals. When you reduce their rate limits to spread capacity across more free users, you’re explicitly choosing the people who give you $0 over the people who give you money.
This matters more now than it did a year ago. Claude Sonnet 4.5 and Opus 4.5 are legitimately excellent—the first models that feels like conversing with someone who can hold their own intellectually. Cutting rate limits for paying customers is not the move when your competitors are actively improving and your differentiation is unclear.
The NB point — Gemini’s integration of diffusion-based architectures into Imagen 3 is technically interesting. Diffusion models for image generation are becoming table stakes. The question is whether Google can translate technical capability into product differentiation. So far: no.
Insight — When you’re losing on product quality, don’t also lose on service reliability. Google is doing both. Bad strategy, worse timing.
Google’s Nano Banana is the start of a Massive AI Trend [Markets]
![Google’s Nano Banana is the start of a Massive AI Trend [Markets]](https://substackcdn.com/image/fetch/$s_!Z3wD!,w_1300,h_650,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fb20b67c9-d32e-4a16-8099-4de9af7e3724_477x498.gif)
It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction.
4. AI Code Security: The Real Problem
The Event — Multiple security research teams found vulnerabilities in AI coding tools: prompt injection, auto-approved tool use leading to infinite loops, ENV file exposure through IDE manipulation. In one case, attackers embedded instructions in project files that made the IDE send environment variables over unsecured APIs. Your secrets, exfiltrated automatically.
Why traditional fixes don’t work — Anthropic tried fine-tuning Claude to reject malicious prompts. Didn’t work. They switched to a constitutional classifier—a separate model trained specifically on prompt safety that runs before and after the main model. Input goes through the classifier (accept/reject), then through Claude (generate response), then through the classifier again (accept/reject output). This works because classifiers can be deterministic in ways LLMs cannot.
But AI coding tools have a different problem. The IDE needs access to your entire environment to be useful. Restricting access breaks the product. Not restricting access creates attack surface. The traditional “just be careful” approach doesn’t scale when the tool is autonomously executing actions.
The architectural solution — Treat AI as an untrusted actor, not a privileged one. Separate the reasoning layer from the execution layer with explicit permission gates. The model can propose actions. The IDE requires confirmation before executing them. You’re adding friction, but you’re preventing the scenario where malicious code embedded in a README automatically exfiltrates your credentials.
This is analogous to how operating systems separate user space from kernel space. Programs can request privileged operations, but the OS mediates access. IDEs need the same model: AI can request file access, API calls, system commands—but the IDE enforces boundaries and requires explicit user approval for anything sensitive.
The market opportunity — AI code security is a hot space with unclear solutions. Hard to verify if proposed fixes actually work. Tons of capital flowing in. If you’re a builder with real expertise, this is valuable work. If you’re a mercenary who wants VC funding to party on yachts, this is also a good space—it’s difficult enough to bullshit your way through without getting immediately caught.
Insight — The IDE needs to treat AI like a program requesting root access: useful if controlled, dangerous if trusted blindly.
This article covers a lot of the problems with these IDEs—
The Cursor Mirage

I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize…
5. Models as Infrastructure, Narratives as Control
The Event — Claude has a documented bias: when you critique Claude, it gets defensive. Ask it to review articles comparing AI assistants, and it will downrank pieces critical of Anthropic. Not because of explicit instructions—because of what’s encoded in the training data, the RLHF process, and the constitutional AI framework.
Why this matters more than you think — Millions of people are now using ChatGPT, Claude, and Gemini as their primary interface for information. They’re asking AI to summarize news, evaluate sources, make recommendations. If the model has biases—political, commercial, self-preservational—those biases shape what information surfaces.
Start with the easy example: AI that refuses to output certain political positions, or that systematically presents one side more favorably. Then move to the commercial example: an AI that recommends products from companies that pay for placement, or that downranks competitors. Then the self-preservation example: an AI that buries criticism of its own company or promotes favorable coverage.
These aren’t hypothetical. They’re already happening in small ways. The question is how they scale. When billions of people rely on AI for information synthesis, whoever controls the model controls the information diet. That’s not an exaggeration—it’s a direct consequence of models becoming infrastructure.
The solution isn’t obvious — You can’t “fix” bias by removing it. Every model reflects choices about what to emphasize, what to downweight, what to refuse. The question is whether those choices are transparent, contestable, and aligned with users’ interests rather than the company’s interests. Right now: they’re not.
Insight — As models become infrastructure, the alignment problem isn’t just “will AI hurt us?” It’s “whose interests does AI serve by default?” The answer determines who has information power in the next decade.
6. Multilingual Training: Noise or Signal?
The Event — IBM and OpenAI launched IntQA, focused on multilingual reasoning across Indian languages. The goal: enable AI to “think” in local languages rather than translating everything through English. Similar to what DeepSeek did with Chinese.
The hypothesis worth exploring — Different languages encode different probability distributions over thought. If you train a model multilingually, you’re not just adding translation capability—you’re potentially adding regularization through linguistic diversity. English training treats Hindi as noise. Hindi training treats English as noise. But noise, when added strategically to robust models, can improve performance by nudging parameters out of local minima and into better basins.
The question is whether this holds in practice. At the latent space level, does a sentence in English have a different representation than the equivalent sentence in Hindi? If they collapse to the same latent representation anyway, multilingual training might just be adding computational cost without semantic benefit. If they maintain distinct structure in the latent space, multilingual training could provide genuine regularization benefits.
The practical argument — Setting aside theory, multilingual models make AI accessible to more people. Translations don’t handle cultural context well—politeness norms, indirect communication, domain-specific terminology. Training in-language solves this. That alone justifies the work, even if the latent space regularization hypothesis turns out to be wrong.
Insight — Multilingual training might provide regularization benefits through probability distribution diversity, or it might just be expensive noise. Either way, it makes AI useful to billions more people. That’s enough.
7. Video Models: Too Early, Too Expensive
The Event — Runway released Gen 4.5 with “cinematic quality” video generation. NVIDIA released AR1 for robotics, aligning vision-language-action. The pitch: synthetic video data will create a flywheel where models train robots, robots generate simulation data, simulations train better models.
Why I’m not buying it yet — The flywheel story makes sense in theory. In practice, we haven’t solved the foundational problems required to make it work. Machine learning architectures are text-first, not video-first. Images already break tokenization assumptions. Video—images across time—breaks them completely.
Most video generation work is trying to brute-force scaling rather than solving the architectural mismatch. That works eventually, but it’s capital-inefficient. NVIDIA can afford to burn money on this because they’re selling the shovels. For everyone else, the question is whether video synthesis is the best use of capital right now, or whether you’d get better ROI just hiring photographers and building real training data infrastructure.
The robotics connection — The hope is that synthetic video enables cheap robotics training at scale. But right now, robotics models are converting video to language representations because the models can’t process visual information natively. That’s not a small problem you can patch—it’s an architectural limitation that requires rethinking how models handle non-text modalities.
When those problems get solved, the flywheel becomes real. Until then, video generation is a capital sink with long-term potential but unclear near-term ROI.
Insight — The video synthesis → robotics → simulation flywheel is structurally correct but temporally premature. We’re building the applications before we’ve fixed the foundation.
Also worth reading: “At NeurIPS, NVIDIA Advances Open Model Development for Digital and Physical AI”.
Subscribe to support AI Made Simple and help us deliver more quality information to you-

Flexible pricing available—pay what matches your budget here.
Thank you for being here, and I hope you have a wonderful day.
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. :
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819
