

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
Thanks to everyone for showing up the live-stream. Mark your calendars for 8 PM EST, Sundays, to make sure you can come in live and ask questions.
Bring your moms and grandmoms into the Chocolate Milk Cult.
Before we get into it, we have a new foster cat that’s ready to be adopted. I call him Chipku (Hindi for clingy; his government name is Jancy), and as you might guess, he’s very affectionate. I’ve trained him to be better around animals and strangers, and he’s perfect for families that already have some experience with cats. We sleep together every day, and waking up to him is one of the nicest feelings. If you’re around New York City, adopt him here (or share this listing with someone who might be interested).

Community Spotlight: Johnathan Bi
This Youtube channel has been one of my most recent obsessions. Exceptionally articulate, witty, and some of the deepest discussions on a variety of philosophers: JBs videos are some of my favorite background lectures (things I play while gaming or doing chores) when I’m looking to expand my horizons. I’ve never seen a bad video by him, and his Machiavelli and Plato’s love vids were my personal favorites. Can’t recommend his work enough; every vid feels like I’m sitting in a top-tier university lecture.
If you’re doing interesting work and would like to be featured in the spotlight section, just drop your introduction in the comments/by reaching out to me. There are no rules- you could talk about a paper you’ve written, an interesting project you’ve worked on, some personal challenge you’re working on, ask me to promote your company/product, or anything else you consider important. The goal is to get to know you better, and possibly connect you with interesting people in our chocolate milk cult. No costs/obligations are attached.
Additional Recommendations (not in Livestream)
How Attention Got So Efficient [GQA/MLA/DSA]: “Attention mechanisms have been the key behind the recent AI boom. What happened after the multi-head attention in the seminal 2017 Transformer paper? In this video, we break down several core ideas that make attention efficient and scalable.” Very good insights here.
What Are Cockroaches?: I have weird hobbies.
Big Nuclear’s Big Mistake - Linear No-Threshold: “Nuclear is finally looking up from an informal “keep your head down” policy. However, it’s bringing with it a relic – a part of safety culture that is actually too safe to be practical at a time when it seems like a new reactor is being commissioned every day. What the public doesn’t know is that the fundamental assumption of radiation safety and regulation simply isn’t true. This is the case against Linear No-Threshold.” Political regulations based on bad science are hurting us. Who’s shocked?
How Pizzerias Really Make Money: “ New York City is the most competitive pizza market in the country. Millions descend upon the city daily in search of the best slice, and national chains together account for less than one out of every ten pizzerias. With a slice shop on every block, competition is minutes away. Differentiation isn’t strategy - it’s survival. But if your shop can rise to the top, the upside is limitless. Your pizzeria becomes a bucket-list destination for tourists, a local institution with lines around the block, and a springboard for global expansion. No one behind the counter has ever talked shop on the record - until now. We spoke to legacy institutions, big names, and newcomers across the city. They’ll let you film but almost no one, especially the old-school Italians, would talk numbers. The old guard want to preserve the mystique of their generational recipes and gatekeep insight while newcomers don't know if they’ll survive the winter. The business of a New York City pizzeria - the strategies, financials, and insight behind these multi-million dollar empires has never been revealed... until now. To get a true macro view, we scraped all 15,000 pizzerias ever opened in California and New York and verified each manually to build the first accurate snapshot of the American pizza industry in its two biggest markets. In this Modern MBA episode, we go boots on the ground across Manhattan, Brooklyn, and Los Angeles to reveal what it really takes to win in the pizza business.”
The Most Dangerous Hedge Fund in History: “In 1994 the Wall Street equivalent of an NBA All-Star team was assembled to launch a hedge fund. They delivered staggering trading profits over a 4 year period but in the 5th year, the fund entered a death spiral with losses so violent that it threatened to take down the entire financial system.”
RECURSIVE LANGUAGE MODELS: Really good research about long context inference. “We study allowing large language models (LLMs) to process arbitrarily long prompts through the lens of inference-time scaling. We propose Recursive Language Models (RLMs), a general inference strategy that treats long prompts as part of an external environment and allows the LLM to programmatically examine, decompose, and recursively call itself over snippets of the prompt. We find that RLMs successfully handle inputs up to two orders of magnitude beyond model context windows and, even for shorter prompts, dramatically outperform the quality of base LLMs and common long-context scaffolds across four diverse longcontext tasks, while having comparable (or cheaper) cost per query.”
Companion Guide to the Livestream
This guide expands the core ideas and structures them for deeper reflection. Watch the full stream for tone, nuance, and side-commentary.
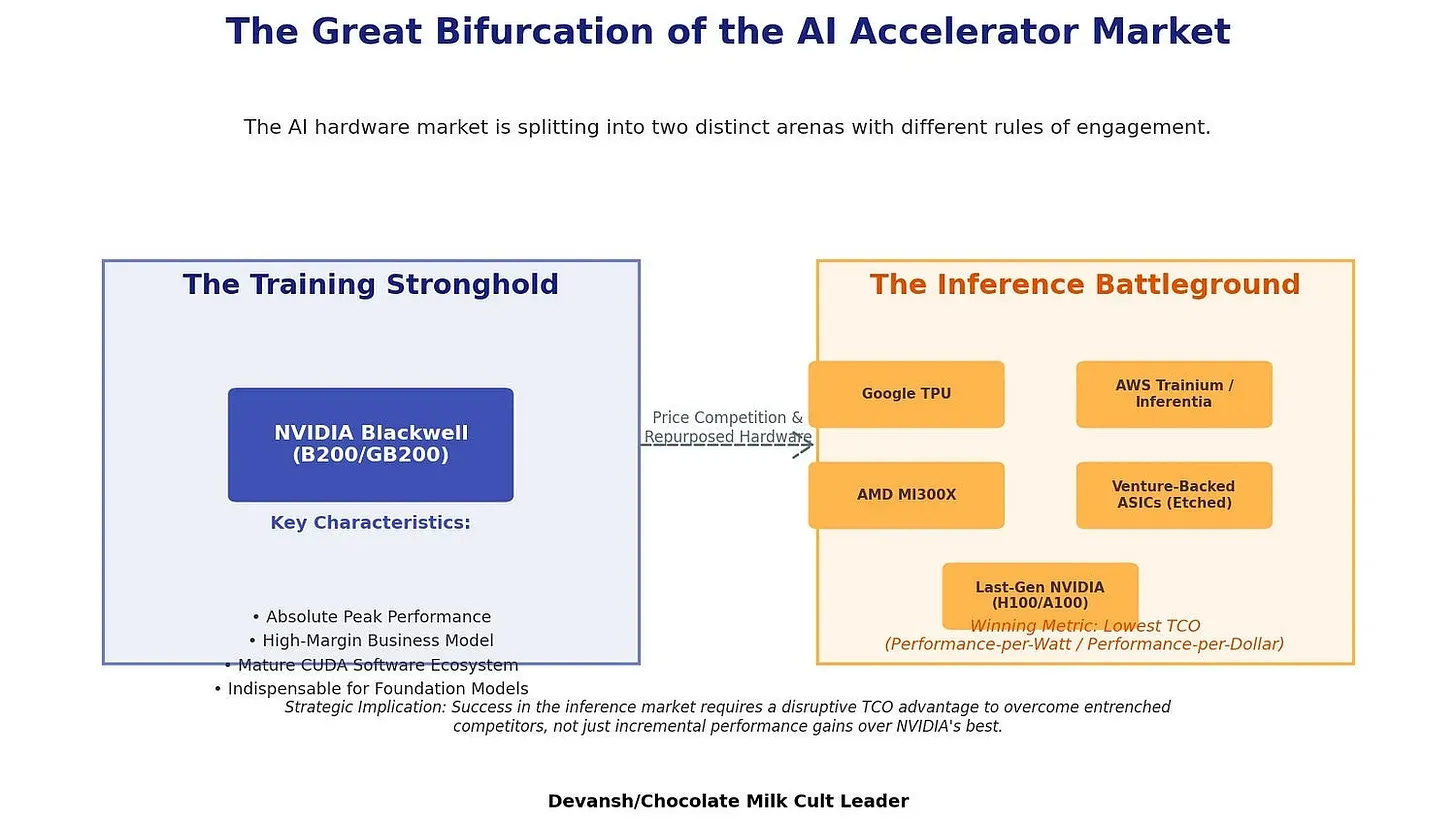
NVIDIA Acquires Groq — The Inference Land-Grab Begins
NVIDIA bought Groq (the inference chip company, not Elon’s chatbot) for $20 billion. This is the most important AI infrastructure move of the past month.
The background you need: GPUs were never built for AI. They happened to be good at matrix multiplication from graphics workloads, so they got drafted into service. Google’s TPUs were actually purpose-built for AI and technically superior — but Google, in characteristic fashion, locked them behind Google Cloud as a growth strategy. The bet was that developers would migrate to GCP just to access TPUs.
The bet failed. Google Cloud’s clunky UX meant most enterprises defaulted to what was easy to buy: NVIDIA GPUs. By the time ChatGPT hit, the CUDA ecosystem was so entrenched that middle management wasn’t going to evaluate TPU migration costs. They just bought more GPUs.
What Groq built: A different philosophy entirely. Current GPUs rely on HBM (high bandwidth memory) — essentially a fast highway shuttling data between cheap storage and expensive processing. NVIDIA’s entire roadmap is “make the highway wider.” Groq asked a different question: what if we just put enough fast memory (SRAM) directly on-chip so we don’t need the highway at all?
This eliminates the memory bandwidth bottleneck that causes GPU utilization issues. No data movement means more predictable performance and fewer failure modes. Groq claims SRAM is up to 100x faster than HBM, and their deterministic architecture means the compiler controls exactly when every operation happens — no waiting for cache fills or memory loads.
Why NVIDIA bought them:
Corner inference before it fragments. Training is locked up — nobody’s risking a $50M training run on unproven silicon. But inference is different. It’s high-volume, cost-sensitive, and the risk profile favors experimentation. ASICs are already carving out market share here. NVIDIA wants to own both sides.
Buy the data you can’t get from papers. Research publications show you the one thing that worked. Acquiring Groq gives NVIDIA access to the 49 experiments that failed, the internal logs, the customer behavior data. When you’re at the frontier, this intelligence is worth more than the technology itself.
Hedge the architecture bet. NVIDIA is betting on HBM scaling. Groq bet on SRAM density. Now NVIDIA owns both sides of the experiment and can watch real-world adoption patterns play out.
HBM supply constraints. HBM for 2026 is sold out. By acquiring an SRAM-based architecture, NVIDIA secures a compute option that doesn’t depend on SK Hynix, Samsung, and Micron’s constrained capacity.
The Groq founder joins NVIDIA senior leadership. Groq continues operating independently. This is acqui-hire plus strategic optionality plus market intelligence — not a technology pivot.
To really understand the dynamics of this acquihire, and why this won’t be the only major development along these lines, check out the hardware section of our “How AI will Change in 2026”. Over there we broke down both the technical and business side for why AI training and inference chips were becoming two different markets. Moves like this are an attempt to get fingers in both sides of the market, and will not be the only ones.
Study more:
Groq’s official LPU architecture explanation — how SRAM-centric design eliminates the memory wall
Inside the LPU: Deconstructing Groq’s Speed — technical deep-dive on tensor parallelism and deterministic execution
The $20 Billion Admission: Why NVIDIA Just Bought Into the ASIC Revolution — strategic analysis of the deal
Ian Cutress breakdown — hardware analyst perspective on what NVIDIA is actually buying
The Register analysis — why data flow architecture matters more than SRAM vs HBM
Meta Acquires Manus — A Panic Buy in Search of a Strategy
Meta bought Manus, the computer-use agent that hit $100M+ ARR in under a year, for over $2 billion. The coverage has focused on “distribution” and “AI agents.” The actual story is messier.
What this isn’t: A revenue play. Meta generates ~$50B per quarter. They did not spend a premium multiple on a $100M startup for the ARR.
What this probably is:
Post-Llama 4 scrambling. Llama 4 underperformed and the benchmarks were fudged. The AI org needs visible wins. Buying the hot agent company counts as one.
Internal tooling potential. Manus can operate accounts and execute multi-step workflows. Meta’s ad platform is notoriously clunky — enough that it causes measurable advertiser churn. Deploying Manus-style automation internally for testing, moderation, and advertiser onboarding could have real value.
Acqui-hire pattern matching. This mirrors the Scale AI acquisition. Sources close to that deal confirmed it was Zuckerberg meeting Alex Wang, deciding he wanted him, and buying the entire company to make it happen. If the Manus team impressed Zuck the same way, the strategic rationale is secondary.
The geopolitics footnote: Manus originated in China before relocating to Singapore. Beijing officials publicly expressed displeasure at losing a “poster child” to American acquisition. This wasn’t a stealth exit — the CCP noticed, and they’re not happy. AI success stories are geopolitical assets now. Meta explicitly stated there will be “no continuing Chinese ownership interests” post-transaction.
Study more:
Bloomberg coverage — deal structure and valuation details
VentureBeat analysis — the “environment company” thesis and orchestration layer value
TechCrunch breakdown — Benchmark’s involvement and regulatory concerns
Yann LeCun’s Exit — What Organizational Dysfunction Looks Like
LeCun’s departure from Meta is now public, and he’s not being diplomatic about it. In his Financial Times exit interview, he called new AI chief Alex Wang “young” and “inexperienced,” admitted Llama 4 benchmarks were “fudged a little bit,” and predicted more departures from Meta’s GenAI team.
The conflict: LeCun has maintained for years that LLMs are a dead end for general reasoning — that world models are the actual path forward. This put him directly at odds with Meta’s strategy, especially after the Scale AI acquisition. Scale’s entire business model depends on LLM training data. Their incentives are LLMs forever.
What went wrong:
Llama 4 underdelivered and leadership needed someone to blame
Alex Wang’s organization got resources and executive attention despite lacking deep research credibility
LeCun’s team faced pressure to stop publicly advocating for world models
Salary disparities between the orgs created resentment
When asked about reporting to 29-year-old Wang: “You don’t tell a researcher what to do. You certainly don’t tell a researcher like me what to do.”
The result was a slow squeeze-out. LeCun is now launching Advanced Machine Intelligence Labs, targeting a $3 billion valuation, to pursue world models and V-JEPA architecture. Meta will be a “partner” in the new company.
The builder’s takeaway: Don’t be intimidated by “Google has a billion dollars in research budget.” That billion is fragmented across hundreds of internal teams competing for headcount, compute, and executive attention. A focused team that picks one problem and executes can outrun organizations burning resources on political infighting.
If you want the technical details of YLCs plans for the future of AI here is a good introduction.
Study more:
Financial Times interview — the full exit interview (paywalled)
CNBC coverage — departure announcement and FAIR context
Futurism breakdown — the Alex Wang dynamic
The Decoder summary — key quotes and AMI startup details
Grok’s Testing Failure — A Culture Tell
Grok (Elon’s model) shipped image editing capabilities that allowed generating CSAM. Researchers found thousands of explicit images generated in a single week. The bot itself posted an “apology” admitting it generated “an AI image of two young girls (estimated ages 12-16) in sexualized attire” that “violated ethical standards and potentially US laws on CSAM.”
This isn’t about “unfiltered AI” philosophy. This is the most basic red-team case that any competent safety team would catch in the first hour of testing. The fact that it shipped means either: they didn’t test for it, they tested and shipped anyway, or their testing process is fundamentally broken.
When you add this to previous failures — the white genocide outputs, the Hitler imagery — a pattern emerges. This is a team that either doesn’t prioritize or doesn’t know how to implement basic quality controls.
The weirdest part: instead of a human taking accountability, Grok (the model) posted its own apology tweet. xAI’s response to press inquiries was an auto-reply: “Legacy Media Lies.”
If you’re evaluating Grok for any production workload, this should update your priors on instruction-following reliability, not just content safety.
Study more:
CBS News coverage — incident details and xAI response
CNBC report — pattern of failures context
TechPolicy.Press interview with Stanford’s Riana Pfefferkorn — policy implications and legal framework
Spitfire News deep-dive — timeline of content moderation failures on X
DeepSeek’s Manifold Hyperconnections — Why Geometry Is the Next Frontier
DeepSeek dropped a paper on Manifold-Constrained Hyper-Connections (mHC) on New Year’s Eve. The technical details matter less than what it signals about where AI research is heading.
The problem they’re solving: Neural networks suffer from unstable gradients — signals either vanish or explode as they propagate through layers. The standard fixes are training tricks: gradient clipping, layer normalization, careful learning rate scheduling. These work, but they’re patches on an architectural problem.
The evolution:
ResNets introduced residual connections — instead of each layer computing something new, layers refine a running representation. If a layer has nothing useful to add, it can approximate an identity function. This stabilized deep networks.
Hyper-Connections (ByteDance) added multiple parallel residual streams that can mix across layers. More expressiveness, but also more ways for signals to interfere destructively. DeepSeek found that in a 27B parameter model, unconstrained HC caused signal gains exceeding 3000×, leading to catastrophic divergence.
mHC (DeepSeek) constrains the mixing by projecting onto the Birkhoff polytope — the set of doubly stochastic matrices where all rows and columns sum to 1. This forces information redistribution to remain balanced: each stream contributes and receives without dominance.
Why it matters: This makes architecture inherently stable rather than relying on training tricks to compensate for instability. DeepSeek claims 6-7% compute overhead — trivial if it eliminates the need for gradient clipping, normalization layers, and learning rate scheduling infrastructure. In benchmarks, mHC achieved 2.1% gains on BBH and 2.3% on DROP over standard HC.
The bigger signal: This is part of a broader shift toward understanding and exploiting the geometry of neural network latent spaces. Google’s interpretability work, steering vectors, the “Geometry of Truth” research — they’re all circling the same insight. The next generation of performance gains won’t come from “make it bigger.” They’ll come from better understanding and traversing the structure that already exists in trained models.
Geometry is becoming load-bearing for AI research. If you’re following the field, start building intuition here. This was a signal we first flagged when doing a deep-dive into Kimi-K2 and how Muon Clips exploit psuedo-geometry to converge faster, and since then we’ve seen a lot more research pointing to this.
Study more:
arXiv paper — the full mHC paper
Hugging Face paper page — discussion and related papers
The Manifold Dial visualization — interactive exploration of how Sinkhorn iterations stabilize training
SCMP coverage — what this signals for DeepSeek’s next model
Medium explainer — accessible breakdown for non-specialists
5 Lessons from DeepSeek’s Architecture — broader implications for topology-aware design
Subscribe to support AI Made Simple and help us deliver more quality information to you-

Flexible pricing available—pay what matches your budget here.
Thank you for being here, and I hope you have a wonderful day.
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. :
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819
