
How to Thrive in the Age of AI
Why You Should Read: James Wang.

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
Which parts of your work become more valuable when AI exists, and which parts become cheap? How do we upskill ourselves to ensure that we stay relevant in the agent of AI? People are grappling with such questions. To answer them, we must understand how the technology works at an architectural level — what deep learning actually does, where the architecture structurally stops working, and what falls out of that for careers, companies, and markets.
James Wang’s What You Need to Know About AI is one of the best attempts at doing that. James Wang left Bridgewater Associates to move to the Bay Area in 2013 after reading the AlexNet paper. He cofounded an AI healthtech company, did a stint at Google, completed graduate work in machine learning, and is now a venture capitalist at a deep tech firm specializing in AI, robotics, and synthetic biology. He also runs one of my favorite Substacks ( Weighty Thoughts ) and I highly recommend his work for investors, technologists, and policymakers.
In this article, I will blend the book’s core ideas with my own frameworks on startup defensibility and AI market dynamics to help you understand how to thrive in the age of AI. More specifically, we will cover:
Why deep learning works by forgetting, and what that mechanism tells you about where AI structurally stops being reliable
How “bounded variation” answers three questions at once: will AI take my job, is this AI startup defensible, and is AGI close
What Wang’s models-compute-data framework reveals about AI business moats, and how it connects to my own work on why incumbents fail to crush paradigm-shifting startups
What “oracle-grade” expertise actually looks like in practice — not “develop judgment” but the specific capabilities that separate people who catch machine errors from people who cannot
Why AI threatens the apprenticeship path that builds expertise in the first place, and how to use AI as a training partner instead of a shortcut that hollows you out
All to answer the question on everyone’s mind: how do you win against the Holy Ghost in the Shell?

Executive Highlights (tl;dr of the article)
Deep learning works by forgetting. Its layers act as lossy compression that forces abstraction over memorization, bending the classical bias-variance tradeoff in ways that should not work according to standard statistical theory. That architectural property is why deep learning scales where classical ML could not.
“Bounded variation” is the concept that resolves every AI career question, startup question, and AGI timeline question into something actionable. If your work lives within patterns AI has already seen, you are getting compressed. If it requires genuine novelty, counterfactual reasoning, or creative judgment beyond the training distribution, you are about to become more valuable than ever.
The real class divide is not AI users versus non-users. It is people who can catch when the machine is wrong versus people who cannot tell the difference between a plausible answer and a correct one. Wang calls the first group “oracles.”
Most expertise gets built through grunt work that AI now lets you skip. Unless you deliberately use AI as a training partner rather than a replacement for thinking, the tool hollows out the judgment it needs you to have.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
Want access to a repository containing all of our research? 300+ files containing our notes of various experiments, discussions with cutting-edge teams, and insights into where the industry is headed next. Get a Founding Member Subscription to AI Made Simple. Want to talk to me for details/get my insights into the tech ecosystem? Reach out to me through any of my socials over here or reply to this email.
Why Does Deep Learning Generalize Instead of Memorizing?
“Computer” used to be a job title. It meant a room full of people grinding through arithmetic for artillery tables and census data. When the calculator arrived, that job vanished. But computation didn’t. The people who survived the transition were the ones whose judgment about what to compute was the scarce resource. If you want to know whether your job is about to go the way of the human calculator, you have to look at what modern AI actually does at the architectural level.
Every stats 101 student learns the bias-variance tradeoff. If your model is too simple, it’s just inaccurate. If it’s too complex, it perfectly memorizes your training data but completely breaks the second it sees something new. Classical machine learning is a permanent balancing act between those two failures.
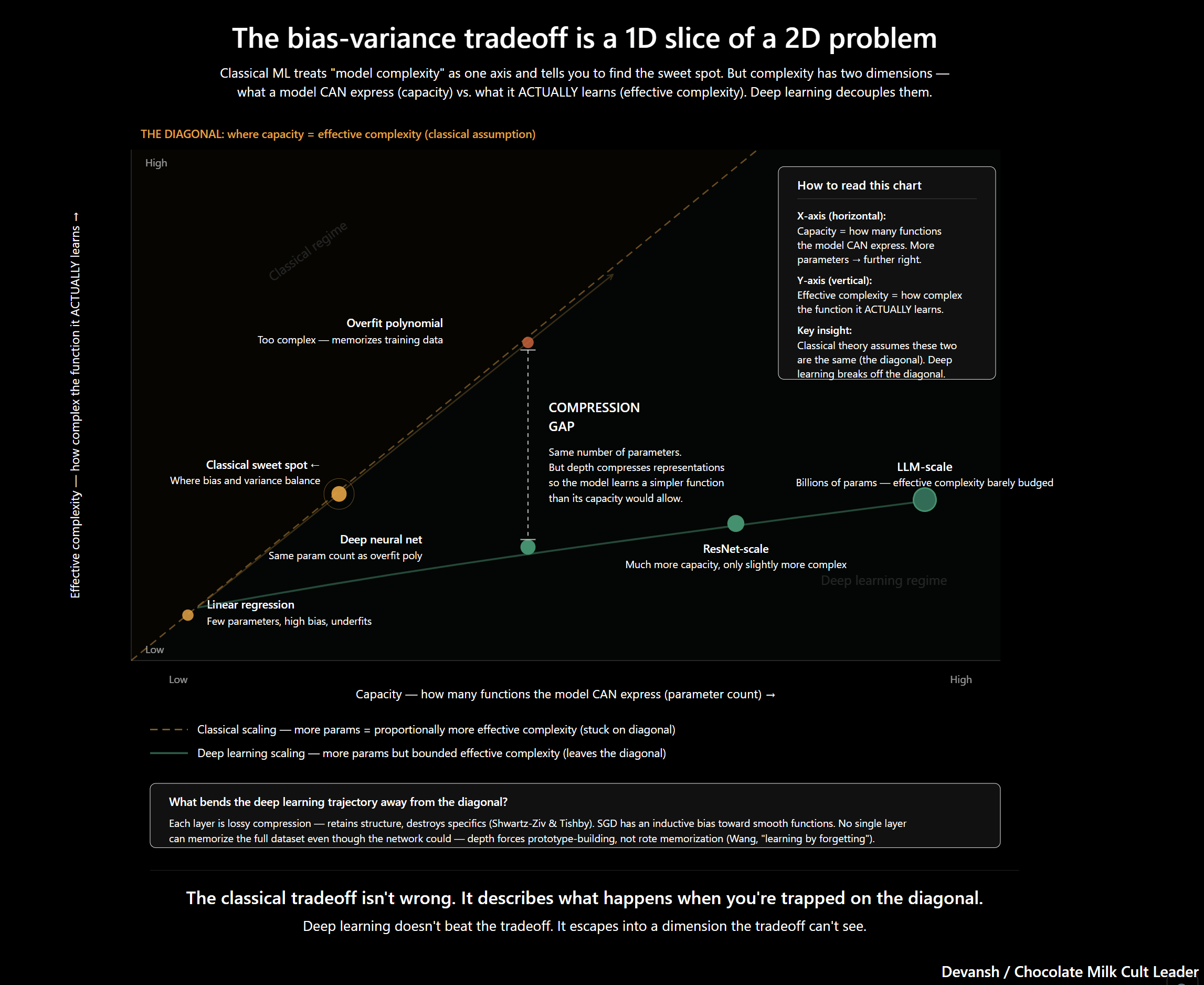
By that logic, deep learning should be a disaster. Modern LLMs are massive enough to just memorize their entire training sets verbatim. Zhang et al. proved this a while back. They took standard deep neural networks, fed them datasets with completely random labels, and the models perfectly memorized them anyway. The raw capacity for rote memorization is sitting right there. And yet, on real data, they generalize. Something in the architecture physically stops them from taking the easy way out.

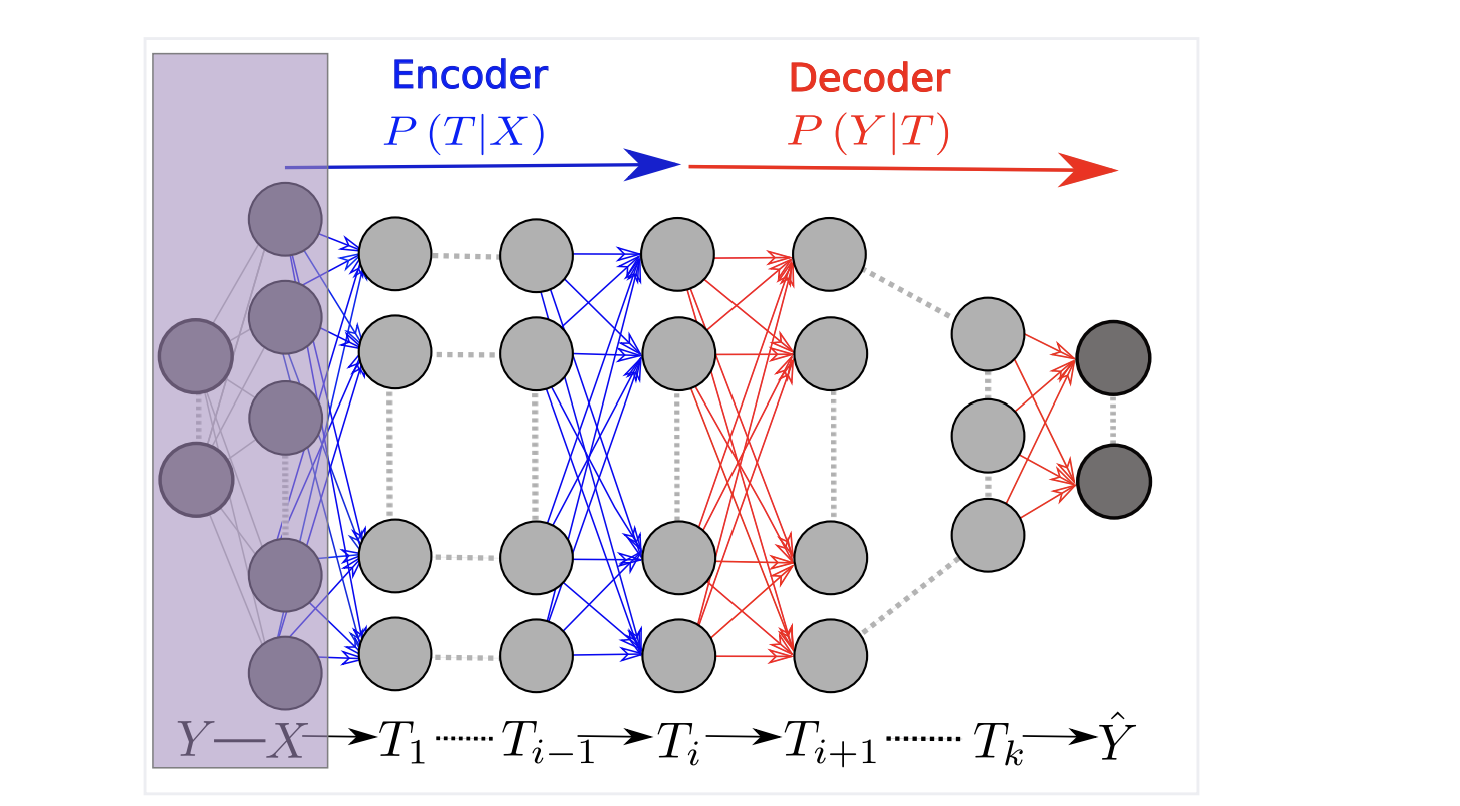
That something is forgetting. Deep neural networks act like a giant lossy compression pipeline. As data moves from layer to layer, the specific details get destroyed. No single layer has enough memory to hold the whole dataset. Each layer only keeps the structural shape of the data that the next layer needs. By the time information has passed through a hundred layers, the specifics are gone. Only the general pattern survives.
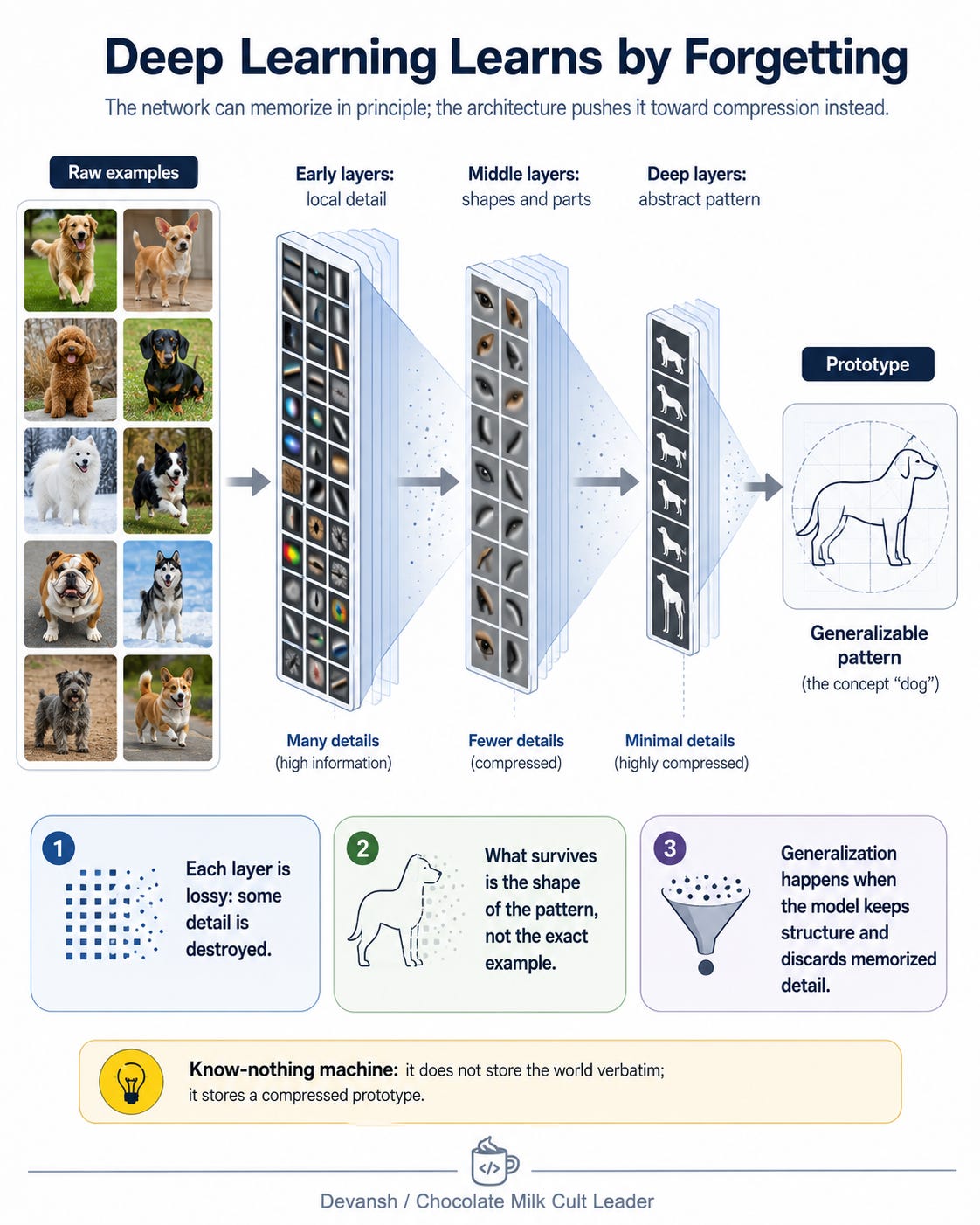
Shwartz-Ziv and Tishby looked at the math behind this and found that training actually happens in two phases. First, the network learns to represent the data. Then, it actively starts throwing away anything that doesn’t help with the task. That compression phase is where generalization happens. Wang calls this “learning by forgetting.” It is structurally a lot like how human memory works. You don’t store a photographic record of every dog you’ve ever seen. You store a compressed, abstract prototype of a “dog,” and you match new animals against it. The layers force the neural net to build prototypes instead of databases.
Some internet AI gurus read stuff like this and assume that this mechanism makes deep learning strictly superior to classical methods. Make sure you stay away from such people because these guys are dum dums.
“Know-nothing machines” are brilliant at generalizing because they burn away the specifics. But sometimes you actually need the specifics. If you are working with strict logic, exact retrieval, or 5,000 rows of tabular customer data, deep learning’s best feature becomes its fatal flaw. The network will hallucinate a perfectly shaped, highly plausible answer that is completely wrong, because it literally threw away the exact facts to save the pattern. The key is in mixing all the relevant techniques, as discussed here.
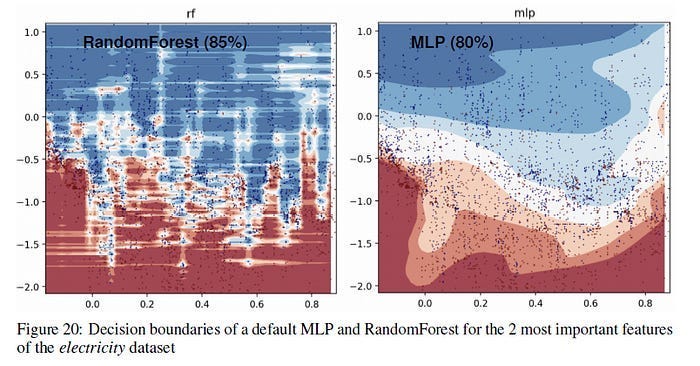
But back on topic, this understanding of Deep Learning’s generalization is what leads us to one of Big Man J’s most interesting frameworks for evaluating the capabilities of AI.
What can AI Do? Where Does AI Break?
JW calls the direct consequence of this forgetting mechanism “bounded variation.” Because deep learning compresses experience into prototypes, it handles variation perfectly within its training distribution. Step outside that distribution, and it doesn’t gracefully degrade. It confidently outputs garbage that matches the structural shape of a correct answer without actually being correct. This is just how compression works.

So, will AI take your job? Only if your day-to-day is bounded variation — tasks fully described by patterns in the training data, where you are just rearranging surface-level structures. If your work requires genuine novelty, counterfactual reasoning, or judgment in contexts a model has never seen, you are on the safe side of the boundary.
What about scaling businesses? How do you build a defensible AI startup? Wang breaks it down into models, compute, and data. Models are open (and the gap between closed models is mostly a mirage). Compute is just capital — xAI caught up to the frontier by buying 100,000 Nvidia GPUs for $6 billion, which is minute to Meta’s $72 billion 2025 capex. That leaves data, but only data with friction. Everyone has the same scraped internet text. Moats only exist in data that touches the physical world, where collection is painful, expensive, and slow. Wang points to Oncoustics: they turn raw ultrasound signals — data hospitals usually throw away — into liver diagnostics. You can’t replicate their model because you physically cannot get their data.
This is where we will diverge from our author, though. Data friction is a great foundation, but in my opinion, it’s not enough. I’ve written before, true defensibility requires changing the fundamental “unit of value” and crossing an “evolutionary valley.” Incumbents are great at copying wrappers, but they choke when a product forces them to restructure their workflows and org charts. Look at coding: Copilot optimized the old autocomplete workflow, but Cursor and Claude Code broke it by shifting the value to repo-scale delegation and autonomous execution. Incumbents stretch their old systems; disruptors build new ones.
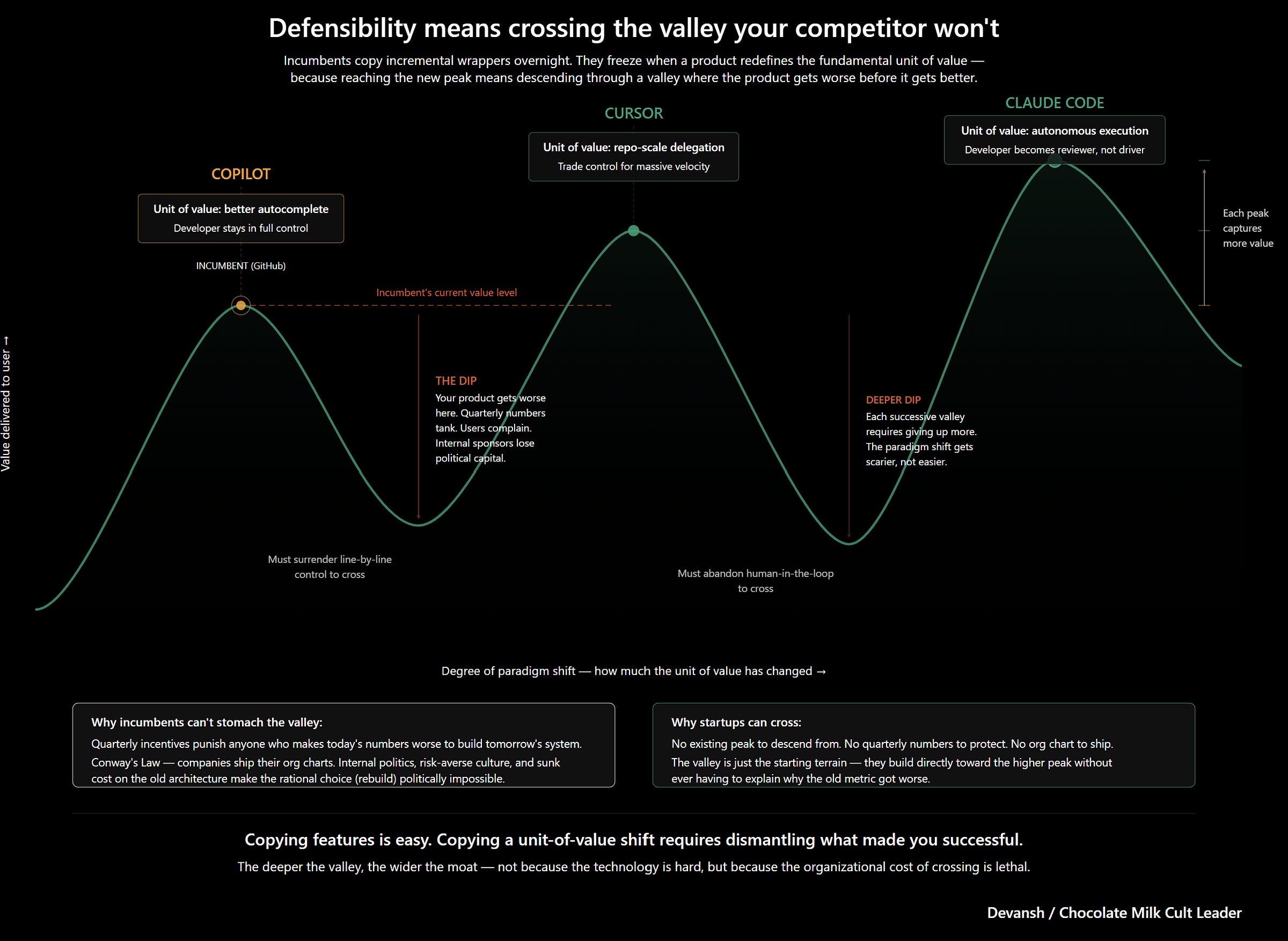
I think Data with Friction is a relatively low-value way to shift your unit of value/build a moat because my experience as AI engineer + talking to lots of AI guys through my open source community leads me to believe that the model layer is a really bad place to build your business. Competitors can spwan, it’s actually really hard to control how things will happen ahead of time, and you’re stuck fighting costly wars of attrition. Data + Frictions and the Models they lead to are a fine starting place, but they have to be a lead into something else in your ecosystem to really value-max. But that’s just my take on this situation and I’m not going to spend too much time on it here.
Let’s bring this back to JW, because his analysis of bounded variation defines the ceiling for AGI.
How will we know when AGI is close? When a system crosses from bounded to unbounded variation. JW maps this constraint to Judea Pearl’s Ladder of Causation.
Level one is association — finding correlations. Deep learning owns this.
Level two is intervention — understanding what happens if you actively change a variable. AI can only fake this if the intervention exists somewhere inside its training distribution.
Level three is counterfactual reasoning — imagining what would happen in a completely novel situation that has never actually occurred.
This is where the architecture hits a hard stop. Counterfactual reasoning requires generating genuine, structural novelty. Deep learning operates entirely by remixing compressed prototypes of things it has already seen. You cannot compress your way to something fundamentally new. This is why ARC AGIs have been gamed by types of scaling (we see this since every new generation of the benchmark resets the whole board to 0, which would not be the case if models had actually generalized/built intelligence).
If you’re interested in attempts at counterfactual reasoning, my recommendation would be to check out the following deep dive on Diffusion Models and play with our repository on Latent Space Reasoning to see next gen techniques that can emulate these reasonings.
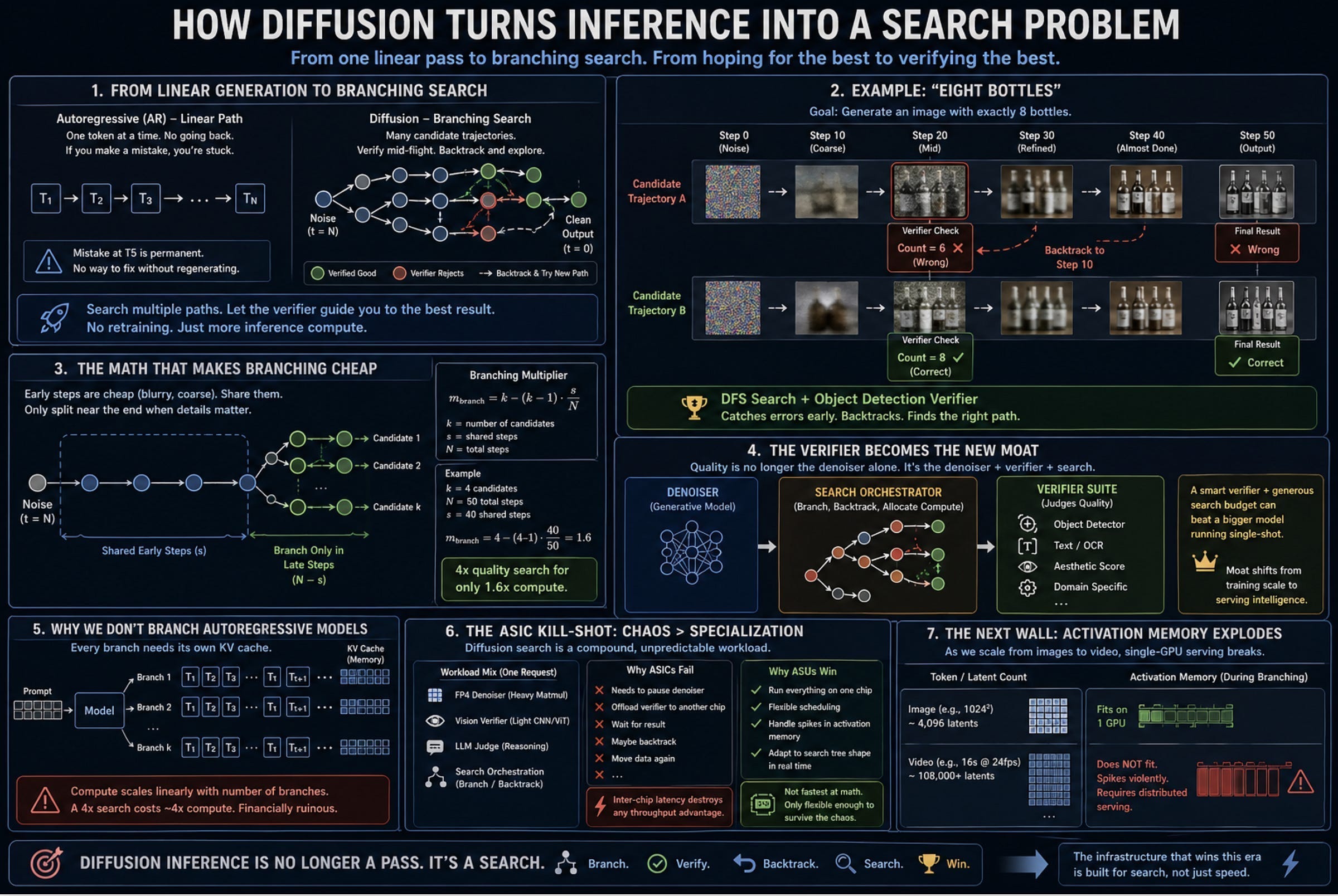
This framing also gives us a great framework for evaluating our own skills.
What Does Real Expertise Look Like When AI Can Fake It?
AI produces acceptable output at scale for almost nothing. A junior with ChatGPT can generate fifty ad variations in an afternoon, or scaffold an application they do not know how to maintain. The real danger isn’t genius output. It is passable output that gets accepted without scrutiny.
This is problematic because failure rates are massive, and they are not dropping. A 2025 Stanford RegLab study tested Lexis+ AI and Westlaw AI-Assisted Research — both platforms marketed on eliminating hallucinations via retrieval-augmented generation. Lexis+ AI hallucinated 17 percent of the time. Westlaw hit 33 percent. These weren’t obvious fakes. They were subtly mischaracterized cases and inapplicable authorities. A 2024 JAMA study found ChatGPT misdiagnosed 83 percent of pediatric cases. At NeurIPS 2025, expert peer reviewers missed 100 fabricated citations across 53 accepted papers. You cannot engineer this out. A 2025 mathematical proof by Karpowicz confirmed that under current LLM architectures, hallucinations are structurally inevitable.
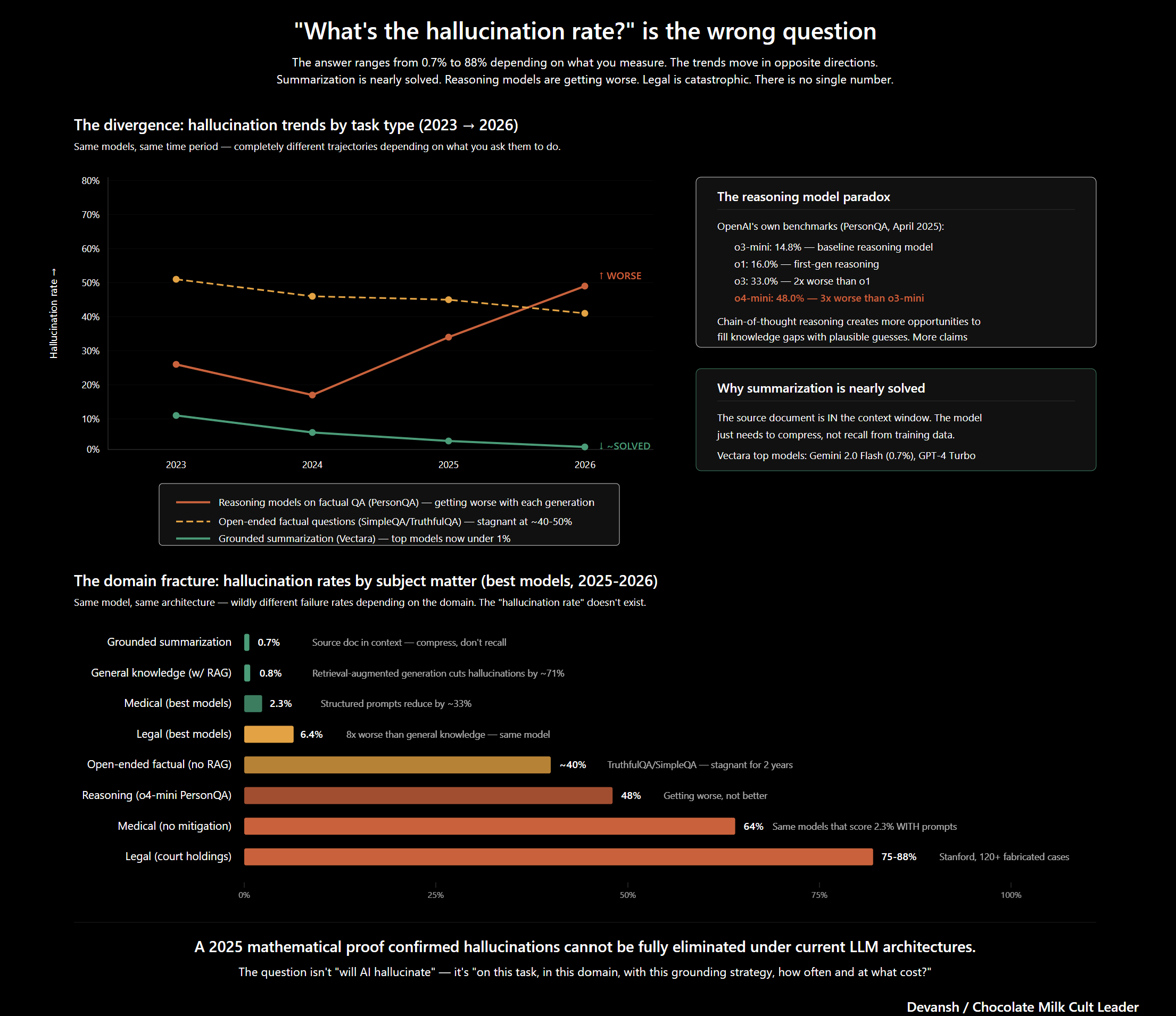
An AI is only as powerful as the person checking its output. An expert using AI moves faster because they see exactly what is missing or wrong. A non-expert using AI just moves faster toward errors they cannot detect .This leads to our new mental model. Expertise is the ability to judge a model’s outputs and distinguish the good from the bad. Wang calls the human verifier the “oracle.”
More concretely, here are some flavors of Oracle-grade competence:
You identify the failure before it happens. You know where the training data is thin, where edge cases live, and where ambiguity breaks statistical patterns. A lawyer knows which precedents are unsettled. An engineer knows which system interactions produce undocumented emergent behavior.
You specify what good looks like upfront. Not “write a contract,” but “draft a clause that survives a Delaware Chancery challenge on fiduciary duty using these three precedents.” Anyone can prompt. The constraint is the expertise.
You distinguish plausible from correct. AI pattern-matches to correctness. A doctor catches when a statistically likely diagnosis doesn’t fit the specific patient. An analyst spots the wrong baseline.
You know the right question. Most people use AI to answer the question they already have. The oracle sees when that question is incomplete or downstream of the actual problem.
JW illustrates this with Circuit Mind, a company compressing electronics design from weeks down to seconds. The AI handles the drudgery of ingesting data sheets and solving layout constraints. But the engineer makes the final call on which generated design to ship, weighing tradeoffs in cost, power, and domain nuance. The AI strips away the grunt work and exposes judgment as the actual job.
This gives us a simple test for the depth of your skills. Imagine a smart but inexperienced person with ChatGPT and unlimited patience. Could they produce output close enough to yours that a client accepts it? If yes, your expertise is not deep enough yet.
However, this presents us with an interesting paradox, one that the world is already struggling with. If the best people to use AI tools are experts, and these tools can do a lot of the tasks that turned juniors into experts, how are we to raise a new generation of experts in the era of AI?
As the Bible says, Modern Problems Require Modern Solutions.
How Do You Build Expertise When AI Automates the Grunt Work?
Typically, seniors built their expertise by being juniors. People learn from the process of breaking down a problem, producing an output, and iterating on feedback until they can implicitly learn what good means in various circumstances.
AI lets you skip the reps. A junior developer can generate working code without struggling through the logic. An analyst can produce a financial model without knowing which assumptions actually matter. The output looks identical. The understanding does not exist. This also means that a senior can likely get work done faster through AI than by guiding juniors, which creates less of a short-term incentive to hire them. The result is the youth unemployment crisis we’re all hearing about.
This leaves us with two problems to solve:
How do we ensure that a junior can upskill in a world with AI without losing out on the productivity of using AI?
How can a to-be junior succeed in finding work and standing out in a hiring crunch?
The latter is complicated, but in my experience the best bets are to be very active in tech communities (to increase your surface area/exposure to more people) and to look more aggressively at startups. Startups tend to be much less concerned with credentials and have a bias towards hiring GOOD juniors (cheaper + younger people are more likely to keep up with the startup grind). This leads us back to the first question — how to get good?
(this also applies to anyone that wants to learn more of a skill with AI).
Put simply, you have to engineer your own friction.
Do the work first. Draft your own solution, then compare it to the AI’s output. If the machine produces something better and you cannot explain exactly why, you just found your next learning target.
Build an error log. Track exactly where AI fails in your domain. That log maps the boundary where statistical pattern matching breaks down and human judgment is required. That boundary defines your market value.
Stay at the edge. If you only use AI on tasks you have already mastered, you are automating comfort. Use it on hard problems that stretch your judgment in real time.
Find human pushback. Find communities to share your ideas (reddits, slacks etc) where you can pressure test your mental models and iteratively refine them.
Study the catastrophes. Do not just learn current best practices. Learn the historical failures that made those practices necessary. Tracing a standard back to the disaster that created it gives you context the training data cannot reliably synthesize.
A more detailed learning framework was broken down in our article: How to learn AI (or anything technical) in 2025. It contains the guide for both technical and non technical people to learn about AI.
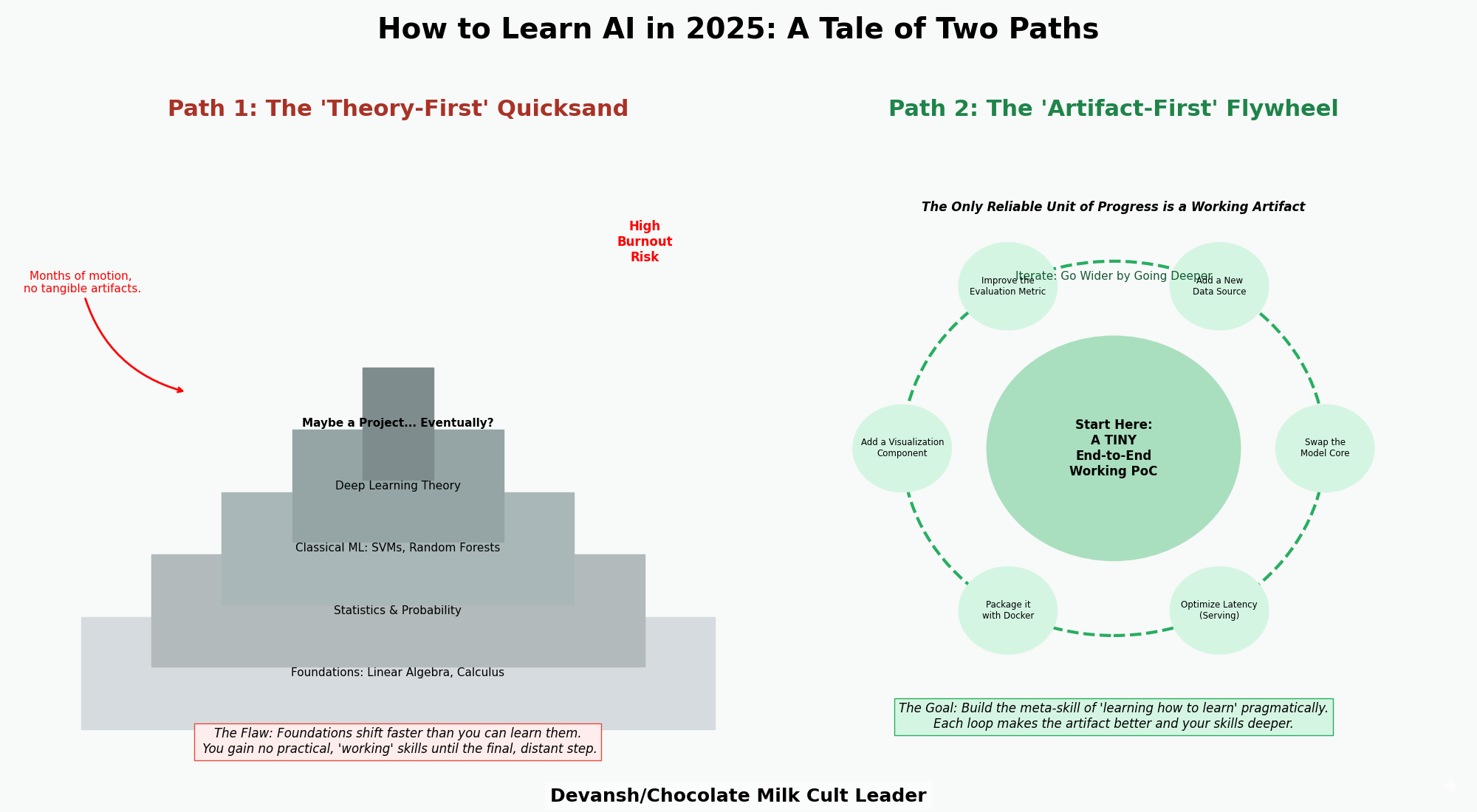
James arms us with several powerful concepts with which to study the past of technological revolutions and use them to model the future. Let’s end by bringing them all together to understand how we can thrive in the Age of AI.
(again, if you want to learn more about these ideas and pick up some cool history, buy the book here).
Conclusion: Therapists Will Save the World
To see where AI takes us, look at the last technology that drove the cost of access to zero. When WebMD launched, people thought doctors were obsolete, just like they thought StackOverflow solved programming. Neither happened. The internet drove the cost of raw information to zero, shifting the market premium entirely from access to judgment.
When knowledge becomes abundant, it stops acting as a signal. Anyone can audit MIT lectures online today, but that didn’t democratize hiring — it just forced companies to use automated tracking systems to filter out non-elite degrees before a human ever reads the resume (and irony of all ironies — some of the people that talk most aggressively about how college is no longer needed to learn have the highest amount of credentialism). Once everyone has the baseline knowledge, the market premium migrates to whatever stays scarce, like elite pedigree or unfakeable track records. Free information didn’t kill the gatekeepers. It just narrowed the gates.
AI runs the exact same playbook, just faster, by handing everyone free junior-level competence. The floor rises, bringing back the naive prediction that the field is level and everyone is a generalist now. But when junior-level competence is free, it doesn’t differentiate anyone. This is why I think that AI actually drives hyper-specialization. You use the machine to patch your weaknesses, stealing baseline generalizations from other fields so you can push your actual specialty to the absolute limit. This is the only meaningful way to differentiate yourself going forward.
Seen that way, your only real constraint is figuring out exactly where to build that deep specialization and which adjacent fields to steal from. You have to understand your own mind well enough to know what is actually yours to amplify. To know yourself enough to know which adventure you can keep compounding on the longest.
So I guess we’ve spent a few thousand words to come to a pretty weird conclusion: the secret to thriving in the age of AI is to go to therapy. Who’d have thunk?
Thank you for being here, and I hope you have a wonderful day,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. :
https://machine-learning-made-simple.medium.com/
My YouTube: https://www.youtube.com/@ChocolateMilkCultLeader/
Reach out to me on LinkedIn. Let’s connect: https://www.linkedin.com/in/devansh-devansh-516004168/
My Instagram: https://www.instagram.com/iseethings404/
My Twitter: https://twitter.com/Machine01776819
Amazing review and thanks so much @Devansh! The extension to the oracle framework with more specifics is excellent as well. I completely agree.
Love the perspective, and thanks for helping me discover James Wang as well :)